Linux文本处理工具
感谢阅读!
本篇博客主要介绍如下内容
PS:其中的课件都是来源于我的恩师邵娇芳老师的课堂ppt,借用过来写博客她应该不会怪我吧~嘿嘿


awk:
- 文本级数据处理编程语言
- 可获取并打印特定内容
- 名字来源于。。。。
awk 语法规则
- awk [options] -f profile file
- awk [options] 'program'file
常用选项
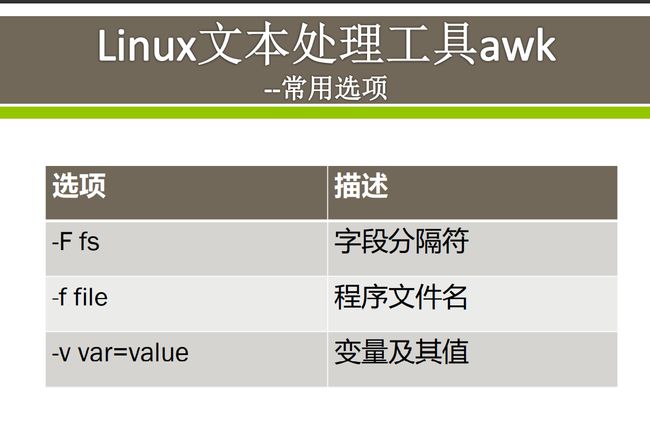
读取脚本的方式

——————————————————————————————

程序脚本中变量的各种含义

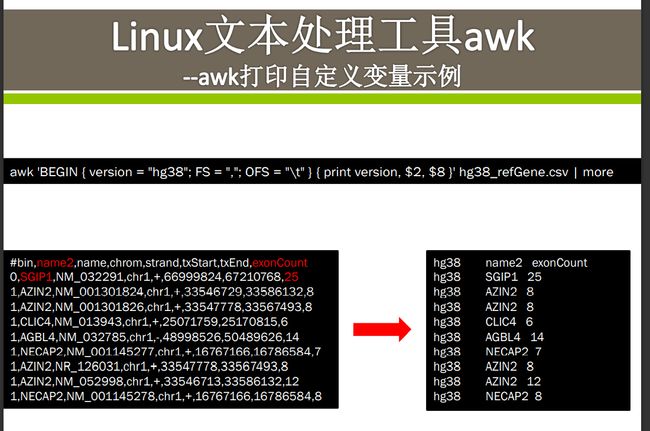
awk打印变
此处先在lab3目录 ln 一个链接,相当于复制文件到目录内,
FS=","辨识原信息中逗号,把信息分隔开来,分成按需序号排列的信息模块,之后第二个大括号内的$2则代表第二个模块的内容 |代表管道管道符(匿名管道)是Shell编程经常用到的通信工具。. 管道符是" | ",主要是把两个应用程序连接在一起,然后把第一个应用程序的输出,作为第二个应用程序的输入。. 如果还有第三个应用程序的话,可以把第二个程序的输出,作为第三个应用程序的输入,以此类推。
自定义变量名规则

自定义变量的操作
自定义变量的其他方式

运算法则和匹配


单引号双引号的区别和应用

sed语法规则
sed [OPTION]{script}[input-file]
常用选项

脚本中常用内容
a text:在每行后面加上新行text
i text :在每行前面加上新行text
r filename:在每行后面加上filename中的所有内容
R filename:在每行后面依次加上一行filename中的内容
d :删除
p:打印
s/pattern/repalce_string/ :把pattern替换成replace_string
w filename :另存为
打印实例
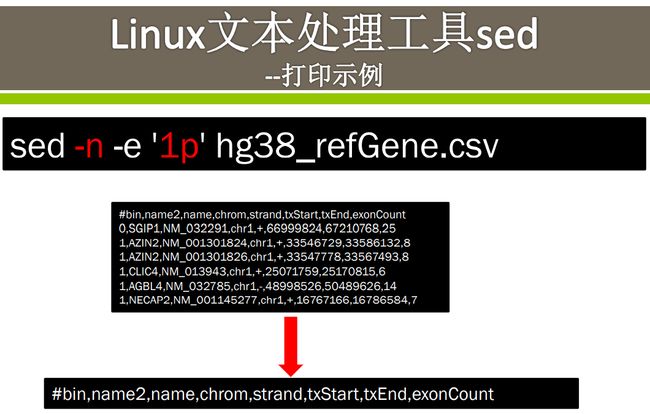
这里的-n是必须的,不然会把内容先一行一行打印出来
插入文本内容实例

