Hadoop的集群搭建windows基于VMware虚拟机超详细教程(一主二从)
Hadoop集群搭建(一主二从)
文章目录
- Hadoop集群搭建(一主二从)
- 前言
- 一、VMware安装包以及所需要的jdk,Hadoop安装包
- 二、XSHELL和XFTP下载与安装
- 三、在VMware虚拟机中安装CentOS 7
- 四、配置CentOS7
- 五、克隆虚拟机,配置主机,搭建集群。
- 六、用Xshell连接三台虚拟机
- 七、配置Hadoop
- 八、启动Hadoop集群
前言
查阅了许多资料和参考了其他博主的文章之后耗时一天终于成功搭建出window基于VMware虚拟机的Hadoop集群。基于win10系统,配置3台CentOS虚拟机,部署Hadoop-2.7.7,出本教程希望帮助到同样在学习的同学们。
一、VMware安装包以及所需要的jdk,Hadoop安装包
安装包提取地址:https://pan.baidu.com/s/14FEEDIKgBMCt_zxyclgQcg
提取码:re8a
复制这段内容后打开百度网盘手机App,操作更方便哦
二、XSHELL和XFTP下载与安装
官网地址:https://www.netsarang.com/zh/free-for-home-school/
(在下载中选中两者填写姓名邮件即可下载,会通过邮件的方式发送)
1.为什么要使用xshell呢?因为xshell用来在windows界面下访问远端不同系统下的服务器,从而实现较好地远程控制终端的目的。
2.为什么使用Xftp呢,就是因为Xftp是一个功能强大的SFTP、FTP 文件传输软件。
三、在VMware虚拟机中安装CentOS 7
教程所使用的是虚拟机的镜像安装 CentOS-7-x86_64-Minimal-2009.iso
下载地址:http://mirrors.aliyun.com/centos/7.9.2009/isos/x86_64/
然后找到我们上面提到的镜像,选中下载。(因为要同时开三台的虚拟机,博主的内存只有8g,带不动鸭。所以直接就安装最小化的。)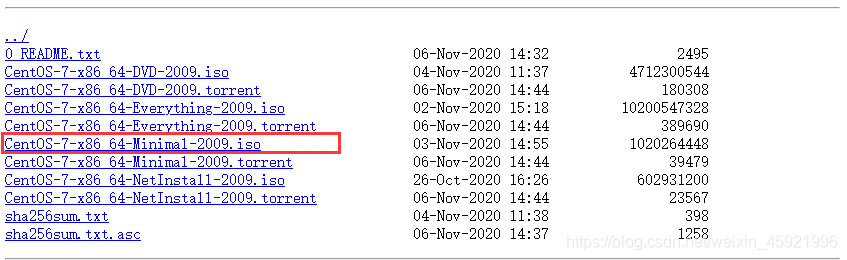
打开VMware,如下图,创建新的虚拟机:
在光盘映像文件中选中我们之前下载的iso文件。
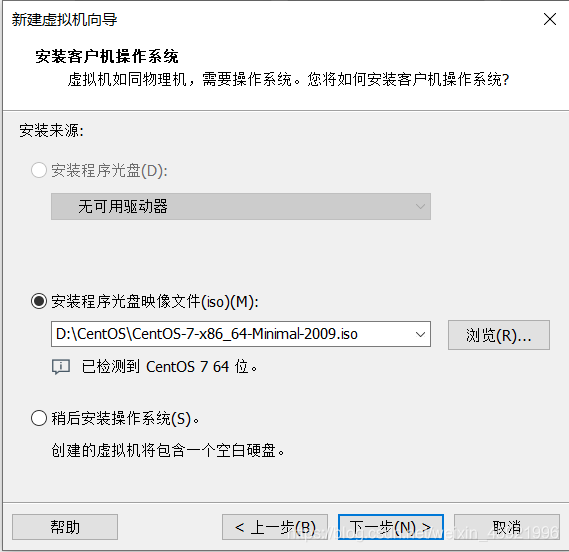
选则存放的地方默认是C盘,这里我放在D盘。
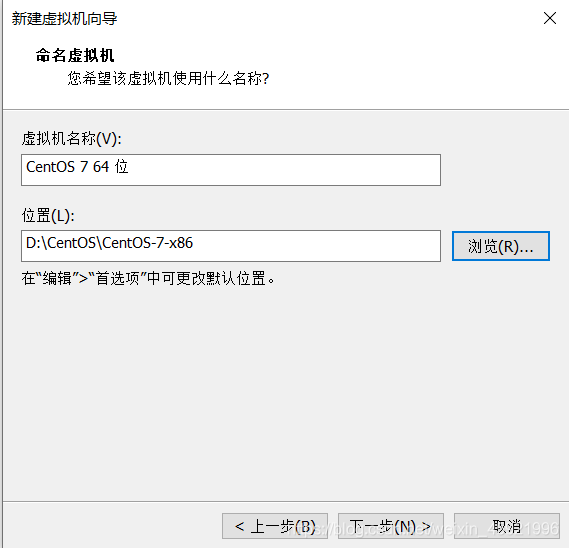
选择分给的硬盘大小,最小是20g可以自行安排分配大小。选则选中完成

