Elasticsearch-分布式搜索服务指南
一、初识es
1.了解ES

es是一款强大的开源搜索引擎,可以帮助我们从海量数据中快速找到需要的内容
es结合kibana,Logstash,Beats也就是elastic stack(ELK),被广泛应用在日志数据分析,实时监控等领域,elasticsearch是elk的核心,负责存储,搜索,分析数据
es的底层是用Lucene实现的,Lucene是一个java语言的搜索引擎类库,是Apache公司的顶级项目
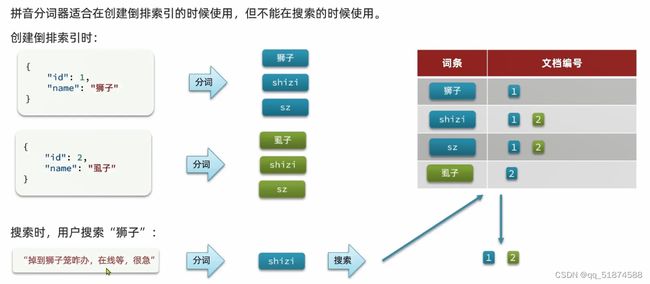
2.倒排索引
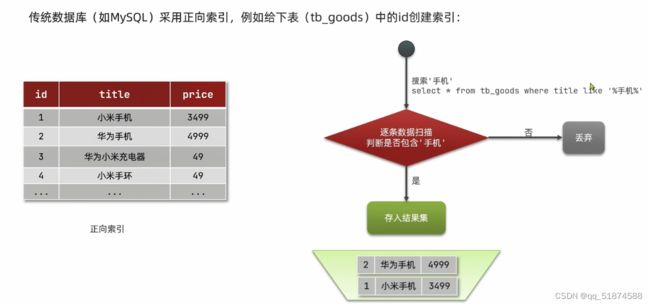
正向索引和倒排索引:
传统数据库比如mysql采用正向索引,例如给表中的id创建索引
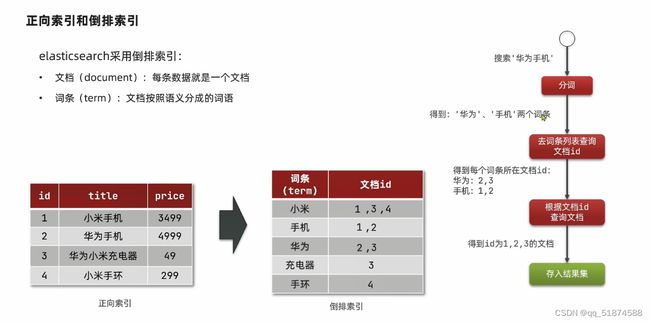
倒排索引具体存储与搜索过程与规则:
3.Es的一些概念
Es是面向文档存储的,可以是数据库中的一条商品数据,一个订单信息。文档数据会被序列化成json格式后存储在elasticsearch中

es索引:相同类型文档的集合
es映射:索引中文档的字段约束信息,类似于表的结构约束

Mysql与es存储数据的概念对比
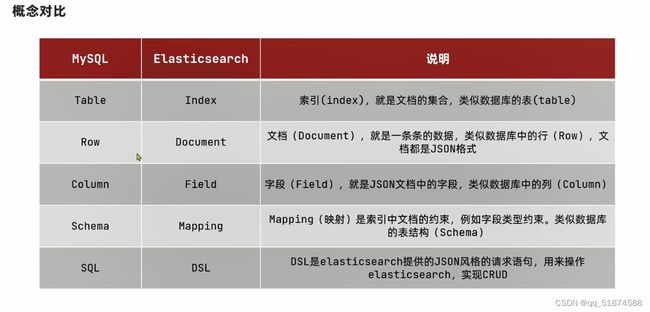
Mysql更擅长事务类型操作,可以确保数据的安全和一致性
Es更擅长海量数据的搜索、分析、计算
在后续业务的构建中,二者是起到互补的效果
4.kibana
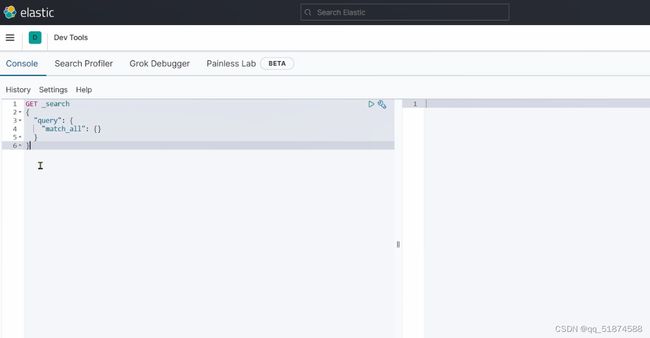
Kibana是ES提供的一个可视化的操作界面,利于我们学习ES的各种操作
Kibana安装完成之后就可以通过控制台写json语句对ES进行各种操作:
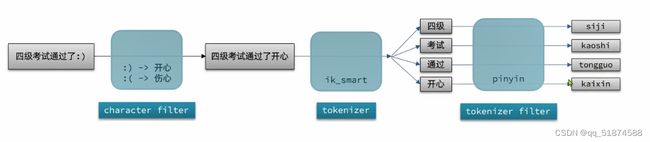
5.IK分词器
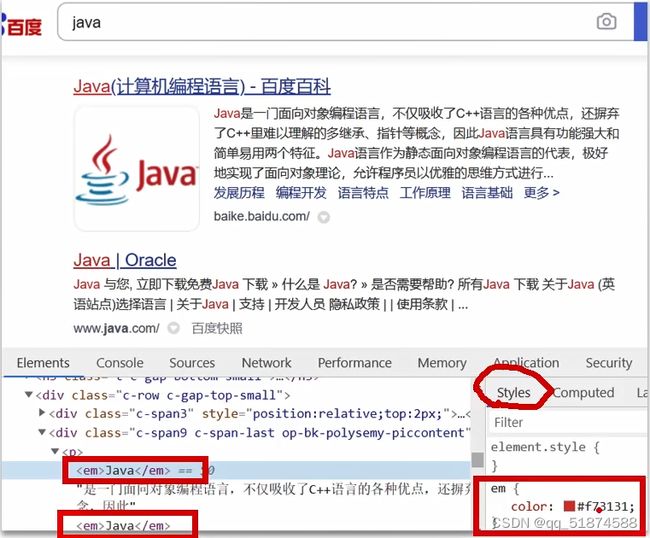
Es搜索是根据词来进行,而es的默认分词对中文的支持非常差,基本是一个字一个词
所以我们要用到IK分词器
IK分析器常用的有两种分词模式,一个是ik_smart 和 ik_max_word
前者是粗分词,字成词之后就不会进行更细的切分了,后者是细分词,会将一句话所有的词全部分出来
Ik分词器有自己的默认词典,对于一些陌生词语是不支持的,比如奥里给、白嫖之类的,这里我们可以自己来拓展词库
IK分词器支持拓展词库,需要修改ik分词器目录中的config目录中的ikAnalyzer.cfg.xml文件
Ik分词器还有更多高级用法,比如热更新之类的,可以查看ik分词器的github官方网址
二、索引库操作
1.mapping映射属性
Mapping是对索引库中文档的约束,常见的mapping属性包括
--type:字段数据类型,常见简单类型有:字符串:text(可分词的文本) , keyword(不可分词的字符串) , 数值:long,integer等 , 布尔 Boolean , 日期 date , 对象object
--index:是否创建索引(倒排索引),默认为true,我们在创建字段时常常需要设置
--分词器:analyzer:使用哪种分词器(只有text类型才用分词器)
--properties:该字段的子字段比如下面例子中的name就有子字段