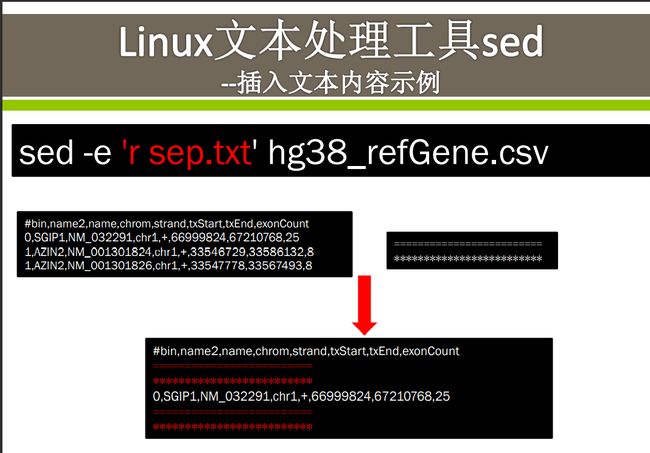
这里要注意一下有r和没有r的区别
寻址

存储示例

存放在aaa中
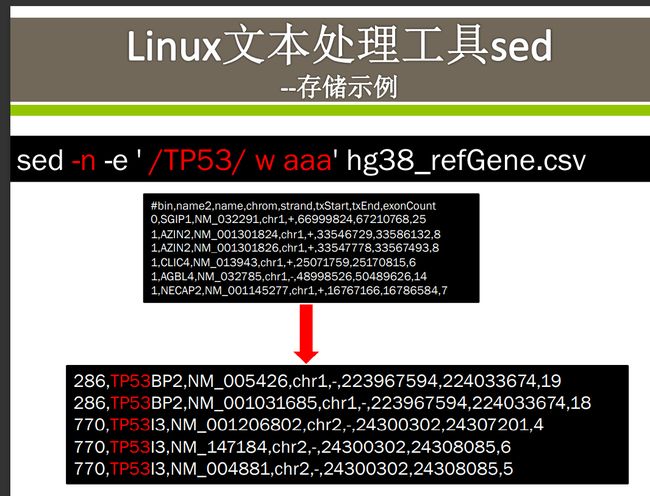
查找以TP53开头的数据并存放在文件aaa中
替换脚本
形式
s/pattern/repalce_string/flags
flag
- 数字:第几行模式匹配的地方
- g :替换所有
- p :打印原来的行
- w filename:替换的结果写到文件filename中
替换示例

- 替换每一行的第一个字符
- 替换每一行所有pattern
- 从第m行到第n行替换
- 在同一个文件中替换并保存
单引号双引号的区别(?)

a=foobar是shell的变量赋值,a是变量名,它等于foobar,后面可以直接引用。

grep
- global regular expression print
- 文本搜索工具
grep语法规则
-a --text #不要忽略二进制的数据。
-A<显示行数> --after-context=<显示行数> #除了显示符合范本样式的那一列之外,并显示该行之后的内容。
-b --byte-offset #在显示符合样式的那一行之前,标示出该行第一个字符的编号。
-B<显示行数> --before-context=<显示行数> #除了显示符合样式的那一行之外,并显示该行之前的内容。
-c --count #计算符合样式的列数。
-C<显示行数> --context=<显示行数>或-<显示行数> #除了显示符合样式的那一行之外,并显示该行之前后的内容。
-d <动作> --directories=<动作> #当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
-e<范本样式> --regexp=<范本样式> #指定字符串做为查找文件内容的样式。
-E --extended-regexp #将样式为延伸的普通表示法来使用。
-f<规则文件> --file=<规则文件> #指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。
-F --fixed-regexp #将样式视为固定字符串的列表。
-G --basic-regexp #将样式视为普通的表示法来使用。
-h --no-filename #在显示符合样式的那一行之前,不标示该行所属的文件名称。
-H --with-filename #在显示符合样式的那一行之前,表示该行所属的文件名称。
-i --ignore-case #忽略字符大小写的差别。
-l --file-with-matches #列出文件内容符合指定的样式的文件名称。
-L --files-without-match #列出文件内容不符合指定的样式的文件名称。
-n --line-number #在显示符合样式的那一行之前,标示出该行的列数编号。
-q --quiet或--silent #不显示任何信息。
-r --recursive #此参数的效果和指定“-d recurse”参数相同。
-s --no-messages #不显示错误信息。
-v --revert-match #显示不包含匹配文本的所有行。
-V --version #显示版本信息。
-w --word-regexp #只显示全字符合的列。
-x --line-regexp #只显示全列符合的列。
-y #此参数的效果和指定“-i”参数相同。
grep [OPTIONS] PATTERN

