大数据综合项目--网站流量日志数据分析系统(详细步骤和代码)
文章目录
- 前言:
- 基本概述
-
- Sqoop概述
-
- 什么是Sqoop
- Flume概述
-
- 什么是Flume
- 为什么需要flume
- HIve概述
-
- 什么是Hive
- 系统背景:
- 模块开发
-
- 数据采集
-
- 使用Flume搭建日志采集系统
- 数据预处理
-
- 实现数据预处理
- 数据仓库开发
-
- 数据导出
- 日志分析系统报表展示
前言:
提示:这里简述我使用的版本情况:
ubuntu16.04
hbase1.1.5
hive1.2.1
sqoop1.4.6
flume1.7.0
项目所使用的参考文档和代码资源和部分数据
网盘链接:链接:https://pan.baidu.com/s/1TIKHMBmEFPiOv48pxBKn2w
提取码:0830


基本概述
为更好的理解项目架构,对项目使用的一些服务补充一些基本概述:
Sqoop概述
什么是Sqoop
Sqoop是Apache旗下的一款开源工具,2013年独立成为Apache的一个顶级开源项目
Sqoop主要用于在Hadoop和关系数据库或大型机之间传输数据,可以使用Sqoop工具将数据从关系数据库管理系统导入(import)到Hadoop分布式文件系统中,或者将Hadoop中的数据转换导出(export)到关系数据库管理系统,功能图如下
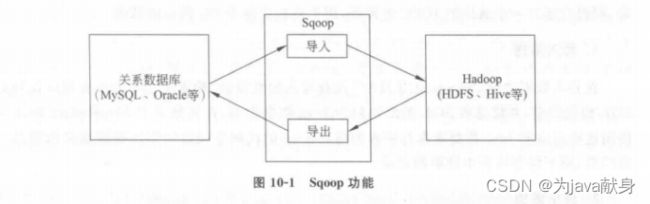
目前sqoop主要分为sqoop1和sqoop2两个版本,其中版本号为1.4.x属于sqoop1,而版本号为1.99.x的属于Sqoop2.这两个版本开发时的定位方向不同,体系结构具有很大的差异,因此它们之间互不兼容。
Sqoop1功能结构简单,部署方便。提供命令行操作方式,主要适用于系统服务管理人员进行简单的数据迁移操作,该项目只用到sqoop1解决数据迁移问题,因此我们使用sqoop1就可以完成基本的需求
Flume概述
什么是Flume
Flume原是Cloudera公司提供的一个高可用、高可靠、分布式海量日志采集、聚合和传输系统,后来纳入到Apache旗下,作为一个顶级开源项目。Apache Flume 不仅只限于日志数据的采集,由于Flume采集的数据源是可定制的,因此Flume还课用于传输大量事件数据,包括但不限于网络流量数据、社交媒体生成的数据以及几乎任何可能的数据源
当前Flume分成两个版本:Flume0.9x统称Flume-og和Flume1.x版本,统称Flume-ng,早期Flume-og存在设计不合理,纳入Apache旗下后对Flume代码进行重构,进行补充和加强该项目也是使用Flume-ng版本进行Flume开发
Flume运行机制