2.索引库中的CRUD
Es中通过Restful请求操作索引库、文档。请求内容用DSL语句来表示。
-创建索引库和mapping的DSL语法如下(使用PUT):

-查看索引库语法:GET /索引库名
-删除索引库语法:DELETE /索引库名
-修改索引库:索引库和mapping一旦创建就无法修改,但是可以添加新的字段,语法如下:

3.索引库中的其他知识
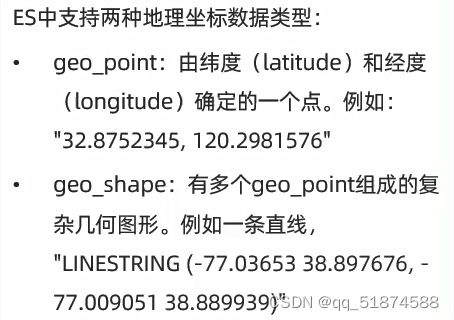
-经纬度表示geo_point类型
-copy_to关键字
在实际业务中,有时用户搜索可能会同时带有几个关键字,比如某地某品牌某类型产品一起搜索,这时就需要用到copy_to关键字段

三、文档操作
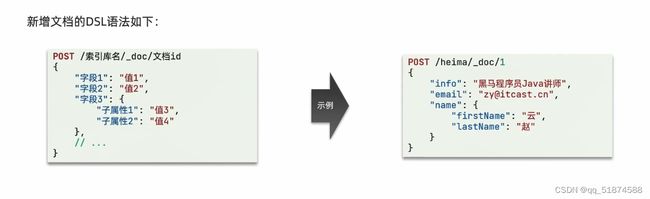
1.新增文档
2.查询文档
GET /索引库名/_doc/文档id
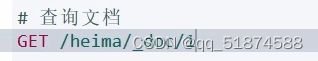
示例查询结果:
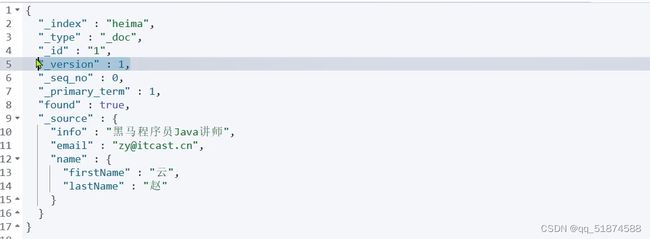
这里的version是指版本控制,文档每被修改一次,version就会+1
3.删除文档
DELETE /索引库名/_doc/文档id


注意这里删除文档也会导致文档版本变更
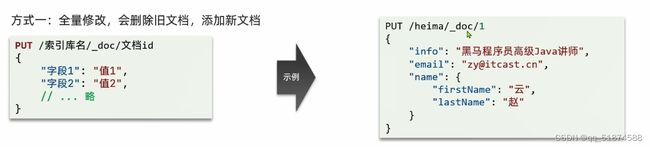
4.修改文档
-全量修改:既能修改,又能新增
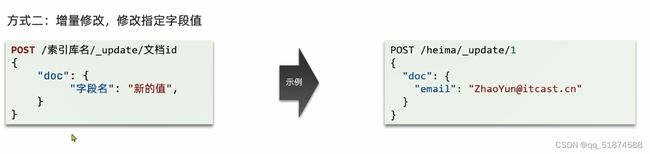
-增量修改
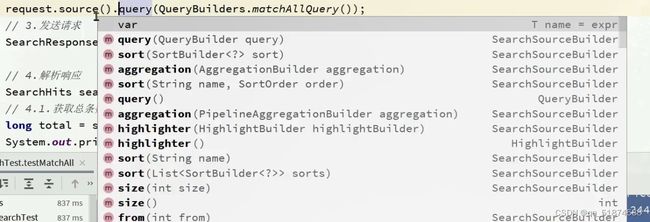
四、RestClient操作索引库
1.RestClient介绍
ES官方提供了各种不同语言的客户端,用来操作es,这些客户端的本质就是组装DSL语句,通过http请求发给ES

