python情感分析中文_【python机器学习】中文情感分析
3月31日,3月最后的一天接到了腾讯HR终面,看着招聘官网变成已完成还有点小自豪呢python

而后百度搜了搜显示“已完成”是否是稳了,原来不是,好多最后被通知没被录取。。。。web

随缘吧~代码还要继续码,博客还要继续更,论文还要继续写。。。。。正则表达式
数据源app
公众号文章:Python有趣|中文文本情感分析
罗罗攀在里面有发数据,你们之后能够跟着他的公众号进行学习,很是适合我这种小白哈哈哈哈哈哈
这是大众点评上的评论数据(王树义老师提供)dom
原始数据svg
import pandas as pd
import csv
import numpy as np
data = pd.read_csv(r'C:\Users\xuxiaojielucky_i\Desktop\data1.csv',encoding='utf-8')
data.head()

情感分析——分类函数
能够看到数据中有一列是平分(star)数据,咱们看先这个数据有哪些分值。能够看到分值有1,2,4,5四中等级。学习
data['star'].unique()

对数据进行标注,咱们假定分数小于3的为消极并标注为0,大于3的分数为积极并标注为1,经过1和0 对数据进行分类,所以咱们定义一个函数,用apply方法获得一个新的列(分类的列)。测试
def make_label(star):
if star > 3:
return 1
else:
return 0
data['setiment'] = data.star.apply(make_label)
data.head()

snownlpui
python最强大的地方就是第三方库,其实有现成的库能够直接对文本进行情感分析,如snownlp,直接调用返回的是积极情绪的几率,咱们来调用一下吧~

