python爬虫05 - BeautifulSoup4的安装,下载,源码简介,使用。
1. bs4简介
1.1 基本概念
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的网页信息提取库
1.2 源码分析
• github下载源码
• 安装
• pip install lxml
• pip install bs4
pip install bs4 -i https://pypi.douban.com/simple
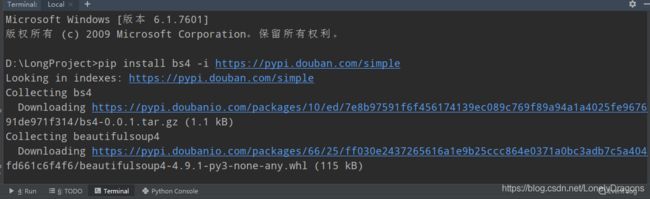
在github 下载BeautifulSoup源码
下载第一个
BeautifulSoup源码简介
主要的源码在bs4 中间两个文档文件夹 最后一个脚本文件夹先不用看

一张爱丽丝梦游仙境的插图
_init_ 就是初始化的意思
class BeautifulSoup(Tag): 经常出现
Tag就是标签 就是让你传递一个lxml html文档
咱们再看一些有什么方法
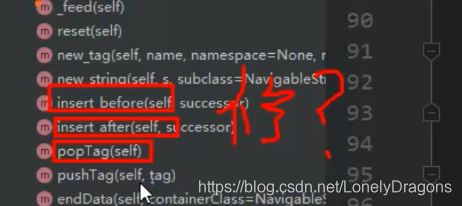
insert before 在前面插入
insert after 在之后插入
而前面用到过pop 删除的意思 那么这三个方法就是修改方法
find() find_all()
这就是一些查找的方法
![]()
遍历的方法
还有很多很多方法值得去注意学习的
找next_sibling 下一个兄弟的意思吧 就像是导航的意思
我们用爬虫写一些代码 从网上获取一些免费的资源比如文字 图片 平常中我们可以通过复制粘贴这个动作来创建一个新的文本 但是网页中这个文字粘贴到文本里 是一个比较慢的动作 而爬虫的核心思想就是写一些程序 这些程序能把文字爬取并且能把文字保存在文档里 这些代码或者是想法就衍生出来了各种各样的工具 模块
bs4就是其中的一种模块 那么它是如何抓取数据的 查找 导航…
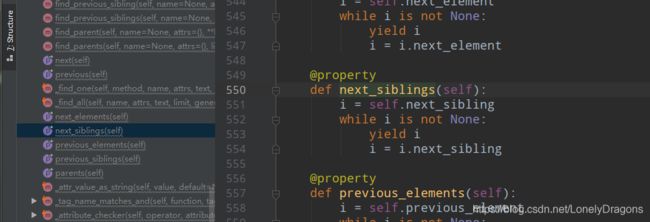
比如在next_sibling()这个方法中
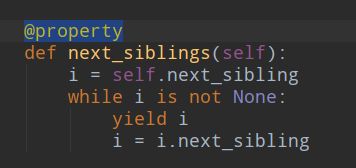
就比如说平常 是
对象.next_sibling() 加了装饰器@property后对象.next_sibling 就可以将next_sibling当作属性来调用
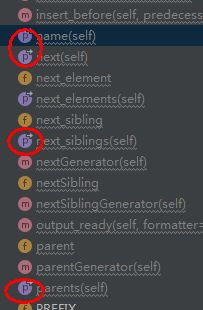
只要是通过装饰器装饰的 他的小图标就是蓝紫色p标记的
有兴趣 就要再多看看 可以把里面内容翻译一下
2. bs4的使用
比如你到了公司 刚拿到一个最新的技术点 你又没有太多合适的博客 资料你该如何学习
可以看这个文档 点击你有的浏览器打开

2.1 快速开始

咱们也用这个例子 玩玩
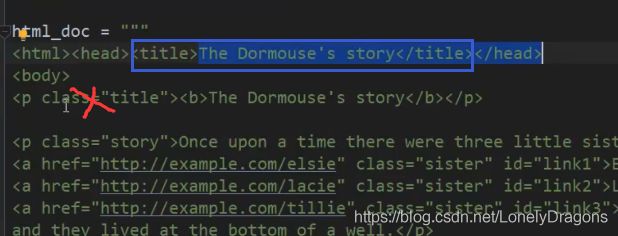
大家可以看出这个html文档结构有些不美观
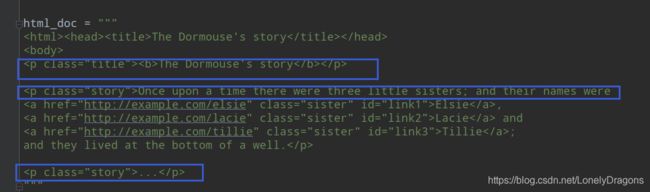
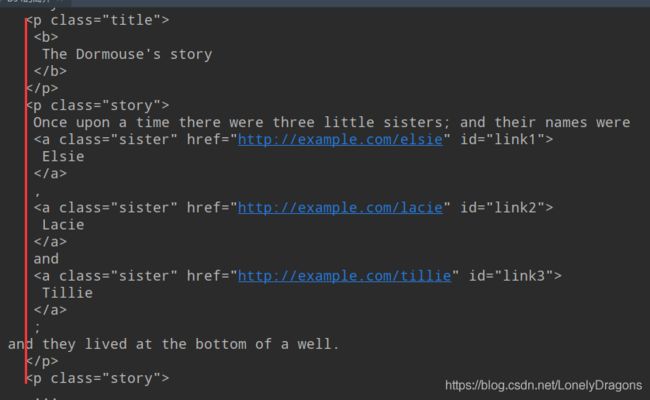
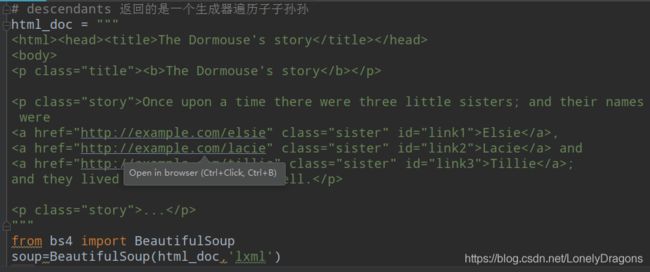
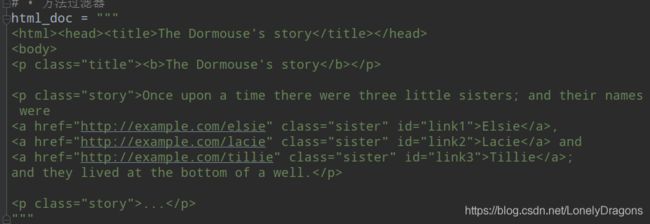
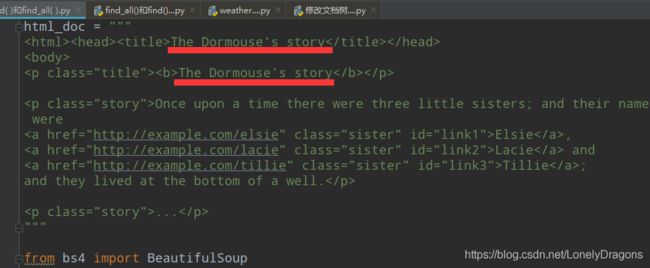
html_doc = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
我们可以看到body标签中有很多段落 p a 段落中属性 比如class=“story”
href属性对应的是一个链接 还有id 还有比如Elsie Lacie这样的文字
打印一下 这个结构不是很美观呀
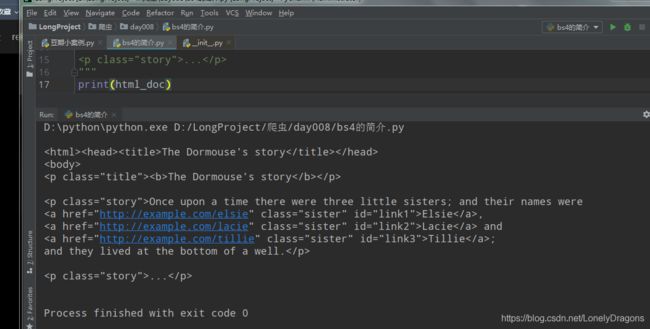

BeautifulSoup是一个类
可以创建一个实例化对象
BeautifulSoup()的传一个Tag 我们就传入html_doc
run后 给了一个警告
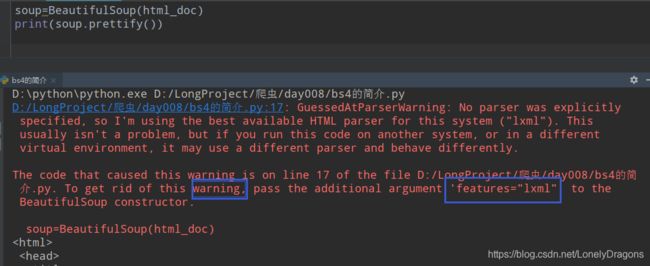
‘features=“lxml”’ 就是说的你的解释器少了lxml
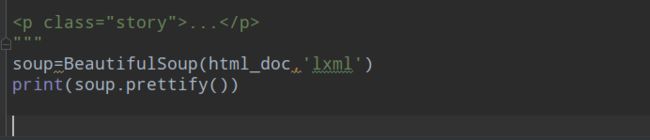
加上’lxml’
这样就行了 结构就变得清晰了
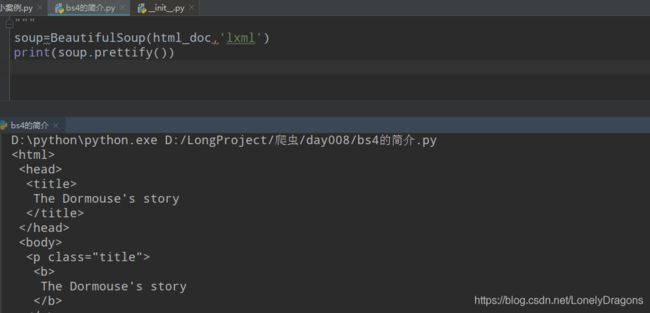
将html变成一个实例化对象,这个对象的方法
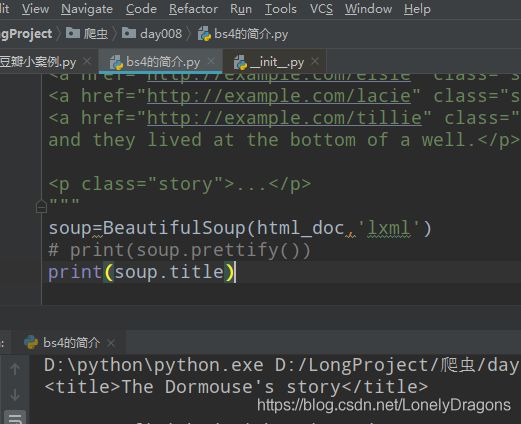
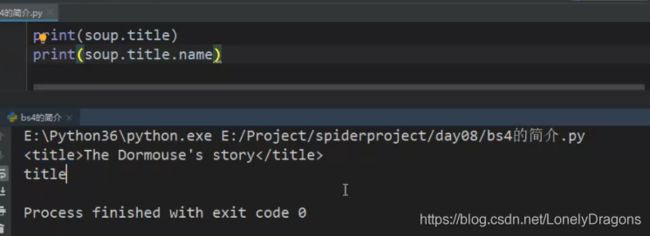
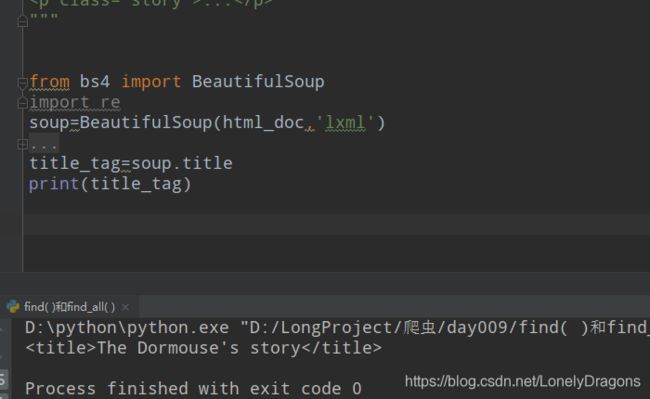
比如我们找The Dormouse’s story 而不是p标签里的title
print(soup.title)
我们以前用xpath 得把这个数据变成一个element对象然后再写xpath的语法
写哪个标签下的标签
而这种方法直接对象.属性的方法直接找到了
而且如果你用正则表达式 把那一段截取下来
![]()
中间一删除换成 (.*?)
![]()
这还是比较简单的正则
![]()
所以上面的那个新方法 是非常简单粗暴的 直接就拿到了这个数据了
获取标签的名字
那比如我想要中间的那个数据