Agent:Agent是Flume中的核心组件,用来收集数据。一个Agent就是一个JVM进程,它是Flume中最小的独立运行的单元。
Flume的核心是把数据从数据源(如Web Server)通过数据采集器(Source)收集过来,
再将收集的数据通过缓冲通道(Channel)汇集到指定的接收器(Sink)。
为什么需要flume
1、当大量的数据在同一个时间要写入HDFS时,每次一个文件被创建或者分配一个新的块,都会在namenode发生很复杂的操作,主节点压力很大,会造成很多问题,比如写入时间严重延迟、写入失败等。
2、flume是一个灵活的分布式系统,易扩展,高度可定制化。
3、flume中的核心组件Agent。一个Agent可以连接一个或者多个Agent,可以从一个或者多个Agent上收集数据。多个Agent相互连接,可以建立流作业,在Agent链上,就能将数据从一个位置移动到另一个地方(HDFS、HBase等)。
HIve概述
Hive起源于Facebook,facebook公司有着大量的日志数据,而Hadoop是一个实现了Mapreduce模式开源的分布式并行计算框架。可以轻松处理大规模的数据量,Mapreduce程序虽然对于熟悉Java语言的工程师来说比较容易开发,但是对于其他语言使用者来说难度较大,为此Facebook开发团队想到设计一种使用Sql语言就能够对日志数据查询分析的工具,大大节省开发人员的学习成本,HIve则诞生于此
什么是Hive
Hive是建立在Hadoop文件系统上的数据仓库,它提供了一系列工具,能够对存储在HDFS中的数据进行数据提取、转换和加载(ETL),这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的工具。
Hive定义了简单的类SQL查询语言,可以将结构化的数据文件映射为一张数据表,允许熟悉SQL的用户查询数据,也允许熟悉MapReduce的开发者开发定义mapper和reducer来处理复杂的分析工作,这样Hive的有事更加明显
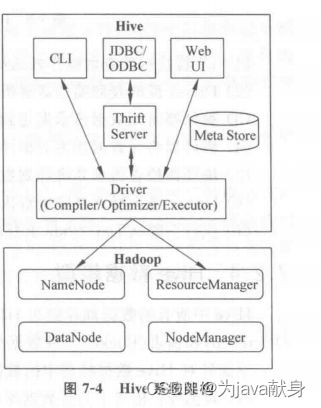
(1)用户接口:主要分为3个,分别是CLI、JDBC/ODBC 和 WebUI。其中,CLI 即 Shell终端命令行,它是最常用的方式。JDBC/ODBC是Hive的
Java实现,与使用传统数据库JDBC的方式类似,WebUI指的是通过浏览器访问Hive。
(2)跨语言服务(Thrift Server):Thrift是Facebook开发的一个软件框架,可以用来进行可扩展且跨语言的服务。Hive集成了该服务﹐能让不同
的编程语言调用Hive的接口。
(3)底层的驱动引擎:主要包含编译器(Compiler),优化器(Optimizer)和执行器(Executor ),它们用于完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成,生成的查询计划存储在HDFS中,并在随后由MapReduce调用执行。
(4)元数据存储系统(Metastore):Hive中的元数据通常包含表名,列、分区及其相关属性,表数据所在目录的位置信息,Metastore默认存在自带的 Derby数据库中。由于Derby数据库不适合多用户操作,并且数据存储目录不固定,不方便管理,因此,通常都将元数据存储在MySQL数据库。
系统背景:
近年来,随着社会的不断发展,人们对于海量数据的挖掘和运用越来越重视,互联网是面向全社会公众进行信息交流的平台,已成为了收集信息的最佳渠道并逐步进入传统的流通领域。同时,伴随着大数据技术的创新与应用,进一步为人们进行大数据统计分析提供了便利。
大数据信息的统计分析可以为企业决策者提供充实的依据。例如,通过对某网站日志数据统计分析,可以得出网站的日访问量,从而得出网站的欢迎程度;通过对移动APP的下载数据量进行统计分析,可以得出应用程序的受欢迎程度﹐甚至还可以通过不同维度(区域、时间段、下载方式等)进行进一步更深层次的数据分析,为运营分析与推广决策提供可靠的参照数据
为了更清晰地了解系统日志数据统计分析的流程及架构,沟通一张架构图来了解一下

