精读yolo LoadImagesAndLabels类
安装albumentations
配置清华源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install -U albumentations安装不起的问题一般都是网络的问题, 开源地址:
GitHub - albumentations-team/albumentations: Fast image augmentation library and an easy-to-use wrapper around other libraries. Documentation: https://albumentations.ai/docs/ Paper about the library: https://www.mdpi.com/2078-2489/11/2/125
初始化:
文件读取:
try:
f = [] # image files
for p in path if isinstance(path, list) else [path]:
p = Path(p) # os-agnostic
if p.is_dir(): # dir
f += glob.glob(str(p / '**' / '*.*'), recursive=True)
# f = list(p.rglob('*.*')) # pathlib
elif p.is_file(): # file
with open(p) as t:
t = t.read().strip().splitlines()
parent = str(p.parent) + os.sep
f += [x.replace('./', parent, 1) if x.startswith('./') else x for x in t] # to global path
# f += [p.parent / x.lstrip(os.sep) for x in t] # to global path (pathlib)
else:
raise FileNotFoundError(f'{prefix}{p} does not exist')
self.im_files = sorted(x.replace('/', os.sep) for x in f if x.split('.')[-1].lower() in IMG_FORMATS)
# self.img_files = sorted([x for x in f if x.suffix[1:].lower() in IMG_FORMATS]) # pathlib
assert self.im_files, f'{prefix}No images found'
except Exception as e:
raise Exception(f'{prefix}Error loading data from {path}: {e}\n{HELP_URL}') from e测试一下:
if __name__ == '__main__':
path = 'D:\PycharmProjects\opencvtest\datasets\coco\images'
a = LoadImagesAndLabels(path)
next(iter(a))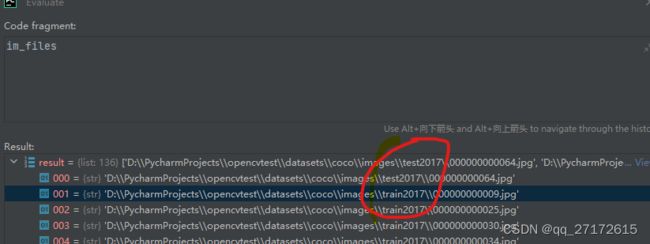
它把根目录的所有地址都读取出来了。关键这句代码
f += glob.glob(str(p / '**' / '*.*'), recursive=True)即使不了解通配符匹配规则,大概也知道是什么意思了。 **表示所有文件名, *.*表示所有文件名。p 传入的根目录
缓存cahe
# Check cache
self.label_files = img2label_paths(self.im_files) # labels
cache_path = (p if p.is_file() else Path(self.label_files[0]).parent).with_suffix('.cache')
try:
cache, exists = np.load(cache_path, allow_pickle=True).item(), True # load dict
assert cache['version'] == self.cache_version # matches current version
assert cache['hash'] == get_hash(self.label_files + self.im_files) # identical hash
except Exception:
cache, exists = self.cache_labels(cache_path, prefix), False # run cache ops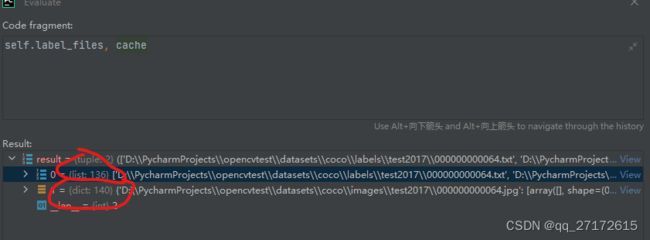
发现了 结果不一样, 先不管看这个方法
def img2label_paths(img_paths):
# Define label paths as a function of image paths
sa, sb = f'{os.sep}images{os.sep}', f'{os.sep}labels{os.sep}' # /images/, /labels/ substrings
return [sb.join(x.rsplit(sa, 1)).rsplit('.', 1)[0] + '.txt' for x in img_paths]os.sep 这个方法是根据操作系统自动生成的文件分割符
这个方法将文件地址 例如:
'D:\\PycharmProjects\\opencvtest\\datasets\\coco\\images\\train2017\\000000000009.jpg'
匹配其中的images 替代成
labels
后缀jpg 替代为txt. 一个找寻label地址的方法。
def cache_labels(self, path=Path('./labels.cache'), prefix=''):
# Cache dataset labels, check images and read shapes
x = {} # dict
nm, nf, ne, nc, msgs = 0, 0, 0, 0, [] # number missing, found, empty, corrupt, messages
desc = f"{prefix}Scanning {path.parent / path.stem}..."