那必如要找这个p导航的话
而且通过标签导航找的是第一个
那么你可能就想找到所有的p标签 我们先看看有多少个p标签
而且要注意上回的p是一个属性 而这个会得传一个字符串的 ‘p’ 要不然就报错了
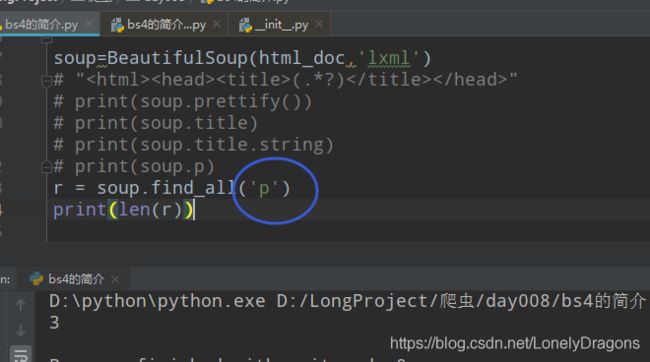
确实有3个p标签
在看看print®的结果是什么

而且还用逗号分隔了 第二个p标签下有3个a标签
Once upon a time there were three little sisters; and their names were
从前有三个小姐妹,她们的名字是 3个a标签中的文字
and they lived at the bottom of a well
他们住在井底

第二个p标签下有3个a标签
而且这些数据都是在一个列表中 那么你想拿这些元素就可以遍历这个列表
那还比如你想要href中的链接
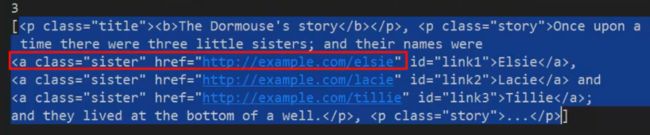
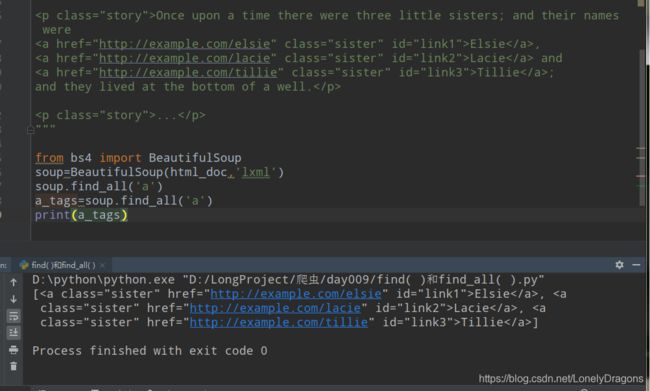
links = soup.find_all('a')
for link in links:
print(link.get('href'))
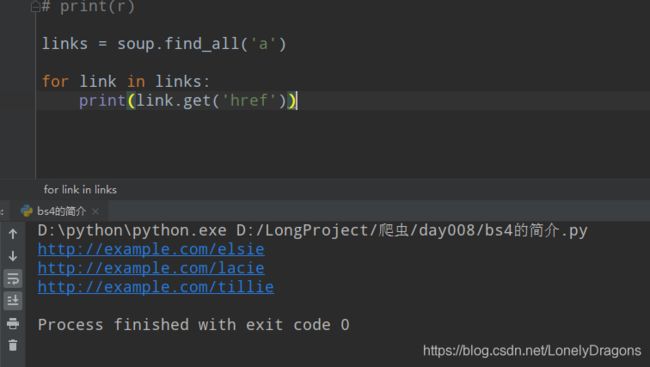
from bs4 import BeautifulSoup
html_doc = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup=BeautifulSoup(html_doc,'lxml')
# "(.*?) "
# print(soup.prettify())
# print(soup.title)
# print(soup.title.string)
# print(soup.p)
# r = soup.find_all('p')
# print(len(r))
# print(r)
links = soup.find_all('a')
for link in links:
print(link.get('href'))
也就是你想从html_doc 中找数据 就先通过soup=BeautifulSoup(html_doc,‘lxml’)把html_doc变成一个对象 然后这个对象有很多找数据的方法 导航 搜索 修改…
小结
# 获取bs对象
bs = BeautifulSoup(html_doc,'lxml')
# 打印文档内容(把我们的标签更加规范的打印)
print(bs.prettify())
print(bs.title) # 获取title标签内容 The Dormouse's story
print(bs.title.name) # 获取title标签名称 title
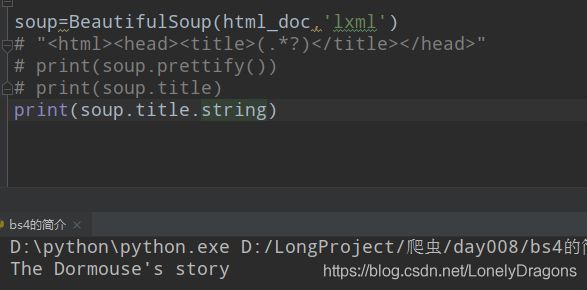
print(bs.title.string) # title标签里面的文本内容 The Dormouse's story
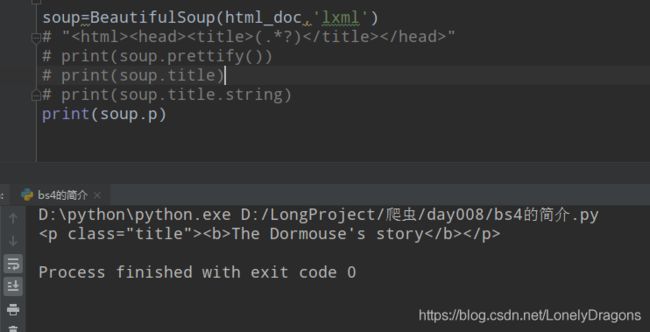
print(bs.p) # 获取p段落
2.2 bs4的对象种类
• tag : 标签
• NavigableString : 可导航的字符串
• BeautifulSoup : bs对象
• Comment : 注释
那么刚才上面的soup是bs4的哪种对象?
当然是第三种 BeautifulSoup : bs对象
soup=BeautifulSoup(html_doc,'lxml')
打印一下其类型
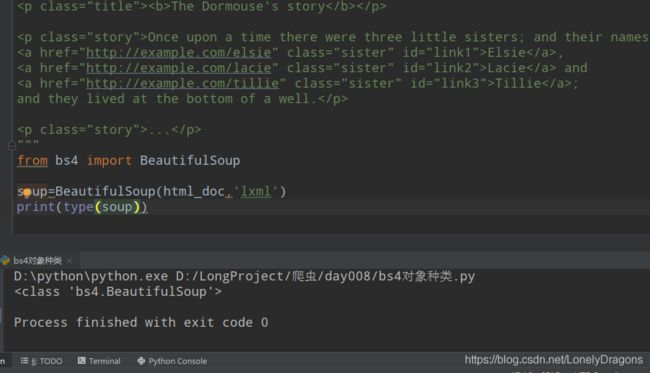
再看看上面那个title标签是bs4的哪种对象
tag : 标签
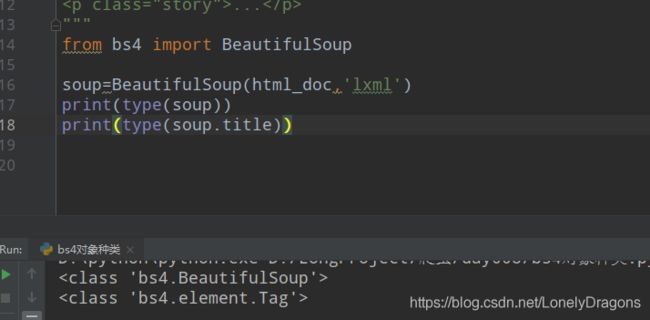
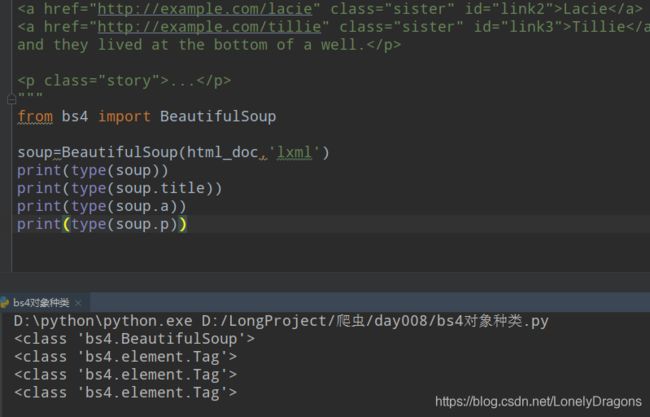
tag是一个标签(tag)类型的对象 那么按照这个结论 a p head 都是标签(tag)类型的对象
验证一下
html_doc = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
from bs4 import BeautifulSoup
soup=BeautifulSoup(html_doc,'lxml')
print(type(soup)) # 那么NavigableString : 可导航的字符串 这个是什么意思
比如我想看p标签的里面一些文字内容怎么搞
bs.p.string
而且是默认找第一个属性
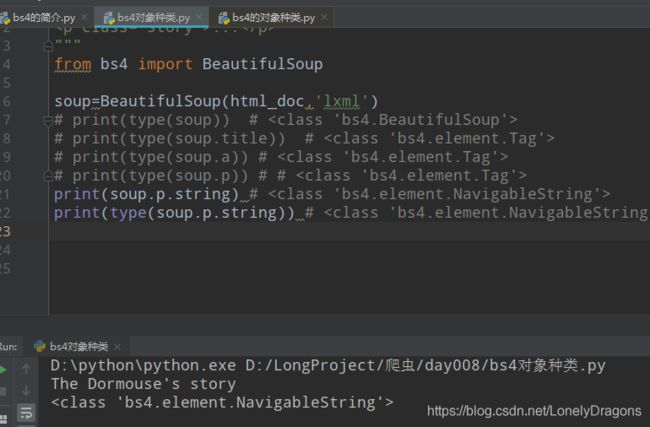
那么这个soup.p.string对象的类就是NavigableString (可导航的字符串)
也就是我们通过soup.p.string导航到了文本的内容
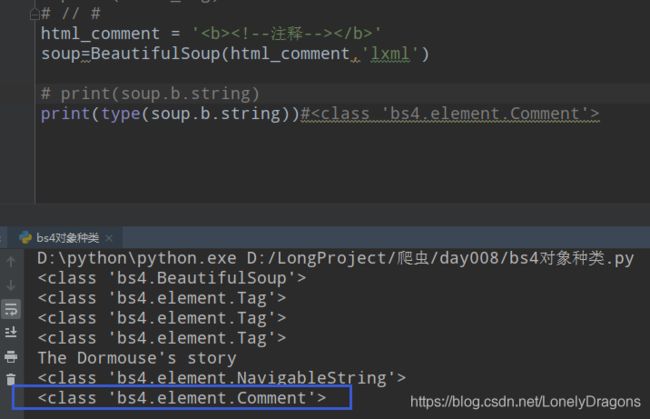
那么最后一个Comment : 注释类对象呢?
很显然赋了值的title_tag就是第一个p标签了
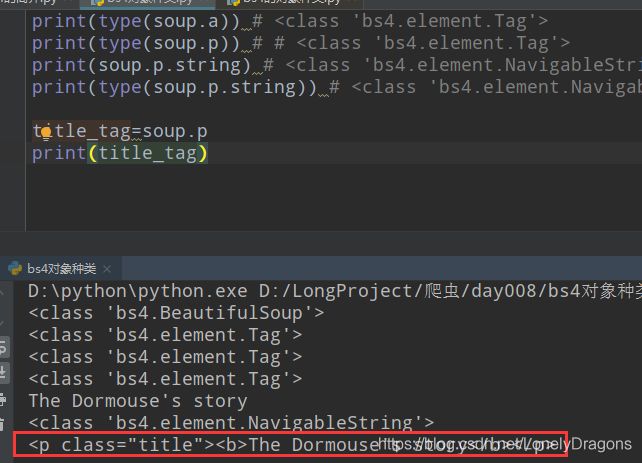
也就是能看到p标签的 class属性 还有其中的文字内容
java里的注释: // python里的注释: #
前端的注释 没法打出来
![]()
得模拟一个注释才能看出来效果
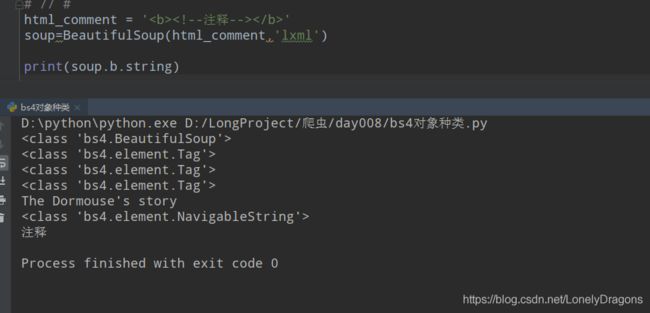
print(soup.p.string) #The Dormouse's story
![]()
而
html_comment = ''
soup=BeautifulSoup(html_comment,'lxml')
print(soup.b.string)
时 结果只会是 注释 (就是这个位置的内容)
再看看它的类型
html_doc = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
from bs4 import BeautifulSoup
soup=BeautifulSoup(html_doc,'lxml')
print(type(soup)) # 小结
print(bs.title)
获取title标签内容
![]()
print(bs.title.name) # 获取title标签名称 title
print(bs.title.string) # title标签里面的文本内容 The Dormouse’s story
print(bs.title[‘class’]) #获取title标签里的属性 [‘title’]