示例

who的运用
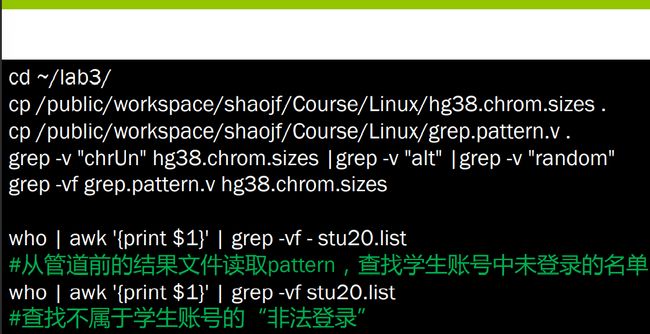
三剑客小结

sort命令的书写
语法及其常用参数格式
sort [-bcfMnrtk][源文件][-o 输出文件]
补充说明:sort可针对文本文件的北荣,以行为单位来排序。
参数(用法,指令)
-b 忽略每行前面开始出的空格字符。
-c 检查文件是否已经按照顺序排序
-f 排序时,忽略大小写字母。
-M 将前面3个字母依照月份的缩写进行排序
-n 依照数值的大小进行排序
-o<输出文件> 将排序后的结果存入指定的文件
-r 以相反的顺序来排序
-t<分隔字符> 指定排序时所用的栏位分隔字符
-k 选择以哪个区间进行排序
举例
(1)sort
(2)sort的-u选项
(3)sort的-r选项
(5)sort的-o选项
但如果是将排序结果输出到原文件中,用重定向就不行了
例如:
这么做之后,number这个文件将被清空
就在这个时候,-o选项出现了,它完美地解决了这个问题,让你放心的将结果写入原文件,
这就是为什么-o比重定向优势的原因
例如:
(6)sort的-n选项
我们会经常遇到排序下来10比2“小”的情况。
出现这种情况主要是由于排序程序将这些数字按照字符来排序了,排序程序会先比较1和2,显然1比2小,所以就将10放在2前面,这也是sort一贯的作风。
我们如果想改变这种现状,就要使用-n选项,来告诉sort,“要以数值来排序”!
(7)sort的-t选项
(8)cat file1 file2 | sort
合并两个文件并排序
(9)sort -k n
按第n个key排序
(10)其他的sort常用选项
-f会将小写字母都转化为大写字母来进行比较,即忽略大小写
-c会检查文件是否排好序,如果乱序,则输出第一个乱序的行的相关信息,最后返回1
-C会检查文件是否已经排好序,如果乱序,不输出内容,仅返回1
-M会以月份来排序,比如JAN小于FEB等等
-b会忽略每一行前面的所有空白部分,从第一个可见字符开始比较。
课件示例
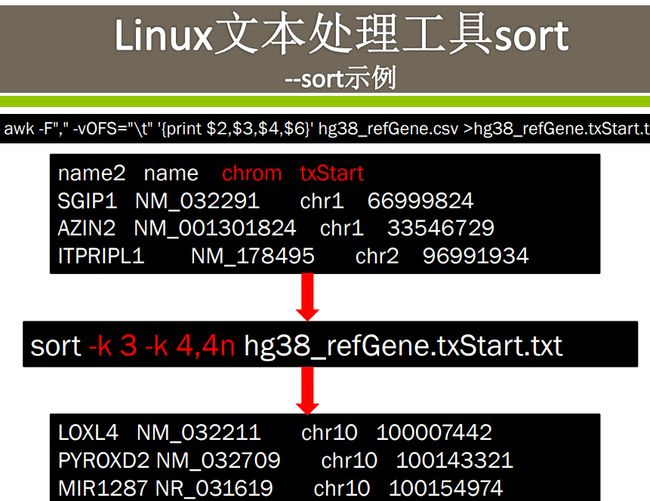
问:这里的k3 和k4 的含义是指先排序key3再排列key4?最后的4n是啥意思嘞?
先按第3列排序 如果第3列相同 则按第4列排序。第四列按照数值大小排序,而第三列则按字典顺序排,例如1 10 11 12……2 20 21 22……3这样的顺序
uniq:去除重复
uniq用法:uniq [option]
语法:uniq [-cdu][-f][-s][-w][--help][--version][输入文件][输出文件]
参数
-c或--count 在每列旁边显示该行重复出现的次数。
-d或--repeated 仅显示重复出现的行列。
-f或--skip-fields= 忽略比较指定的栏位。
-s或--skip-chars= 忽略比较指定的字符。
-u或--unique 仅显示出一次的行列。
-w或--check-chars= 指定要比较的字符。
--help 显示帮助。
--version 显示版本信息。
示例
[输入文件] 指定已排序好的文本文件。
[输出文件] 指定输出的文件。
文件testfile中第2 行、第5 行、第9 行为相同的行,使用uniq 命令删除重复的行,可使用以下命令:
uniq testfile
testfile中的原有内容为:
$ cat testfile #原有内容
test 30
test 30
test 30
Hello 95
Hello 95
Hello 95
Hello 95
Linux 85
Linux 85
使用uniq 命令删除重复的行后,有如下输出结果:
$ uniq testfile #删除重复行后的内容
test 30
Hello 95
Linux 85
检查文件并删除文件中重复出现的行,并在行首显示该行重复出现的次数。使用如下命令:
uniq-c testfile
结果输出如下:
$ uniq-ctestfile #删除重复行后的内容
3 test 30 #前面的数字的意义为该行共出现了3次
4 Hello 95 #前面的数字的意义为该行共出现了4次
2 Linux 85 #前面的数字的意义为该行共出现了2次
补充
linux中的uniq命令的常见例子
当你有一个包含相同条目的雇员(employee)的文件,你可以以如下方式来删除相同的条目
$ sort namesd.txt | uniq
$ sort –u namesd.txt
如果你想知道有多少行是相同的,可以像下面这个做。以下例子中的第一列显示该行的重复数量。在本例中,以Alex和Emma开头的行,在文件中有两个重复行。
$ sort namesd.txt | uniq –c
2 Alex Jason:200:Sales
2 Emma Thomas:100:Marketing
1 Madison Randy:300:Product Development
1 Nisha Singh:500:Sales
1 Sanjay Gupta:400:Support
以下命令仅仅列出了相同的条目
$ sort namesd.txt | uniq –cd
2 Alex Jason:200:Sales
2 Emma Thomas:100:Marketing
cut提取特定列
用法
- cut -c list
剪下list所列的字符 - cut -f list
剪下list所列的field