选中第一个回车,等待加载。
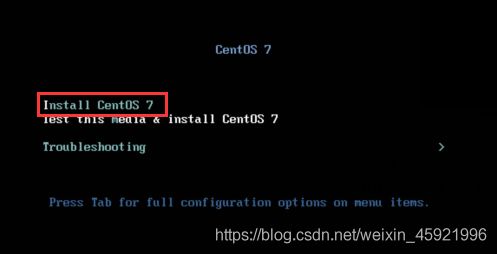
加载完成,进入到安装界面,选中中文简体,点击继续。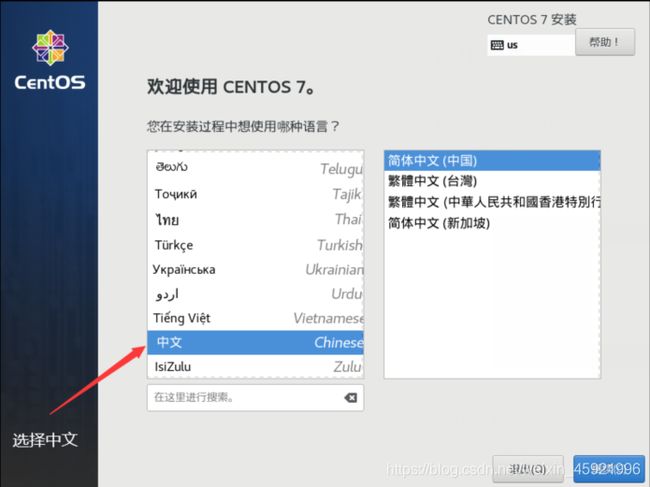
点击安装位置
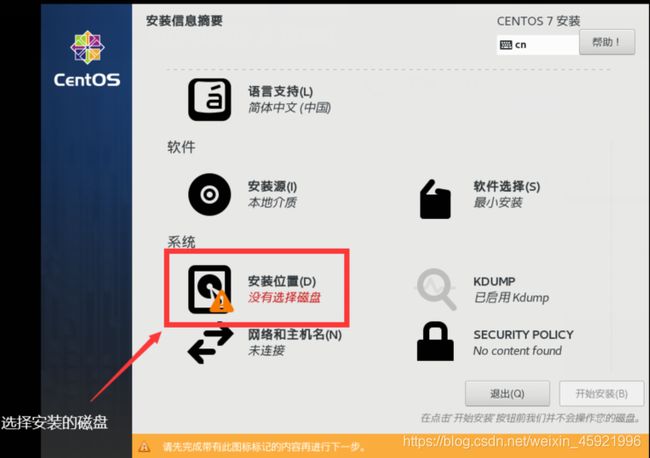
选择后点击完成
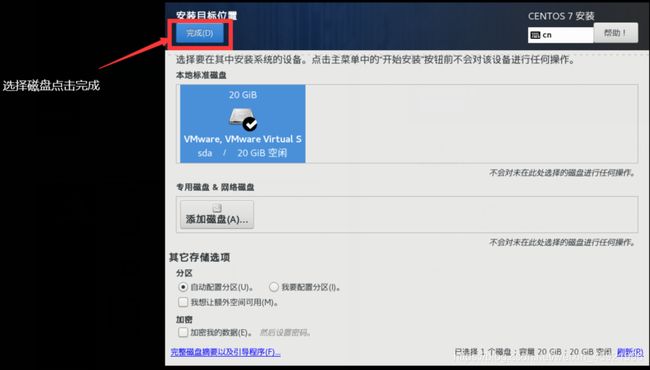
点击网络和主机名进行配置。
注意:打开以太网这里可能碰到显示如下图情况:
可能的原因我们没有打开相关的服务,我们进到任务管理器选择服务找到下面两个服务,打开它我们就可连上网了。
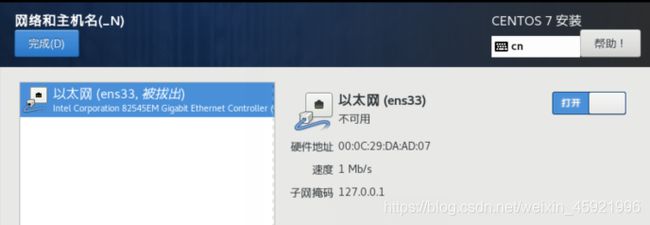

打开网卡之后点击配置。(这里要记得拍照截图后面我们用的到)

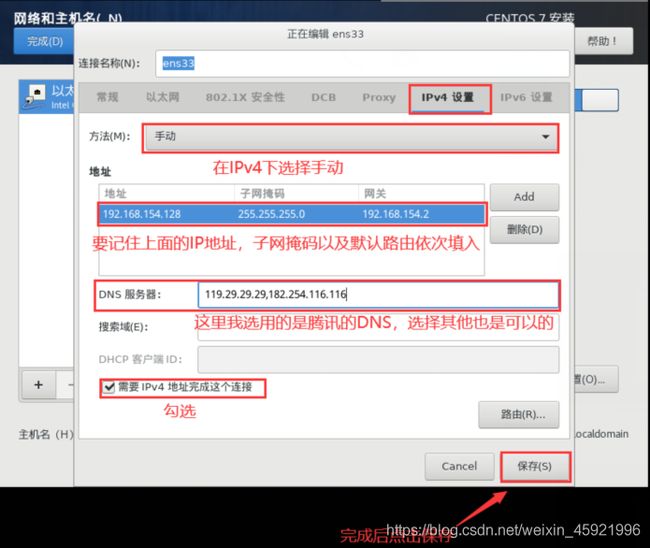
然后设置IPv4,将方法改为手动,目的是固定IP地址,方便之后的连接以及Hadoop集群的通信,点击Add添加地址就是刚刚截图的内容,如下图输入,网关就是路由IP地址。这里我刚开始用的腾讯的DNS,后面改用用阿里的DNS223.5.5.5,223.6.6.6,然后勾选IPv4点击保存。注意:这里要使用你们自己的IP地址,就是在配置网络时的IP要记住。
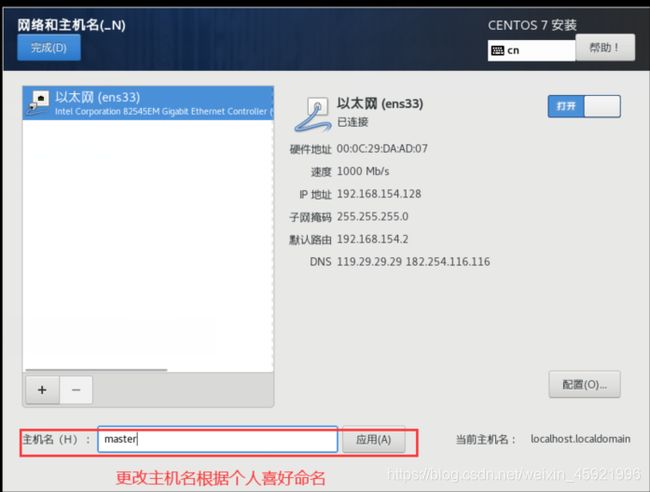
更改主机名。(根据个人喜好命名)
点击开始安装
点击配置ROOT密码,这里我们方便记,密码直接设为123456,然后点击两次完成即可。