三个Nginx可能产生大量的日志文件,然后通过Flume分别采集这些日志文件,然后将采集的日志文件放在HDFS上,我们可以写Mapreduce程序来对采集后的日志进行预处理,因为从服务器采集过来的数据格式不能满足我们的需求,可能有一些脏数据,我们要通过Mapreduce对这些文件进行清理,把它们编程结构化的数据,然后我们可以把清洗后的数据加载到Hive仓库里面。可以对清洗后的数据进行数据分析,这一步是大数据中最重要的工作.分析之后得出我们的结果,可以通过sqoop这个迁移工具将我们的结果导出到mysql,导出到mysql之后我们可以通过web技术对我们的结果进行一个可视化的展示
在整个流程中,系统的数据分析并不是一次性大的,而是按照一定频率反复计算,因而整个处理链条中的各个环节需要按照一个的先后关系紧密衔接,即大量任务单元的管理调度。
模块开发
数据采集
在该项目中,对数据采集模块的可靠性,容错能力的要求通常不会非常严苛,因此使用通用的Flume日志采集框架完全可以满足数据采集的需求
使用Flume搭建日志采集系统
a1.sources=s1
a1.channels=c1
a1.sinks=k1
a1.sources.s1.type=TAILDIR
a1.sources.s1.positionFile=/root/export/data/nginx/taildir_position.json
a1.sources.s1.filegroups=f1 f2
a1.sources.s1.filegroups.f1=/root/export/data/nginx/test1/access.log
a1.sources.s1.filegroups.f2=/root/export/data/nginx/test2/.*log.*
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path=hdfs://192.168.80.140:9000/weblog/%Y%m%d
#上传文件的前缀
a1.sinks.k1.hdfs.filePrefix = logs-
#是否按照时间滚动文件夹
#a1.sinks.k1.hdfs.round =true
#多少时间单位创建一个新的文件夹
#a1.sinks.k1.hdfs.roundValue = 1
#重新定义时间单位
#a1.sinks.k1.hdfs.roundUnit = hour
#是否使用本地时间戳
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a1.sinks.k1.hdfs.batchSize = 1000
#设置文件类型,可支持压缩
a1.sinks.k1.hdfs.fileType = DataStream
#多久生成一个新的文件
a1.sinks.k1.hdfs.rollInterval =0
#设置每个文件的滚动大小
a1.sinks.k1.hdfs.rollSize = 10485760
#文件的滚动与Event数量无关
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.threadsPoolSize=10
a1.sinks.k1.hdfs.callTimeout=30000
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=1000
a1.sources.s1.channels=c1
a1.sinks.k1.channel=c1
我们知道通过Flume系统采集后的网站流量日志数据会汇总到HDFS上进行保存(这里假设保存目录为 /root/export/data/nginx/test1/access.log)
采集后的数据:
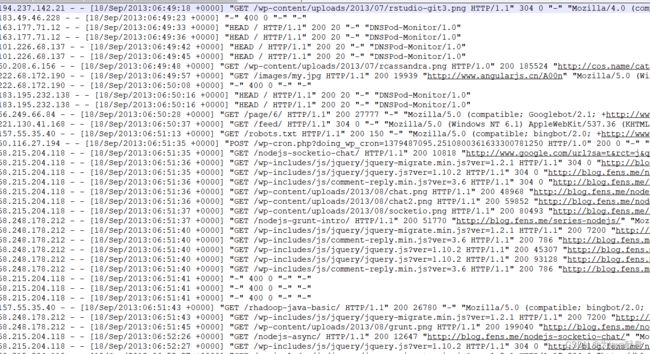
也可以用现成的采集后的数据,在网盘资源里有
采集后的数据每个字段的含义

数据预处理
在收集的日志文件中,通常不能直接将日志文件进行数据分析,这是因为日志文件中有许多不合法的数据,要对不合法的数据进行过滤,清洗出无意义的数据信息,并且将原始日志中的数据格式转换成利于后续数据分析时规范的格式,根据统计需求,筛选出不同主题的数据
实现数据预处理
1.创建Maven项目,添加相关依赖

