Deep Learning for Medical Image Segmentation: Tricks, Challenges and Future Directions 2D部分代码笔记-训练部分
目录
前言
一.训练整体架构(2DUnet/train.py)
1.1 训练参数设置(2DUnet/options.py)
1.2 模型训练(2DUnet/networker_trainer.py)
1.2.1 设置GPU设备号、日志配置、设置随机种子
1.2.2 设置主干网络
1.2.3 设置损失函数
1.2.4 设置优化器和数据集
1.2.5 train
(1).AverageMeter类
(2).深监督(DeepS)
1.2.6 验证过程
1.2.7 运行过程
二、 后续
前言
本篇博客将作为我研0到研3的学习经历的一个记录平台,也是我经验分享的第一步,也许对他人不会起到什么帮助,但是这将会成为我一步步走在科研路上的坚实记录。
人最宝贵的是生命。生命属于人只有一次。人的一生应当这样度过:当他回首往事的时候,不会因为碌碌无为、虚度年华而悔恨,也不会因为为人卑劣、生活庸俗而愧疚。---《钢铁是怎样炼成的》
这篇博客将说明《Deep Learning for Medical Image Segmentation: Tricks, Challenges and Future Directions》这篇论文所提供的2DUnet训练部分代码的一些理解,包括整体架构,部分模块含义以及论文中提到的一些训练技巧在代码中的体现。
一.训练整体架构(2DUnet/train.py)
不同于一些习惯于将模型训练过程和数据预处理、设置网络、设置训练参数等等写在一起的代码风格,这篇论文的coder将基本上所有关于网络训练部分的设置全部模块化处理(测试时也是相同),可以让人很清晰的按照train.py所提供的训练顺序来了解医疗影像分割训练的整体过程,也方便后续人们进行所需代码模块的调用。
下面为train.py的具体代码:
import sys
sys.path.append('../') # 把路径添加到系统路径中去,防止路径报错
import network_trainer
from options import Options
def main():
'''opt实际上为存放模型、训练、测试、图片变形的一系列操作变量的大字典'''
opt = Options(isTrain=True) # 获取基本变量
opt.parse() # 解析环境变量
opt.save_options() # 保存环境变量
trainer = network_trainer.NetworkTrainer(opt) # 网络训练部分
trainer.set_GPU_device() # 设置使用哪几个GPU来进行训练、测试工作
trainer.set_logging() # 设置日志
trainer.set_randomseed() # 给训练设置随机种子 2022
trainer.set_network() # 设置训练的主干网络
trainer.set_loss() # 设置损失函数 初始为交叉熵
trainer.set_optimizer() # Adam+余弦学习率更新
trainer.set_dataloader() # 加载数据集
trainer.run()
if __name__ == "__main__":
main()
从代码来看,整体网络训练的过程如下:
设置环境、训练变量(argparse库实现)---- 将设置的变量保存为字典,之后保存到.txt文件中方便查看----设置训练时的一些配置(GPU、日志、seed等)----设置主干网络----设置损失函数、优化器等等----加载数据集----训练
下面也将按照此流程进行说明
1.1 训练参数设置(2DUnet/options.py)
optipn.py主要设置训练时的一些参数,也包括将这些配置写入.txt文件的代码
import os
import argparse
from NetworkTrainer.dataloaders.get_transform import get_transform
class Options:
def __init__(self, isTrain):
self.isTrain = isTrain # 判断是否训练
self.model = dict() # 模型属性
self.train = dict() # 训练部分的字典
self.test = dict() # 测试部分的字典
self.transform = dict() # 三种模型状态下 图片变形的方式
self.post = dict() # 数据后处理字典
def parse(self):
""" Parse the options, replace the default value if there is a new input ---网络训练时的一些默认参数"""
parser = argparse.ArgumentParser(description='')
parser.add_argument('--dataset', type=str, default='isic2018', help='isic2018 or conic') # 数据集类型
parser.add_argument('--task', type=str, default='debug', help='') # 调试任务
parser.add_argument('--fold', type=int, default=0, help='0-4, five fold cross validation') # 交叉验证文件夹
parser.add_argument('--name', type=str, default='res50', help='res34, res50, res101, res152') # 残差模型名称
parser.add_argument('--pretrained', type=bool, default=False, help='True or False') # 是否采用预训练模型
parser.add_argument('--in-c', type=int, default=3, help='input channel') # 输入图片的维度
parser.add_argument('--input-size', type=list, default=[256,256], help='input size of the image') # 输入图片的尺寸
parser.add_argument('--train-gan-aug', type=bool, default=False, help='if use the augmente samples generated by GAN') # 是否使用GAN模型数据增强
parser.add_argument('--train-train-epochs', type=int, default=200, help='number of training epochs') # 训练周期
parser.add_argument('--train-batch-size', type=int, default=32, help='batch size')
parser.add_argument('--train-checkpoint-freq', type=int, default=500, help='epoch to save checkpoints')
parser.add_argument('--train-lr', type=float, default=3e-4, help='initial learning rate')
parser.add_argument('--train-weight-decay', type=float, default=1e-5, help='weight decay')
parser.add_argument('--train-workers', type=int, default=16, help='number of workers to load images') # 训练时cpu个数
parser.add_argument('--train-gpus', type=list, default=[0, ], help='select gpu devices')
parser.add_argument('--train-start-epoch', type=int, default=0, help='start epoch')