安装完成后点击重启,在master login那一行输入root用户名。回车,输入刚刚设置的密码,这里密码是不显示的,不要误以为出bug了。
出现下面图片情况,表示安装成功。
![]()
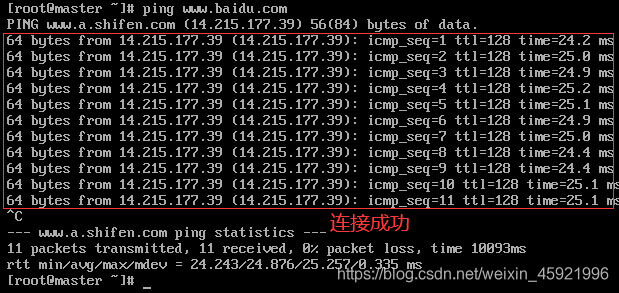
这里输入ping www.baidu.com测试虚拟机是否联网成功。出现下图证明外网连接成功。(按ctrl+c结束命令),到这CentOS7安装成功。
四、配置CentOS7
更细一下yum源,运行命令yum -y update。当看到Complete!表示更细完成。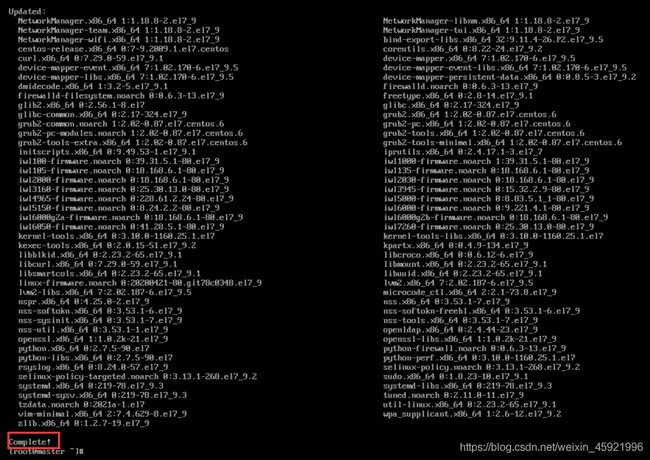
接下来是将系统的防火墙关闭。依次输入下面两个命令。
1.临时关闭防火墙 systemctl stop firewalld.service
2.永久关闭防火墙 systemctl disable firewalld.service

接着关闭Linux系统内核SELinux。输入vi /etc/selinux/config
linux中vi是编辑文本的命令,按下键盘上的字母 i ,才会进入编辑模式,按下后底下会提示为INSERT状态。
找到SELINUX=enforcing这一行,将enforcing修改为disabled,然后按下键盘的esc键。输入:wq进行保存并退出。w 指令表示写入文件,q 表示退出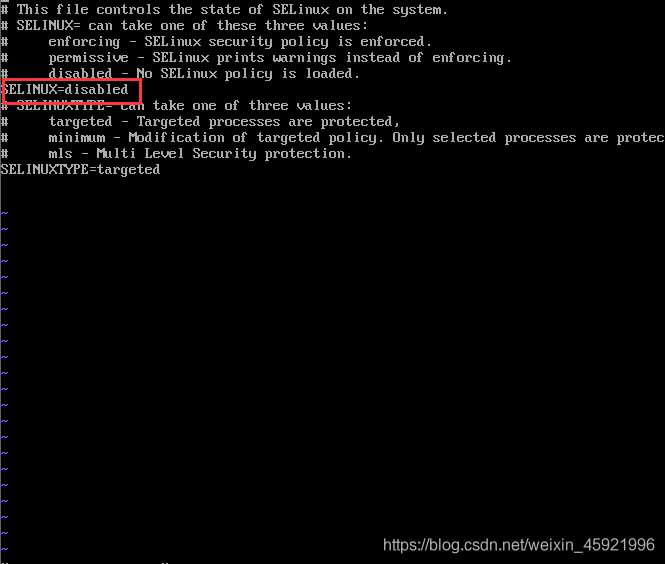
然后输入reboot命令回车重启系统,使命令生效。重启之后输入/usr/sbin/sestatus -v 查看SELinux是否被禁用

这里输入yum install vim -y 安装vim编辑器,作用vi命令一样,对后面修改Hadoop配置有帮助。
修改hosts文件,后面配置虚拟机将IP先添加到hosts当中。
输入:vim /etc/hosts
编辑hosts文件

这里的a1和a2分别在IP地址末尾加1,这里192.168.154.128是我上面安装虚拟机的IP地址。a1和a2后缀分别为.129和.130,前面的192.168.154要和master的一样。修改保存并退出。
接着创建Hadooptools文件夹,后面文件放在此文件夹。再根目录进行创建。依次输入下面命令:
cd /root
mkdir Hadooptools
cd Hadooptools
打开我们之前下载的XFTP。点击新建会话
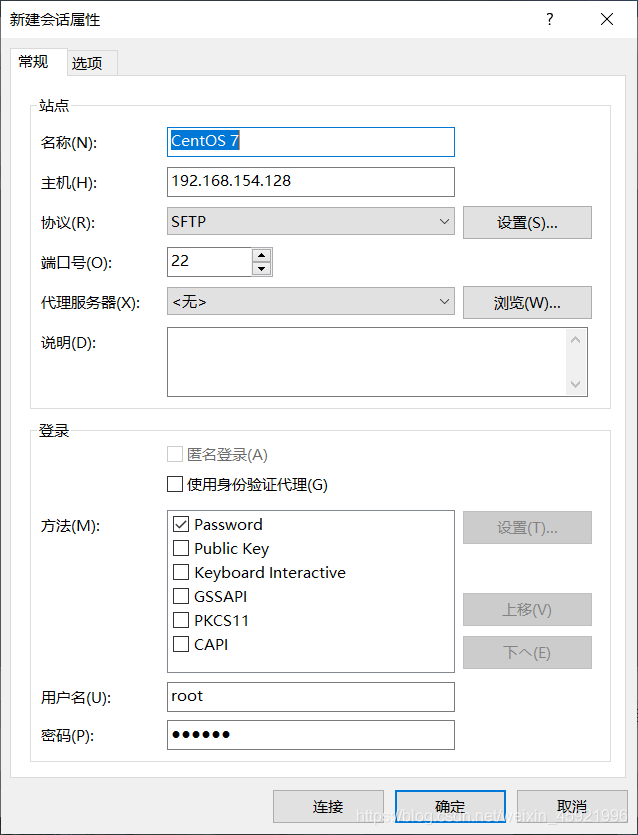
将我们之前的Hadoop安装包里的下面两个文件拖拽到/root/Hadooptools文件下
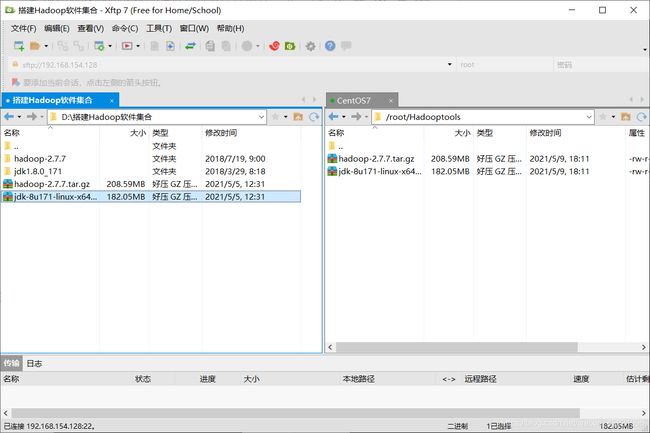
然后我们回到虚拟机,进入到Hadoop文件夹,然后查看是否上传成功。
进入到Hadooptools查看:cd /root/Hadooptools
输入:ls 查看