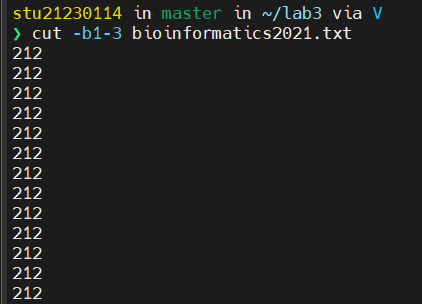
cut示例
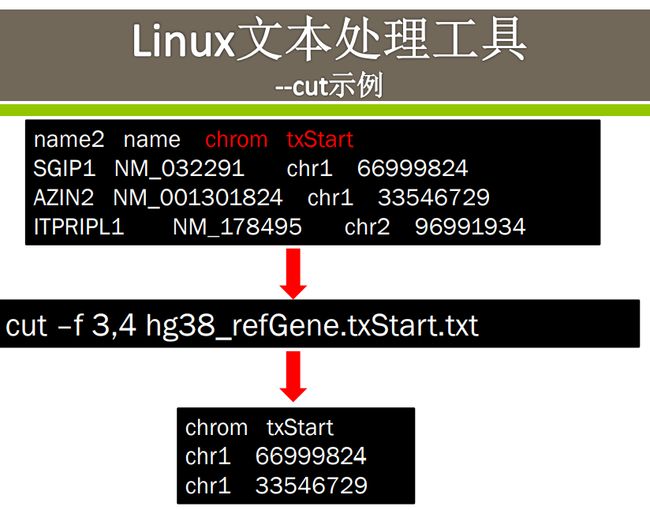
要显示字段的某个范围,可以指定开始和结束的字段,中间用连字符(-)连接,如下所示:

paste
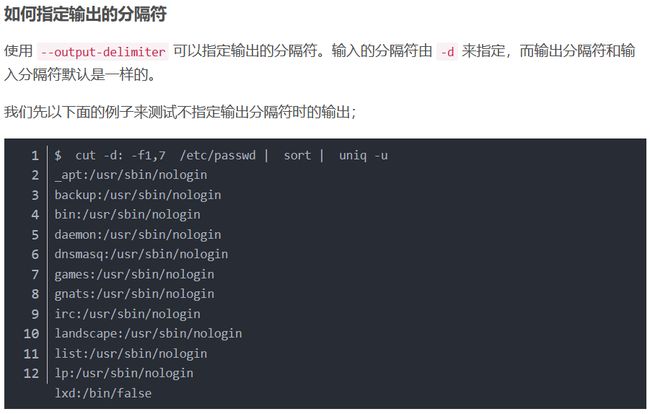
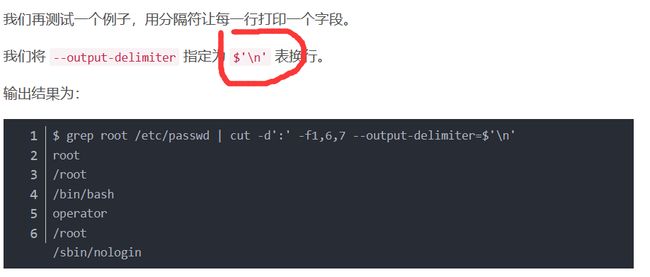
使用注意事项
粘贴两个不同来源的数据时,首先需将其分类,并确保两个文件行数相同。paste将按行将不同文件行信息放在一行。缺省情况下, paste连接时,用空格或tab键分隔新行中不同文本,除非指定-d选项,它将成为域分隔符。
paste选项及其含义
paste -d -s -file1 file2
-d 指定不同于空格或tab键的域分隔符。例如用@分隔域,使用- d @。
-s 将每个文件合并成行而不是按行粘贴。
- 使用标准输入。例如ls -l |paste ,意即只在一列上显示输出。
示例
#cat pas1
ID897
ID666
ID982
#cat pas2
P.Jones
S.Round
L.Clip
基本paste命令将pas1和pas2两文件粘贴成两列:
# paste pas1 pas2
ID897 P.Jones
ID666 S.Round
ID982 L.Clip
通过交换文件名即可指定哪一列先粘:
# paste pas2 pas1
P.Jones ID897
S.Round ID666
L.Clip ID982
要创建不同于空格或tab键的域分隔符,使用-d选项。下面的例子用冒号做域分隔符。
# paste -d: pas2 pas1
P.Jones:ID897
S.Round:ID666
L.Clip:ID982
要合并成两行,而不是按行粘贴,可以使用-s选项。下面的例子中,第一行粘贴为ID号,第二行是名字。
# paste -s pas1 pas2
ID897 ID666 ID982
P.Jones S.Round L.Clip
join
命令概述
join命令用来将两个文件中,制定栏位内容相同的行连接起来。找出两个文件中,指定栏位内容相同的行,并加以合并,再输出到标准输出设备。
注意:join在对两个文件进行连接时,两个文件必须都是按照连接域排好序的,按其他域排序是无效的。
命令格式
用法:join [选项]... 文件1 文件2
常用选项
针对每一对具有相同内容的输入行,整合为一行写到标准输出,
默认的内容连接区块是由第一个空白符代表的分界符号。当文件1
或文件2 都被指定为"-"时,程序将从标准输入读取数据。
-a 文件编号 文件编号的值可以是1 或2,分别对应文件1 和 文件2。
此选项用于根据指定文件编号输出不成对的行目。
-e 字符 将缺失的输入区块替换为指定字符
-i, --ignore-case 比较时忽略大小写
-j 域 等于"-1 域 -2 域"
-o 格式 按照指定格式构造输出行
-t 字符 使用指定字符作为输入和输出的分隔符
-v 文件编号 类似 -a 文件编号,但禁止组合输出行
-1 域 在文件1 的此域组合
-2 域 在文件2 的此域组合
--check-order 检查输入行是否正确排序,即使所有输入行均是成对的
--nocheck-order 不检查输入是否正确排序
--header 将首行视作域的头部,直接输出而不对其进行匹配
--help 显示此帮助信息并退出
--version 显示版本信息并退出
除非使用了"-t 字符串" 选项,否则前导空格分隔的域将被忽略,如果指定了字符串,
则使用指定字符串分隔任意的域并从1 开始计数的域编号。可以指定的格式是由一个
或多个逗号活空格所分隔的描述,其形式为"文件编号.域"或者"0"。默认的
格式输出合并后的域、文件1 和文件2 剩下的域,均由该指定字符串分隔。
重要提示:文件1 和文件2 必须在合并域中排序。
例如,如果"join"后没有选项,使用"sort -k 1b,1"。
注意,所进行的比较遵从"LC_COLLATE"所指定的的规则。
如果输入没有被排序并导致某些行无法合并,将会显示警告信息。
参考示例
两个文件内容如下
[deng@localhost test]$ cat file1
1 一月
2 二月
3 三月
4 四月
5 五月
6 六月
7 七月
8 八月
9 九月
10 十月
11 十一月
12 十二月
13 十三月
[deng@localhost test]$ cat file2
1 January
2 February
3 March
4 April
5 May
6 June
7 July
8 August
9 September
10 October
11 November
12 December
14 MonthUnknown
[deng@localhost test]$
内连接(忽略不匹配的行)
[deng@localhost test]$ join file1 file2
1 一月 January
2 二月 February
3 三月 March
4 四月 April
5 五月 May
6 六月 June
7 七月 July
8 八月 August