parser.add_argument('--train-checkpoint', type=str, default='', help='checkpoint')
parser.add_argument('--train-seed', type=int, default=2022, help='bn or in')
parser.add_argument('--train-loss', type=str, default='ce', help='loss function, e.g., ce, dice, focal, ohem, tversky, wce') # loss
parser.add_argument('--train-deeps', type=bool, default=False, help='if use deep supervision')
parser.add_argument('--test-model-path', type=str, default=None, help='model path to test')
parser.add_argument('--test-test-epoch', type=int, default=0, help='the checkpoint to test')
parser.add_argument('--test-gpus', type=list, default=[0, ], help='select gpu devices')
parser.add_argument('--test-save-flag', type=bool, default=False, help='if save the predicted results')
parser.add_argument('--test-batch-size', type=int, default=4, help='batch size')
parser.add_argument('--test-flip', type=bool, default=False, help='Test Time Augmentation with flipping')
parser.add_argument('--test-rotate', type=bool, default=False, help='Test Time Augmentation with rotation') # TTA选项
parser.add_argument('--post-abl', type=bool, default=False, help='True or False, post processing') # 后处理选项
parser.add_argument('--post-rsa', type=bool, default=False, help='True or False, post processing')
args = parser.parse_args()
self.dataset = args.dataset
self.task = args.task
self.fold = args.fold
self.root_dir = 'C:\\Users\\Desktop\\MedISeg-main\\isic2018' # 数据集目录
self.result_dir = os.path.expanduser("~") + f'/Experiment/isic-2018/{self.dataset}/'
self.model['name'] = args.name
self.model['pretrained'] = args.pretrained
self.model['in_c'] = args.in_c
self.model['input_size'] = args.input_size
'''train部分属性'''
# --- training params --- #
self.train['save_dir'] = '{:s}/{:s}/{:s}/fold_{:d}'.format(self.result_dir, self.task, self.model['name'], self.fold) # path to save results
self.train['train_epochs'] = args.train_train_epochs
self.train['batch_size'] = args.train_batch_size
self.train['checkpoint_freq'] = args.train_checkpoint_freq
self.train['lr'] = args.train_lr
self.train['weight_decay'] = args.train_weight_decay
self.train['workers'] = args.train_workers
self.train['gpus'] = args.train_gpus
self.train['seed'] = args.train_seed
self.train['loss'] = args.train_loss
self.train['deeps'] = args.train_deeps
self.train['gan_aug'] = args.train_gan_aug
# --- resume training --- #
self.train['start_epoch'] = args.train_start_epoch
self.train['checkpoint'] = args.train_checkpoint
# --- test parameters --- #
'''test部分属性'''
self.test['test_epoch'] = args.test_test_epoch
self.test['gpus'] = args.test_gpus
self.test['save_flag'] = args.test_save_flag
self.test['batch_size'] = args.test_batch_size
self.test['flip'] = args.test_flip
self.test['rotate'] = args.test_rotate
self.test['save_dir'] = '{:s}/test_results'.format(self.train['save_dir'])
if not args.test_model_path:
self.test['model_path'] = '{:s}/checkpoints/checkpoint_{:d}.pth.tar'.format(self.train['save_dir'], self.test['test_epoch'])
# --- post processing --- #
'''图片后处理部分'''
self.post['abl'] = args.post_abl
self.post['rsa'] = args.post_rsa
# define data transforms for training
self.transform['train'] = get_transform(self, 'train')
self.transform['val'] = get_transform(self, 'val')
self.transform['test'] = get_transform(self, 'test')
def save_options(self):
if not os.path.exists(self.train['save_dir']):
'''建立测试结果和检查点的文件夹'''
os.makedirs(self.train['save_dir'], exist_ok=True)
os.makedirs(os.path.join(self.train['save_dir'], 'test_results'), exist_ok=True)
os.makedirs(os.path.join(self.train['save_dir'], 'checkpoints'), exist_ok=True)
if self.isTrain:
filename = '{:s}/train_options.txt'.format(self.train['save_dir'])
else:
filename = '{:s}/test_options.txt'.format(self.test['save_dir'])
file = open(filename, 'w')
groups = ['model', 'test', 'post', 'transform']
file.write("# ---------- Options ---------- #")
file.write('\ndataset: {:s}\n'.format(self.dataset))
file.write('isTrain: {}\n'.format(self.isTrain))
'''获取类中self.xxx的属性值,查看对象内部所有属性名和属性值组成的字典,该部分是将groups = ['model', 'test', 'post', 'transform']的几种状态的变量值写到文件中去'''
for group, options in self.__dict__.items(): # 11个属性
if group not in groups:
continue
file.write('\n\n-------- {:s} --------\n'.format(group))
if group == 'transform':
for name, val in options.items():
if (self.isTrain and name != 'test') or (not self.isTrain and name == 'test'):
file.write("{:s}:\n".format(name))
for t_val in val:
file.write("\t{:s}\n".format(t_val.__class__.__name__))
else:
for name, val in options.items():
file.write("{:s} = {:s}\n".format(name, repr(val)))
file.close()
这一部分代码主要设置了“model”、“train”、“test”、“post”部分的参数,方便后续调用,这部分操作在每项代码都会有体现,即设置环境变量、储存各部分需要的初始参数等,在此不作详细说明
1.2 模型训练(2DUnet/networker_trainer.py)
这部分是训练的主干,它将模型的训练过程分别模块化,因此在此也会逐步分析每个模块
1.2.1 设置GPU设备号、日志配置、设置随机种子
class NetworkTrainer:
def __init__(self, opt):
self.opt = opt
self.criterion = CELoss() # 评价函数初始为CEloss(交叉熵)
def set_GPU_device(self):
os.environ['CUDA_VISIBLE_DEVICES'] = ','.join(str(x) for x in self.opt.train['gpus']) # 设置在哪个GPU上跑
def set_logging(self):
self.logger, self.logger_results = setup_logging(self.opt) # 设置日志
def set_randomseed(self):
num = self.opt.train['seed'] # 获得初始种子 2022
random.seed(num) # 设置随机种子
os.environ['PYTHONHASHSEED'] = str(num) # 加到系统环境变量中
np.random.seed(num) # 作用同random.seed(num)
# 给CPU、当前GPU、所有GPU设置随机数种子
torch.manual_seed(num)
torch.cuda.manual_seed(num)
torch.cuda.manual_seed_all(num)setup_logging是定义在2DUnet/utils.py中的,主要是利用logging库来设置日志参数等,代码中的随机数种子设置为2022(有点数学竞赛选填总会有一道x的2022次方题的味道了),但实际上效果比较好的种子一般会设为1337、0等。(其余的我也不太知道了)
setup_logging代码如下:
'''记录模型整个过程的日志'''
def setup_logging(opt):
mode = 'a' if opt.train['checkpoint'] else 'w'
# create logger for training information
logger = logging.getLogger(
'train_logger') # 应当通过模块级别的函数 logging.getLogger(name) 。多次使用相同的名字调用 getLogger() 会一直返回相同的 Logger 对象的引用】
logger.setLevel(logging.DEBUG) # 日志等级小于 debug会被忽略。严重性为 level 或更高的日志消息将由该记录器的任何一个或多个处理器发出
# create console handler and file handler
# console_handler = logging.StreamHandler()
console_handler = RichHandler(show_level=False, show_time=False, show_path=False)
console_handler.setLevel(logging.INFO) # 记录info级别的日志
file_handler = logging.FileHandler('{:s}/train_log.txt'.format(opt.train['save_dir']), mode=mode)
file_handler.setLevel(logging.DEBUG) # 新建日志文件 记录DEBUG级别以上的日志
# create formatter
# formatter = logging.Formatter('%(asctime)s\t%(message)s', datefmt='%m-%d %I:%M')
'''建立格式化对象formatter 将消息包括在日志记录调用中'''
formatter = logging.Formatter('%(message)s')
# add formatter to handlers
console_handler.setFormatter(formatter)
file_handler.setFormatter(formatter)
# add handlers to logger
logger.addHandler(console_handler)
logger.addHandler(file_handler)
# create logger for epoch results
logger_results = logging.getLogger('results')
logger_results.setLevel(logging.DEBUG)
file_handler2 = logging.FileHandler('{:s}/epoch_results.txt'.format(opt.train['save_dir']), mode=mode)
file_handler2.setFormatter(logging.Formatter('%(message)s'))
logger_results.addHandler(file_handler2)
logger.info('***** Training starts *****')
logger.info('save directory: {:s}'.format(opt.train['save_dir']))
if mode == 'w':
logger_results.info('epoch\ttrain_loss\ttrain_loss_vor\ttrain_loss_cluster\ttrain_loss_repel')
return logger, logger_results设置日志是为了查看训练代码运行中出现的问题,处于调试方便一般都会设立此模块
1.2.2 设置主干网络
代码中使用的网络类型很多,如:densenet,resnet,vit,resunet等,除此之外还有是否使用深监督等一系列设置,通过字典中名字来分别设置主干网络
def set_network(self):