初始化RestClient依赖

2.RestClient对索引库的各种操作
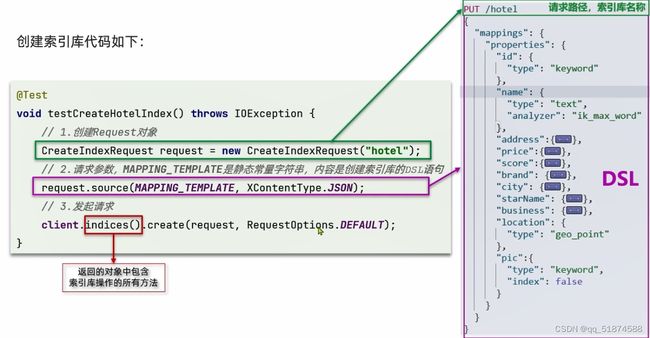
-创建索引库
-删除与查询索引库


3.RestClient对于文档的各种操作
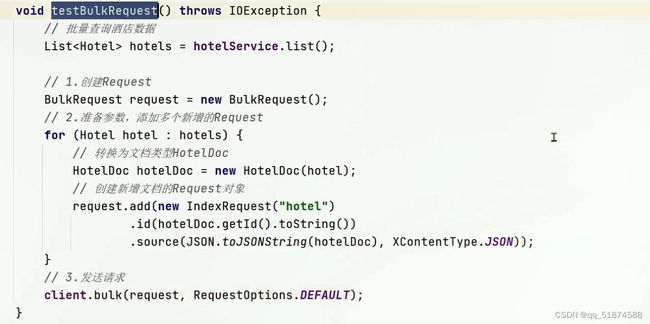
-新增文档(示例是从mysql数据库里面查过来在放到ES里面)

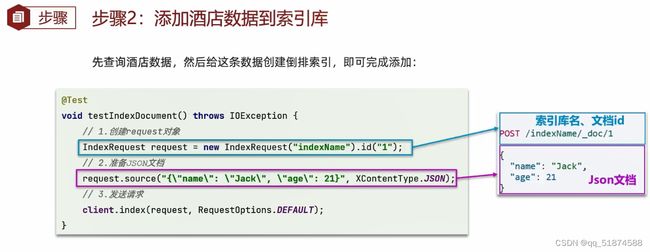
具体完整代码:

代码解释:先利用mybatis在mysql数据库中查询到hotel对象,由于hotel对象在mysql字段与ES字段略有不同,这里利用hotelDoc类将其转换为与ES文档字段一致的字段,然后利用FastJson库的toJsonString函数将对象转换成JSON对象传入source函数
-查询文档


这里使用FastJson库中的反序列化函数将Json转化为Hotel对象
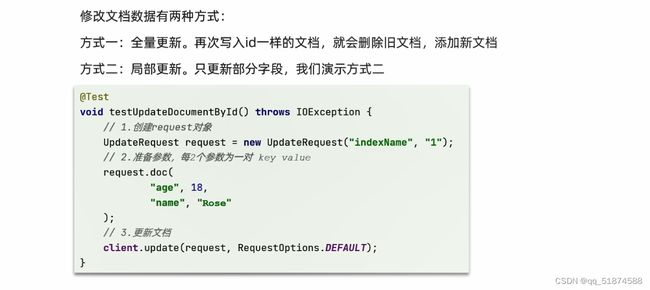
-修改文档
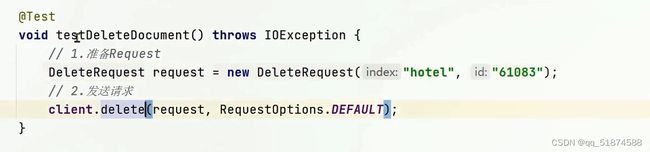
-删除文档

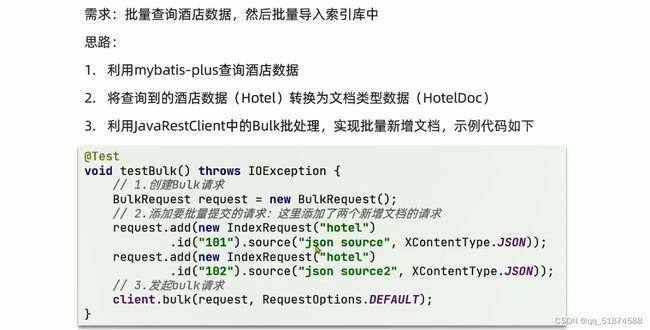
利用javaRestClient将mysql中的数据批量导入到ES中
五、ES的搜索功能
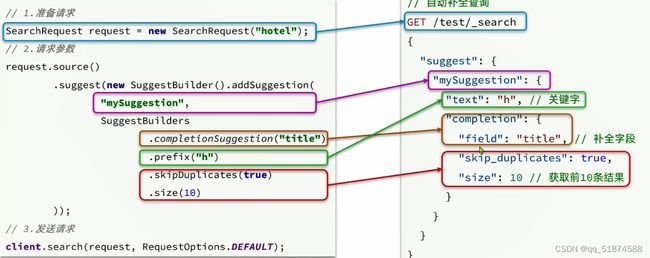
1.DSL查询文档介绍
ES提供了基于JSON的DSL来定义查询,常见的查询类型包括:

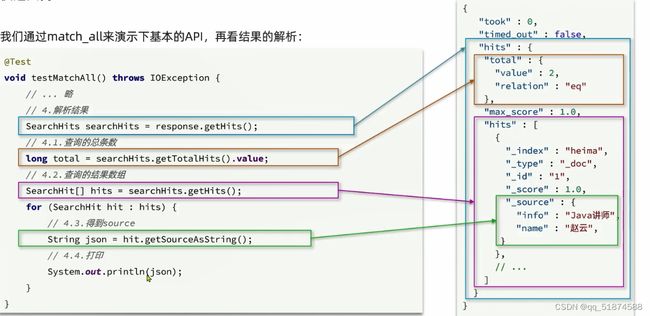
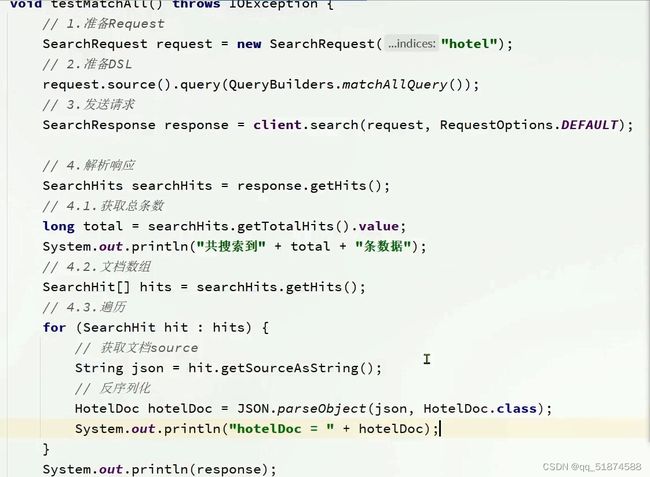
例子-查询所有:
这里只会查询一部分,是分页导致的
2.全文检索查询
全文检索查询会对用户输入内容进行分词,常用于搜索框搜索
match查询:会对用户输入内容分词,然后去倒排索引库进行检索,语法为:


multi_match查询,可以同时查询多个字段

这里搜索的结果和上面用match搜索的结果一样,因为brand、name、business字段都被包含到all字段里面去了,但一般用上面的那种搜索方式,因为搜索时字段越多,查询效率越低
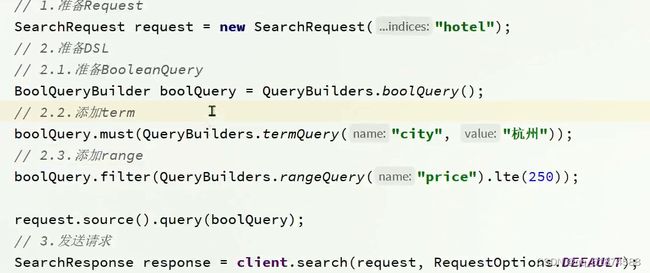
2.精确查询
精确查询一般是查找keyword、数值、日期、boolean等字段,所以不会对字段做分词
term:根据词条精确值查询 range:根据范围查询。使用案例:
![]()