输入下面命令分别解压2个压缩包:
tar -zxvf hadoop-2.7.7.tar.gz
tar -zxvf jdk-8u171-linux-x64.tar.gz
解压完成之后,进行jdk的安装和配置
cd ~
ls -all

然后输入:vim .bash_profile
将下面内容添加到文件中:
![]()

保存退出后输入下面命令使其生效:source .bash_profile
然后输入java -version 查看是否成功,如下图表示配置成功。到此CentOS,配置完成,输入shutdown now关闭虚拟机。

五、克隆虚拟机,配置主机,搭建集群。
将我们目前的虚拟机名字修改为master。(右击选择重命名)
在VMware虚拟机选择如下操作:
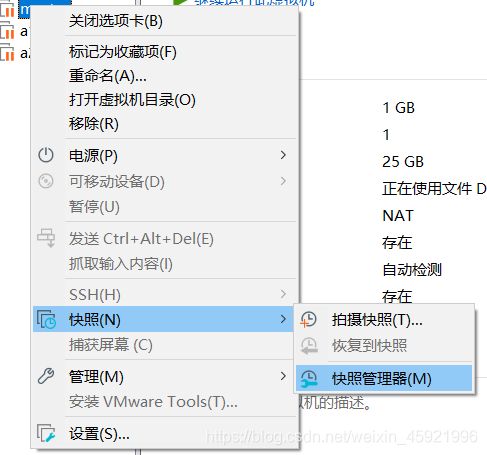
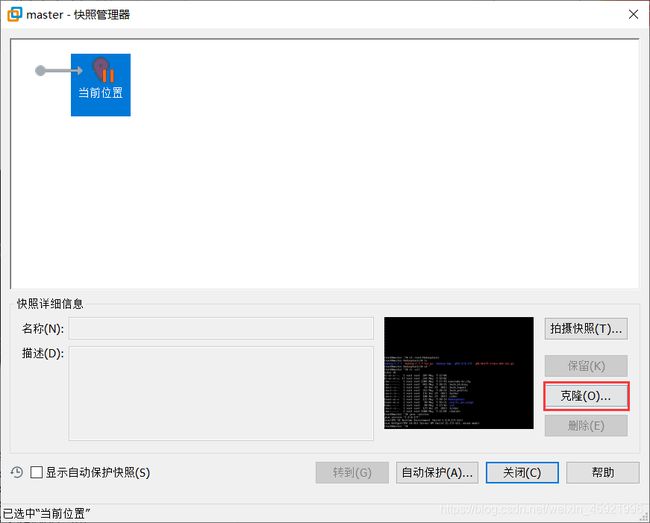
命名为a1,选择位置存放。点击完成,等待克隆完成,克隆完成点击关闭。
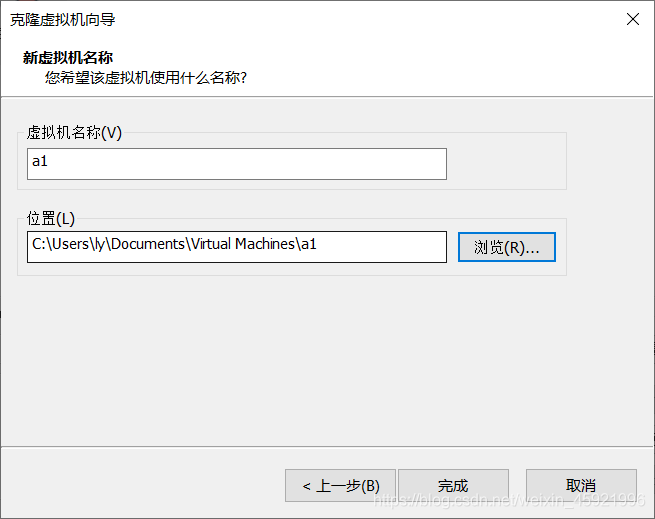

选择创建完整克隆,克隆创建2次,将这个两个虚拟机分别命名为a1,a2.如下图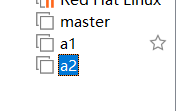
然后依次启动3台虚拟机,然后修改IP。进入a1虚拟机,输入下面命令,配置网络文件:
vim /etc/sysconfig/network-scripts/ifcfg-ens33 将其IPADDR改为192.168.154.129,保存退出后,输入service network restart 使配置生效
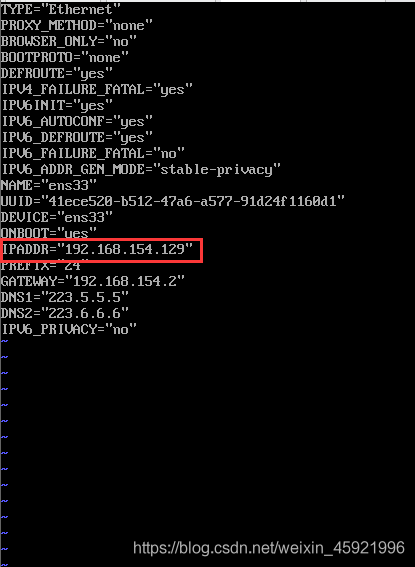
同样的命令配置a2,其地址为192.168.154.130.然后保存退出,同样命令使其生效。
接下来修改主机名,输入下面命令:
A1:hostnamectl set-hostname a1
A2:hostnamectl set-hostname a2
完成后分别输入logout用户登出。
在次登陆就可以看到我们的主机名变为a1.![]()
然后在master主机分别输入以下命令看是否能ping通。
ping master
ping a1
ping a2
下图表明master和a1,a2连接正常。依次在a1和a2做验证看是否成功。
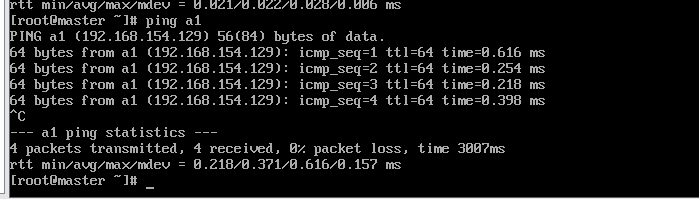
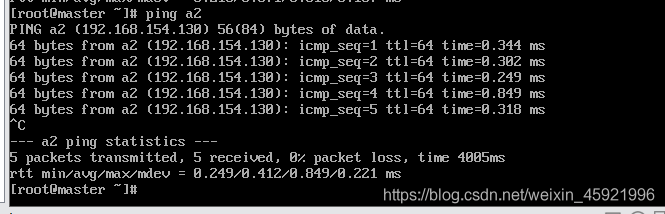
六、用Xshell连接三台虚拟机
点击新建会话
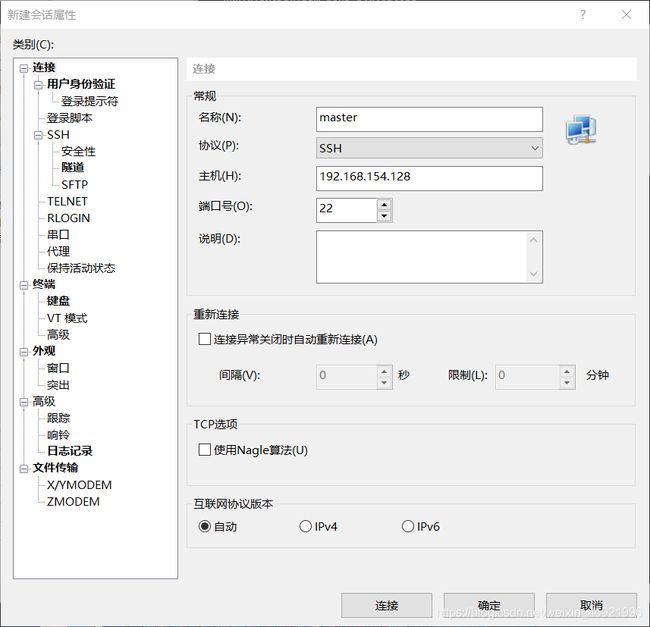
点击用户身份验证,用户名root,密码123456(我们之前配置的密码)。

