VOC2007格式数据集的制作及YOLOv3权重文件的训练
最近刚刚接触深度学习,做yolov3的数据集。将自己的参考的方法总结一下,并将自己学习过程中遇到的问题都说明一下,让刚刚和我一样接触的少走一些弯路。
1.darknet的安装及编译测试
darknet深度学习框架是由Joseph Redmon提出的一个用C和CUDA编写的开源神经网络框架。它安装速度快,易于安装,并支持CPU和GPU计算。
(1)下载darknrt并编译
终端命令:
$ git clone https://github.com/pjreddie/darknet
$ cd darknet如果使用CPU操作,直接接着上面输入
~/darknet$ make如果使用GPU操作,则需要对darknet文件下的Makefile文件修改
1 GPU=1
2 CUDNN=1
3 opencv=1//如果安装了opencv并需要使用可以设置为1
...
24 NVCC=/usr/local/cuda/bin/nvcc然后在输入
~/darknet$ make注:①如果使用GPU训练,需要安装显卡驱动+suda+nvcc。网上有教程,安装过程较麻烦
②如果都安装完毕依然报错没有找到nvcc.h的头文件,那么可以将Makefile文件中CUDNN还是改为0
(2)下载权重文件测试
wget https://pjreddie.com/media/files/yolov3.weights这个文件240多M可能有点慢 也可以在网上搜yolov3.weights进行下载之后在
./darknet detect cfg/yolov3.cfg yolov3.weights data/person.jpg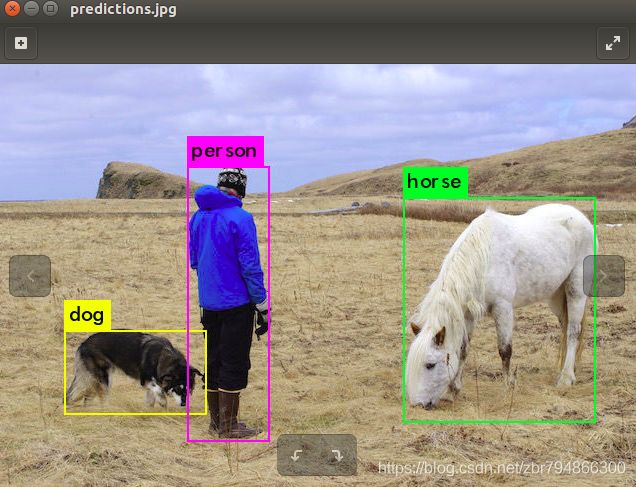
也可以选择data目录下的其他图片测试或者你下载的图片测试。如果安装亮opencv并将Makefile中opencv的值设为1,就直接在终端窗口弹出检测结果图;若没有设置,检测完之后图片在darknet文件夹下。
2 VOC2007格式数据集制作
建议现在按照标准数据集格式在darknet文件下创建文件夹
/home/xxx/darknet/VOCdevkit/VOC2007/并在VOC2007目录下创建以下4个目录:Annotations、ImageSets、JPEGImages、labels
然后在Annotations目录下创建Main目录。创建好上述目录结构后,将自己准备的数据集图片拷贝到JPEGImages目录下,并最好按照VOC2007数据集格式命名,例如:000001.jpg ,000002.jpg。其中图片长宽比不要太大。
注:图片的大小最好统一修改像素大小,可以调整为416*416。之前吃过亏,图片大小没统一,后续的训练结果有问题,导致整个标注工作全部白费。python批量修改尺寸代码
此处附一段重命名批量处理的python代码:
# -*- coding:utf8 -*-
import os
class BatchRename():
'''
批量重命名文件夹中的图片文件
'''
def __init__(self):
self.path = '/home/xxx/darknet/VOCdevkit/VOC2007/JPEGImages' #表示需要命名处理的文件夹
def rename(self):
filelist = os.listdir(self.path) #获取文件路径
total_num = len(filelist) #获取文件长度(个数)
i = 1 #表示文件的命名是从1开始的
for item in filelist:
if item.endswith('.png'): #初始的图片的格式为jpg格式的(或者源文件是png格式及其他格式,后面的转换格式就可以调整为自己需要的格式即可)
src = os.path.join(os.path.abspath(self.path), item)
#dst = os.path.join(os.path.abspath(self.path), ''+str(i) + '.jpg')#处理后的格式也为jpg格式的,当然这里可以改成png格式
dst = os.path.join(os.path.abspath(self.path), '000' + format(str(i), '0>3s') + '.jpg') #这种情况下的命名格式为000000.jpg形式,可以自主定义想要的格式
try:
os.rename(src, dst)
print ('converting %s to %s ...' % (src, dst))
i = i + 1
except:
continue
print ('total %d to rename & converted %d jpgs' % (total_num, i))
if __name__ == '__main__':
demo = BatchRename()
demo.rename()
样本图片准备好之后,就可以进行标注工作。标注工具是大神提供的labelmg工具,链接:https://github.com/tzutalin/labelImg