我想要这个属性值怎么找
title_tag = soup.p
print(title_tag['class'])
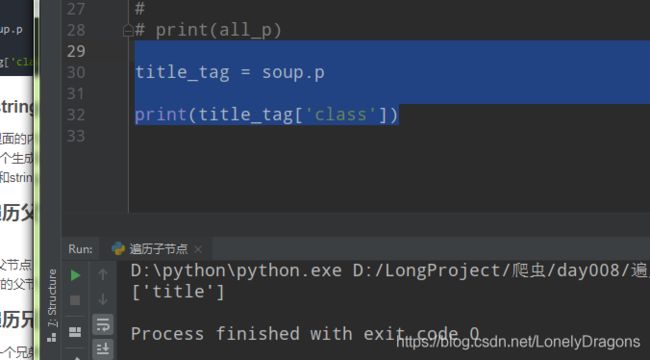
返回的是一个列表 想要里面的元素 价格[0]就ok
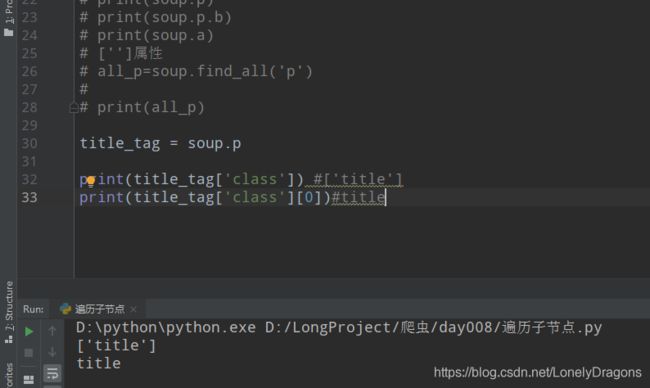
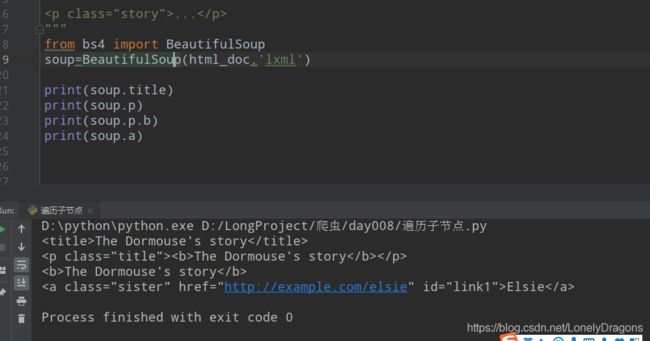
文字内容在b标签中
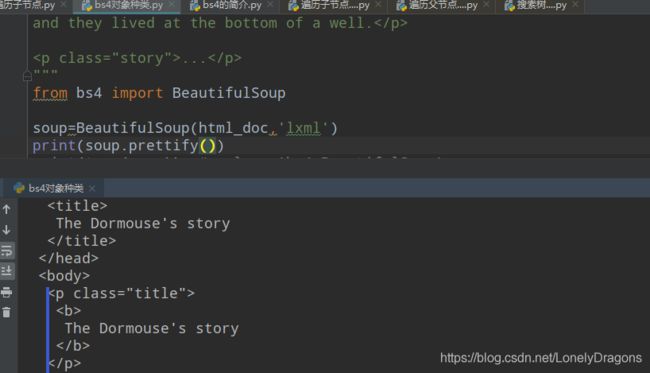
当然我们知道 soup.p这样找p标签只能找第一个
当然还可以用find_all (上面已经演示过的)
from bs4 import BeautifulSoup
soup=BeautifulSoup(html_doc,'lxml')
# print(soup.title)
# print(soup.p)
# print(soup.p.b)
# print(soup.a)
all_p=soup.find_all('p')#返回的是一个列表
print(all_p)
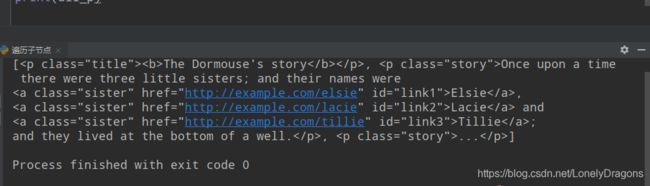
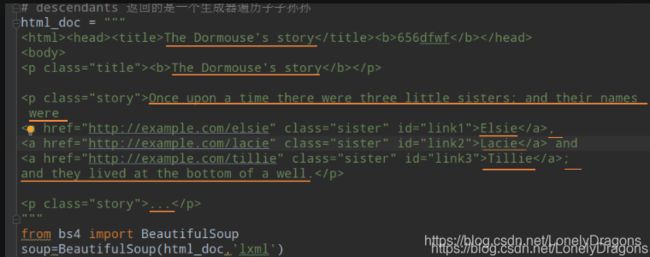
3. 遍历树 遍历子节点
bs里面有三种情况,第一个是遍历,第二个是查找,第三个是修改
3.1 contents children descendants
• contents 返回的是一个列表
• children 返回的是一个迭代器通过这个迭代器可以进行迭代
• descendants 返回的是一个生成器遍历子子孙孙
迭代 iterate 指的是按照某种顺序逐个访问列表(比如列表 但是还有其他例子)中的某一项 例如 Python中的for语句
循环 loop 指满足某些条件下,重复执行某一段代码 例如 Python中的while语句
contents
html_doc还是那个爱丽丝梦游仙境的
contents 返回的是一个列表
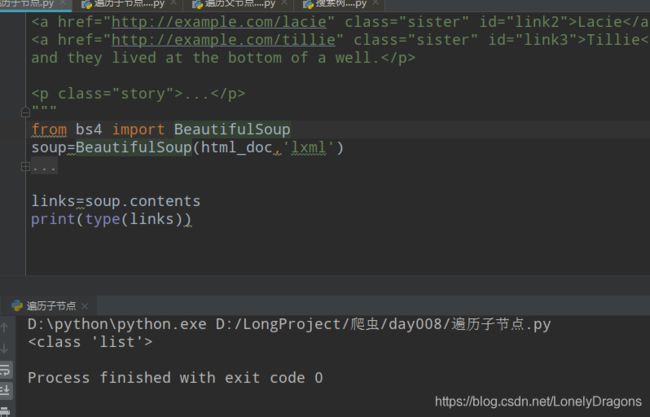
那这个links的值是什么
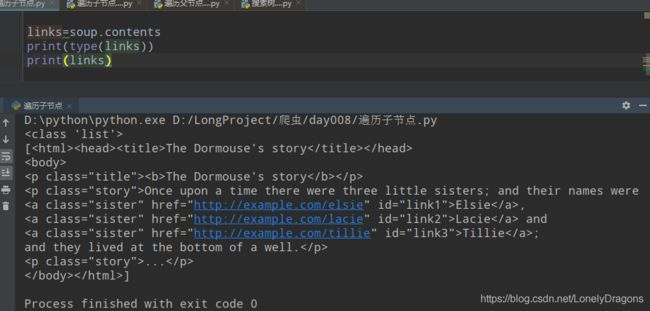
你会发现contents把html文档(html_doc)的所有内容全部拿到了 而且是把全部内容放在了列表中
children
children 返回的是一个迭代器通过这个迭代器可以进行迭代
html = '''
'''
soup2=BeautifulSoup(html,'lxml')
links2=soup2.contents
for li in links2:
r=li.find_all('a')# 也正好find_all方法返回的是一个列表
print(r)
for l in r:
print(l.string)
[<a href="#">李若彤</a>, <a href="#">热巴</a>, <a href="#">老师</a>]
李若彤
热巴
老师
可以看出links是一个可迭代的
那么我们就可以通过for遍历一下看看结果如何
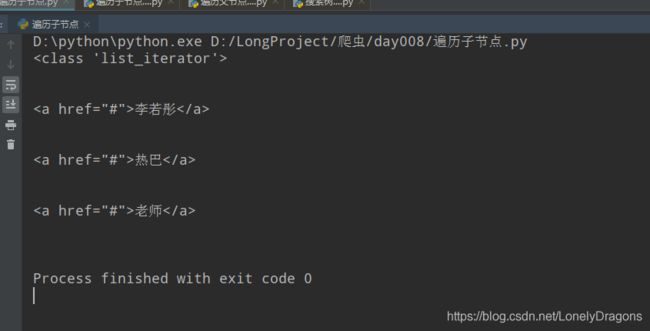
html = '''
<div>
<a href='#'>李若彤</a>
<a href='#'>热巴</a>
<a href='#'>老师</a>
</div>
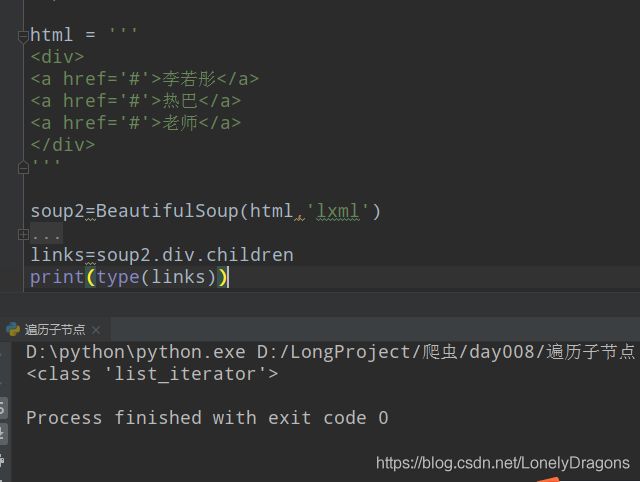
links=soup2.div.children
print(type(links))
for link in links:
print(link)
descendants
descendants 返回的是一个生成器遍历子子孙孙
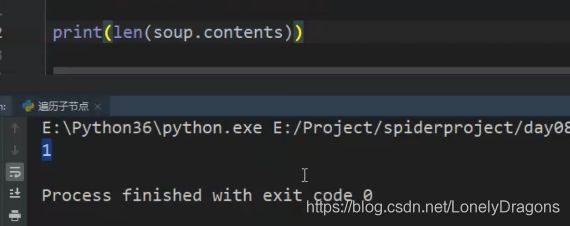
soup.contents的类型是列表 所以长度是1
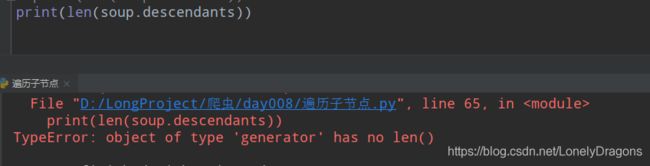
TypeError: object of type ‘generator’ has no len()
也就是这个generator类型的对象是没有长度的 子子孙孙就没长度了
generator就是生成器的意思
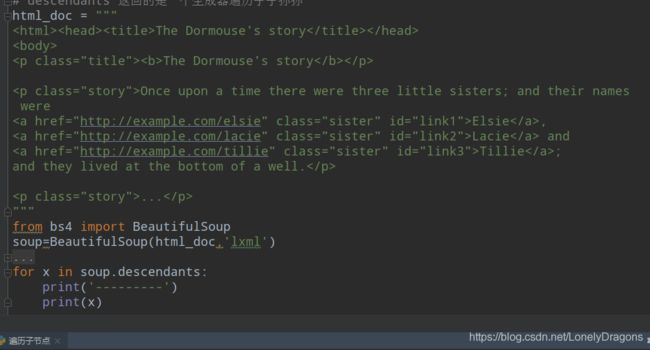
D:\python\python.exe D:/LongProject/爬虫/day008/遍历子节点.py
---------
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body></html>
---------
<head><title>The Dormouse's story</title></head>
---------
<title>The Dormouse's story</title>
---------
The Dormouse's story
---------
---------
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body>
---------
---------
<p class="title"><b>The Dormouse's story</b></p>
---------
<b>The Dormouse's story</b>
---------
The Dormouse's story
---------
---------
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
---------
Once upon a time there were three little sisters; and their names were
---------
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
---------
Elsie
---------
,
---------
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>
---------
Lacie
---------
and
---------
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
---------
Tillie
---------
;
and they lived at the bottom of a well.
---------
---------
<p class="story">...</p>
---------
...
---------
Process finished with exit code 0
用分割线 分割后 更容易看出结果的结构
第一个是整个的doc_html文档
它可以循环拿到所有的内容某一个标签下的子元素 包括子元素的子元素(跟剥洋葱一样剥一层少一层)
3.2 .string .strings .stripped strings
• string获取标签里面的内容
• strings 返回是一个生成器对象用过来获取多个标签内容
• stripped strings 和strings基本一致 但是它可以把多余的空格去掉
.string
string获取标签里面的内容 (就是文字内容)