with Pool(NUM_THREADS) as pool:
pbar = tqdm(pool.imap(verify_image_label, zip(self.im_files, self.label_files, repeat(prefix))),
desc=desc,
total=len(self.im_files),
bar_format=TQDM_BAR_FORMAT)
for im_file, lb, shape, segments, nm_f, nf_f, ne_f, nc_f, msg in pbar:
nm += nm_f
nf += nf_f
ne += ne_f
nc += nc_f
if im_file:
x[im_file] = [lb, shape, segments]
if msg:
msgs.append(msg)
pbar.desc = f"{desc} {nf} images, {nm + ne} backgrounds, {nc} corrupt"
pbar.close()
if msgs:
LOGGER.info('\n'.join(msgs))
if nf == 0:
LOGGER.warning(f'{prefix}WARNING ⚠️ No labels found in {path}. {HELP_URL}')
x['hash'] = get_hash(self.label_files + self.im_files)
x['results'] = nf, nm, ne, nc, len(self.im_files)
x['msgs'] = msgs # warnings
x['version'] = self.cache_version # cache version
try:
np.save(path, x) # save cache for next time
path.with_suffix('.cache.npy').rename(path) # remove .npy suffix
LOGGER.info(f'{prefix}New cache created: {path}')
except Exception as e:
LOGGER.warning(f'{prefix}WARNING ⚠️ Cache directory {path.parent} is not writeable: {e}') # not writeable
return x上面输出多了四个的原因。添加了hash, results, msgs, version几个数据。
显示cache
# Display cache
nf, nm, ne, nc, n = cache.pop('results') # found, missing, empty, corrupt, total
if exists and LOCAL_RANK in {-1, 0}:
d = f"Scanning {cache_path}... {nf} images, {nm + ne} backgrounds, {nc} corrupt"
tqdm(None, desc=prefix + d, total=n, initial=n, bar_format=TQDM_BAR_FORMAT) # display cache results
if cache['msgs']:
LOGGER.info('\n'.join(cache['msgs'])) # display warnings
assert nf > 0 or not augment, f'{prefix}No labels found in {cache_path}, can not start training. {HELP_URL}'
这个说几个参数 nf: found表示的是label文件存在的数量,nm:表示label文件不存在 , ne:label文件存在但是为null, n:表示通过验证的label数量。
verify_image_label 这个方法里面执行的。
读cache
# Read cache
[cache.pop(k) for k in ('hash', 'version', 'msgs')] # remove items
labels, shapes, self.segments = zip(*cache.values())
nl = len(np.concatenate(labels, 0)) # number of labels
assert nl > 0 or not augment, f'{prefix}All labels empty in {cache_path}, can not start training. {HELP_URL}'
self.labels = list(labels)
self.shapes = np.array(shapes)
self.im_files = list(cache.keys()) # update
self.label_files = img2label_paths(cache.keys()) # update读取l标签坐标 分割坐标, 文件地址 标签地址
创建索引:
# Create indices
n = len(self.shapes) # number of images
bi = np.floor(np.arange(n) / batch_size).astype(int) # batch index
nb = bi[-1] + 1 # number of batches
self.batch = bi # batch index of image
self.n = n
self.indices = range(n)bi这个方法有点意思: 比如 [0, 1, 2, 3] batch_size:为2 那么相除的结果:[0, 1/2, 1, 3/2]
再向下取整[0, 0, 1, 1] 刚好表示[0, 1, 2, 3]属于那个批量
更新标签
# Update labels
include_class = [] # filter labels to include only these classes (optional)
include_class_array = np.array(include_class).reshape(1, -1)
for i, (label, segment) in enumerate(zip(self.labels, self.segments)):
if include_class:
j = (label[:, 0:1] == include_class_array).any(1)
self.labels[i] = label[j]
if segment:
self.segments[i] = segment[j]
if single_cls: # single-class training, merge all classes into 0
self.labels[i][:, 0] = 0include_class 永远为假。所以他们还没实现,后面那个single_cls 在标签文件设置为0就行了。感觉这个方法没什么必要
内存/硬盘缓存
# Cache images into RAM/disk for faster training
if cache_images == 'ram' and not self.check_cache_ram(prefix=prefix):
cache_images = False
self.ims = [None] * n
self.npy_files = [Path(f).with_suffix('.npy') for f in self.im_files]
if cache_images:
b, gb = 0, 1 << 30 # bytes of cached images, bytes per gigabytes
self.im_hw0, self.im_hw = [None] * n, [None] * n
fcn = self.cache_images_to_disk if cache_images == 'disk' else self.load_image
results = ThreadPool(NUM_THREADS).imap(fcn, range(n))
pbar = tqdm(enumerate(results), total=n, bar_format=TQDM_BAR_FORMAT, disable=LOCAL_RANK > 0)
for i, x in pbar:
if cache_images == 'disk':
b += self.npy_files[i].stat().st_size
else: # 'ram'
self.ims[i], self.im_hw0[i], self.im_hw[i] = x # im, hw_orig, hw_resized = load_image(self, i)
b += self.ims[i].nbytes
pbar.desc = f'{prefix}Caching images ({b / gb:.1f}GB {cache_images})'