其中有具体的做法,通篇英文,我把我自己犯的错误也在总结一下。
(1)先安装相应的运行环境
我的系统是unbuntu16.04,我先安装了python3和qt5,因为后面的工作必须在这个基础上,pythonh和qt的最低版本要求,链接中有提到,python3和qt5是没问题的。至于安装网上都有现成的可以根据你自己的版本去搜索。之所以安装qt和python,是因为这个标注工具是大神写的代码,是qt的可视化界面,所有必须有这两个基础的平台。
(2)终端输入命令:
git clone https://github.com/tzutalin/labelImg.git
cd labelImg
sudo apt-get install pyqt5-dev-tools
sudo pip3 install lxml
make qt5py3
python3 labImage.py
如果一切顺利,最后就会显示一个可视化标注界面出来。


然后就可以进行漫长的标注。当然,全靠鼠标点会慢很多,所有还有很多快捷键可以大大提高标注效率,在标注工具那个链接中也有提到,我这里再简单说一下:
首先,进入到标注界面,先Ctrl+u 加载图片文件夹,当然这里选到JPEGimage里的;
其次,在点Change save Dir,保存文件选择到Annotations;
最后,在说一下常用快捷键:
w:出现标注框,用鼠标左键点击拖动框目标物
Ctrl+s:保存,每张图片标注完都需要保存
A:上一张图
D:下一张图
Ctrl+e:对标错名字的目标改名
然后就慢慢标注吧。。。
(3)生成样本集/测试集等
在VOC2007目录下创建python脚本文件gen.py
import os
import random
trainval_percent = 0.5
train_percent = 0.5
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets/Main'
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
ftrainval = open(txtsavepath+'/trainval.txt', 'w')
ftest = open(txtsavepath+'/test.txt', 'w')
ftrain = open(txtsavepath+'/train.txt', 'w')
fval = open(txtsavepath+'/val.txt', 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close()
然后运行该脚本
python3 gen.py会在ImageSets/Main目录下生成以下文件:test.txt、train.txt、trainval.txt、val.txt
接着下载格式转换文件,生成yolo需要的格式:
cd darknet
wget https://pjreddie.com/media/files/voc_label.py
gedit voc_label.py修改voc_label.py文件

那个分类根据具体情况,你标注的类型具体修改
运行voc_label.py完成转换
python3 voc_label.py运行后会在darknet目录下生成2007_test.txt、2007_train.txt、2007_val.txt三个文件,此处将train和val的数据一起用来训练,因此将其合并为train.txt。
cat 2007_train.txt 2007_val.txt > train.txt此时会在darknet文件夹中生成train.txt文档
3.制作相关修改文件
(1) 修改.names文件
进入darknet/data目录,复制该目录下的voc.names文件,命名为xxx.names,并将其中的内容修改为自己要检测的目标类别名
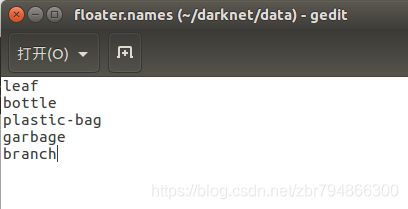
此处我改的floater.names,同时将里面的目标类名改我我要检测的
(2)修改.data文件
进入darknet/cfg目录,复制该目录下的voc.data文件,命名为xxx.data,并进行如下修改:
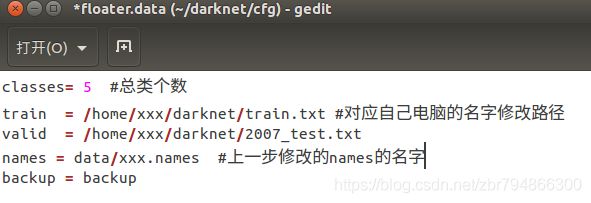
注:要看darknet目录下是否有backup目录,若没有,需要新建该目录。最后训练的权重文件就在这个文件夹内
(3) 修改.cfg文件
进入darknet/cfg目录,复制该目录下的yolo3-voc.cfg文件,命名为xxx.cfg,并进行如下修改(标#注释处为修改的地方):
注释掉文件开头的Testing,取消对Training的注释,如下所示
[net]
# Testing
# batch=1 #训练的时候注释这两行,测试的时候取消注释
# subdivisions=1 #
# Training
batch=64 #训练的时候取消注释,测试的时候注释这两行
subdivisions=16 #
...