title节点前面还有一个父节点 head 那我去head标签中找是否也可以找到内容
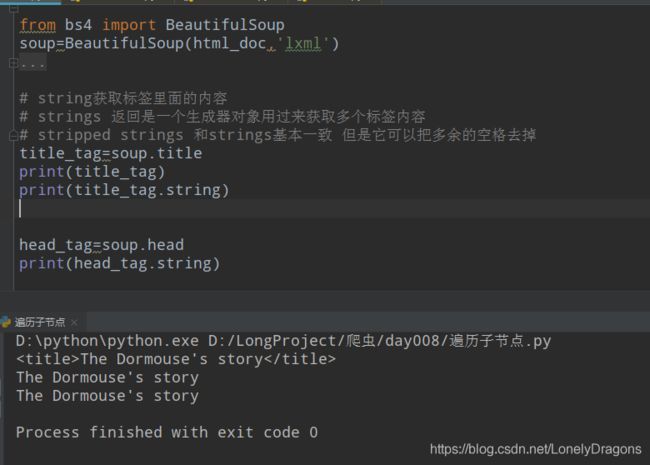
是可以的
但是title 节点都是只有一个内容
head节点只有一个子节点 而且子节点中只有一个内容
如果多个呢?
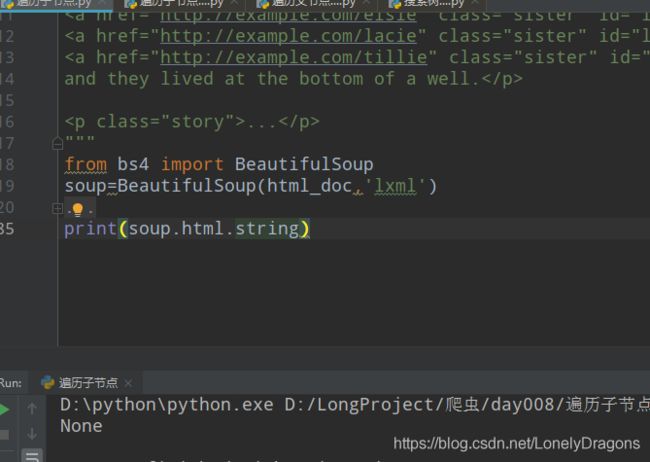
None 就是没有获取到.
所以string的使用场景就是 第一 这个节点只有一个子元素,第二这个节点只有一个内容
我们再对html_doc做些改动 验证一下
在head节点中的title节点后增加一个有内容的b节点