if 'res' in self.opt.model['name']:
self.net = ResUNet(net=self.opt.model['name'], seg_classes=2, colour_classes=3, pretrained=self.opt.model['pretrained']) # Res50, 2D 二分类,channel=3
if self.opt.train['deeps']:
self.net = ResUNet_ds(net=self.opt.model['name'], seg_classes=2, colour_classes=3, pretrained=self.opt.model['pretrained'])
elif 'dense' in self.opt.model['name']:
self.net = DenseUNet(net=self.opt.model['name'], seg_classes=2)
elif 'trans' in self.opt.model['name']:
config_vit = CONFIGS_ViT_seg[self.opt.model['name']]
config_vit.n_classes = 2
config_vit.n_skip = 4
if self.opt.model['name'].find('R50') != -1:
config_vit.patches.grid = (int(self.opt.model['input_size'][0] / 16), int(self.opt.model['input_size'][1] / 16))
self.net = ViT_seg(config_vit, img_size=self.opt.model['input_size'][0], num_classes=config_vit.n_classes).cuda()
else:
self.net = UNet(3, 2, 2) # 默认主干网络
self.net = torch.nn.DataParallel(self.net) # 使用多个GPU加速训练
self.net = self.net.cuda()1.2.3 设置损失函数
论文中提及了4种损失函数计算方法,即Dice,Focalloss,tverskyloss和ohemloss,代码中加入了WCEloss等,此部分代码如下:
def set_loss(self):
# set loss function
if self.opt.train['loss'] == 'ce':
self.criterion = CELoss()
elif self.opt.train['loss'] == 'dice':
self.criterion = DiceLoss()
elif self.opt.train['loss'] == 'focal':
self.criterion = FocalLoss(apply_nonlin=torch.nn.Softmax(dim=1))
elif self.opt.train['loss'] == 'tversky':
self.criterion = TverskyLoss()
elif self.opt.train['loss'] == 'ohem':
self.criterion = OHEMLoss()
elif self.opt.train['loss'] == 'wce':
self.criterion = CELoss(weight=torch.tensor([0.2, 0.8]))其中,几种损失函数都定义在了loss_imbalance.py中,各种损失函数定义代码如下:
"""
In ISIC dataset, the label shape is (b, x, y)
In Kitti dataset, the label shape is (b, 1, x, y, z)
"""
import ctypes
import torch
import torch.nn as nn
import numpy as np
class CELoss(nn.Module):
def __init__(self, weight=None, reduction='mean'):
self.weight = weight
self.reduction = reduction
def __call__(self, y_pred, y_true):
y_true = y_true.long()
if self.weight is not None:
self.weight = self.weight.to(y_pred.device)
if len(y_true.shape) == 5:
y_true = y_true[:, 0, ...] # 约等于y_pred[:,0,...] 降维取每维第一个元素
loss = nn.CrossEntropyLoss(weight=self.weight, reduction=self.reduction)
return loss(y_pred, y_true)
'''视之为二分类的Diceloss,但代码流程为普通DiceLoss'''
class DiceLoss(nn.Module):
def __init__(self, smooth=1e-8):
super(DiceLoss, self).__init__()
self.smooth = smooth # 极小量保证除式分母不为0
def forward(self, y_pred, y_true):
# first convert y_true to one-hot format
axis = identify_axis(y_pred.shape) # axis=[2,3,4]
y_pred = nn.Softmax(dim=1)(y_pred) # 沿1维softmax 降为(a,b,c,d)
tp, fp, fn, _ = get_tp_fp_fn_tn(y_pred, y_true, axis) # 获取计算DiceLoss的tp,fp,fn
intersection = 2 * tp + self.smooth
union = 2 * tp + fp + fn + self.smooth
dice = 1 - (intersection / union) #
return dice.mean()
# taken from https://github.com/JunMa11/SegLoss/blob/master/test/nnUNetV2/loss_functions/focal_loss.py
class FocalLoss(nn.Module):
"""
copy from: https://github.com/Hsuxu/Loss_ToolBox-PyTorch/blob/master/FocalLoss/FocalLoss.py
This is a implementation of Focal Loss with smooth label cross entropy supported which is proposed in
'Focal Loss for Dense Object Detection. (https://arxiv.org/abs/1708.02002)'
Focal_Loss= -1*alpha*(1-pt)*log(pt)
:param num_class:
:param alpha: (tensor) 3D or 4D the scalar factor for this criterion
:param gamma: (float,double) gamma > 0 reduces the relative loss for well-classified examples (p>0.5) putting more
focus on hard misclassified example
:param smooth: (float,double) smooth value when cross entropy
:param balance_index: (int) balance class index, should be specific when alpha is float
:param size_average: (bool, optional) By default, the losses are averaged over each loss element in the batch.