import snownlp
text1 = '个人卷发棒在哪?'
text2 = '你的卷发棒就棒在十分撑托你的美!'
s1 = Snownlp(text1)
s2 = Snownlp(text2)
print(s1.sentiments,s2.sentiments)
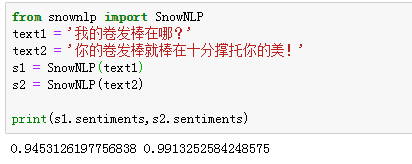
啊哈哈哈哈不咋准,由于没有进行训练,他不知道“卷发棒”是一个词,一直都以为人工智能这个领域产生了一个很是廉价枯燥的工做岗位——数据标注实习生 = =
from snownlp import SnowNLP
text1 = '这个通常般!'
text2 = '这个太棒了!'
s1 = SnowNLP(text1)
s2 = SnowNLP(text2)
print(s1.sentiments,s2.sentiments)
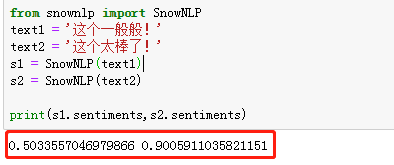
一样,咱们对他进行一个定义,大于0.5的咱们认为是积极,小于0.5的咱们认为是消极。
def snow_result(comment):
s = SnowNLP(comment)
if s.sentiments >= 0.5:
return 1
else:
return 0
data['snlp_result'] = data.comment.apply(snoe_result)
data.head()
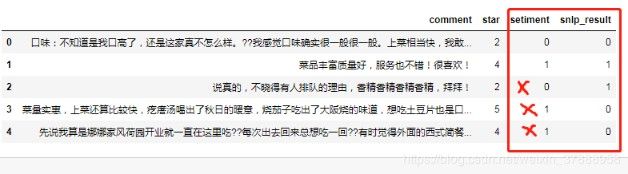
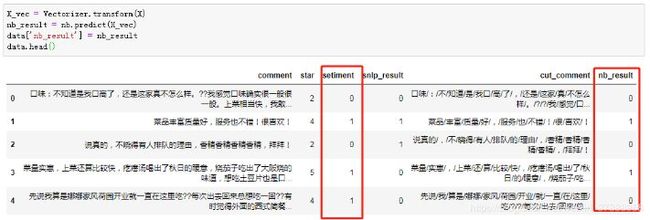
效果不咋地哇,但可能只是这5个效果很差,总体来看也许还行,就算下他的准确度吧~
counts = 0
for i in range(len(data)):
if data.iloc[i,2] == data.iloc[i,3]:
counts+=1
print(counts/len(data))
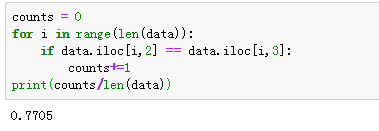
效果确实不咋地,还有就是这个库是通用的,一些有针对性的词可能都不能识别,好比香精,可能认为“香”的积极性会比较高。
朴素贝叶斯
以前用的是snownlp库,没有针对性,咱们能够训练本身的模型,这里咱们使用sklearn实现朴素贝叶斯模型。
分词
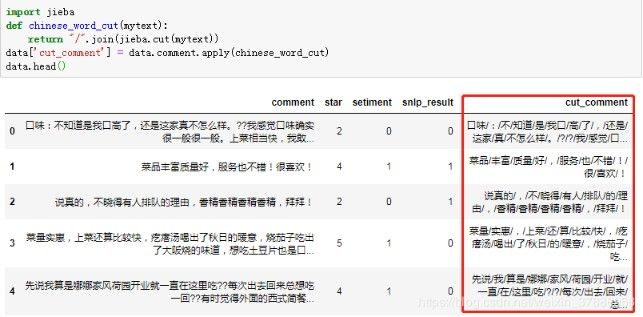
使用jieba分词对评论数据进行分词。
import jieba
def chinese_word_cut(mytext):
return "/".join(jieba.cut(mytext))
data['cut_comment'] = data.comment.apply(chinese_word_cut)
data.head()
划分数据集
先学习下sklearn的划分数据集的基本用法
基本用法
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(train_data,train_target,test_size=0.2, random_state=22)
train_data:样本特征集
train_target:样本标签集
test_size:样本占比,测试集占数据集的比重
random_state:是随机数的种子。在同一份数据集上,相同的种子产生相同的结果,不一样的种子产生不一样的划分结。其实就是保证每次的随机数是同样的,否则每次实验随机出来的结果不一样。作一个实验写同样就行。
X_train,y_train:构成了训练集
X_test,y_test:构成了测试集
X = data['cut_comment']
y = data.sentiment
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=19113122)
词向量
天然语言处理第一步就是词向量特征的提取。
语言的特征提取在sklearn模块中有至关完善的方法和模块,而针对中文其实也能够同分词软件作分词而后再按照英文文本的思路开展特征提取。
这里就用到sklearn的CountVectorize
几个关键的参数
参数
做用
token_pattern
过滤规则,表示token的正则表达式,通常用来过滤数字和标点符号
max_df
能够设置为范围在[0.0 1.0]的float,也能够设置为没有范围限制的int,默认为1.0。若是这个参数是float,则表示词出现的次数与语料库文档数的百分比,若是是int,则表示词出现的次数。
min_df
同max_df
stop_words
设置停用词,若是是英文使用内置的英语停用词,设为list可以使用自定义停用词,设为None不使用停用词,设为None且max_df∈[0.7, 1.0)将自动根据当前的语料库创建停用词表
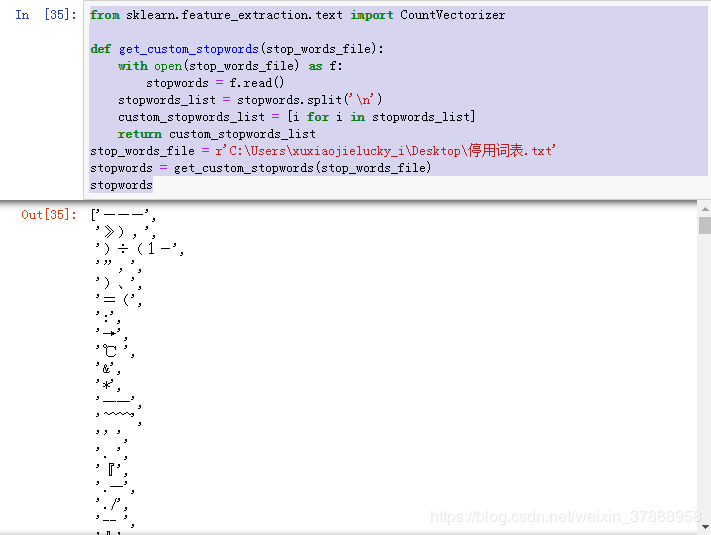
设置中止词表
若是使用自定义的中止词表,须要转换成list的形式
from sklearn.feature_extraction.text import CountVectorizer
def get_custom_stopwords(stop_words_file):
with open(stop_words_file) as f:
stopwords = f.read()
stopwords_list = stopwords.split('\n')
custom_stopwords_list = [i for i in stopwords_list]
return custom_stopwords_list
stop_words_file = r'C:\Users\xuxiaojielucky_i\Desktop\停用词表.txt'
stopwords = get_custom_stopwords(stop_words_file)
stopwords
Vectorizer = CountVectorizer(max_df = 0.8,
min_df = 3,
token_pattern = u'(?u)\\b[^\\d\\W]\\w+\\b',
stop_words =frozenset(stopwords) )
u或者U:表示unicode字符串 ,通常英文字符在使用各类编码下, 基本均可以正常解析, 因此通常不带u;可是中文, 必须代表所需编码, 不然一旦编码转换就会出现乱码。
'(?u)\\b[^\\d\\W]\\w+\\b'
其实就是
'(?u)\b[^\d\W]\w+\b' #\是显示出来的字符串是用r的模式解读出来,自动带了转义
“(?u)“放在前面的意思是匹配中对大小写不敏感
”\b"和末尾的”\b"表示定位符规定匹配模式必须出如今目标字符串的开头或结尾的两个边界之一
CountVectorizer是经过fit_transform函数将文本中的词语转换为词频矩阵,矩阵元素a[i][j] 表示j词在第i个文本下的词频。即各个词语出现的次数,经过get_feature_names()可看到全部文本的关键字,经过toarray()可看到词频矩阵的结果。
test = pd.DataFrame(Vectorizer.fit_transform(X_train).toarray(),
columns=Vectorizer.get_feature_names())
test.head()

训练模型
from sklearn.naive_bayes import MultinomialNB
nb = MultinomialNB()
X_train_vect = Vectorizer.fit_transform(X_train)
nb.fit(X_train_vect, y_train)
train_score = nb.score(X_train_vect, y_train)
print(train_score)

训练过的模型明显好多了
测试数据
X_test_vect = Vectorizer.transform(X_test)
print(nb.score(X_test_vect, y_test))

X_vec = Vectorizer.transform(X)
nb_result = nb.predict(X_vec)
data['nb_result'] = nb_result