这里如果写上海杭州,则没有查询结果,因为精确查询需要词条与结果词条完全一样

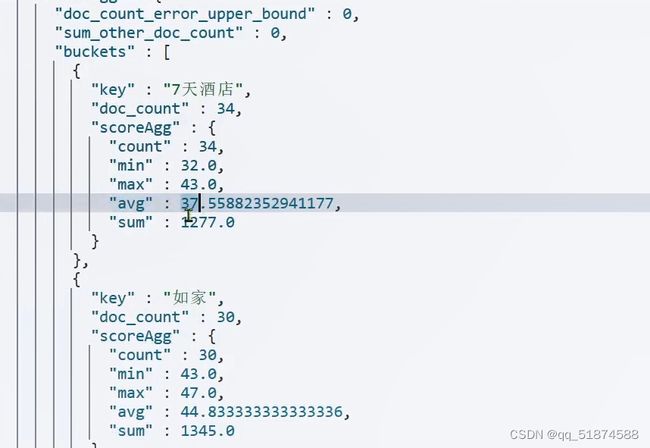
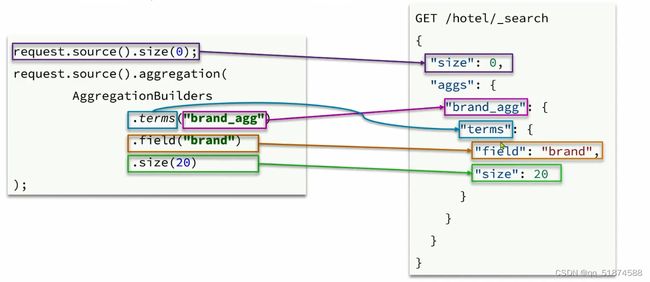
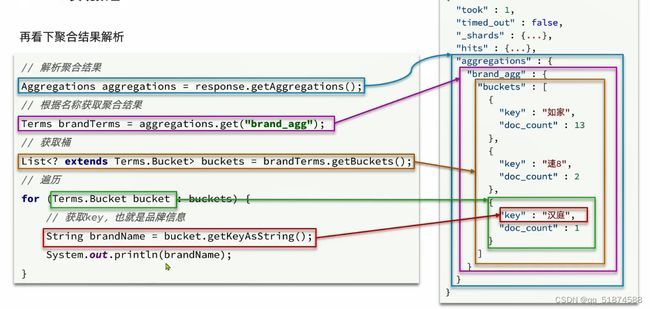
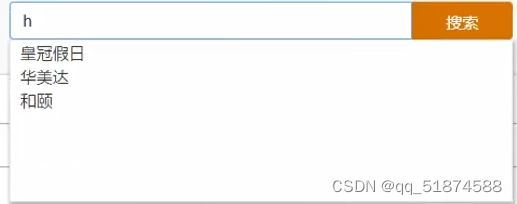
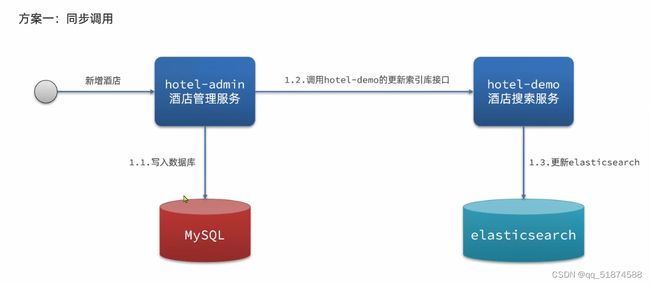
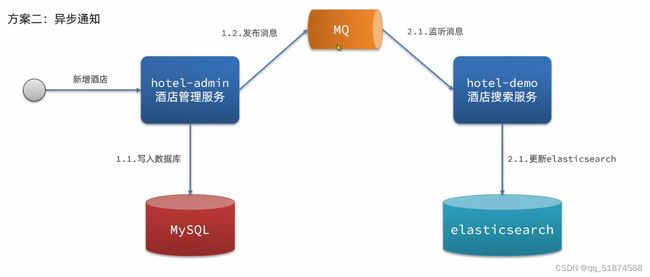
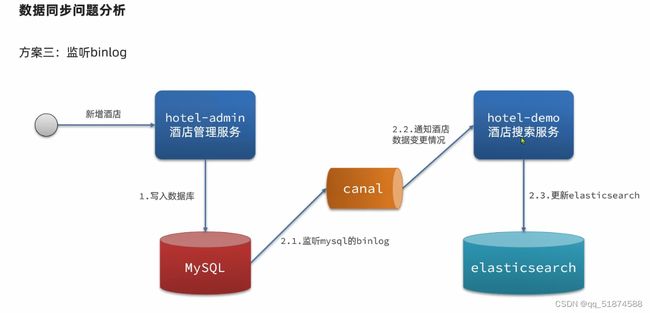
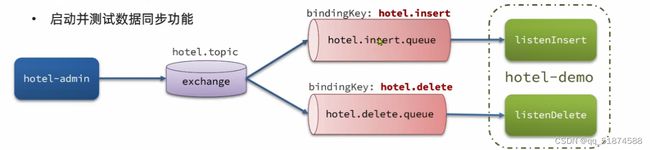
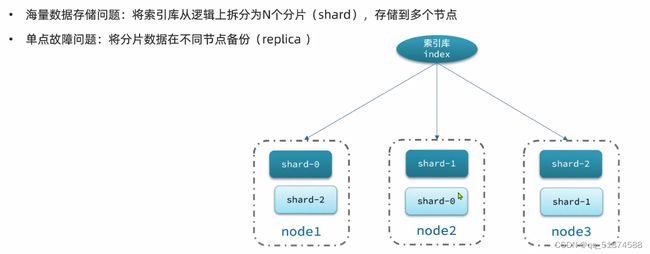
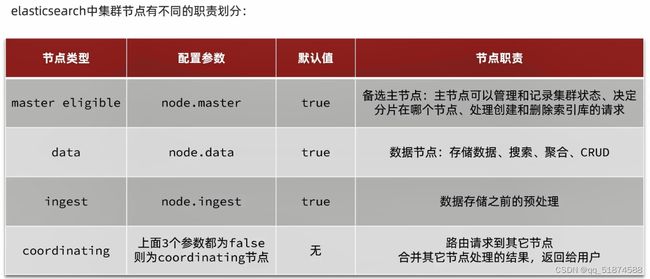
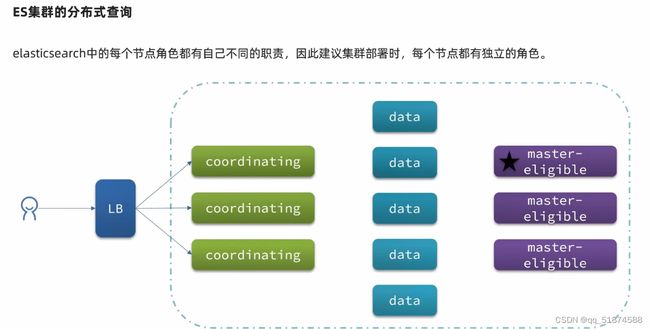
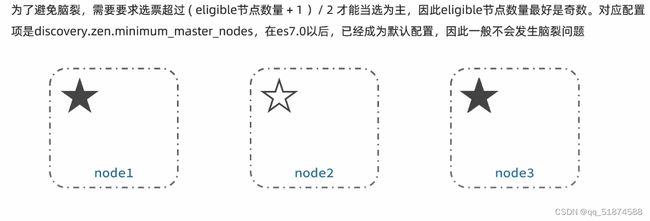
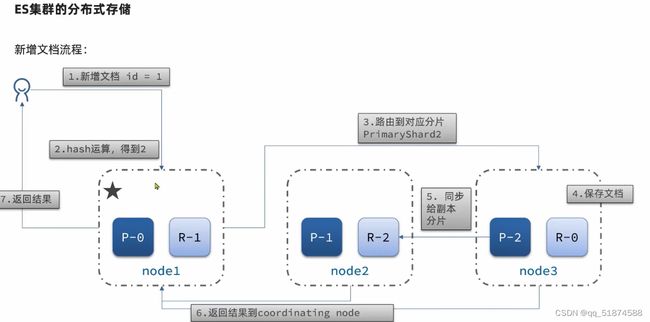
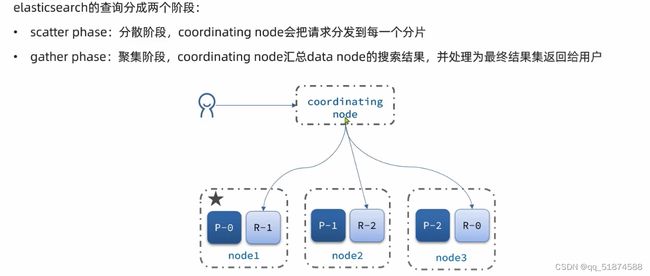
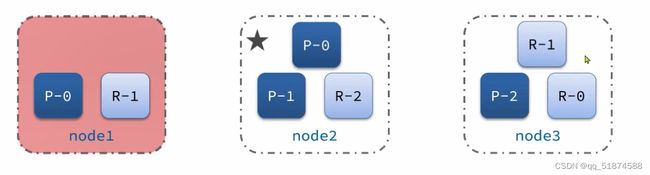
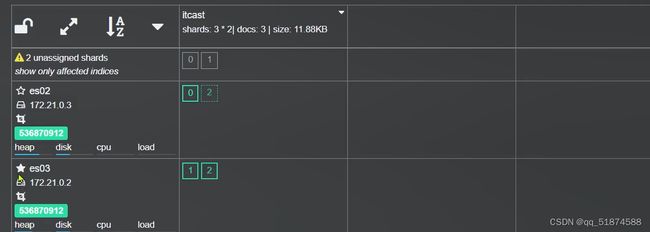
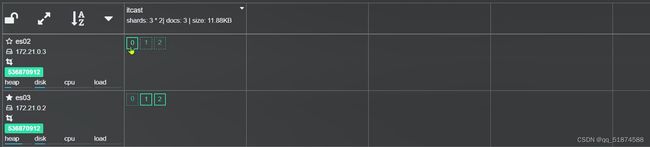
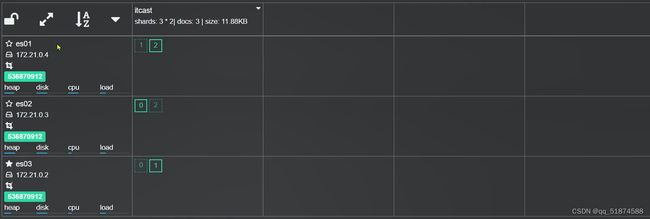
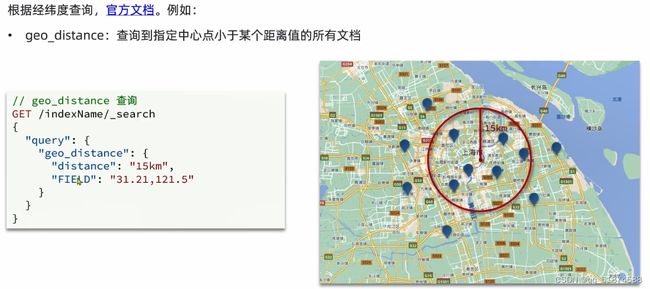
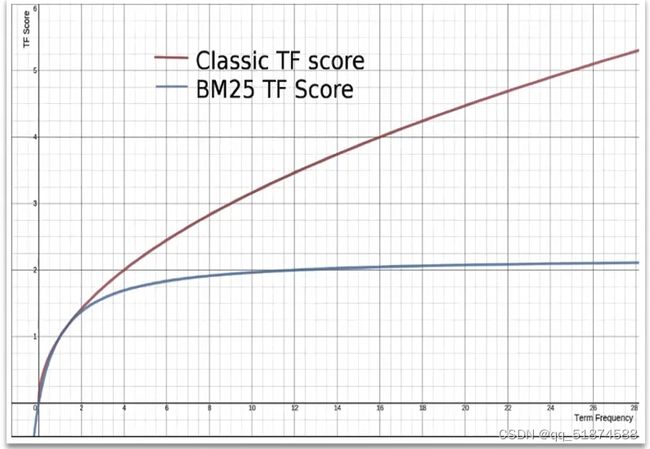
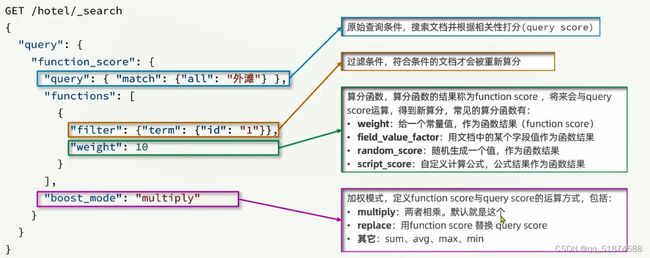
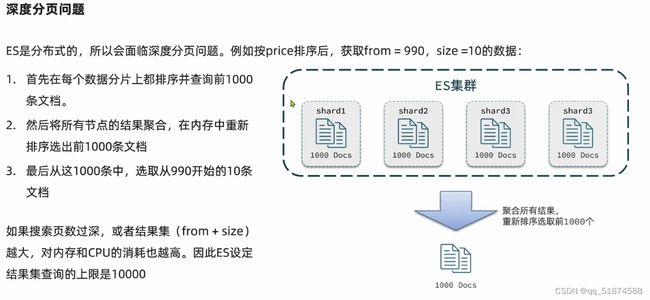
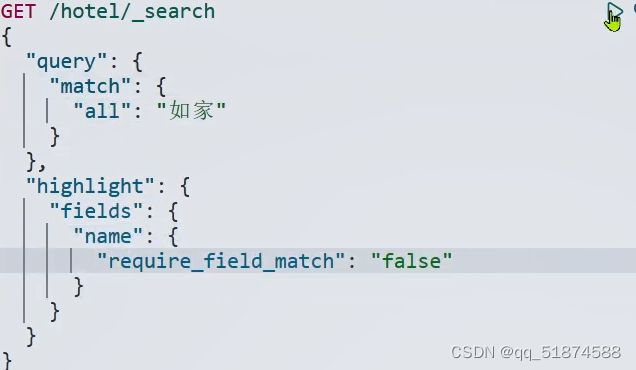
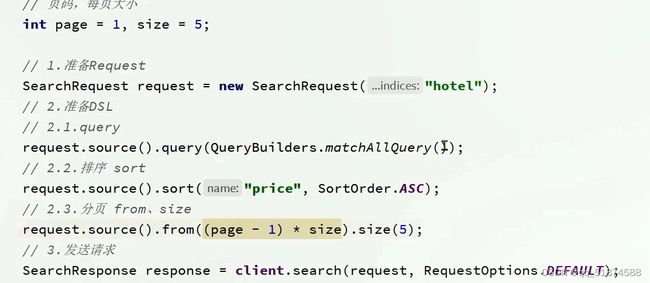
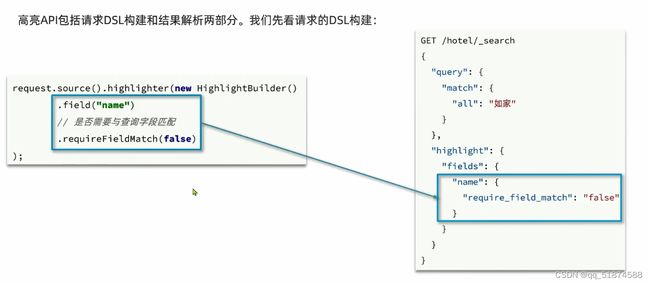
这里的加e代表有=条件,这里就表示 1000 3.地理查询 根据经纬度查询,常见使用场景包括寻找酒店,寻找附近的人等等 对于地理查询有以下方式: 这种矩形查询适用于【寻找酒店】之类的业务 这种点距离查询适用于【附近的人】这种业务 4.