"""
# 支持多分类和二分类
def __init__(self, apply_nonlin=None, alpha=0.25, gamma=2, balance_index=0, smooth=1e-5, size_average=True):
super(FocalLoss, self).__init__()
self.apply_nonlin = apply_nonlin #
self.alpha = alpha # 公式中的alpha
self.gamma = gamma # 可调节因子 公式中的次方数
self.balance_index = balance_index
self.smooth = smooth
self.size_average = size_average # loss是否平均
if self.smooth is not None:
if self.smooth < 0 or self.smooth > 1.0:
raise ValueError('smooth value should be in [0,1]')
def forward(self, logit, target):
if self.apply_nonlin is not None:
logit = self.apply_nonlin(logit)
num_class = logit.shape[1] # 3个channel
'''这一部分的操作为将logits降维 (voxels,channels)'''
if logit.dim() > 2:
# N,C,d1,d2 -> N,C,m (m=d1*d2*...)
logit = logit.view(logit.size(0), logit.size(1), -1) # logits从(1,3,5,5,5) 变为(1,3,125)
logit = logit.permute(0, 2, 1).contiguous() # N,C,m--->N,m,C
logit = logit.view(-1, logit.size(-1)) # view(-1)变成了一行数据,也就是说不管原来是什么维度的张量,经过view操作之后,\
# 行优先的顺序变成了一行数据\
# 变为(125,3)
target = torch.squeeze(target, 1)
target = target.view(-1, 1) # 变为1列
alpha = self.alpha
if alpha is None: # alpha没有则随机取
alpha = torch.ones(num_class, 1)
elif isinstance(alpha, (list, np.ndarray)): # alpha是否为list或array
assert len(alpha) == num_class
alpha = torch.FloatTensor(alpha).view(num_class, 1)
alpha = alpha / alpha.sum() # 归一化
elif isinstance(alpha, float):
alpha = torch.ones(num_class, 1) # 1初始化
alpha = alpha * (1 - self.alpha)
alpha[self.balance_index] = self.alpha # alpha[0]
else:
raise TypeError('Not support alpha type')
'''统一device'''
if alpha.device != logit.device:
alpha = alpha.to(logit.device)
idx = target.cpu().long()
one_hot_key = torch.FloatTensor(target.size(0), num_class) # 随机创建(125,3)的FloatTensor
one_hot_key = one_hot_key.zero_() # 把自己填0
one_hot_key = one_hot_key.scatter_(1, idx, 1) # torch.Tensor.scatter_(dim, index, src) → Tensor
'''scatter_具体算法 建立onehot和target的映射
self[index[i][j][k]][j][k] = src[i][j][k] # if dim == 0
self[i][index[i][j][k]][k] = src[i][j][k] # if dim == 1
self[i][j][index[i][j][k]] = src[i][j][k] # if dim == 2'''
if one_hot_key.device != logit.device:
one_hot_key = one_hot_key.to(logit.device)
'''这一步主要是为了防止log运算出现 log0 的情况'''
if self.smooth:
one_hot_key = torch.clamp(
one_hot_key, self.smooth / (num_class - 1), 1.0 - self.smooth) # 把onehot编码限制到(min,max)范围 无限接近于(0,1) 避免下面log运算报错
pt = (one_hot_key * logit).sum(1) + self.smooth # 计算pt false sample prob*0+true sample prob*1+极小量=pt、
# pt越大 越好学习 loss中占的比重小
logpt = pt.log()
gamma = self.gamma
alpha = alpha[idx] # idx : (125,1)
alpha = torch.squeeze(alpha) # 得到(125,)
'''公式实现'''
mul = torch.pow((1 - pt), gamma) # (125,)
loss = -1 * alpha* mul * logpt
'''batch内平均loss'''
if self.size_average:
loss = loss.mean()
else:
loss = loss.sum()
return loss
'''T loss为Diceloss的改进版本 强调fp fn权重 alpha beta 其余同Diceloss'''
class TverskyLoss(nn.Module):
def __init__(self, alpha=0.3, beta=0.7, eps=1e-7): # 0.3 0.7一般效果比较好
super(TverskyLoss, self).__init__()
self.alpha = alpha
self.beta = beta
self.eps = eps
def forward(self, y_pred, y_true):
axis = identify_axis(y_pred.shape)
y_pred = nn.Softmax(dim=1)(y_pred)
y_true = to_onehot(y_pred, y_true)
y_pred = torch.clamp(y_pred, self.eps, 1. - self.eps)
tp, fp, fn, _ = get_tp_fp_fn_tn(y_pred, y_true, axis)
tversky = (tp + self.eps) / (tp + self.eps + self.alpha * fn + self.beta * fp)
return (y_pred.shape[1] - tversky.sum()) / y_pred.shape[1] # 0.6590
# return (1-tversky).mean() # 0.6707
class OHEMLoss(nn.CrossEntropyLoss):
"""
Network has to have NO LINEARITY!