添加相关依赖
org.apache.hadoop
hadoop-common
2.7.4
org.apache.hadoop
hadoop-hdfs
2.7.4
org.apache.hadoop
hadoop-client
2.7.4
org.apache.hadoop
hadoop-mapreduce-client-core
2.7.4
junit
junit
4.13-beta-3
compile
创建JavaBean对象,封装日志记录(WebLogBean.java)
package cn.itcast.mr.weblog.bean;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* 对接外部数据的层,表结构定义最好跟外部数据源保持一致
* 术语: 贴源表
* @author itcast
*
*/
public class WebLogBean implements Writable {
private boolean valid = true;// 判断数据是否合法
private String remote_addr;// 记录客户端的ip地址
private String remote_user;// 记录客户端用户名称,忽略属性"-"
private String time_local;// 记录访问时间与时区
private String request;// 记录请求的url与http协议
private String status;// 记录请求状态;成功是200
private String body_bytes_sent;// 记录发送给客户端文件主体内容大小
private String http_referer;// 用来记录从那个页面链接访问过来的
private String http_user_agent;// 记录客户浏览器的相关信息
//设置属性值
public void set(boolean valid,String remote_addr, String remote_user, String time_local, String request, String status, String body_bytes_sent, String http_referer, String http_user_agent) {
this.valid = valid;
this.remote_addr = remote_addr;
this.remote_user = remote_user;
this.time_local = time_local;
this.request = request;
this.status = status;
this.body_bytes_sent = body_bytes_sent;
this.http_referer = http_referer;
this.http_user_agent = http_user_agent;
}
public String getRemote_addr() {
return remote_addr;
}
public void setRemote_addr(String remote_addr) {
this.remote_addr = remote_addr;
}
public String getRemote_user() {
return remote_user;
}
public void setRemote_user(String remote_user) {
this.remote_user = remote_user;
}
public String getTime_local() {
return this.time_local;
}
public void setTime_local(String time_local) {
this.time_local = time_local;
}
public String getRequest() {
return request;
}
public void setRequest(String request) {
this.request = request;
}
public String getStatus() {
return status;
}
public void setStatus(String status) {
this.status = status;
}
public String getBody_bytes_sent() {
return body_bytes_sent;
}
public void setBody_bytes_sent(String body_bytes_sent) {
this.body_bytes_sent = body_bytes_sent;
}
public String getHttp_referer() {
return http_referer;
}
public void setHttp_referer(String http_referer) {
this.http_referer = http_referer;
}
public String getHttp_user_agent() {
return http_user_agent;
}
public void setHttp_user_agent(String http_user_agent) {
this.http_user_agent = http_user_agent;
}
public boolean isValid() {
return valid;
}
public void setValid(boolean valid) {
this.valid = valid;
}
/**
* 重写toString()方法,使用Hive默认分隔符进行分隔,为后期导入Hive表提供便利
* @return
*/
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append(this.valid);
sb.append("\001").append(this.getRemote_addr());
sb.append("\001").append(this.getRemote_user());
sb.append("\001").append(this.getTime_local());
sb.append("\001").append(this.getRequest());
sb.append("\001").append(this.getStatus());
sb.append("\001").append(this.getBody_bytes_sent());
sb.append("\001").append(this.getHttp_referer());
sb.append("\001").append(this.getHttp_user_agent());
return sb.toString();
}
/**
* 序列化方法
* @param in
* @throws IOException
*/
@Override
public void readFields(DataInput in) throws IOException {
this.valid = in.readBoolean();
this.remote_addr = in.readUTF();
this.remote_user = in.readUTF();
this.time_local = in.readUTF();
this.request = in.readUTF();
this.status = in.readUTF();
this.body_bytes_sent = in.readUTF();
this.http_referer = in.readUTF();
this.http_user_agent = in.readUTF();
}
/**
* 反序列化方法
* @param out
* @throws IOException
*/
@Override
public void write(DataOutput out) throws IOException {
out.writeBoolean(this.valid);
out.writeUTF(null==remote_addr?"":remote_addr);
out.writeUTF(null==remote_user?"":remote_user);