复合查询 之前的查询都属于简单查询 复合查询可以将其他简单查询组合起来,实现更复杂的搜索逻辑 在说复合查询之前,需要了解一下ES的相关性算分机制 当我们利用match进行查询的时候,文档会根据搜索词条进行关联度打分(_score),返回结果时按照分数高低排行,例如,我们搜索虹桥如家,结果会是这样: 在算相关性算分时,常用的算法有: 第一种比较简单不常用 第二种的思路就是,当一个词在所有搜索出来的文档中所占比例较高时,它就被赋予的分值较低,比如上面那个例子,由于【如家】这个词在3个文档里面都有,它就会被赋予log1分,也就是0分,【虹桥】这个词只有一个文档有,它就会被赋予log3分 第二种算法在业界非常有名,但是现在也是在ES版本5之后就淘汰了 第三种算法是一种更为复杂的算法,在高版本的ES中一般会采用这种算法 它相比于TF-IDF算法比较好的特性就是词频越高,得分会增加的越慢最后趋于水平,比较平滑: 使用function score query 我们可以修改文档的相关性算分,根据新的到的算分排序: 例子: 5.复合查询 Boolean Query 布尔查询是一个或多个查询子句的组合,子查询的组合方式有: 由于算分函数是一个比较复杂消耗资源的函数,所以一般由算分搭配不算分的关键字使用 例子: 搜索框里面的可以加入must关键字参与算分,下面的条件就不算分 搜索案例: 需求:搜索名字包含【如家】,价格不高于400,在坐标31.21,121.5周围10km范围内的酒店 六、搜索结果处理 1.排序 ES支持对搜索结果进行排序,默认是根据相关度算分【_score】来排序。可以排序字段类型有:keyword类型,数值类型、地理坐标类型、日期类型等 一旦自己指定其他排序字段,ES就会放弃打分,搜索效率会有提升 设置排序语法: 可以见到,这个sort和mysql里面的orderBy有点像,可以写多个字段 案例1:对酒店数据按照用户评价降序排序,评价相同的按照价格升序排序 案例2:找到具体经纬度位置周围的酒店,距离升序排序 #这里location也可以采用字符串拼接经纬度的写法 2.分页 之前无论是上面搜索方法,出来的结果最多也就十条数据 因为ES默认情况下只返回top10的数据。而如果要查询更多数据就需要修改分页参数 ES中通过修改from、size参数来控制要返回的分页结果 这里虽然分页展示的代码与mysql很像,但底层实现的方式完全不一样 对于ES来讲,数据以倒排索引的方式进行存储,在例子中ES要获取990-1000的数据,ES会排序获取前1000条数据,然后截获后10条进行展示。 对于单机ES来说,这种查询方式没什么问题,但是ES一般都是集群部署,你不知道到底要找哪个单机上的前1000条数据,这叫ES的深度分页问题 由于这里ES设置的规则上限是10000,所以在实际业务场景中,会直接用业务代码限制用户查询的结果数量最高只能是10000 百度搜索的上限最高是70多页,每页10条数据,京东是100页 针对深度分页问题,ES提供两种解决方案: 第一种方式由于是保存继续的方式,所以查询只能由前往后,不支持从后往前,而且单次查询size也不能超过10000 第二种方式对内存消耗极大,而且不支持实时更新,官方已经不推荐使用 3.高亮 就是在搜索结果中把搜索关键字突出显示出来 这里搜出来,关键字被加了css样式标签,结果是动态的,是ES做的 高亮语法: 这里高亮字段和搜索字段默认必须一致,而且可以高亮的字段不止一个 例子: 这里通过设置,高亮字段和搜索字段可以不一致 七、RestClient的文档操作 1.