"""
def __init__(self, weight=None, ignore_index=-100, k=0.7):
super(OHEMLoss, self).__init__()
self.k = k
self.weight = weight
self.ignore_index = ignore_index
def forward(self, y_pred, y_true):
res = CELoss(reduction='none')(y_pred, y_true) # 算CEloss
num_voxels = np.prod(res.shape, dtype=np.int64) # 算体素
res, _ = torch.topk(res.view((-1,)), int(num_voxels * self.k), sorted=False) # 排序取前k个损失最大的pixel\
# 该函数返回2个值,第一个值为排序的数组,第二个值为该数组中获取到的元素在原数组中的位置标号
return res.mean() # 最后,求这些 hard example 的损失的均值作为最终损失
def to_onehot(y_pred, y_true):
shp_x = y_pred.shape # tensor(1,3,5,5,5)
shp_y = y_true.shape
with torch.no_grad():
"predict & target batch size don't match"
if len(shp_x) != len(shp_y):
y_true = y_true.view((shp_y[0], 1, *shp_y[1:])) # tensor(1,1,5,5,5)
if all([i == j for i, j in zip(y_pred.shape, y_true.shape)]): # 预测的分类张量形式和onehot形式一样
# if this is the case then gt is probably already a one hot encoding
y_onehot = y_true # 认定为已经转变为onehot编码
else:
y_true = y_true.long() # 数据类型变为LongTensor
y_onehot = torch.zeros(shp_x, device=y_pred.device)
y_onehot.scatter_(1, y_true, 1) # scatter_(input, dim, index, src)将src中数据根据index中的索引按照dim的方向填进input中
return y_onehot
'''Diceloss源码对应部分'''
# def make_one_hot(input, num_classes):
# """Convert class index tensor to one hot encoding tensor.
# Args:
# input: A tensor of shape [N, 1, *]
# num_classes: An int of number of class
# Returns:
# A tensor of shape [N, num_classes, *]
# """
# shape = np.array(input.shape)
# shape[1] = num_classes
# shape = tuple(shape)
# result = torch.zeros(shape)
# result = result.scatter_(1, input.cpu(), 1)
#
# return result
def get_tp_fp_fn_tn(net_output, gt, axes=None, square=False):
"""
net_output must be (b, c, x, y(, z)))
gt must be a label map (shape (b, 1, x, y(, z)) OR shape (b, x, y(, z))) or one hot encoding (b, c, x, y(, z))
if mask is provided it must have shape (b, 1, x, y(, z)))
:param net_output:
:param gt:
:return:
"""
if axes is None:
axes = tuple(range(2, len(net_output.size()))) # (2,3,4) 3D # shape=tupe(shape)
y_onehot = to_onehot(net_output, gt) # 转变为one_hot编码
tp = net_output * y_onehot # 概率值乘标签图==TP
fp = net_output * (1 - y_onehot)
fn = (1 - net_output) * y_onehot
tn = (1 - net_output) * (1 - y_onehot)
if square:
tp = tp ** 2
fp = fp ** 2
fn = fn ** 2
tn = tn ** 2
if len(axes) > 0:
tp = sum_tensor(tp, axes, keepdim=False)
fp = sum_tensor(fp, axes, keepdim=False)
fn = sum_tensor(fn, axes, keepdim=False)
tn = sum_tensor(tn, axes, keepdim=False)
return tp, fp, fn, tn
'''对张量求和'''
def sum_tensor(inp, axes, keepdim=False):
axes = np.unique(axes).astype(int)
if keepdim:
for ax in axes:
inp = inp.sum(int(ax), keepdim=True)
else:
for ax in sorted(axes, reverse=True):
inp = inp.sum(int(ax)) # 沿着4、3、2维累计求和
return inp
def identify_axis(shape):
"""
Helper function to enable loss function to be flexibly used for
both 2D or 3D image segmentation - source: https://github.com/frankkramer-lab/MIScnn
"""
# Three dimensional
if len(shape) == 5:
return [2, 3, 4]
# Two dimensional
elif len(shape) == 4:
return [2, 3]
# Exception - Unknown
else:
raise ValueError('Metric: Shape of tensor is neither 2D or 3D.')因其模块化的特性,因此可以十分容易将这些损失函数应用/继承到其他代码当中去,这也是这篇论文的写作初衷。
1.2.4 设置优化器和数据集
代码中使用的是Adam优化器+余弦学习率更新策略,而载入的数据集需要提前将ISIC2018的.png格式文件转换为.npy文件,因此在载入数据集前需要一定的预处理。
def set_optimizer(self):