9 九月 September
10 十月 October
11 十一月 November
12 十二月 December
[deng@localhost test]$
【此处观察可发现13和14行已不见了踪影,因为不指定任何参数的情况下使用join命令,就相当于数据库中的内连接,关键字不匹配的行不会输出。】
左/右连接(-a的用法,又称左/右外连接,显示左/右边所有记录)
显示左边文件中的所有记录,右边文件中没有匹配的显示空白。(a1中的1则代表文件1,即左边的文件)
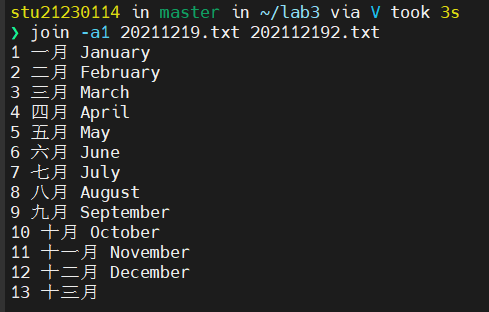
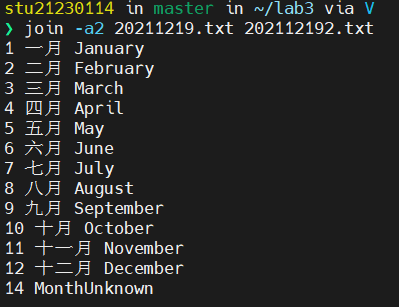
全连接(又称全外连接,显示左边和右边的所有记录)
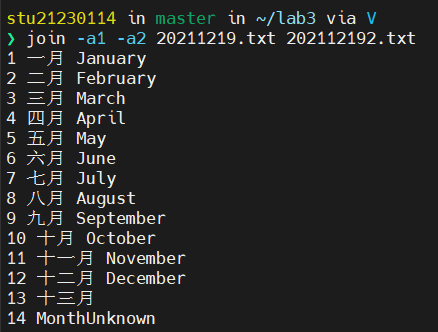
指定输出字段(-o的用法)
参数 -o 1.1 表示只输出第一个文件的第一个字段。
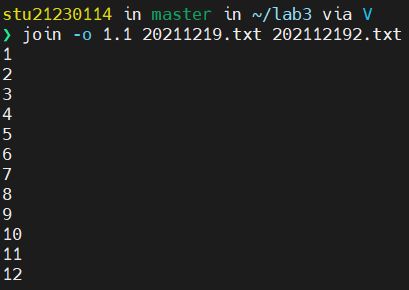
指定输出多个字段(-o的用法)
输出第一个文件的第一个字段,输出第二个文件第二个字段
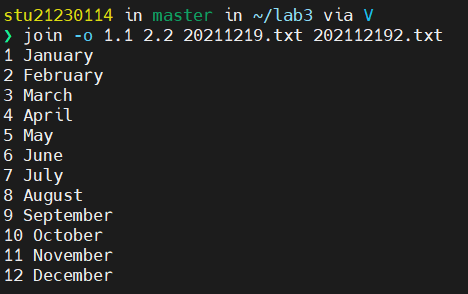
输出第一个文件的第一个字段和第二个字段,输出第二个文件第二个字段
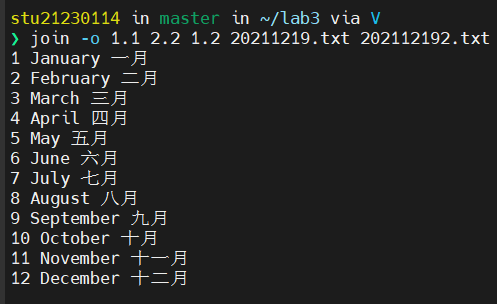
当第一个文件第三个字段不存在的情况下,自动省略“1.3”以及其后面的列
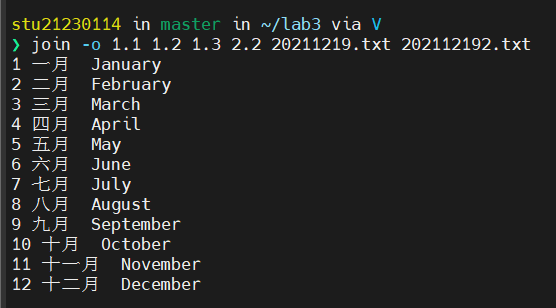
指定分隔符(-t)
指定了以两个文件中第一列做匹配字段
等同于join file1 file2
[deng@localhost test]$ join -j1 file1 file2
1 一月 January
2 二月 February
3 三月 March
4 四月 April
5 五月 May
6 六月 June
7 七月 July
8 八月 August
9 九月 September
10 十月 October
11 十一月 November
12 十二月 December
[deng@localhost test]$
指定匹配的字段
以第一个文件的第二列和第二个文件的第三列做匹配字段。由于第二个文件中第三列的两个3 都与第一个文件中第三行因此输出
[deng@localhost test]$ join -1 1 -2 2 file1 file2
join: file1:10: is not sorted: 10 十月
join: file2:2: is not sorted: 2 February
[deng@localhost test]$
指定字符的补全
-o 指定 将file1的1,2列,file2的1,2 列都输出。-a指定将file1中不匹配的行也输出,但是file2中没有与file1后两行对应的字段,因此使用empty补齐
[deng@localhost test]$ join -o 1.1 1.2 2.1 2.2 -e 'empty' -a1 file1 file2
1 一月 1 January
2 二月 2 February
3 三月 3 March
4 四月 4 April
5 五月 5 May
6 六月 6 June
7 七月 7 July
8 八月 8 August
9 九月 9 September
10 十月 10 October
11 十一月 11 November
12 十二月 12 December
13 十三月 empty empty
[deng@localhost test]$
不匹配的行输出
[deng@localhost test]$ join -v 1 -a1 -a2 file1 file2
13 十三月
14 MonthUnknown
[deng@localhost test]$
结合管道使用
有时我们需要将多个格式相同的文件join到一起,而join接受的是两个文件的指令,此时我们可以使用管道和字符“-"来实现
[deng@localhost test]$ join file1 file2 | join - file2 | join - file1
1 一月 January January 一月
2 二月 February February 二月
3 三月 March March 三月
4 四月 April April 四月
5 五月 May May 五月
6 六月 June June 六月
7 七月 July July 七月
8 八月 August August 八月
9 九月 September September 九月
10 十月 October October 十月
11 十一月 November November 十一月
12 十二月 December December 十二月
[deng@localhost test]$