在隧道找到如下图选项,取消勾选。
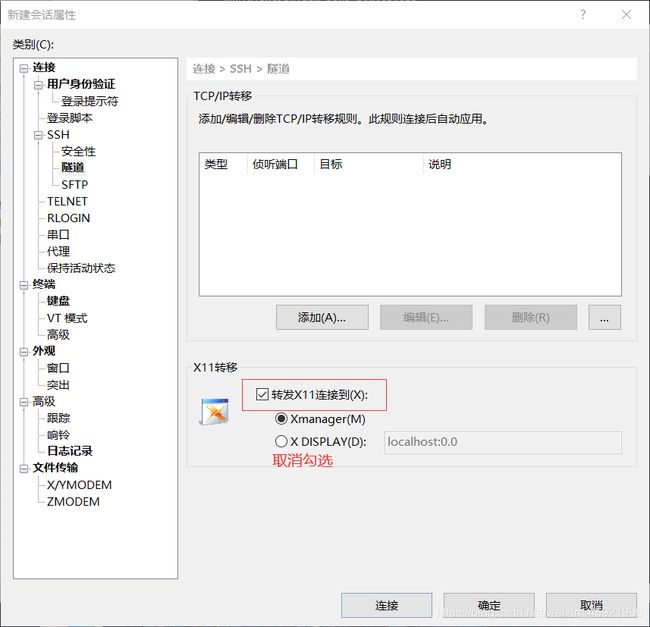
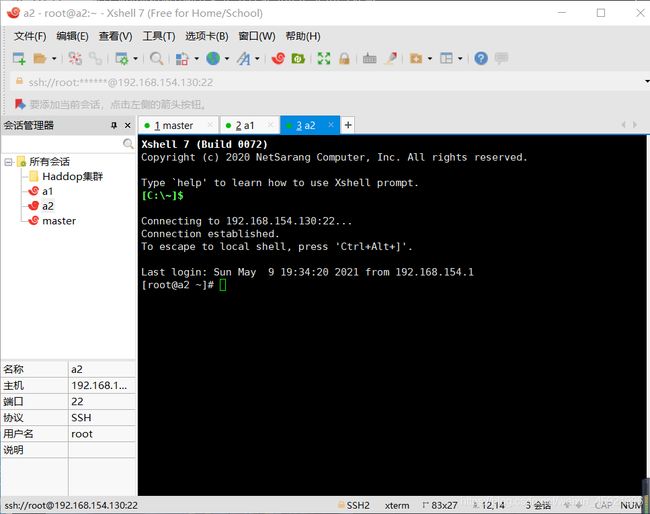
将三个会话全部进行连接上。
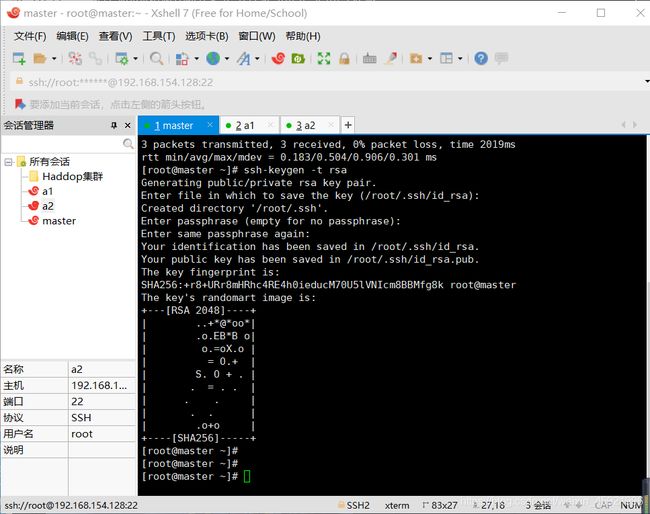
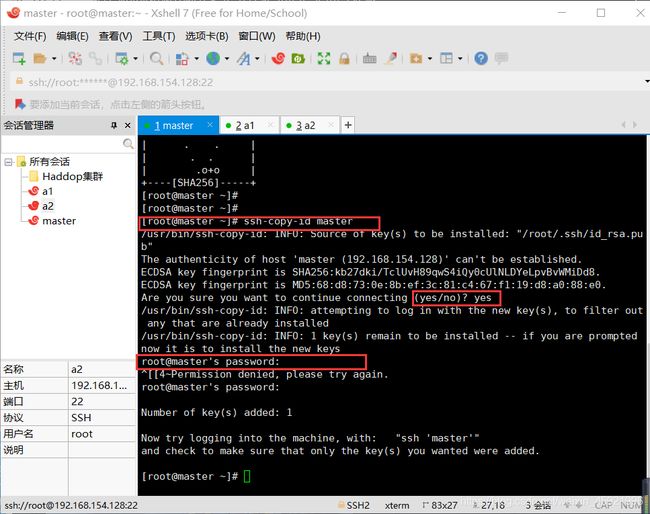
在xshell中制作免密码登陆,在master中输入以下命令:ssh-keygen -t rsa然后一直按回车直到命令结束。同样的操作子在,a1,a2中进行。
在master依次输入下面命令:
ssh-copy-id master
ssh-copy-id a1
ssh-copy-id a2
然后根据提示输入master,a1,a2的密码,这里就是实现了对登陆的免密操作。
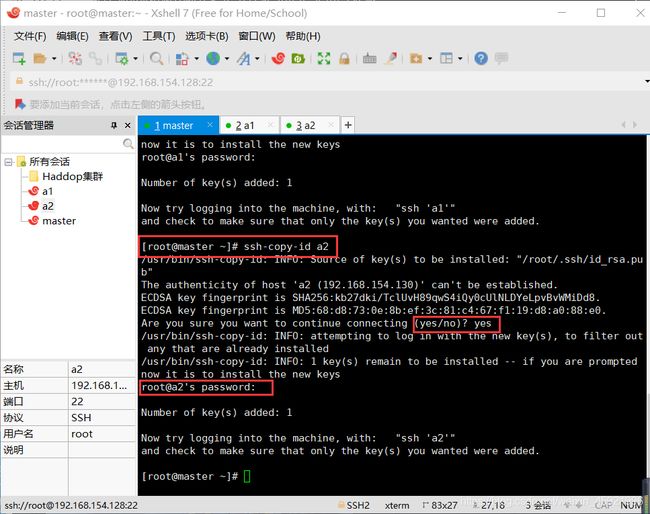
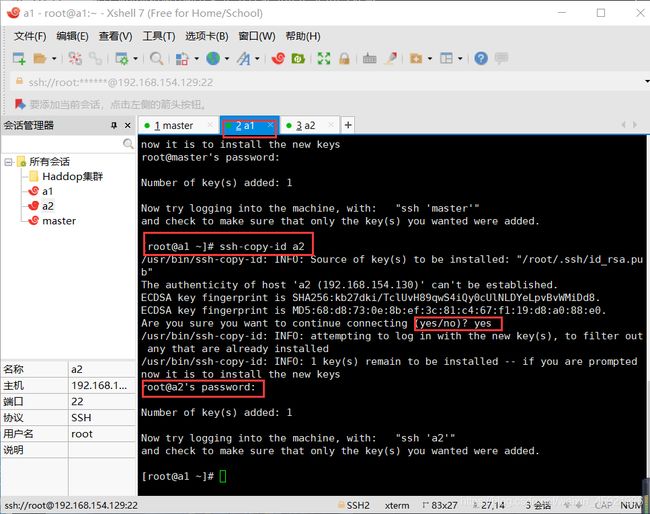
在a1中输入下面命令:
ssh-copy-id master
ssh-copy-id a2