self.optimizer = torch.optim.Adam(self.net.parameters(), self.opt.train['lr'], betas=(0.9, 0.99), weight_decay=self.opt.train['weight_decay']) # Adam
self.scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(self.optimizer, T_max=self.opt.train['train_epochs']) # 余弦学习率更新算法
'''获取载入数据集'''
def set_dataloader(self):
self.train_set = DataFolder(root_dir=self.opt.root_dir, phase='train', fold=self.opt.fold, gan_aug=self.opt.train['gan_aug'], data_transform=A.Compose(self.opt.transform['train']))
self.val_set = DataFolder(root_dir=self.opt.root_dir, phase='val', data_transform=A.Compose(self.opt.transform['val']), fold=self.opt.fold)
self.train_loader = DataLoader(self.train_set, batch_size=self.opt.train['batch_size'], shuffle=True, num_workers=self.opt.train['workers'])
self.val_loader = DataLoader(self.val_set, batch_size=self.opt.train['batch_size'], shuffle=False, drop_last=False, num_workers=self.opt.train['workers'])
我使用的png to npy 代码
import numpy as np
import imageio
import os
os.chdir('C:\\Users\\Desktop\\MedISeg-main\\isic2018\\mask') # 切换python工作路径到你要操作的图片文件夹,mri_2d_test为我的图片文件夹
a = np.ones((2, 2848, 4288)) # 利用np.ones()函数生成一个三维数组,当然也可用np.zeros,此数组的每个元素a[i]保存一张图片
i = 1
for filename in os.listdir(r"C:\\Users\\Desktop\\MedISeg-main\\isic2018\\mask"): # 使用os.listdir()获取该文件夹下每一张图片的名字
im = imageio.imread(filename)
a[i] = im
i = i + 1
i
if (i == 2): #
break
np.save('C:\\Users\\Desktop\\MedISeg-main\\isic2018\\NumpyData', a)
1.2.5 train
训练过程其实是一个标准的普通深度学习过程(最基础的训练过程代码在注释),作者对代码的改变为加入了深监督选项,如果在选择主干网络时选择了带有深监督ResUnet,则需要在此选择加入深监督的训练过程,代码如下:
def train(self):
self.net.train() # 开始训练
'''在train函数中采用自定义的AverageMeter类来管理一些变量的更新。在初始化的时候就调用的重置方法reset。当调用该类对象的update方法的时候就会进行变量更新,当要读取某个变量的时候,可以通过对象.属性的方式来读取,
本质上是对所有batch取平均?/'''
losses = AverageMeter()
for i_batch, sampled_batch in enumerate(self.train_loader): # 过dataloader产生 序号+训练图片(图片+标签) 在这里为 批次序号+采样过的图片序列和标签
volume_batch, label_batch = sampled_batch['image'], sampled_batch['label'] # 分imglist+label
volume_batch, label_batch = volume_batch.cuda(), label_batch.cuda() # 使用cuda
outputs = self.net(volume_batch) # 输出y_pred结果
'''倘若不使用深度监督 正常计算loss即可'''
if not self.opt.train['deeps']:
loss = self.criterion(outputs, label_batch)
else:
# compute loss for each deep layer, i.e., x0, x1, x2, x3
'''------------------------------------深度监督loss计算部分---------------------------------- '''
'''倘若采用深监督 上面的output应为含有4个大元素的tensor 每个元素之间为h,w参数下采样2倍的关系'''
gts = []
loss = 0.
for i in range(4): # res50 算4个层的loss来判断图片是否良好
gt = label_batch.float().cuda().view(label_batch.shape[0], 1, label_batch.shape[1], label_batch.shape[2]) # [c N h w]
h, w = gt.shape[2] // (2 ** i), gt.shape[3] // (2 ** i) # h,w下采样2倍的原因:resunet网络中有下采样操作 因此各阶段对比的输出为上一阶段的2倍下采样,对应的label也需要下采样来匹配
gt = F.interpolate(gt, size=[h, w], mode='bilinear', align_corners=False) # 降采样
gt = gt.long().squeeze(1) # 降维 [C H W]
gts.append(gt)
loss_list = compute_loss_list(self.criterion, outputs, gts) # 计算4个层分别的loss
for iloss in loss_list:
loss += iloss # 算总loss
self.optimizer.zero_grad() # 清空梯度,方便下面梯度积累
loss.backward() # 反向传播计算梯度
self.optimizer.step() # 根据累计的梯度更新网络参数
losses.update(loss.item(), volume_batch.size(0)) # loss.item() 降低计算 更新参数 计算定量值
return losses.avg # 返回平均loss
'''下面为一个传统batch训练过程:和上面的过程并无二至'''