pbar.close()后面两个判断 设置为:disk的时候 执行
f = self.npy_files[i]
if not f.exists():
np.save(f.as_posix(), cv2.imread(self.im_files[i]))当是ram时候:直接读到内存里面,如果你的内存足够大,没什么问题。
总结:
做了几件事
读取文件路径 生成标签路径
处理标签信息: 得到shap, 目标检测坐标,分割坐标
设置索引
缓存:标签信息和图片信息。 np.save() 内存/ram: 直接读进来cv.imread
数据增强 __getitem__
要加载超参数:
if __name__ == '__main__':
hyp, a = load_yaml('D:\PycharmProjects\opencvtest\hyp.scratch-low.yaml')
path = 'D:\PycharmProjects\opencvtest\datasets\coco\images'
a = LoadImagesAndLabels(path, cache_images='disk', hyp=hyp)
for i, l, c, b in a:
show_targer(i, l)注射掉:
# if nl:
# labels[:, 1:5] = xyxy2xywhn(labels[:, 1:5], w=img.shape[1], h=img.shape[0], clip=True, eps=1E-3)
# labels_out = torch.zeros((nl, 6))
# if nl:
# labels_out[:, 1:] = torch.from_numpy(labels)
# #Convert
# img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
# img = np.ascontiguousarray(img)写个显示的函数:
def show_targer(img, targer):
h, w, c = img.shape
for i, x1, y1, x2, y2 in targer:
x1, y1, x2, y2 = int(x1), int(y1), int(x2), int(y2)
cv2.rectangle(img, (x1, y1), (x2, y2), (0, 255, 0), 1)
cv2.putText(img, str(i), (x1, y1), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 1)
cv2.imshow('name', img)
cv2.waitKey(0)
cv2.destroyAllWindows()mosaic mixup
mosaic = self.mosaic and random.random() < hyp['mosaic']
if mosaic:
# Load mosaic
img, labels = self.load_mosaic(index)
shapes = None
# MixUp augmentation
if random.random() < hyp['mixup']:
img, labels = mixup(img, labels, *self.load_mosaic(random.randint(0, self.n - 1))) def load_mosaic(self, index):
# YOLOv5 4-mosaic loader. Loads 1 image + 3 random images into a 4-image mosaic
labels4, segments4 = [], []
s = self.img_size
yc, xc = (int(random.uniform(-x, 2 * s + x)) for x in self.mosaic_border) # mosaic center x, y
indices = [index] + random.choices(self.indices, k=3) # 3 additional image indices
random.shuffle(indices)
for i, index in enumerate(indices):
# Load image
img, _, (h, w) = self.load_image(index)
# place img in img4
if i == 0: # top left
img4 = np.full((s * 2, s * 2, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles
x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc # xmin, ymin, xmax, ymax (large image)
x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h # xmin, ymin, xmax, ymax (small image)
elif i == 1: # top right
x1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, s * 2), yc
x1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), h
elif i == 2: # bottom left
x1a, y1a, x2a, y2a = max(xc - w, 0), yc, xc, min(s * 2, yc + h)
x1b, y1b, x2b, y2b = w - (x2a - x1a), 0, w, min(y2a - y1a, h)
elif i == 3: # bottom right
x1a, y1a, x2a, y2a = xc, yc, min(xc + w, s * 2), min(s * 2, yc + h)
x1b, y1b, x2b, y2b = 0, 0, min(w, x2a - x1a), min(y2a - y1a, h)
img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax]
padw = x1a - x1b
padh = y1a - y1b
# Labels
labels, segments = self.labels[index].copy(), self.segments[index].copy()
if labels.size:
labels[:, 1:] = xywhn2xyxy(labels[:, 1:], w, h, padw, padh) # normalized xywh to pixel xyxy format
segments = [xyn2xy(x, w, h, padw, padh) for x in segments]
labels4.append(labels)
segments4.extend(segments)
# Concat/clip labels
labels4 = np.concatenate(labels4, 0)
for x in (labels4[:, 1:], *segments4):
np.clip(x, 0, 2 * s, out=x) # clip when using random_perspective()
# img4, labels4 = replicate(img4, labels4) # replicate
# Augment
img4, labels4, segments4 = copy_paste(img4, labels4, segments4, p=self.hyp['copy_paste'])
img4, labels4 = random_perspective(img4,
labels4,
segments4,
degrees=self.hyp['degrees'],
translate=self.hyp['translate'],
scale=self.hyp['scale'],
shear=self.hyp['shear'],
perspective=self.hyp['perspective'],
border=self.mosaic_border) # border to remove
return img4, labels4padw = x1a - x1b x1a表示的是原图在mosaic画布坐标, x1b表示原图应该截取的坐标。
列如:原图大于左上, mosaic画布坐标就是(0, 0)(中心坐标) x1b肯定是大于0的,这个时候减就是负。所以,很显然padw就表示原图需要截取的长度。 标签坐标肯定也要减少这么多。
原图小于左上的时候:x1b=0. 画布坐标肯定大于0, 此时padw就是正的。很显然这个时候labels坐标也要加上padw才能还原.