结果当然还是这种从先的原则
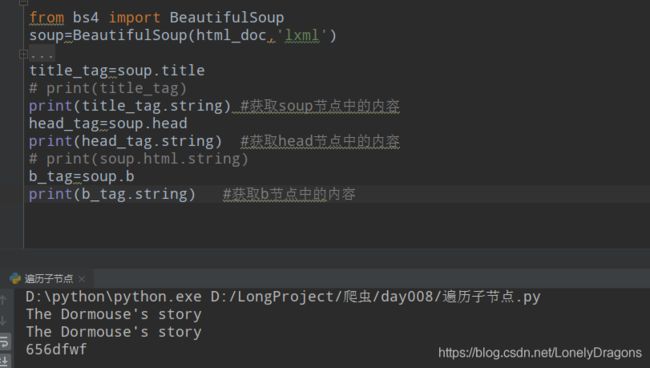
也就是只用string
如果节点中有多个子节点 子节点中有内容
那么多个内容就无法全部获取
.strings
strings 返回是一个生成器对象用过来获取多个标签内容
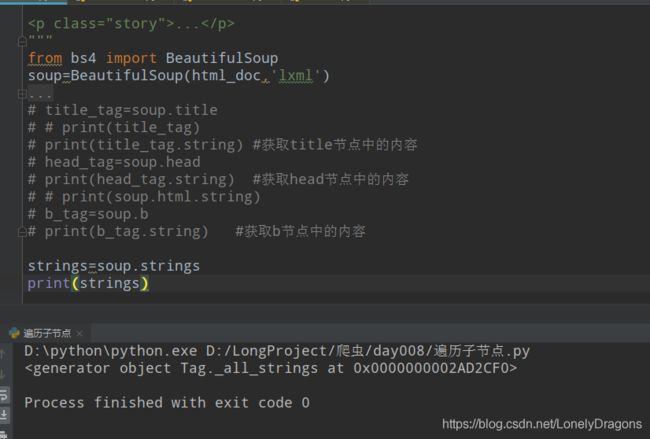
strings赋值后(soup.strings)就成了生成器(generator)对象
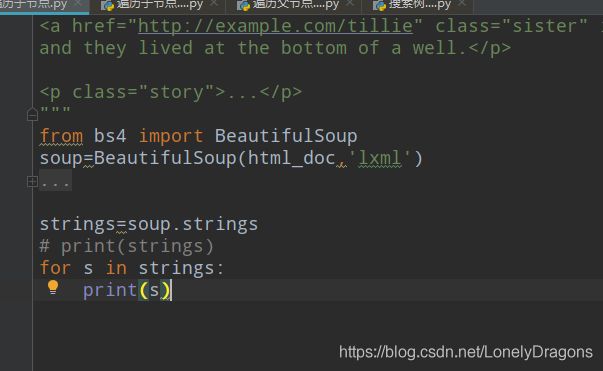
D:\python\python.exe D:/LongProject/爬虫/day008/遍历子节点.py
The Dormouse's story
656dfwf
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie
,
Lacie
and
Tillie
;
and they lived at the bottom of a well.
...
Process finished with exit code 0
soup.strings是把全部内容都拿到了
但是可能内容不是特别美观
.stripped_strings
stripped strings 和strings基本一致 但是它可以把多余的空格去掉
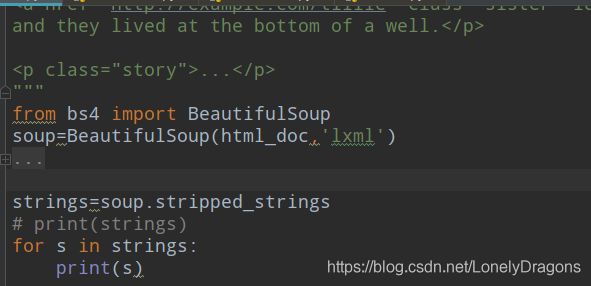
也就是去了个空格吧
D:\python\python.exe D:/LongProject/爬虫/day008/遍历子节点.py
The Dormouse's story
656dfwf
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie
,
Lacie
and
Tillie
;
and they lived at the bottom of a well.
...
Process finished with exit code 0
4. 遍历树 遍历父节点
parent 和 parents
• parent直接获得父节点
• parents获取所有的父节点
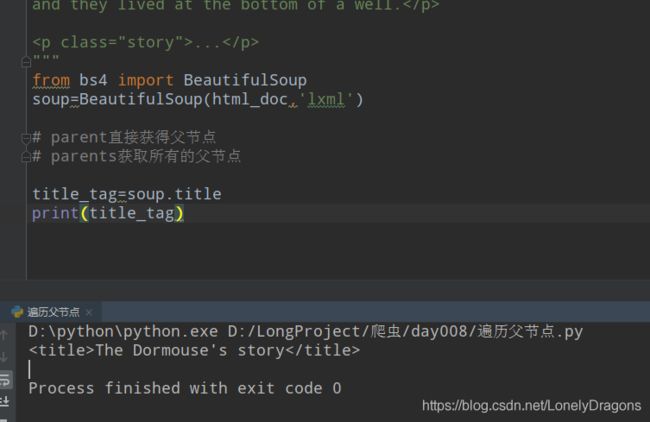
这个title的父节点是谁 直接父节点就是head呀
也就是我们要找title节点这级数据的上一级数据 就是head节点吧
title_tag=soup.title
print(title_tag)
print(title_tag.parent)
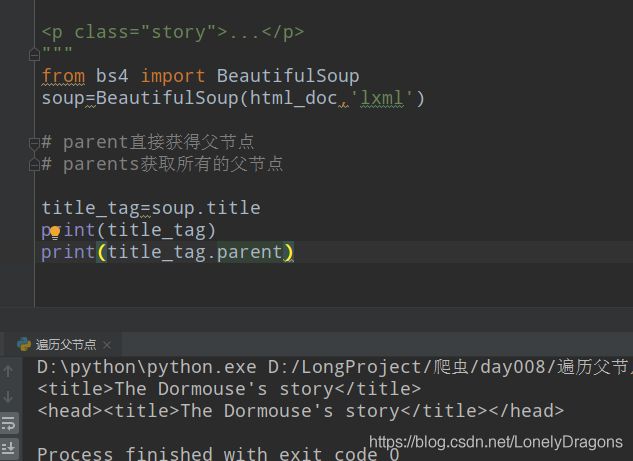
那看看html节点有没有父节点
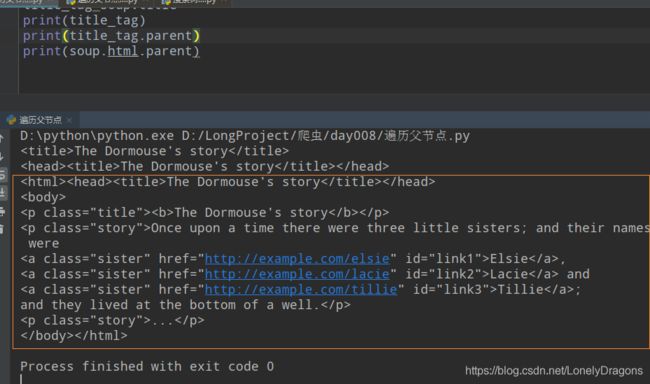
html的父节点就是它本身 也就是整个文档
• parents获取所有的父节点
先拿a标签练练手
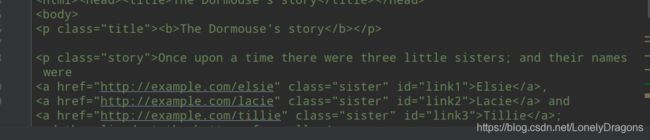
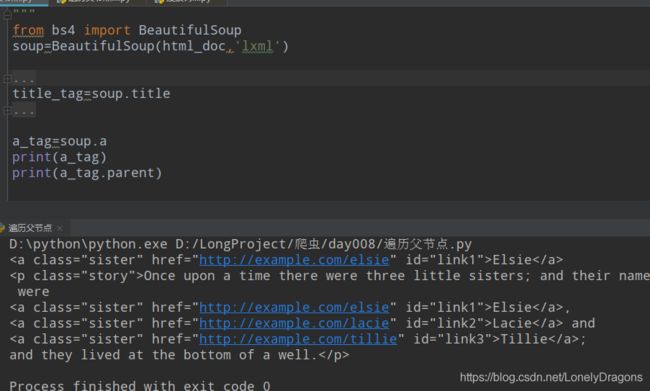
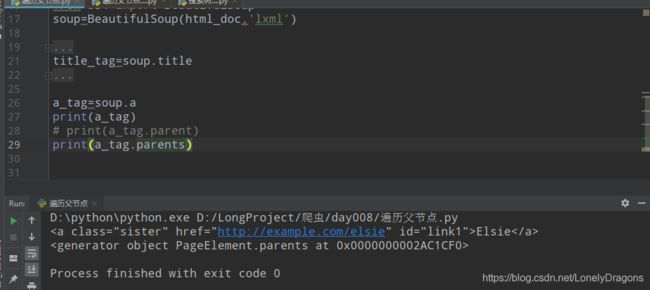
你可以看出.parents与.parent 返回的结果是不同的额 前者是生成器对象 后者是父节点
这点可以类比.string与.strings
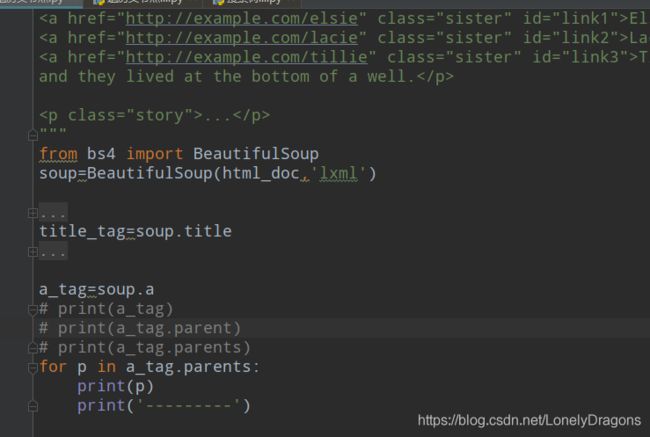
a节点的父节点就有点多了
首先是p节点
然后是body节点 再然后是html节点 后面的重复的后面还会讲到 先不用管它
D:\python\python.exe D:/LongProject/爬虫/day008/遍历父节点.py
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
---------
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body>
---------
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body></html>
---------
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body></html>
---------
Process finished with exit code 0
5. 遍历树 遍历兄弟结点
• next_sibling 下一个兄弟结点
• previous_sibling 上一个兄弟结点
• next_siblings 下一个所有兄弟结点
• previous_siblings上一个所有兄弟结点
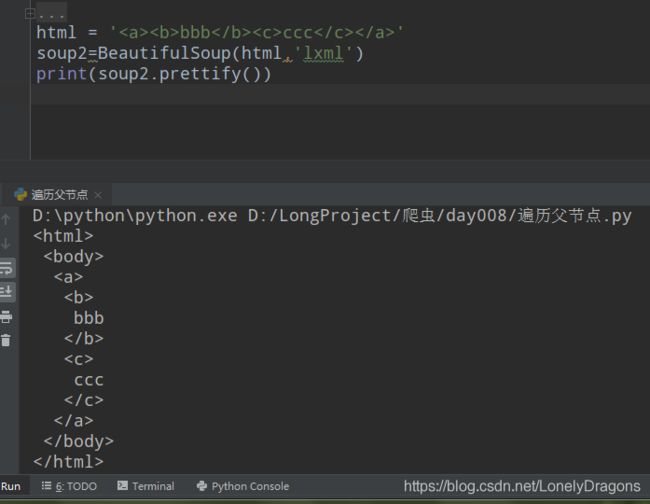
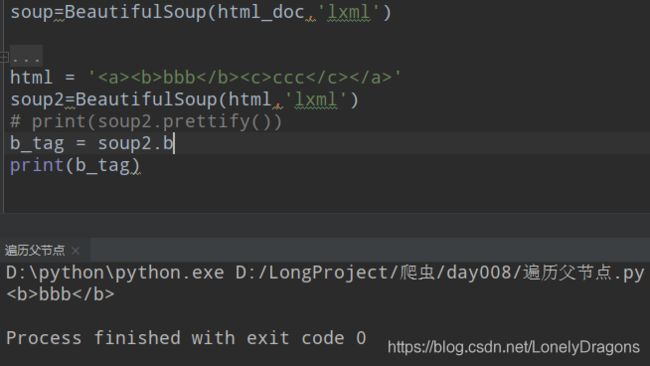
比如拿b标签(节点)
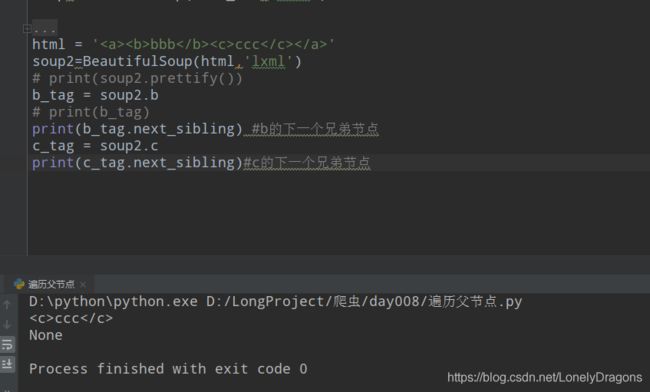
c没有下一个兄弟节点的呀
previous_sibling
那试试c的上一个兄弟结点 那不就是b节点了吗
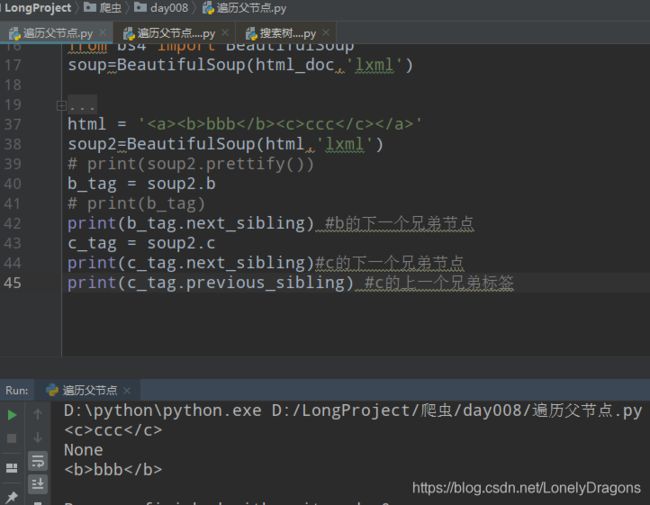
next_siblings 下一个所有兄弟结点
previous_siblings上一个所有兄弟结点
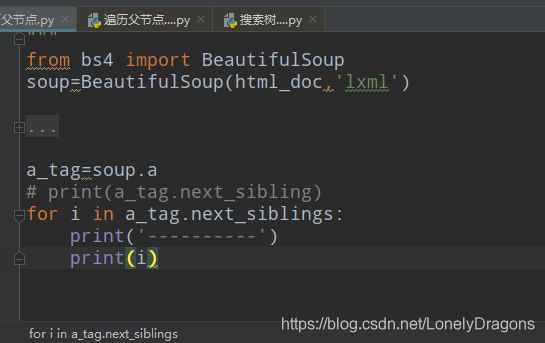
那么得拿爱丽丝梦游仙境的文档来练