# self.net.train() # 开始训练
# losses = AverageMeter()
# for i, (images, target) in enumerate(train_loader):
# # 1. input output
# images = images.cuda(non_blocking=True)
# target = torch.from_numpy(np.array(target)).float().cuda(non_blocking=True) # 单阶段的训练
# outputs = model(images)
# loss = criterion(outputs, target)
#
# # 2.1 loss regularization
# loss = loss / accumulation_steps # 不一定会有
# # 2.2 back propagation
# loss.backward() # 反向传播计算梯度
# # 3. update parameters of net
# if ((i + 1) % accumulation_steps) == 0:
# # optimizer the net
# optimizer.step() # update parameters of net
# optimizer.zero_grad() # reset gradient代码中需要注意的一些部分
(1).AverageMeter类
这个类是深度学习中来管理一些变量的更新,由类中的update方法来实现,具体代码如下:
class AverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self):
self.reset()
'''损失函数初始化(置零)'''
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
'''更新参数,计算平均'''
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count代码中设置这个类主要是对所有batch取平均,对医疗影像分割任务来说,这并不是一个好的策略,应该对一个batch内的所有图片loss取平均更好
(2).深监督(DeepS)
深监督是为一种辅助学习策略,通过中间层某阶段的处理与label的loss计算来判断图的好坏,为后续的模型处理过程的优劣提供判断基础,示例过程如下:
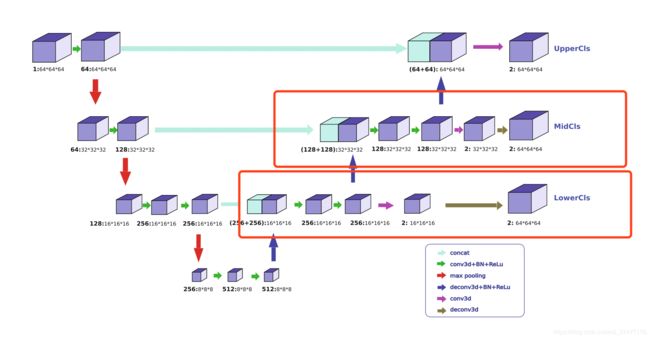
由于网络中有最大池化操作,代码中网络将label降采样对应到网络各阶段输出,这也可以帮助我们更好地了解到哪些训练样本是bad example。
1.2.6 验证过程
def val(self):
'''a) model.eval(),不启用 BatchNormalization 和 Dropout。此时pytorch会自动把BN和DropOut固定住,不会取平均,而是用训练好的值。不然的话,一旦test的batch_size过小,很容易就会因BN层导致模型performance损失较大;
b) model.train() :启用 BatchNormalization 和 Dropout。 在模型测试阶段使用model.train() 让model变成训练模式,此时 dropout和batch normalization的操作在训练起到防止网络过拟合的问题。'''
self.net.eval() # 开启验证模式
val_losses = AverageMeter() # 载入参数
'''关闭梯度计算'''
with torch.no_grad():
for i_batch, sampled_batch in enumerate(self.val_loader):
volume_batch, label_batch = sampled_batch['image'], sampled_batch['label']
volume_batch, label_batch = volume_batch.cuda(), label_batch.cuda()
outputs = self.net(volume_batch)
'''深监督 输出有4层 outputs[0]为最后的输出'''
if self.opt.train['deeps']:
outputs = outputs[0]
'''算Diceloss'''
val_loss = DiceLoss()(outputs, label_batch)
'''更新参数'''
val_losses.update(val_loss.item(), outputs.size(0))
return val_losses.avg1.2.7 运行过程
训练过程运行代码如下:
def run(self):
num_epoch = self.opt.train['train_epochs']
self.logger.info("=> Initial learning rate: {:g}".format(self.opt.train['lr']))
self.logger.info("=> Batch size: {:d}".format(self.opt.train['batch_size']))
self.logger.info("=> Number of training iterations: {:d} * {:d}".format(num_epoch, int(len(self.train_loader))))
self.logger.info("=> Training epochs: {:d}".format(self.opt.train['train_epochs']))
dataprocess = tqdm(range(self.opt.train['start_epoch'], num_epoch)) # 进度条
best_val_loss = 100.0
for epoch in dataprocess:
'''记录状态'''
state = {'epoch': epoch + 1, 'state_dict': self.net.state_dict(), 'optimizer': self.optimizer.state_dict()}
'''训练batch+计算loss'''
train_loss = self.train()
'''验证+计算loss'''
val_loss = self.val()
self.scheduler.step() # 更新学习率 epoch更新1次
self.logger_results.info('{:d}\t{:.4f}\t{:.4f}'.format(epoch+1, train_loss, val_loss))
if val_loss < best_val_loss:
best_val_loss = val_loss
save_bestcheckpoint(state, self.opt.train['save_dir'])
print(f'save best checkpoint at epoch {epoch}')
if (epoch > self.opt.train['train_epochs'] / 2.) and (epoch % self.opt.train['checkpoint_freq'] == 0):
save_checkpoint(state, epoch, self.opt.train['save_dir'], True)
logging.info("training finished")二、 后续
这篇论文的目的就是总结医疗影像分割中常见的训练、测试策略,所以其开源代码中各部分模块都可以直接应用到其余类似范畴的代码中,在之后将继续说明2DUnet的测试部分代码,由于本人仅为刚入门的新手,如有纰漏,希望各位能在评论区不吝赐教