padh = y1a - y1b
xywhn2xyxy: 是转换coco数据集坐标到xyxy.
我另外两篇博客写了这两个。
copy_paste:是分割任务的增强
数据增强1
random_perspective
方便看效果:先将mosaci关闭
mosaic: 0 # image mosaic (probability) mosaic
旋转
调节
degrees: 0.0
到
degrees:10.0
平移
translate: 0.5 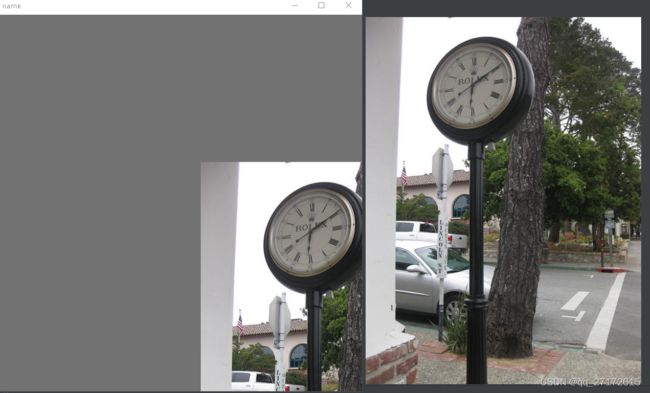
有点遮挡效果
缩放:
scale: 0.7 # image scale (+/- gain)
拉伸
shear: 10 # image shear (+/- deg)透视变化:
perspective: 0.0009 # image perspective (+/- fraction),数据增强2
T = [
A.RandomResizedCrop(height=size, width=size, scale=(0.8, 1.0), ratio=(0.9, 1.11), p=0.0),
A.Blur(p=0.01),
A.MedianBlur(p=0.01),
A.ToGray(p=0.01),
A.CLAHE(p=0.01),
A.RandomBrightnessContrast(p=0.0),
A.RandomGamma(p=0.0),
A.ImageCompression(quality_lower=75, p=0.0)] 这些增强都是写死了的,估计是他们调出来这样是最好的。
# Flip up-down
if random.random() < hyp['flipud']:
img = np.flipud(img)
if nl:
labels[:, 2] = 1 - labels[:, 2]
# Flip left-right
if random.random() < hyp['fliplr']:
img = np.fliplr(img)
if nl:
labels[:, 1] = 1 - labels[:, 1]这个是翻转,也没啥好说。有点注意的是,label坐标也得翻转。
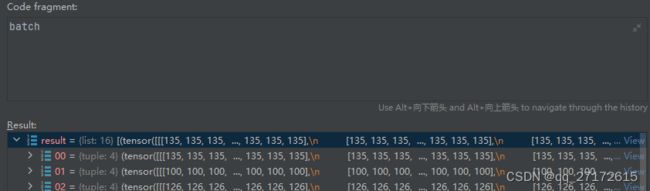
batch:
return loader(dataset,
batch_size=batch_size,
shuffle=shuffle and sampler is None,
num_workers=nw,
sampler=sampler,
pin_memory=PIN_MEMORY,
collate_fn=LoadImagesAndLabels.collate_fn4 if quad else LoadImagesAndLabels.collate_fn,
worker_init_fn=seed_worker,
generator=generator), dataset @staticmethod
def collate_fn(batch):
im, label, path, shapes = zip(*batch) # transposed
for i, lb in enumerate(label):
lb[:, 0] = i # add target image index for build_targets()
return torch.stack(im, 0), torch.cat(label, 0), path, shapes例如: batch=16