a标签的下一个标签是,
那么a标签下一个所有的兄弟节点就是
D:\python\python.exe D:/LongProject/爬虫/day008/遍历父节点.py
----------
,
----------
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>
----------
and
----------
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
----------
;
and they lived at the bottom of a well.
Process finished with exit code 0
那么还有一种
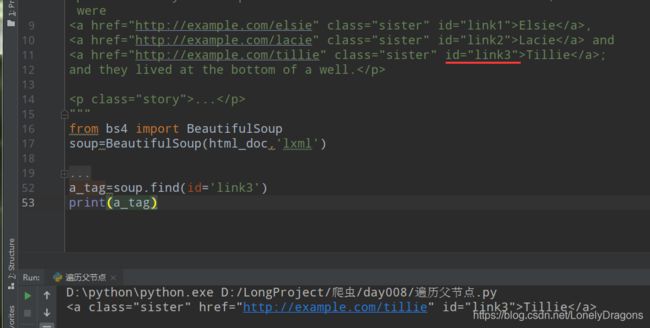
此时的a_tag就是最后的一个a标签 那么
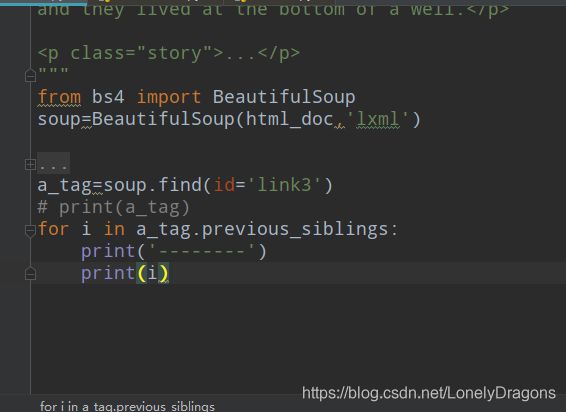
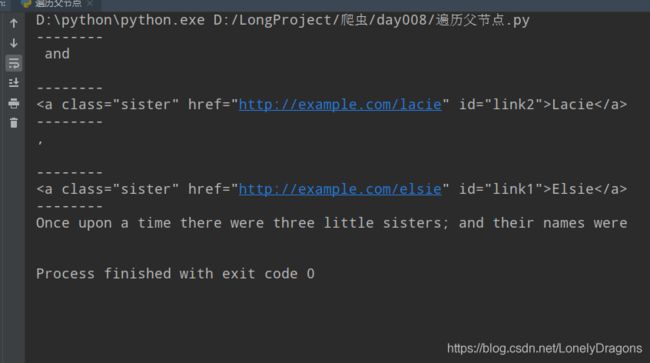
previous_siblings
a节点上一个所有兄弟结点就是
6. 搜索树
• 字符串过滤器
• 正则表达式过滤器
我们用正则表达式里面compile方法编译一个正则表达式传给 find 或者 findall这个方法可以实现一个正则表达式的一个过滤器的搜索
• 列表过滤器
• True过滤器
• 方法过滤器
字符串过滤器
比如找a标签
a_tag = soup.find('a')
那么这种情况其实就是字符串过滤器
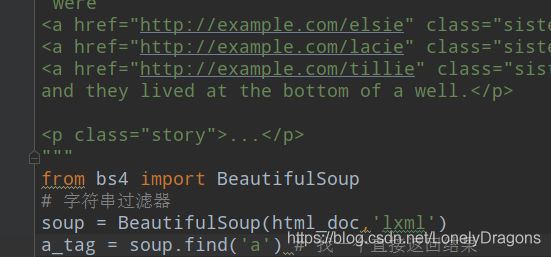
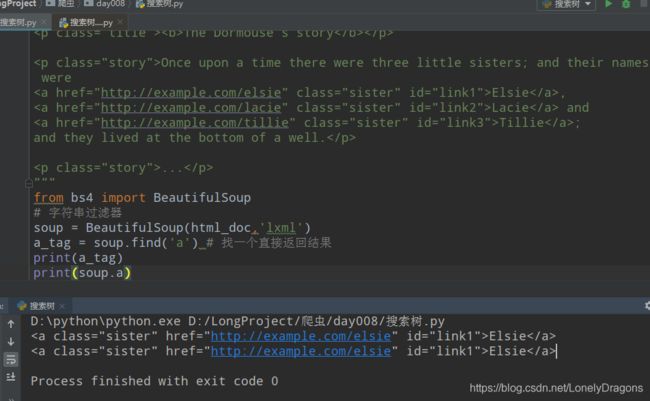
那找所有的a标签呢
而且返回值还是列表
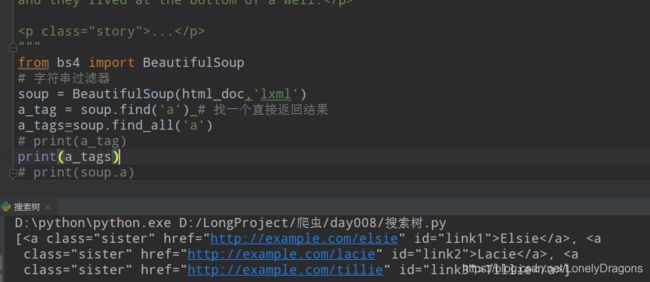
也就是过滤器中find_all 方法 会把soup中的所有标签划分元素 放入列表中 只传一个’a’ 就是soup.find_all(‘a’) 找元素(标签)中所有a开头的标签或者元素(’<'应该不算开头字符串)
a_tag = soup.find('a') find找一个直接返回结果
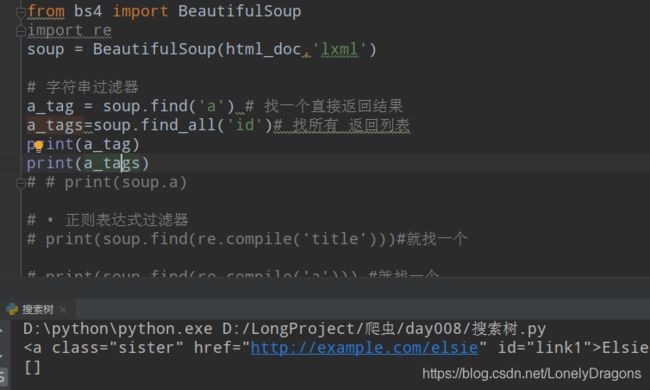
a_tags=soup.find_all('a') find_all找所有 返回列表
正则表达式过滤器
先导入模块re

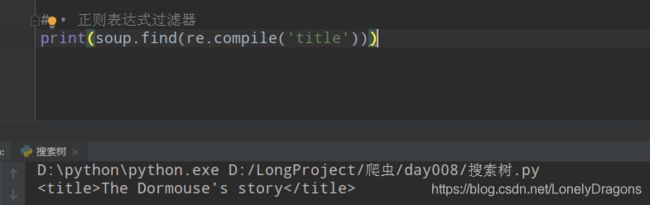
# • 正则表达式过滤器
print(soup.find(re.compile('title')))
当然上面的那个写法很简单 来个稍微难度的
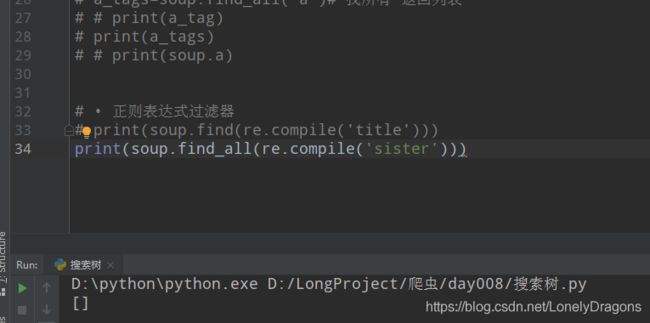
说明re.compile( )中传入的只能是先匹配开头的
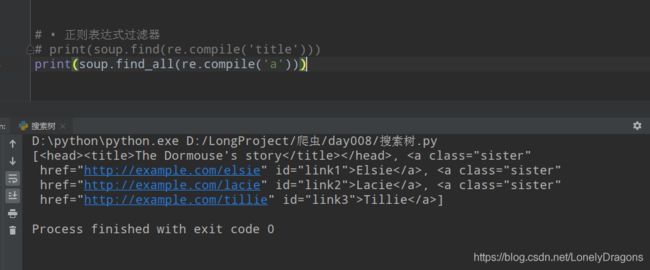
当然还有更多复杂的写法 就不一一阐述了
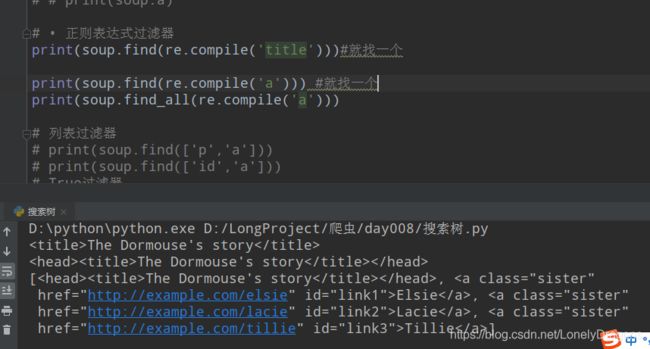
列表过滤器
其实就是能多找点什么开头 的 节点
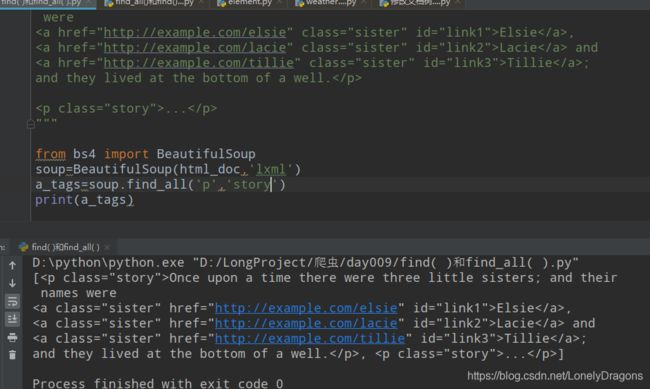
print(soup.find_all(['p','a']))
也就是找出p和a开头的所有标签
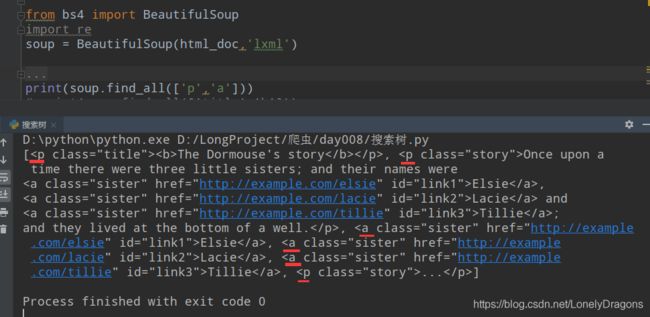
蓝色的为一整个p标签(里面还有很多a标签) 是这个列表的一个元素
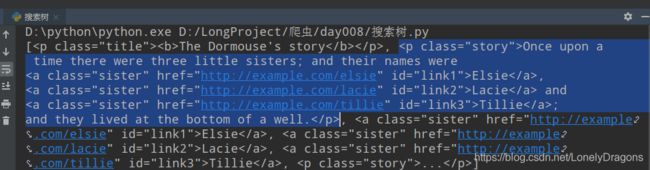
没有id开头的标签 所有找不到
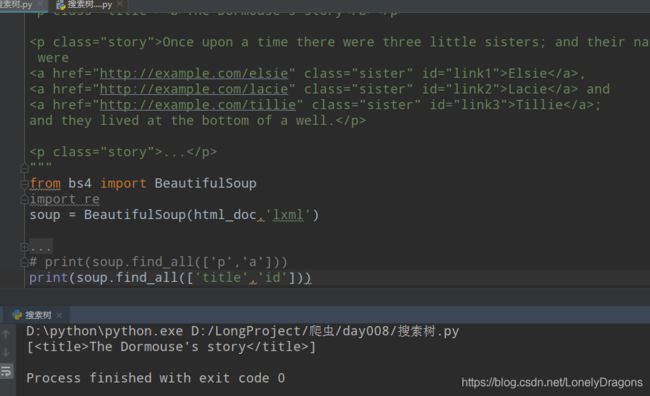
find就找一个 还从先 所以只能是两个标签 就不找a开头的
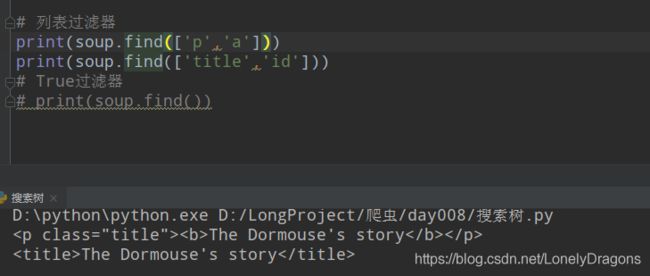
True过滤器
print(soup.find_all(True))
这个过滤器意义不是特别大…