快速入门 这样写了之后,查询完成,API会将查询到的结果直接封装成一个对象返回给我们,就是这个【SearchResponse】对象,我们需要从中解析获取需要的信息: 利用这个API查询酒店数据: 可以见到,整套代码里面最重要的就是这个request.source()里面的方法,可以用来做搜索排序高亮等各种功能: 2.全文检索查询、精确查询、复合查询等 案例:用Boolean查询查找一个位置在杭州,价格低于250的酒店: 3.排序和分页 这个案例使用Page,size传参处理是因为在真实业务场景中,一般页码和大小都是前端传过来的数据。 4.高亮显示 高亮的结果解析 八、数据聚合 1.聚合的种类 聚合(aggregations)可以实现对文档数据的统计分析运算,类似于mysql中的聚合函数(sum、max等配合group by使用) 在ES中的常用聚合有一下几类: 做了桶聚合的字段不能分词 2.DSL实现Bucket聚合 语法例子:统计所有数据中酒店品牌有几种,根据酒店品牌名做聚合 统计出来的结果 可以见到,默认情况下,bucket聚合会统计文档数量_count,按_count降序排列 修改为升序可以这么写: 默认情况下,Bucket聚合是对索引库中的所有文档做聚合,我们可以限定要聚合的文档范围,只需要添加query条件即可: 3.DSL实现Metrics聚合 语法例子:我们要求获取每个品牌的用户评分的min、max、avg等值,我们可以利用stats聚合: 运行结果: 对结果进行自定义排序: 4.RestAPI实现聚合 语法: 对结果进行解析 九、自动补全 1.拼音分词器 所谓自动补全,就是在搜索框搜索东西的时候自动出现拼音对应单词的提示,要实现这个功能的关键就是拼音分词器 安装好拼音分词器之后就可以对其进行测试: 运行结果: 2.自定义分词器 上面分词器的问题:搜索的【如家酒店还不错】这句话每个字都没单独分了拼音,然后还有一个全部首字母的分词,所以是不满足要求的 ES中的分词器的组成包含三部分: 我们可以在创建索引库时,通过settings来配置自定义的analyzer: 这里没有用到第一个组成是因为这个业务问题不需要用到转化陌生字符功能 这里是先用ik进行分词,然后用拼音进行拼音的分词 这里这么写是有问题的:因为你用ik分词之后,它还是会一个字一个字分拼音 在拼音分词器的官网上有拼音分词器的各种配置,可以修改单个字拼的配置问题 所以得这么写: 下面还要声明mapping映射: 测试: 这里可以发现查询没有任何问题了,但实际还是存在一个问题,就是搜索可能出现不相关的同音字问题: 这里最好的解决方案是用户输入中文,就直接使用IK分词器进行搜索,输入拼音的时候,才用自定义的分词器,这里需要对mapping做一些更改:设置搜索分词器为ik 3.DSL实现自动补全 ES提供了Completion Suggester查询来实现自动补全功能。这个查询会匹配以用户输入内容开头的词条并返回。