指数平滑预测模型
目录
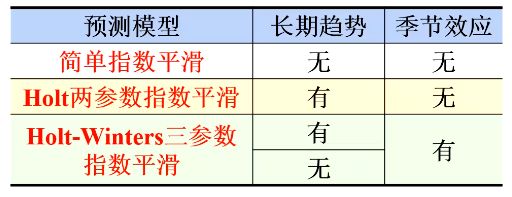
1.分类
2.简单指数平滑
简单指数平滑预测:
平滑系数的确定
R中实现:
3. Holt两参数指数平滑
4. Holt-Winters三参数指数平滑
5.ARIMA加法季节模型
R实现
例题:
1.分类
2.简单指数平滑
简单移动平均法向前预测1期:

缺点:历史信息的权重都为1/n
简单指数平滑预测:

还可写成:
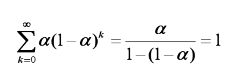
其均值为:

平滑系数的确定
- 一般对于变化缓慢的序列,α常取较小的值
- 对于变化迅速的序列,α常取较大的值
- 经验表明α介于0.05至0.3之间,修匀效果比较好。
例1对某一观察值序列{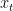 },使用简单指数平滑法。已知=10,
},使用简单指数平滑法。已知=10,![]() = 10.5,平滑系数
= 10.5,平滑系数 =0.25。
=0.25。
(1)求向前预测2期的预测值.![]()
(2)在2期预测值![]() 中,前面的系数等于多少。
中,前面的系数等于多少。
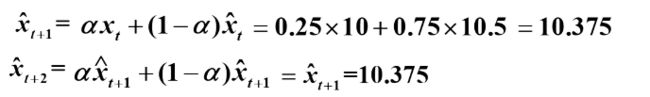
理论上可以证明简单指数平滑法任意期的预测值都为常数,所以简单指数平滑只适合做1期预测,是常用的平稳序列预测方法,且1期预测以后的值都与1期预测一样,所以只适合短期预测。
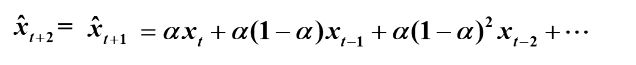
R中实现:

例6-4根据1949-1998年北京市每年最高气温序列,采用指数平滑法预测1999-2018年北京市每年最高气温。
a<-read.table('D:/桌面/6_4.csv',,sep=',',header=T) #读取数据
x<-ts(a$temp,start=1949)
plot(x) #时序图返回:
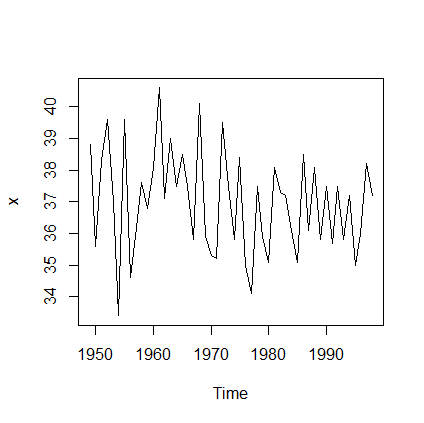
进行简单指数平滑:
fit<-HoltWinters(x,beta=F,gamma=F)
fit返回:

基于简单指数平滑模型进行5期预测:
library(forecast)
fore1<-forecast(fit,h=5)
fore1返回:

绘制预测效果图:
plot(fore1,lty=2)
lines(fore1$fitted,col='red')返回:
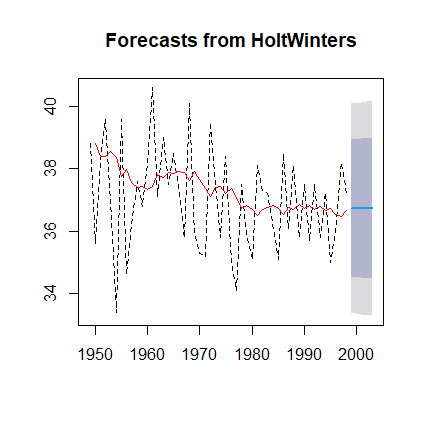
3. Holt两参数指数平滑
使用场合:含有线性趋势的序列进行修匀
模型结构:

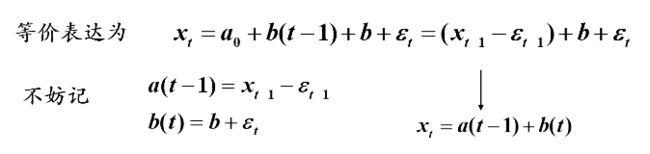
两参数修匀:

k期预测:
![]()
4. Holt-Winters三参数指数平滑
![]() 水平部分,
水平部分,![]() 趋势部分,
趋势部分,![]() 季节因子(周期m),c(t)是t时刻季节指数的无偏估计值
季节因子(周期m),c(t)是t时刻季节指数的无偏估计值
Holt两参数指数平滑:
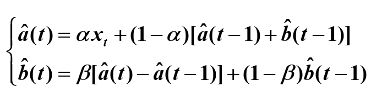
加法模型:
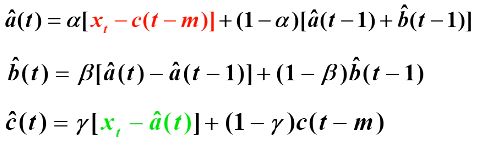
乘法模型:
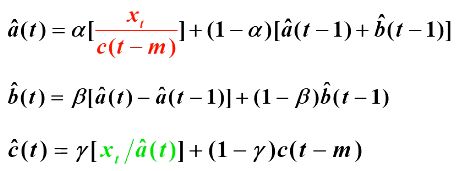
k期预测:
两参数预测:

三参数预测:
假设t+k期为季节周期的第j期

例6-1(续))对1981-1990年澳大利亚政府季度消费支出序列进行Holt-Winters三参数指数平滑进行8期预测。
a<-read.table('D:/桌面/6_1.csv',,sep=',',header=T) #读取数据
x<-ts(a$x,start=c(1981,1),frequency=4)
plot(x) #时序图
进行三参数指数平滑:
fit<-HoltWinters(x)
fit返回:

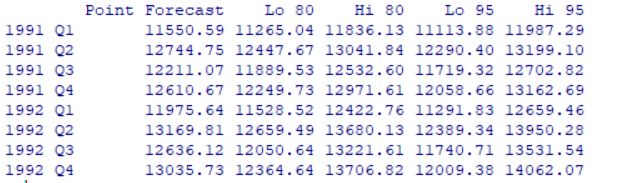
8期预测:
library(forecast)
fore<-forecast(fit,h=8)
fore返回:
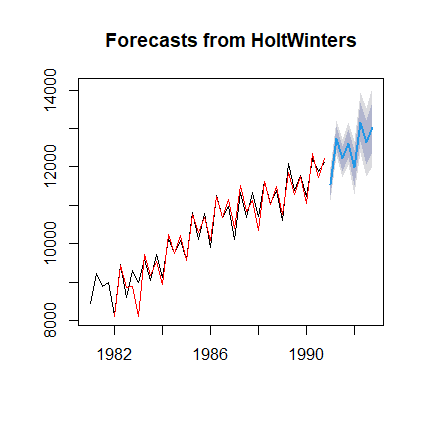
绘制预测结果:
plot(fore)
lines(fore$fitted,col='red')
返回:
5.ARIMA加法季节模型
季节效应和其它效应之间是加法关系
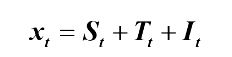
通过简单的趋势差分、季节差分之后转化为平稳,模型结构通常如下
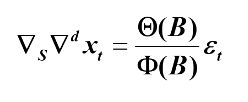
R实现
在上节的ARIMA函数的基础上多了个参数 seasonal(季节)

例题:
1、我国1949—2008年每年铁路货运量(单位:万吨)数据如习题5-2.csv所示。请选择适当模型拟合该序列,并预测2009—2013年我国铁路货运量。
a<-read.table('D:/桌面/习题5-2.csv',sep=',',header=T) #读取数据
x<-ts(a$transport,start=1949)
plot(x) #时序图
返回:
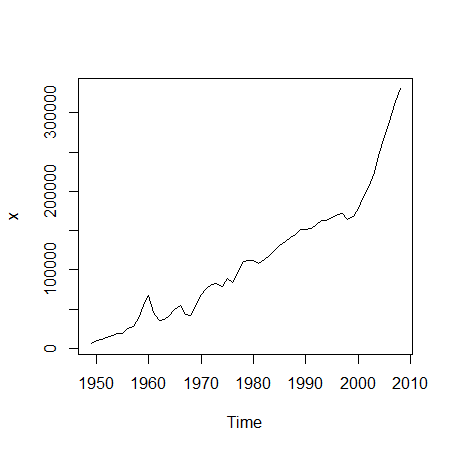
由时序图得,该序列有明显趋势,所以为非平稳序列,要对其进行1阶差分:
diff1<-diff(x)
diff1返回:
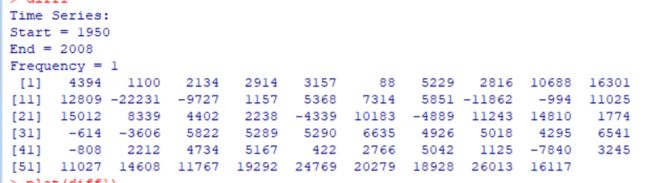
对1阶差分绘制时序图:
plot(diff1)
返回;