什么是高阶函数呢
就是以函数对象作为参数接收的函数 或者是以函数对象作为返回值返回的函数就是高阶函数
(有点套娃的感觉)
方法过滤器
def fn(tag):
return tag.has_attr('id')
print(soup.find_all(fn))
tag是有这个has_attr( )方法的
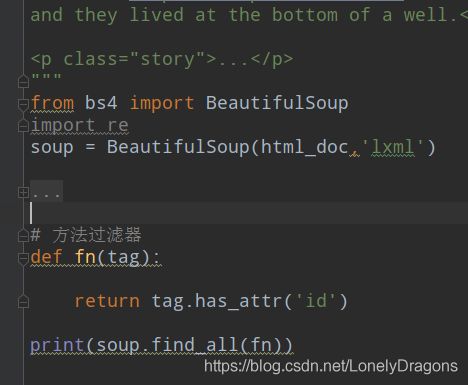
也就是这个有了这个tag.has_attr方法 就能找含有id属性的标签
soup.find_all(fn) 这个高阶的函数 可以理解成找所有含有id属性 的标签
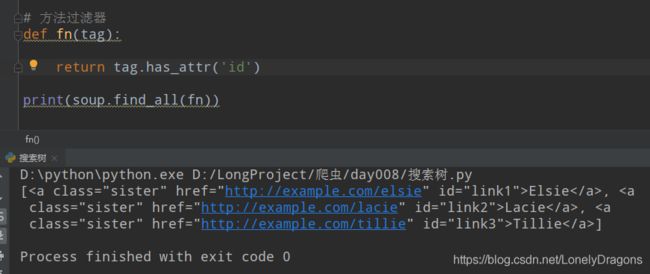
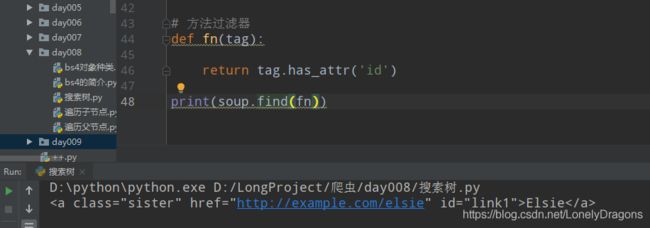
而是如果单独传入一个’id’ 那憨憨的find_all只会找所有id开头的标签 结果就是没有一个…
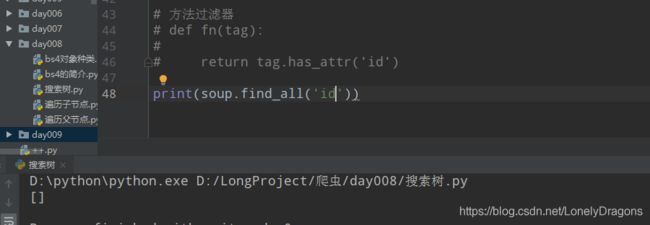
复习

7. find_all() 和 find()
7.1 find_all()
• find_all()方法以列表形式返回所有的搜索到的标签数据
• find()方法返回搜索到的第一条数据
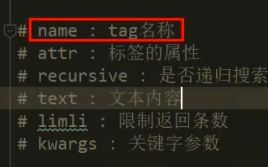
• find_all()方法参数

def find_all(self, name=None, attrs={}, recursive=True, text=None,
limit=None, **kwargs):
• name : tag名称
• attr : 标签的属性
• recursive : 是否递归搜索 默认是True
• text : 文本内容
• limit : 限制返回条数
• **kwargs : 关键字参数
不定长参数分为两种: *args 位置参数 **kwargs关键字参数
name : tag名称
还有高级点的
传入标签 加上传入属性值 就不会再先找第一个了

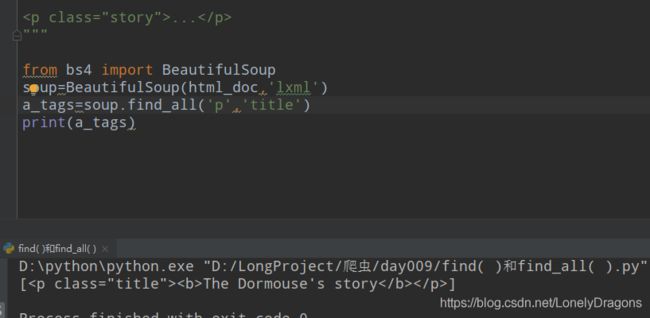
tag标签 也就是再次定位一下
传入标签的属性必须是标签对应的class值才行 也就是要找这样的tag名称
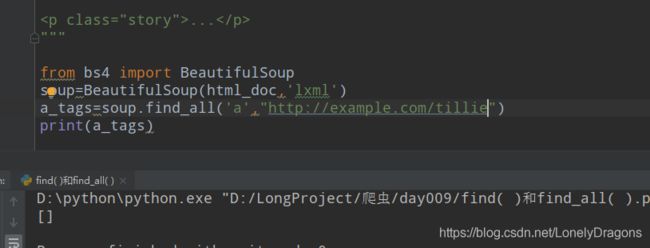
而且双引号 单引号没影响的
…
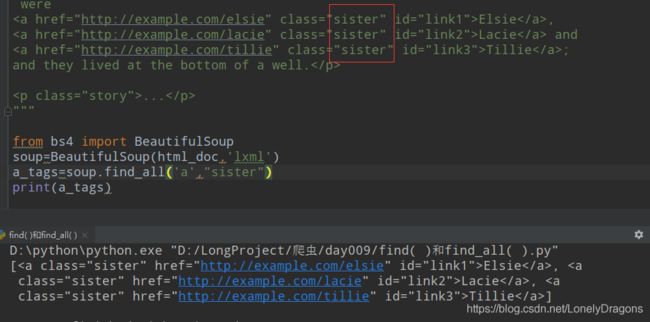
所以就是tag 传入一个后 在指定传入一个class的属性值 这个功能有点局限的.
再说一下kwargs : 关键字参数
找一个关键字参数 刚好这个就是
![]()
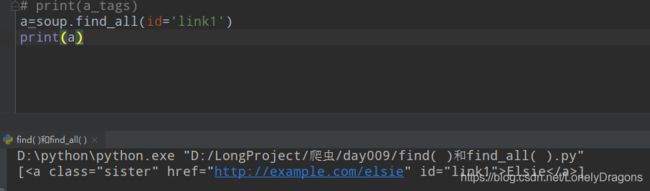
还有一种(脱了裤子放p的)写法 就是和上面效果一样的
导入re模块
import re
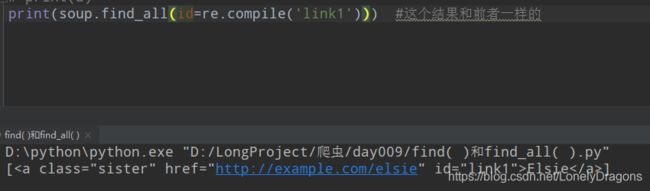
print(soup.find_all(id=re.compile('link1')))
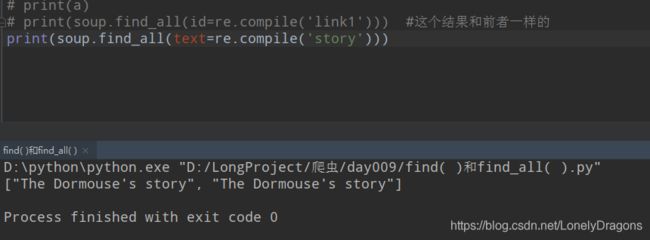
还有一个text的参数 也就是找文本的内容
text : 文本内容
我们可以结合re.compile()这样来写
limit : 限制返回条数
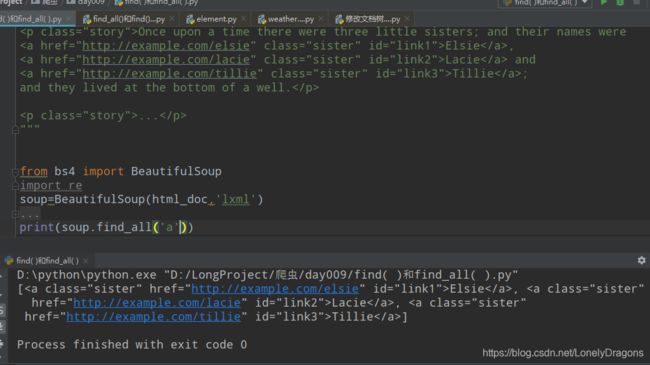
limit=1是什么东西呢
限制一条 以第一条数据进行返回 返回的是一个列表
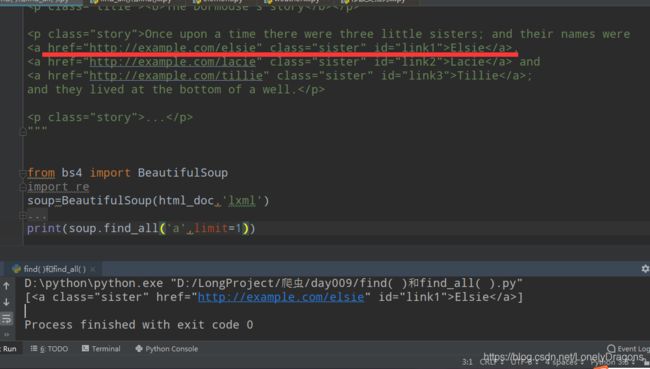
limit=2
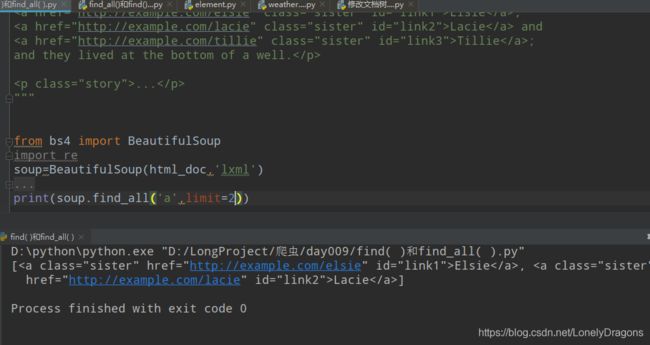
limit=3 嗯 3个和3个以上结果都一样的 因这个html_doc 中就只有3个a标签
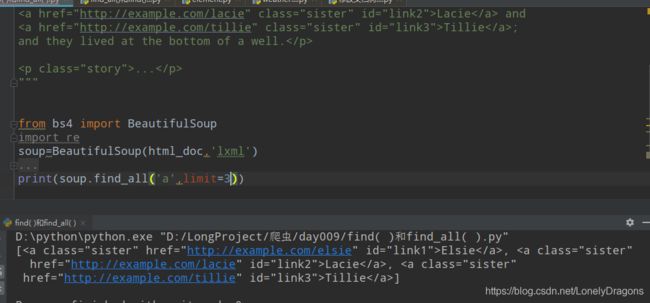
那么试试limit=-1 会不会是倒数第一个a标签
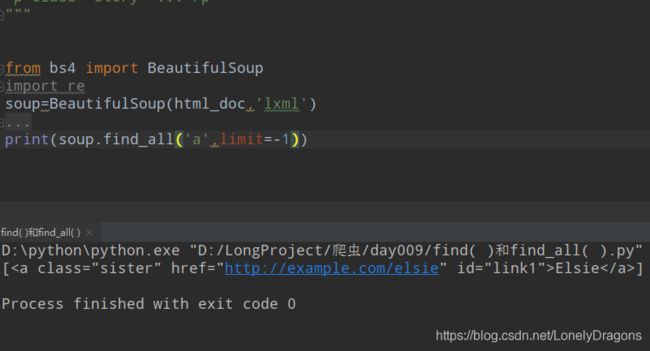
结果还是第一个 然后limit=-2 -3 -999 都是返回第一个
那limit=0呢 那不就是不限制条数 那返回的列表就是全部a标签的呀
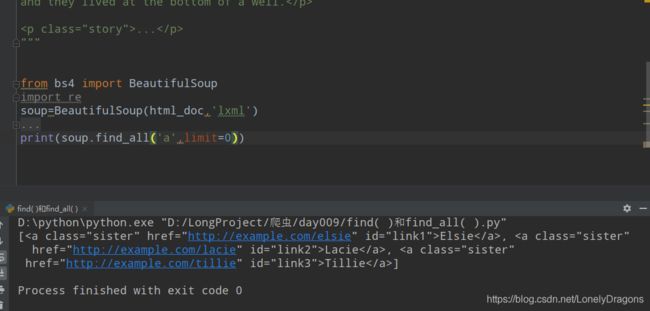
然后find_all 中还有一个参数
recursive : 是否递归搜索
这个recursive的默认值是 True