out.writeUTF(null==time_local?"":time_local);
out.writeUTF(null==request?"":request);
out.writeUTF(null==status?"":status);
out.writeUTF(null==body_bytes_sent?"":body_bytes_sent);
out.writeUTF(null==http_referer?"":http_referer);
out.writeUTF(null==http_user_agent?"":http_user_agent);
}
}
编写MapReduce程序,执行数据预处理
package cn.itcast.mr.weblog.preprocess;
import cn.itcast.mr.weblog.bean.WebLogBean;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.HashSet;
import java.util.Set;
/**
* 处理原始日志,过滤出真实请求数据,转换时间格式,对缺失字段填充默认值,对记录标记valid和invalid
*/
public class WeblogPreProcess {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(WeblogPreProcess.class);
job.setMapperClass(WeblogPreProcessMapper.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job, new Path("d:/weblog/input"));
FileOutputFormat.setOutputPath(job, new Path("d:/weblog/output"));
job.setNumReduceTasks(0);
boolean res = job.waitForCompletion(true);
System.exit(res ? 0 : 1);
}
public static class WeblogPreProcessMapper extends Mapper {
// 用来存储网站url分类数据
Set pages = new HashSet();
Text k = new Text();
NullWritable v = NullWritable.get();
/**
* 设置初始化方法,加载网站需要分析的url分类数据,存储到MapTask的内存中,用来对日志数据进行过滤
* 如果用户请求的资源是以下列形式,就表示用户请求的是合法资源。
*/
@Override
protected void setup(Context context) throws IOException, InterruptedException {
pages.add("/about");
pages.add("/black-ip-list/");
pages.add("/cassandra-clustor/");
pages.add("/finance-rhive-repurchase/");
pages.add("/hadoop-family-roadmap/");
pages.add("/hadoop-hive-intro/");
pages.add("/hadoop-zookeeper-intro/");
pages.add("/hadoop-mahout-roadmap/");
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获取一行数据
String line = value.toString();
//调用解析类WebLogParser解析日志数据,最后封装为WebLogBean对象
WebLogBean webLogBean = WebLogParser.parser(line);
if (webLogBean != null) {
// 过滤js/图片/css等静态资源
WebLogParser.filtStaticResource(webLogBean, pages);
k.set(webLogBean.toString());
context.write(k, v);
}
}
}
}
定义WebLogParser类用于解析读取每行日志信息,并将解析结果封装为WebLogBean对象
package cn.itcast.mr.weblog.preprocess;
import cn.itcast.mr.weblog.bean.WebLogBean;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Locale;
import java.util.Set;
public class WebLogParser {
//定义时间格式
public static SimpleDateFormat df1 = new SimpleDateFormat("dd/MMM/yyyy:HH:mm:ss", Locale.US);
public static SimpleDateFormat df2 = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss", Locale.US);
public static WebLogBean parser(String line) {
WebLogBean webLogBean = new WebLogBean();
//把一行数据以空格字符切割并存入数组arr中
String[] arr = line.split(" ");
//如果数组长度小于等于11,说明这条数据不完整,因此可以忽略这条数据
if (arr.length > 11) {
//满足条件的数据逐个赋值给webLogBean对象
webLogBean.setRemote_addr(arr[0]);
webLogBean.setRemote_user(arr[1]);
String time_local = formatDate(arr[3].substring(1));
if(null==time_local || "".equals(time_local)) time_local="-invalid_time-";
webLogBean.setTime_local(time_local);
webLogBean.setRequest(arr[6]);
webLogBean.setStatus(arr[8]);
webLogBean.setBody_bytes_sent(arr[9]);
webLogBean.setHttp_referer(arr[10]);
//如果useragent元素较多,拼接useragent
if (arr.length > 12) {
StringBuilder sb = new StringBuilder();
for(int i=11;i= 400) {// 大于400,HTTP错误
webLogBean.setValid(false);
}
if("-invalid_time-".equals(webLogBean.getTime_local())){
webLogBean.setValid(false);
}
} else {
webLogBean=null;
}
return webLogBean;
}
//添加标识
public static void filtStaticResource(WebLogBean bean, Set pages) {
if (!pages.contains(bean.getRequest())) {
bean.setValid(false);
}
}
//格式化时间方法
public static String formatDate(String time_local) {
try {
return df2.format(df1.parse(time_local));
} catch (ParseException e) {
return null;
}
}
}
该项目使用本地模式运行,只需要在编写MapReduce程序完成后,在本地D:/weblog/input目录中放入将要清洗的日志文件,再执行程序就即可
(意思就是将我们刚才flume采集的文件放到input下)
程序执行结果
在程序指定的输出路径可以看到这些