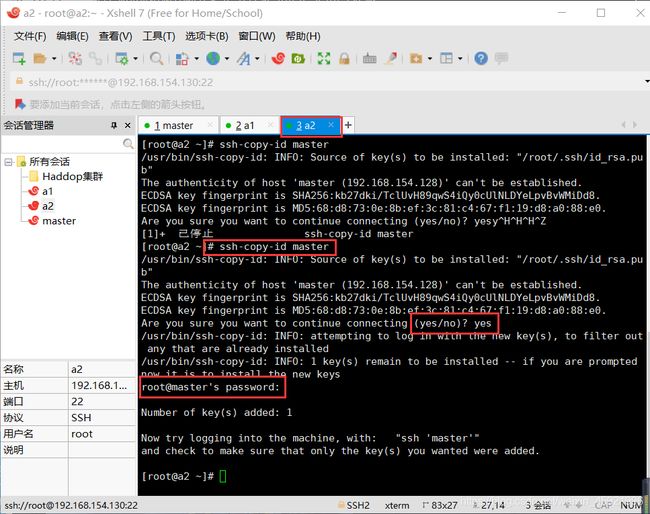
在a2中依次输入以下命令:
ssh-copy-id master
ssh-copy-id a1

通过ssh命令测试看是否设置免密登陆成功,如下图操作:
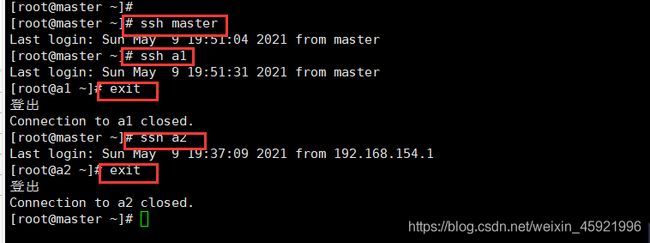
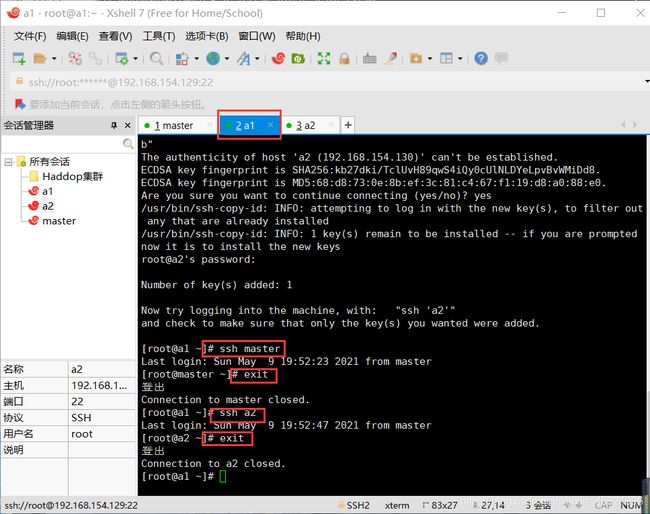
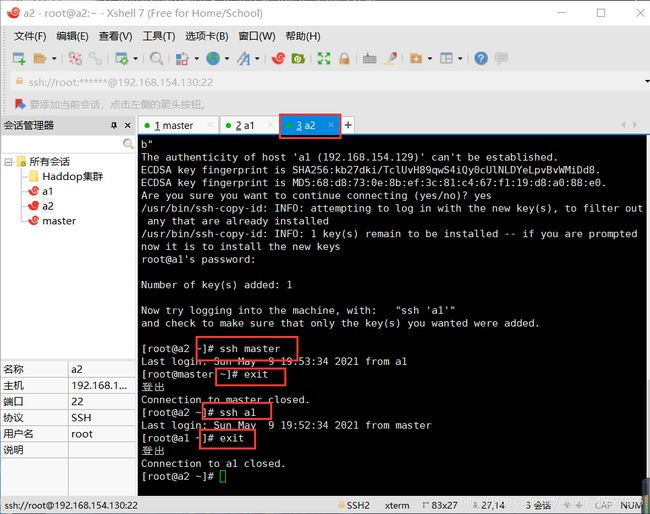
配置时间同步:
在master,输入:crontab -e
输入:0 1 * * * /usr/sbin/ntpdate cn.pool.ntp.org,保存并退出
输入clock检查时间是否正确。![]()
a1,a2配置同上。
七、配置Hadoop
下面的操作均在master上进行,只需将master操作里的修改等命令复制粘贴到a1,a2即可。
修改hadoop-env.sh
输入下面命令:cd /root/Hadooptools/hadoop-2.7.7/etc/hadoop/进入到
hadoop-2.7.7文件夹。
输入下面命令修改hadoop-env.sh。
vim hadoop-env.sh
将export JAVA_HOME修改为下面的值,然后保存并退出。
# The java implementation to use.
export JAVA_HOME=/root/Hadooptools/jdk1.8.0_171
修改yarn-env.sh
输入:vim yarn-env.sh
修改JAVA_HOME,然后保存退出。
# some Java parameters
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
if [ "$JAVA_HOME" != "" ]; then
#echo "run java in $JAVA_HOME"
JAVA_HOME=/root/Hadooptools/jdk1.8.0_171
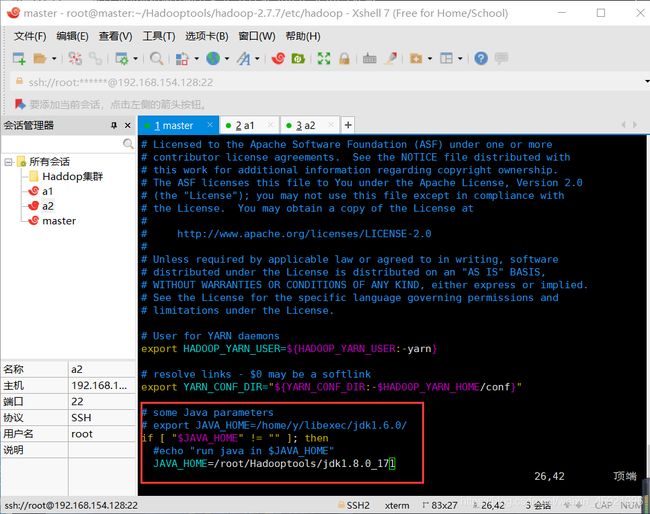
修改core-site.xml
输入:vim core-site.xml,修改 core-site.xml
将下面内容复制粘贴到文件中,然后保存退出。
fs.default.name
hdfs://master:9000
配置NameNode的URL
hadoop.tmp.dir
/root/Hadooptools/hadoop-tmp