为了提高补全查询的效率,对于文档中的字段类型有一些约束: -参与补全查询的字段必须是completion类型 -字段的内容一般是用来补全的多个词条形成的数组 这样,无论是输入S , 还是输入WH,都能出现Sony-WH-1000XM3这条数据 Completion suggester查询的语法如下: 实战案例:实现hotel索引库的自动补全、拼音搜索功能,这里给出大致步骤: 4.RestAPI实现自动补全 十、数据同步 1.数据同步问题与解决方案 ES中的数据来源于mysql数据库,因此mysql数据发生改变时,ES也必须跟着改变,这个就是ES与mysql之间的数据同步。 这里就会出现一个问题:在微服务中,负责管理操作mysql的业务与操作ES的服务可能不在同一个微服务上,这个数据同步该如何实现? 解决方案一:同步调用 问题:业务耦合,本来只需要写入MySQL的操作,变成了后面还要调用ES的API,响应会慢很多 解决方案二:异步通知 这种方案低耦合,但是比较依赖mq的可靠性 解决方案三:监听binlog 这种方案耦合度最低,因为酒店管理服务完全不用干其它任何事情了,但是会增加mysql的压力,而且需要引入中间件canal 2.利用MQ实现mysql与ES的数据同步 主要有以下步骤: 十一、Elasticsearch集群 1.ES集群结构 单机的ES做数据存储,必然面临两个问题:海量数据存储问题、单点故障问题 单机存储的数据量是有限的,而且单机宕机对于业务的影响的毁灭性的 解决方法: 2.ES中集群节点不同的职责划分: 默认情况下,每一个节点都是master eligible节点,因此一旦master节点宕机,其他候选节点会选举一个成为主节点。当主节点与其他节点网络故障时,可能发生脑裂问题 -主节点由于网络问题,无法连上其他节点,其他节点以为主节点挂了,就开始选举新的主节点,网络恢复,就会导致数据不一致的脑裂问题 3.ES集群的分布式存储 做一个实验,向三个节点中的一个节点插入三条数据,在第一个节点查询所有能得到三条数据,在第二个和第三个节点做查询也能查到三条数据。 这时可以用explain关键字查询数据的具体存储位置: 会发现三个节点各存储了一条数据 这里的原理是:当新增文档时,ES会通过Hash算法计算文档应该存储到哪个分片 -_routing默认是文档的id 算法与分片数量有关,因此索引库一旦创建,分片数量就不能修改 算法执行流程: 4.ES集群的分布式查询 上面我们做查询的时候用的是查询所有,并没有根据id进行查询,所以这里涉及到一一个分布式查询过程的问题 我们查询所有时,协调节点会将请求发往每一个节点(分散),然后将查询到的所有数据返回给用户(聚合),由于每个分片都可以是协调节点,所以每一个查询结果都是完整的数据。 5.ES集群的故障转移 集群的master节点会监控集群中的节点状态,如果发现有节点宕机,会立即将宕机节点的分片数据迁移到其他节点,保证数据安全,这个叫做故障转移 这里我们可以做个实验故意使一号节点宕机: 可以见到,ES立即完成了主节点选取,过了一会ES完成了数据迁移: 当我们使节点1恢复运行时: 可以见到,数据又迁移回来了,不过主节点此时已经是节点3了,而不是节点1.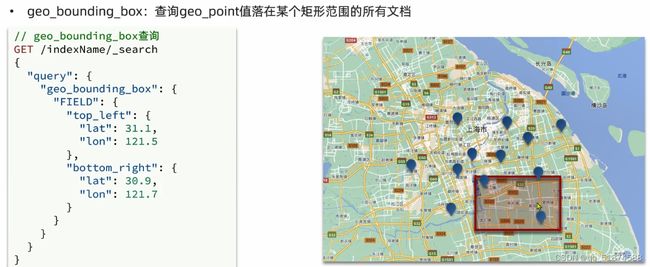



















![]()