split(分割文件)
Split:按指定的行数截断文件
格式: split [-n] file [name]
参数说明:
-n: 指定截断的每一文件的长度,不指定缺省为1000行
file: 要截断的文件
name: 截断后产生的文件的文件名的开头字母,不指定,缺省为x,即截断后产生的文件的文件名为xaa,xab....直到xzz
例一:
split -55 myfile ff
将文件myfile依次截断到名为ffaa,ffab,ffac.....的文件中,每一文件的长度为55行
按文件大小分割
[root@pps public_rw]# split -b 20m 文件名称
[root@pps public_rw]# ls -lh
总计 552M
-rwx------ 1 hoho hoho 276M 2005-09-09 RevolutionOS.rmvb
-rw-r--r-- 1 root root 20M 03-19 17:59 RevOS_part_aa
-rw-r--r-- 1 root root 20M 03-19 17:59 RevOS_part_ab
...
-rw-r--r-- 1 root root 20M 03-19 18:00 RevOS_part_am
-rw-r--r-- 1 root root 16M 03-19 18:00 RevOS_part_an
“-b 20m”指定分割文件的大小为20M,文件后面的“RevOS_part_”是分割文件的前缀,最后的是16M的“剩余”文件。
组装文件:
[root@pps public_rw] cat RevOS_part_* > RevolutionOS_RSB.rmvb
这里不怕组装顺序错误,因为分割的时候是按字母顺序排下来的,cat也是按照字母顺序处理的,如果不放心,将组装后的文件哈希对比一下:
[root@pps public_rw]# md5 sum RevolutionOS.rmvb
ac7cce07f621b1ed6f692e6 df0ac8c16 RevolutionOS.rmvb
[root@pps public_rw]# md5sum RevolutionOS_RSB.rmvb
ac7cce07f621b1ed6f692e6df0ac8c16 RevolutionOS_RSB.rmvb
放心了吧:)
如果要分割的是一个文本文件,比如有好几千行,当然每行的字符数是不等的,想要以行数为分割,比如每100行生成1个文件,只需要 -l 参数,如下:
[root@pps public_rw]# split -l 100 test.txt
其实,如果不加任何参数,默认情况下是以1000行大小来分割的。
diff
diff(选项)(参数)
选项
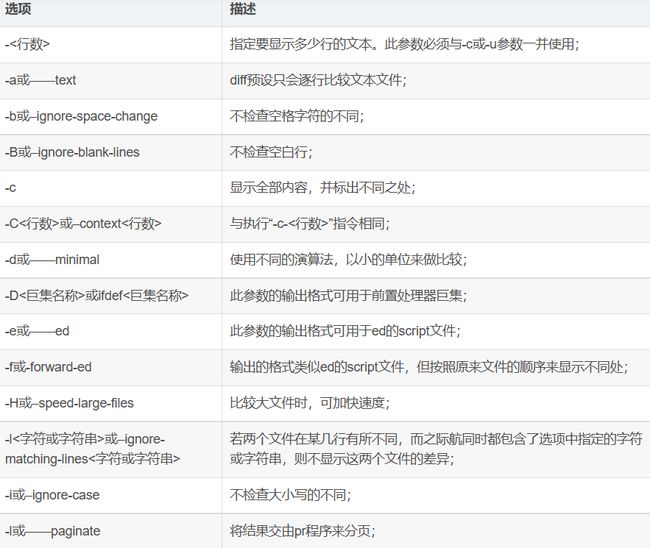
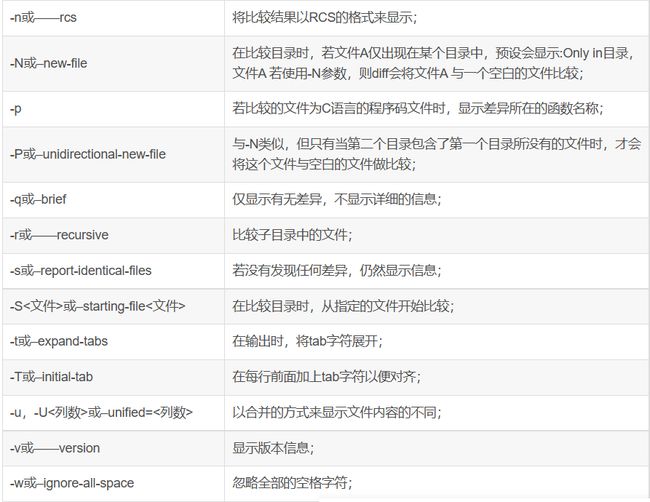
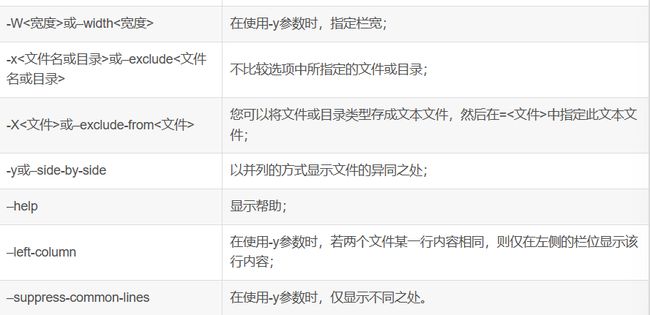
示例
比较log2014.log log2013.log
[root@localhost test3]# diff log2014.log log2013.log
3c3
< 2014-03
---
> 2013-03
8c8
< 2013-07
---
> 2013-08
11,12d10
< 2013-11
< 2013-12
上面的"3c3"和"8c8"表示log2014.log和log20143log文件在3行和第8行内容有所不同;"11,12d10"表示第一个文件比第二个文件多了第11和12行。
并排格式输出
[root@localhost test3]# diff log2014.log log2013.log -y -W 50
2013-01 2013-01
2013-02 2013-02
2014-03 | 2013-03
2013-04 2013-04
2013-05 2013-05
2013-06 2013-06
2013-07 2013-07
2013-07 | 2013-08
2013-09 2013-09
2013-10 2013-10
2013-11 <
2013-12 <
[root@localhost test3]# diff log2013.log log2014.log -y -W 50
2013-01 2013-01
2013-02 2013-02
2013-03 | 2014-03
2013-04 2013-04
2013-05 2013-05
2013-06 2013-06
2013-07 2013-07
2013-08 | 2013-07
2013-09 2013-09
2013-10 2013-10
> 2013-11
> 2013-12
"|"表示前后2个文件内容有不同
"<"表示后面文件比前面文件少了1行内容
">"表示后面文件比前面文件多了1行内容
正则表达式