目前系统中是没有这个目录的,后面需要新建这个目录
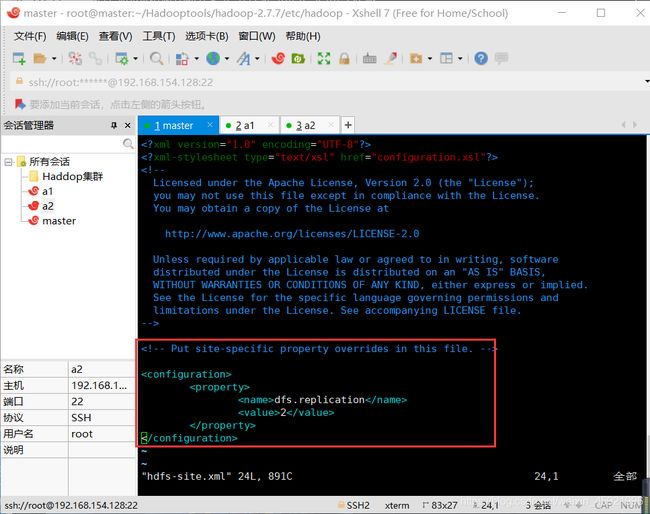
修改hdfs-site.xml
输入:vim hdfs-site.xml,修改 hdfs-site.xml
将下面内容粘贴到文件中,再保存退出。
dfs.replication
2
修改mapred-site.xml
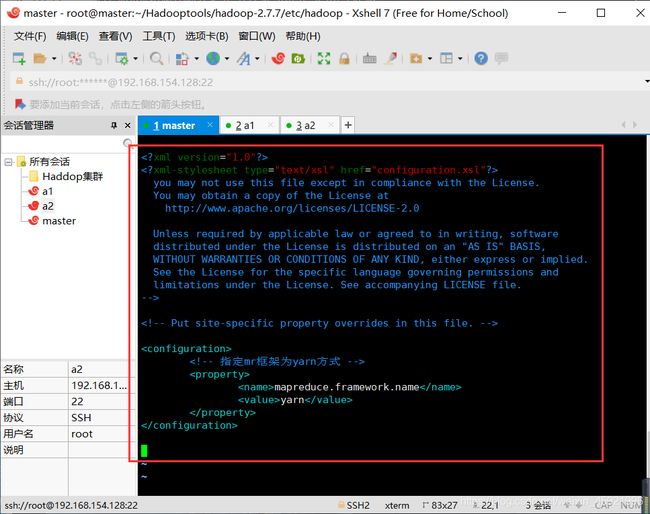
输入:vim mapred-site.xml,修改 mapred-site.xml
将下面内容粘贴到文件中,保存退出。
mapreduce.framework.name
yarn
修改yarn-site.xml
输入:vim yarn-site.xml,修改 yarn-site.xml
将下面内容粘贴到文件中:
yarn.resourcemanager.hostname
master
yarn.nodemanager.aux-services
mapreduce_shuffle
修改slaves
输入:vim slaves,修改 slaves
粘贴以下内容到文件:
master
a1
a2
建立hadoop-tmp文件夹
进入到Hadooptools文件夹下,新建文件夹(依次输入):
cd /root/Hadooptools/
mkdir hadoop-tmp
删除a1,a2上的Hadooptools文件夹
依次再a1,a2,上执行,输入下面命令:
rm -rf /root/Hadooptools/
将 master 上的 Hadooptools文件夹复制到a1,a2上,输入下面命令:
scp -r /root/Hadooptools root@a1:/root/
scp -r /root/Hadooptools root@a2:/root/
配置系统环境变量
输入下面命令:vim /root/.bash_profile
将下面内容添加到文件中:
export HADOOP_HOME=/root/Hadooptools/hadoop-2.7.7
export PATH=$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:
然后执行source /root/.bash_profile,使其生效。
a1,a2虚拟机配置同上。
格式化hadoop文件系统
注意:,该命令只能执行一次不可执行多次。要确保准确无误。
输入:hdfs namenode -format
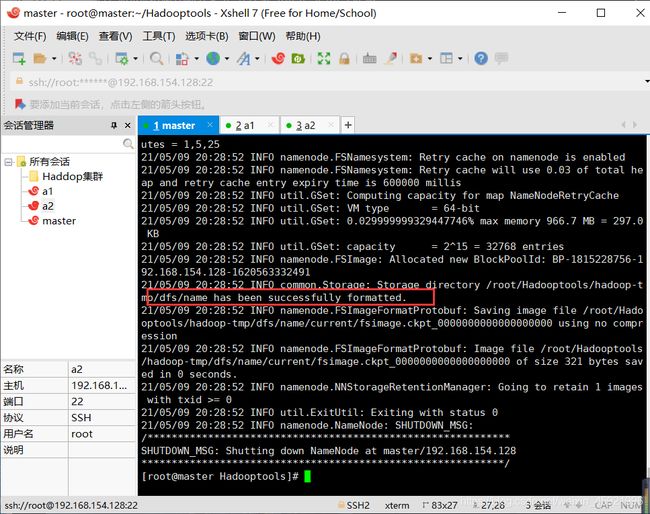
当看到successful信息时,表明格式化成功。
八、启动Hadoop集群
输入:start-all.sh
![]()
根据提示,输入yes。用主浏览器访问 http://192.168.154.128:50070 查看启动是否成功
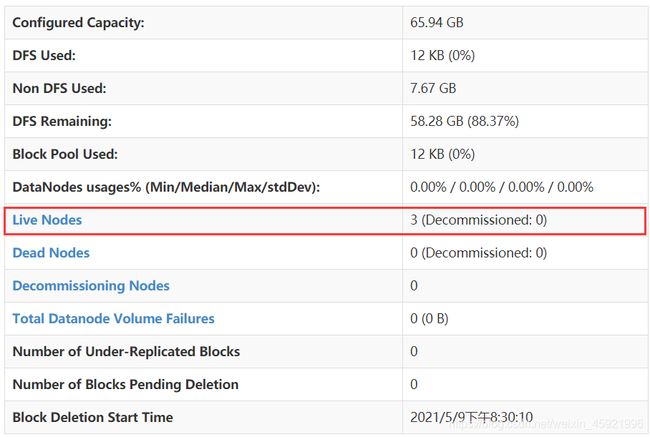
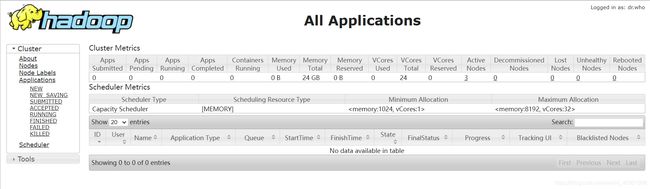
再上图可以看到有3台节点同时在线,如果不是3台证明有问题,需要查看哪里出错了。如果是3台表示配置成功。
登陆yarn的WebUI http://192.168.154.128:8088/
安装spark
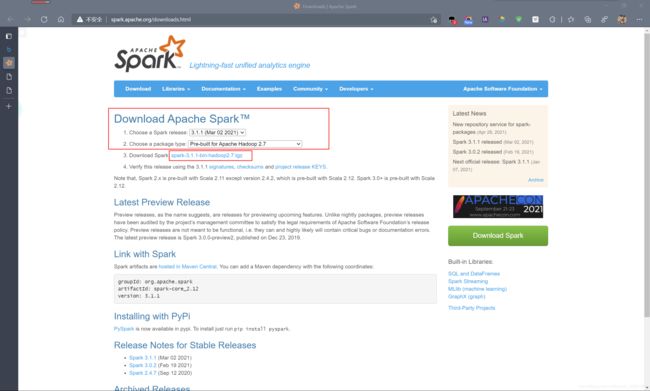