[convolutional]
size=1
stride=1
pad=1
filters=36 #3*(classes+5)
activation=linear
[yolo]
mask = 6,7,8
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=7 #你要训练多少个类
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=1
[convolutional]
size=1
stride=1
pad=1
filters=75
activation=linear
[yolo]
mask = 3,4,5
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=20
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=1
[convolutional]
size=1
stride=1
pad=1
filters=36 #3*(classes+5)
activation=linear
[yolo]
mask = 0,1,2
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=7 #classes
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=1 #1,如果显存很小,将random设置为0,关闭多尺度训练
注:需要修改的一共有上面这些注释的地方,一定要修改完,否则训练出来测试时可能会报核转移的错误。
4.下载训练权重文件并进行训练
(1)下载训练权重文件
cd darknet
wget https://pjreddie.com/media/files/darknet53.conv.74(2)训练
./darknet detector train cfg/xxx.data cfg/xxx.cfg darknet53.conv.74注:xxx.data和xxx.cfg根据自己修改的名字更改
然后就是漫长的等待。。。
其中训练的参数理解参考YOLOv3训练过程中重要参数的理解和输出参数的含义
训练完那之后得会在backup文件夹里得到权重文件,前1000次,每100次保存一个,1000次以后,每一万次保存一次如下图所示:
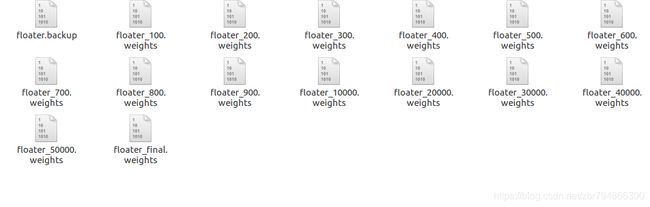
其中 .backup文件是一个保存文件,下次你可以从这里继续训练。比如你训练中途断电了(遇到过这个问题),你不知道你训练ll了多少,你可以直接使用下面的命令:
./darknet detector train cfg/xxx.data cfg/xxx.cfg backup/xxx.backup
//xxx是你自己修改data文件和cfg文件的命名,我这里就是floater.data .cfg .backup这样就可以继续上次训练。
对于多少次保存一次的问题,也在此说明以下:
通过修改darknet/example目录下的detector.c文件中138行左右。默认的是1000次以内每100保存一次,1000次以后每10000次保存一次,内衣通过更改if()内的判断自由发挥:
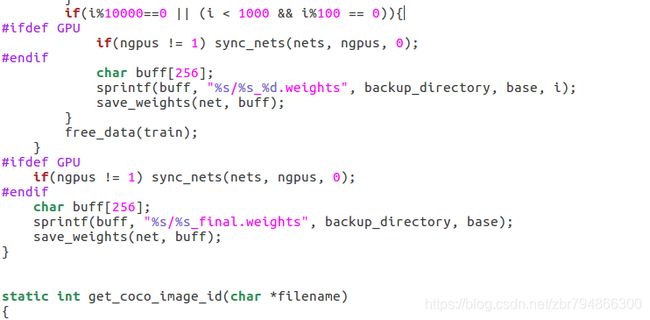
比如改成if(i%1000==0) 每1000次保存一次
测试命令:
./darknet detect cfg/xxx.cfg backup/xxx.weights
加保存日志训练命令:.