什么是正则表达式?
正则表达式是用于描述字符排列和匹配模式的一种语法规则。它主要用于字符串的模式分割、匹配、查找及替换操作。
正则表达式与通配符的区别
- 正则表达式用来在文件中匹配符合条件的字符串,正则是包含匹配。grep、awk、sed等命令可以支持正则表达式
- 通配符用来匹配符合条件的文件名,通配符是完全匹配。ls、find、cp这些命令不支持正则表达式,所以只能用shell自己的通配符来进行匹配
通配符的种类和作用
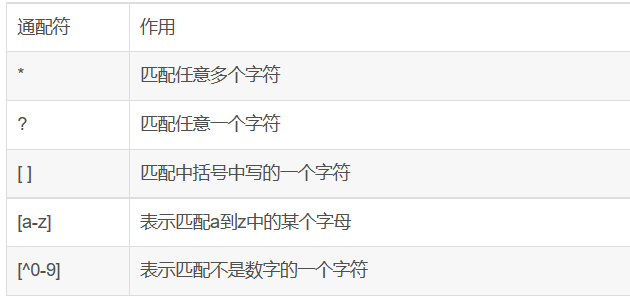
基础正则表达式
正则表达式主要分为基础正则表达式与扩展正则表达式,在linux中扩展正则表达式用得比较少,一般只用于某些特殊场合,先学习基础正则表达式的用法,日后工作如果碰到扩展正则表达式的需求再查阅读相关资料。以下这些正则表达式的元字符需要亲自在linux中反复练习,熟练掌握,日后用处极大。
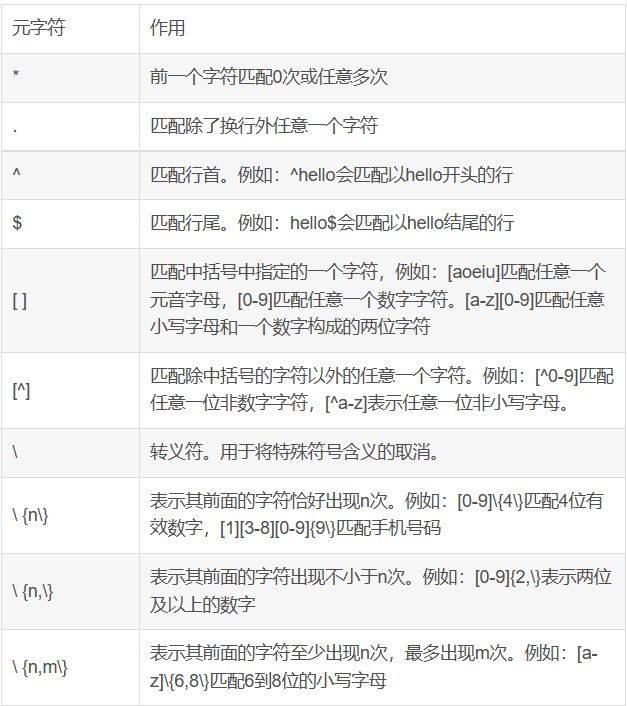
小结