登陆Apache spark官网下载spark
地址:http://spark.apache.org/downloads.html
选择如下图:
将下载下了的压缩包使用XFTP传到master主机:
在Xshell中解压刚刚上传的压缩包(依次输入下面命令):
cd /root/Hadooptools
tar -zxvf spark-3.1.1-bin-hadoop2.7.tgz
将spark-3.1.1-bin-hadoop2.7文件夹名字修改成spark
输入:mv spark-3.1.1-bin-hadoop2.7 spark
修改环境变量,添加spark
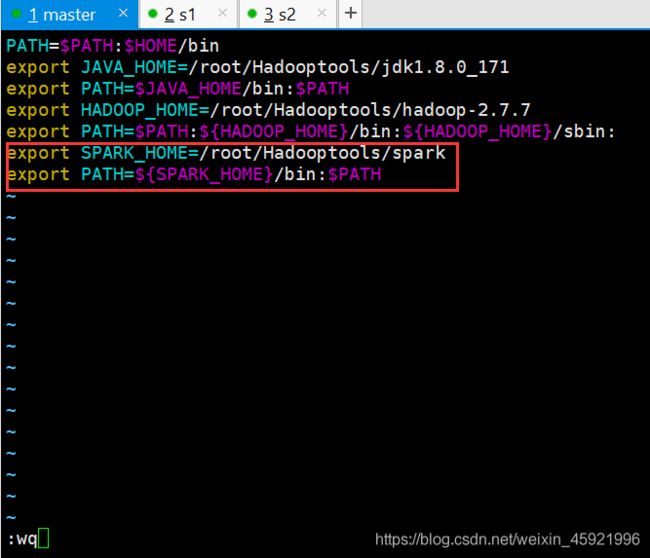
输入:vim /root/.bash_profile
添加下面内容:
export SPARK_HOME=/root/Hadooptools/spark
export PATH=${SPARK_HOME}/bin:$PATH
输入:source /root/.bash_profile,使其生效。
编辑spark-env.sh
输入:cd /root/Hadooptools/spark/conf/
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
将下面内容添加到文件中:
export JAVA_HOME=/root/Hadooptools/jdk1.8.0_171
export SPARK_MASTER_IP=192.168.154.128
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/root/Hadooptools/hadoop-2.7.7/etc/hadoop
添加a1,a2节点信息
vim /root/Hadooptools/spark/conf/slaves
在文件中添加,保存退出:
a1
a2
将spark文件夹复制到a1,a2
运行下面命令:
cd /root/Hadooptools
scp -r spark root@s1:/root/Hadooptools/
scp -r spark root@s2:/root/Hadooptools/
进入spark文件夹,启动spark
运行以下命令:
cd /root/Hadooptools/spark/sbin/
./start-all.sh
在主机的浏览器中访问地址:http://192.168.154.128:8080 ,查看是否能成功访问
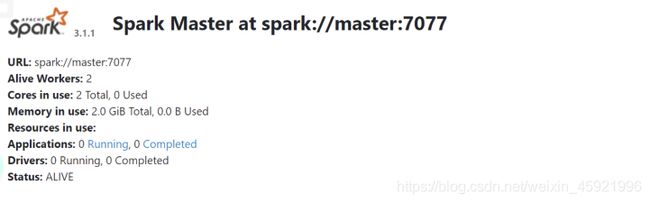
测试spark运行是否正常
运行以下命令:
cd /root
./Hadooptools/spark/bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 /root/Hadooptools/spark/examples//jars/spark-examples_2.12-3.1.1.jar 100
然后打开spark的WebUI查看运行情况
http://192.168.154.128:8080

到此本章教程已结束,感谢阅读!
文章作者: 南风未闻
文章链接: https://blog.csdn.net/weixin_45921996/article/details/116424548
版权声明: 转载请注明来自 南风未闻的博客