/darknet detector train cfg/xxx.data cfg/xxx.cfg darknet53.conv.74 -gpu 0 | tee train_floater.logGPU编号可以看你具体情况改,默认的是0
保存的日志后续可以用来可视化avg-loss和avg-iou,得到可视化的图片类似:
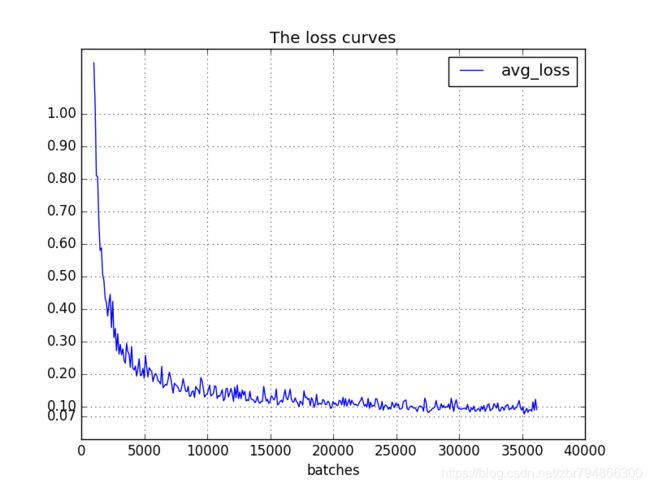
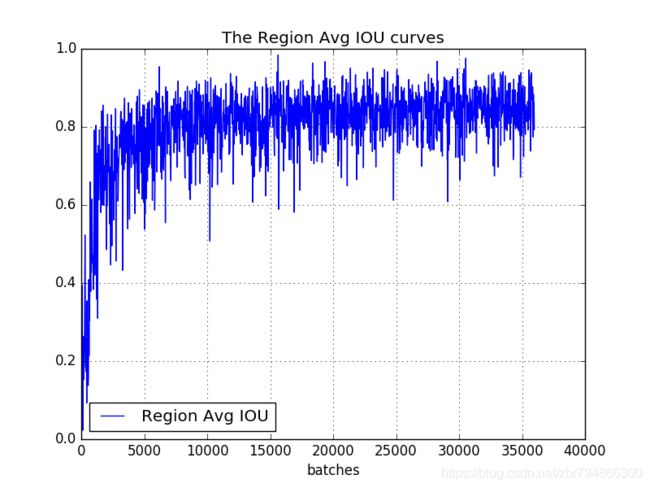
训练参数可视化参照:https://blog.csdn.net/qq_34806812/article/details/81459982
darknet测试命令:https://blog.csdn.net/weixin_30559481/article/details/98936804
出现核心已转储的原因:https://blog.csdn.net/ncepukzh/article/details/88805269
测试结果:
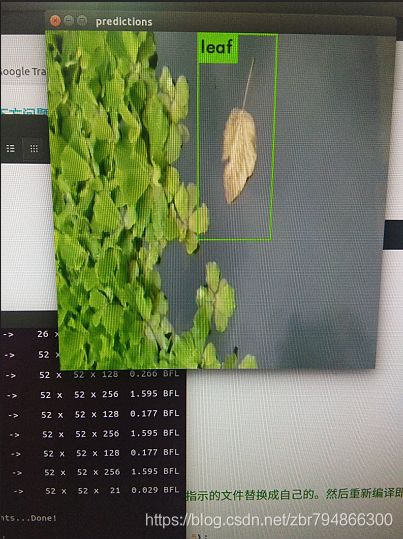
得到到结果没有置信度显示,想要显示置信度,参考:https://blog.csdn.net/syyyy712/article/details/86776828
参考文献:
https://blog.csdn.net/qq_25349629/article/details/87556981