由时序图可得,差分后序列的值基本围绕在0附近,已经没有明显的趋势特征
平稳性检验:
# ADF检验
library(aTSA) #aTSA导入程序包
adf.test(diff1) #平稳性检验返回:

检验结果显示,该序列所有 ADF 检验统计量的 P 值均小于显著性水平(α=0.05),所以可以确定 1 阶差分后系列实现了平稳。
纯随机性检验:
for(i in 1:2)print( Box.test(x,type='Ljung-Box',lag=6*i)) #延迟6到12期的检验
返回:
Box-Ljung test
data: x
X-squared = 209.55, df = 6, p-value < 2.2e-16
Box-Ljung test
data: x
X-squared = 292.47, df = 12, p-value < 2.2e-16
根据随机性检验结果显示 6 阶和 12 阶延迟的统计量的 P 值都小于显著性水平(α=0.05), 所以可以判断该系列为平稳非白噪声序列
自相关系数和偏自相关系数:
acf(diff1,main='自相关图') #绘制自相关图
pacf(diff1,main='偏自相关图') #绘制偏自相关图
返回:

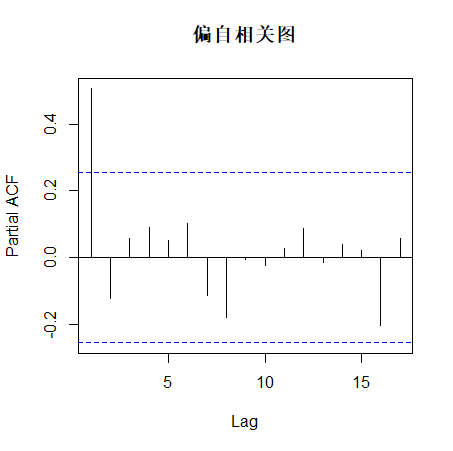
由自相关图和偏自相关图显示,该序列具有自相关图拖尾、偏自相关图1阶截尾的特征,故尝试使用 AR (1)模型拟合 1 阶差分后序列,又因为前面进行了1阶差分,所以可以用ARIMA(1,1,0)进行拟合。
ARIMA(1,1,0) 模型拟合:
fit1<-arima(x,order=c(1,1,0))
fit1返回:
Call:
arima(x = x, order = c(1, 1, 0))
Coefficients:
ar1
0.6589
s.e. 0.0985
sigma^2 estimated as 58008959: log likelihood = -611.35, aic = 1226.69
则可得模型解析式为:
![]()
模型检验:
ts.diag(fit1)返回:

由图可知,拟合模型效果很好。
进行预测:
library(forecast) #导入库
fore1<-forecast::forecast(fit1,h=5)
fore1
plot(fore1)
lines(fore1$fitted,col=4)
返回:
预测结果:
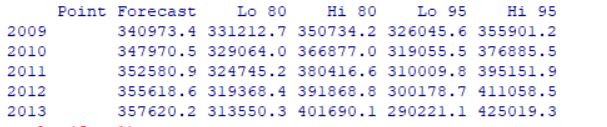
对预测结果绘制时序图:
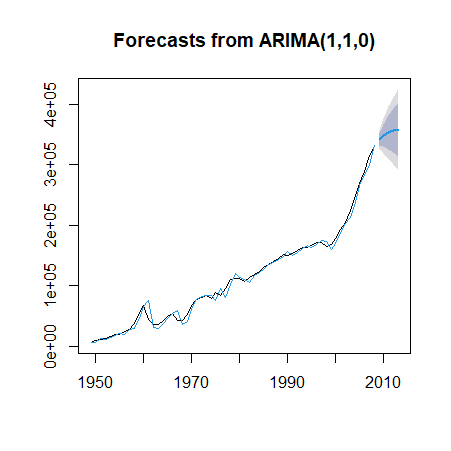
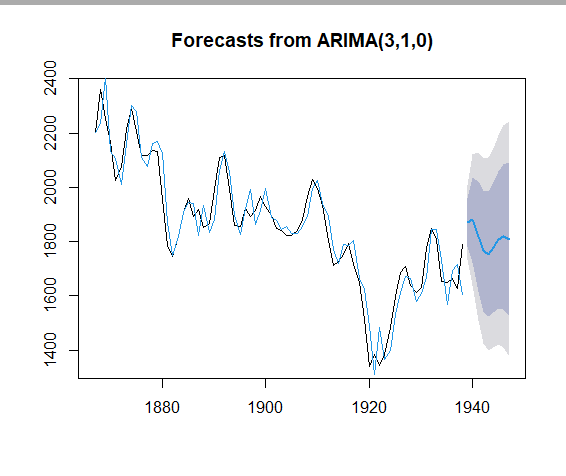
2、1867—1938年英国(英格兰及威尔士)绵羊数量如习题5-5.csv所示。
(1)确定该序列的平稳性;
(2)选择适当模型拟合该序列的发展;
(3)利用拟合模型预测1939—1945年英国绵羊的数量。
b<-read.table('D:/桌面/习题5-5.csv',sep=',',header=T) #读取数据
y<-ts(b$sheep,start=1867)
plot(y) #时序图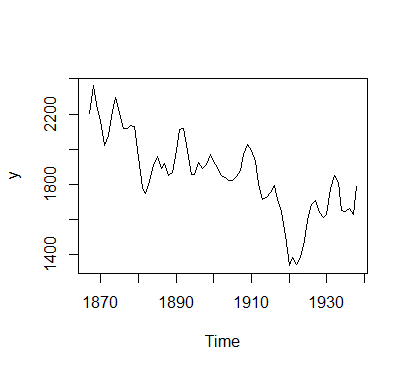
由时序图得,该序列有明显趋势,所以为非平稳序列
对其进行1阶差分:
diff2<-diff(y)
plot(diff2) #对1阶差分绘制时序图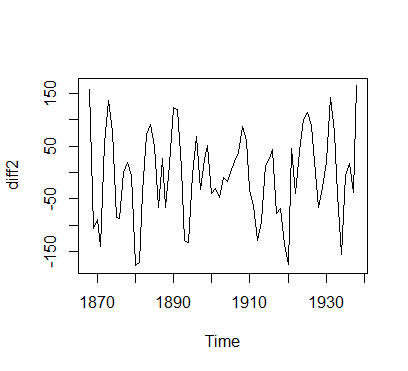
由时序图可得,差分后序列的值基本围绕在0附近,已经没有明显的趋势特征
平稳性检验:
library(aTSA) #aTSA导入程序包
adf.test(diff2) #平稳性检验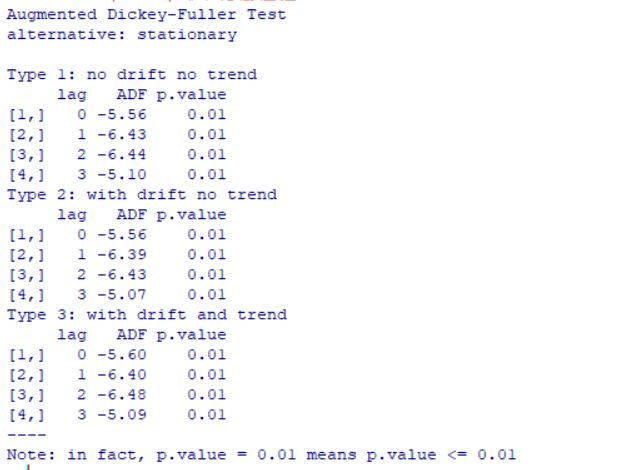
检验结果显示,该序列所有 ADF 检验统计量的 P 值均小于显著性水平(α=0.05),所以可以确定 1 阶差分后系列实现了平稳。
纯随机性检验:
for(i in 1:2)print( Box.test(y,type='Ljung-Box',lag=6*i)) #延迟6到12期的检验
返回:
Box-Ljung test
data: y
X-squared = 210.63, df = 6, p-value < 2.2e-16
Box-Ljung test
data: y
X-squared = 265.32, df = 12, p-value < 2.2e-16
根据随机性检验结果显示 6 阶和 12 阶延迟的统计量的 P 值都小于显著性水平(α=0.05), 所以可以判断该系列为平稳非白噪声序列
自相关系数和偏自相关系数:
acf(diff2,main='自相关图') #绘制自相关图
pacf(diff2,main='偏自相关图') #绘制偏自相关图
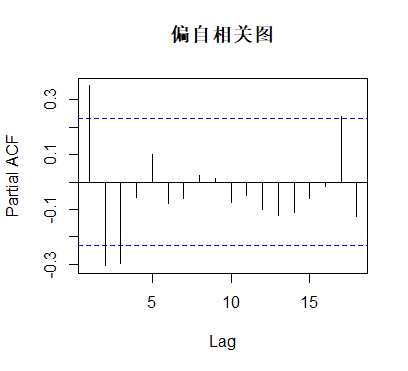
由自相关图和偏自相关图显示,该序列具有自相关图拖尾、偏自相关图3阶截尾的特征,故尝试使用 AR(3)模型拟合 1 阶差分后序列,考虑到前面已经进行的 1 阶差分运算,所以可以用ARIMA(3,1,0)进行拟合。
ARIMA(3,1,0) 模型拟合:
fit2<-arima(y,order=c(3,1,0))
fit2返回:

则可得模型解析式为:
![]()
模型检验:
ts.diag(fit2)
由图可知,拟合模型效果很好。
进行预测:
library(forecast) #导入库
fore2<-forecast::forecast(fit2,h=9)
fore2
plot(fore2)
lines(fore2$fitted,col=4)