查看part-m-000的内容

这些黑黑的是间隔符,可以看出和之前flume采集的数据的差比,有很多flase的数据段
数据仓库开发
数据预处理完成后,就需要将MapReduce程序的输出结果文件上传至HDFS中,并使用HIVE建立相应的表结构于上床的输出结果文件产生映射关系。
我们先将程序执行结果文件
![]()
上传到hadoop集群中的主服务器,通过lrzsz拖拽上传到/root/weblog

这个路径可以根据自己需求修改,再上传到hdfs目录中(如/weblog/preprocessed)
hadoop fs -put part-m-0000 /weblog/preprocessed
如果出现下述情况
![]()
输入hadoop dfsadmin -safemode leave即可
上传成功

启动Hive
创建数据仓库
hive > create database weblog;
使用我们刚才创建的数据库
hive > use weblog;
创建表
hive > create table ods_weblog_origin(
valid string,
remote_addr string,
remote_user string,
time_local string,
request string,
status string,
body_bytes_sent string,
http_referer string,
http_user_agent string ) partitioned by(datestr string) row format delimited fields terminated by '\001';
加载数据到hive表
把我们数据清洗后的数据加载到表中
hive >load data inpath '/weblog/preprocessed/' overwrite into table ods_weblog_origin partition(datestr='20210617');
这里注意路径是我们刚才上传mapreduce程序执行结果文件的路径,路径前后不要出现空格
查询
select * from ods_weblog_origin;
这段指令执行后我们可以看到的结果如下

创建明细表ods_weblog_detail
hive > create table ods_weblog_detail(
valid string, --有效标识
remote_addr string, --来源IP
remote_user string, --用户标识
time_local string, --访问完整时间
daystr string, --访问日期
timestr string, --访问时间
month string, --访问月
day string, --访问日
hour string, --访问时
request string, --请求的url
status string, --响应码
body_bytes_sent string, --传输字节数
http_referer string, --来源url
ref_host string, --来源的host
ref_path string, --来源的路径
ref_query string, --来源参数query
ref_query_id string, --来源参数query值
http_user_agent string --客户终端标识
) partitioned by(datestr string);
18、创建中间临时表t_ods_tmp_referurl
hive > create table t_ods_tmp_referurl as SELECT a.*,b.*
FROM ods_weblog_origin a LATERAL VIEW parse_url_tuple(regexp_replace(http_referer, "\"", ""), 'HOST', 'PATH','QUERY', 'QUERY:id') b as host, path, query, query_id;
创建临时中间表t_ods_tmp_detail
hive > create table t_ods_tmp_detail as select b.*,substring(time_local,0,10) as daystr,
substring(time_local,12) as tmstr,
substring(time_local,6,2) as month,
substring(time_local,9,2) as day,
substring(time_local,11,3) as hour
from t_ods_tmp_referurl b;
加载数据到明细宽表前启用动态分区
hive > set hive.exec.dynamic.partition=true;
hive > set hive.exec.dynamic.partition.mode=nonstrict;
生成明细宽表 向ods_weblog_detail表,加载数据
hive > insert overwrite table ods_weblog_detail partition(datestr)
select distinct otd.valid,otd.remote_addr,otd.remote_user,
otd.time_local,otd.daystr,otd.tmstr,otd.month,otd.day,otd.hour,
otr.request,otr.status,otr.body_bytes_sent,
otr.http_referer,otr.host,otr.path,
otr.query,otr.query_id,otr.http_user_agent,otd.daystr
from t_ods_tmp_detail as otd,t_ods_tmp_referurl as otr
where otd.remote_addr=otr.remote_addr
and otd.time_local=otr.time_local
and otd.body_bytes_sent=otr.body_bytes_sent
and otd.request=otr.request;
查看HDFS的WEB UI界面的ods_weblog_detail文件夹

统计每一天的PV量
# 创建表dw_pvs_everyday
hive > create table dw_pvs_everyday(pvs bigint,month string,day string);
#提取“day”字段
hive > insert into table dw_pvs_everyday
select count(*) as pvs,owd.month as month,owd.day as day
from ods_weblog_detail owd
group by owd.month,owd.day;
查看表dw_pvs_everyday中的数据
Select * from dw_pvs_everyday;
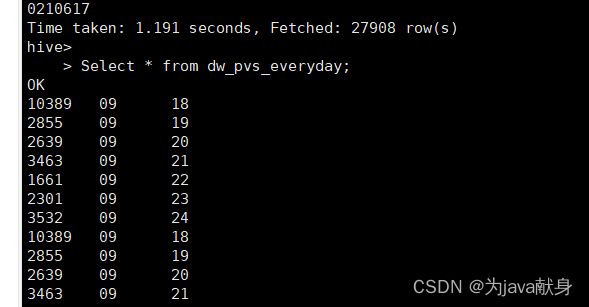
实现人均浏览量
创建维度表dw_avgpv_user_everyday
hive > create table dw_avgpv_user_everyday( day string,avgpv string);
向表dw_avgpv_user_everyday中插入数据
hive > insert into table dw_avgpv_user_everyday
select '2013-09-18',sum(b.pvs)/count(b.remote_addr) from
(select remote_addr,count(1) as pvs from ods_weblog_detail where
datestr='2013-09-18' group by remote_addr) b;
查看表dw_avgpv_user_everyday中的数据
Select * from dw_avgpv_user_everyday;
数据导出
通过SQLyog工具远程连接集群主服务器的MySQL服务

这里要注意的是链连接数据库出现Access denied for user ‘root‘
补充说明:当别的机子(IP )通过客户端的方式在没有授权的情况下是无法连接 MySQL 数据库的,如果需要远程连接 Linux 系统上的 MySQL 时,必须为其 IP 和 具体用户 进行 授权 。一般 root 用户不会提供给开发者。如:使用 Windows 上的 SQLyog 图形化管理工具连接 Linux 上的 MySQL 数据库,必须先对其进行授权。
解决方法的参考链接https://blog.csdn.net/aotongkeji/article/details/123155896
然后测试连接

然后我们可以右击创建数据库

也可以
CREATE DATABASE if NOT EXISTS sqoopdb;
如图所在空白输入代码 执行操作

创建七日人均浏览量表t_avgpv_num
mysql > create table `t_avgpv_num` (
`dateStr` varchar(255) DEFAULT NULL,
`avgPvNum` decimal(6,2) DEFAULT NULL
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
Sqoop导出数据
这一步是将我们的数据加载到mysql数据库中
sqoop export \
--connect jdbc:mysql://192.168.80.140:3306/sqoopdb \
--username hive\
--password hive\
--table t_avgpv_num \
--columns "dateStr,avgPvNum" \
--fields-terminated-by '\001' \
--export-dir /user/hive/warehouse/weblog.db/dw_avgpv_user_everyday;
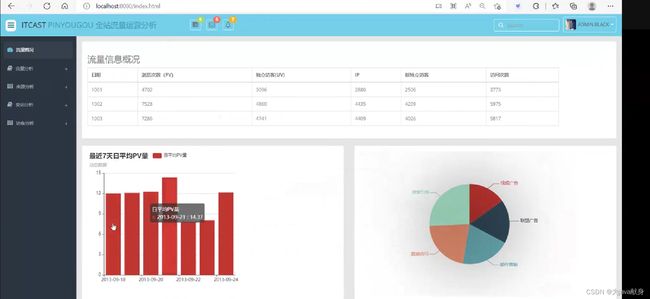
日志分析系统报表展示
将我们的数据库数据使用web技术转化成可视化数据
这部分代码太多了,就不放在这里了
所需代码已经在网盘中
数据库名字和密码和数据库驱动位置

根据自己情况修改

然后点击run as

输入tomcat7:run

然后在浏览器上输入http://localhost:8080/index.html
即可查看可视化结果