什么意思的呢 就是我先找就是先找儿子 再找孙子 这一种正常的找法
那如果改成False呢 它就会查找子节点 如果子节点找不到 比如还有孙子
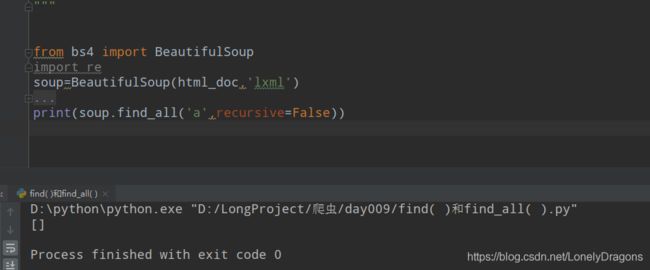
把recursive原来的默认值改成False 这样它就成找a节点下面的子节点了
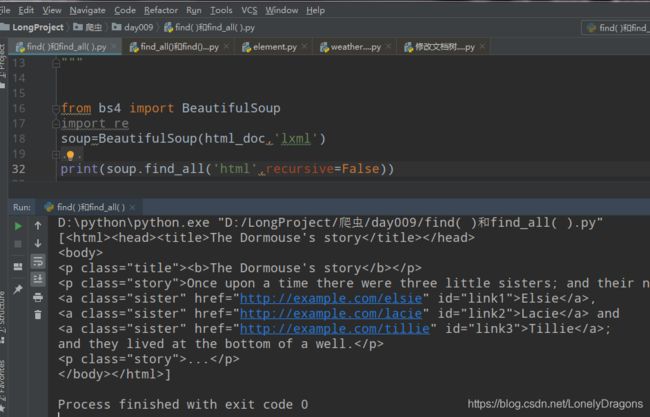
这个你知道有这个参数就可以了的
最多的就是用的是 name这个
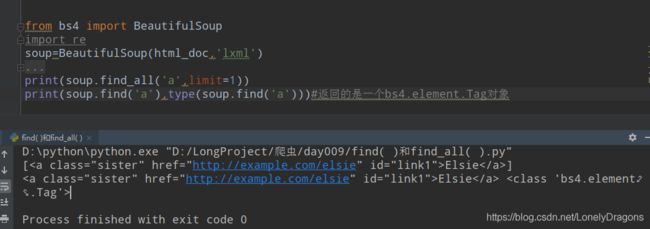
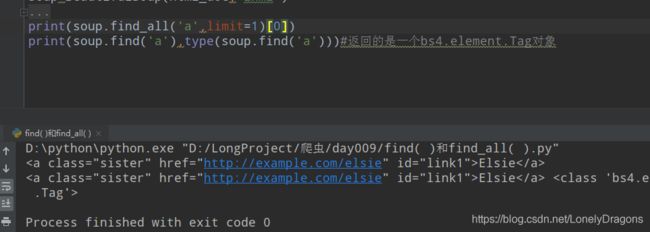
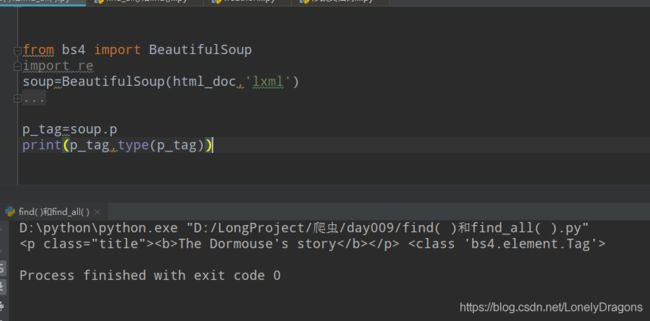
而且我还确实发现find_all 传入name 的话 找的方式是从开头筛选 而find(re.comple()) 从标签的整个内容进行匹配的 而且传入的标签 名字都得是字符串
我们再看一下find() 方法 返回的是一个bs4.element.Tag对象
而find_all()是一个列表(有很多bs4.element.Tag对象的元素)
7.2 find_parents() find_parent() find_next_siblings() find_next_sibling()
• find_parents() 搜索所有父亲
• find_parrent() 搜索单个父亲
• find_next_siblings()搜索所有兄弟
• find_next_sibling()搜索单个兄弟
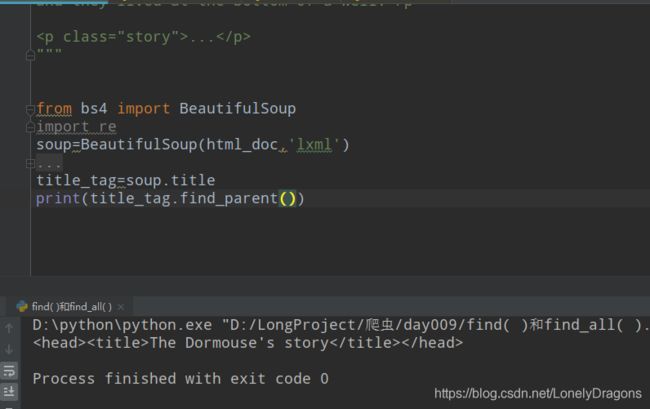
Elsie怎么找的呢
![]()
s是一个bs4.element.NavigableString对象
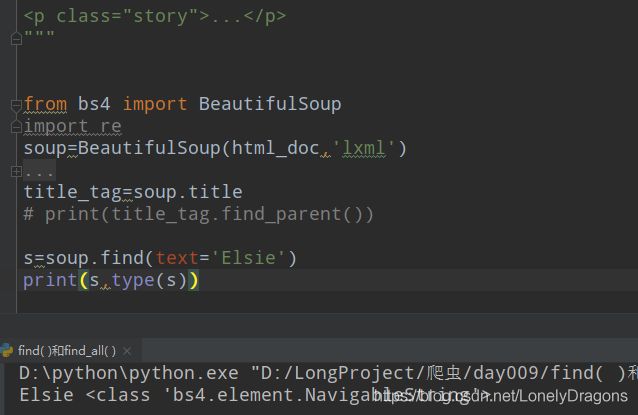
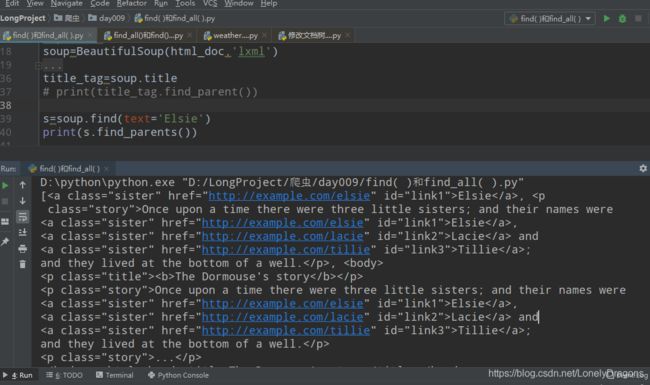
结果是一堆 也就是用find_all 找出的是Elsie的所有父节点
D:\python\python.exe "D:/LongProject/爬虫/day009/find( )和find_all( ).py"
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>, <body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body>, <html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body></html>, <html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body></html>]
Process finished with exit code 0
那要是找p节点(有Elsie) 在s.find_parents()中加上’p’ 而且这个s不是soup(不是一个BeautifulSoup对象) 而是
s=soup.find(text='Elsie')
print(s.find_parent('p'))
s是个 bs4.element.NavigableString对象
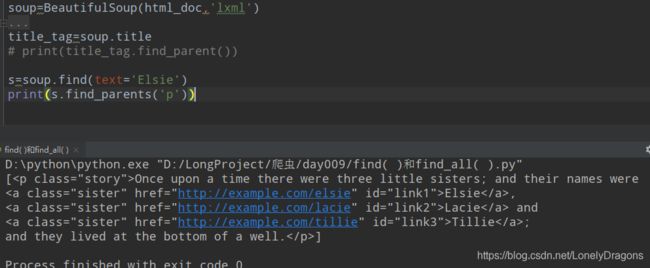
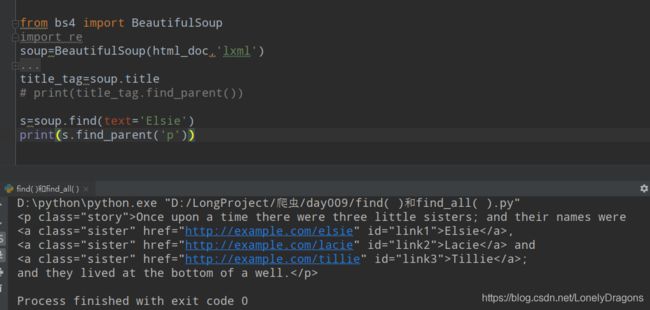
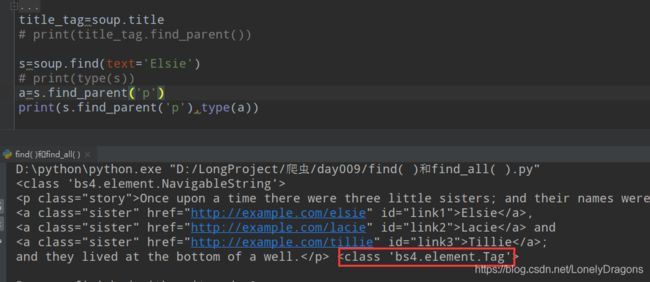

find_parent方法返回的是一个bs4.element.Tag 对象 (bs4的元素标签)
而find_parent返回的是一个类似列表的(列表中有很多bs4.element.Tag 对象的元素) 但其实是一个bs4.element.ResultSet对象 (bs4元素结果)
且调用这两种方法的都是一个bs4.element.NavigableString对象
来历(比如这个对象就是s)
s=soup.find(text='Elsie')
print(type(s))
<class 'bs4.element.NavigableString'>
html_doc='那一堆'
from bs4 import BeautifulSoup
import re
soup=BeautifulSoup(html_doc,'lxml')
# name : tag名称
# attr : 标签的属性
# recursive : 是否递归搜索
# text : 文本内容
# limit : 限制返回条数
# kwargs : 关键字参数
# a_tags=soup.find_all('a',"sister")
# print(a_tags)
# a=soup.find_all(id='link1')
# print(a)
# print(soup.find_all(id=re.compile('link1'))) #这个结果和前者一样的
# print(soup.find_all(text=re.compile('story')))
# print(soup.find_all('a',limit=0))
# print(soup.find_all('html',recursive=False))
# print(soup.find_all('a',limit=1)[0])
# print(soup.find('a'),type(soup.find('a')))#返回的是一个bs4.element.Tag对象
# print(soup.prettify())
title_tag=soup.title
# print(title_tag.find_parent())
s=soup.find(text='Elsie')
# print(type(s))
# a=s.find_parent('p')
# print(s.find_parent('p'),type(a))
a=s.find_parents('p')
print(s.find_parents('p'),type(a))
也就是bs4.element.NavigableString
剩下这个两个方法
• find_next_siblings()搜索所有兄弟
• find_next_sibling()搜索单个兄弟
find_next_siblings()返回的是一个
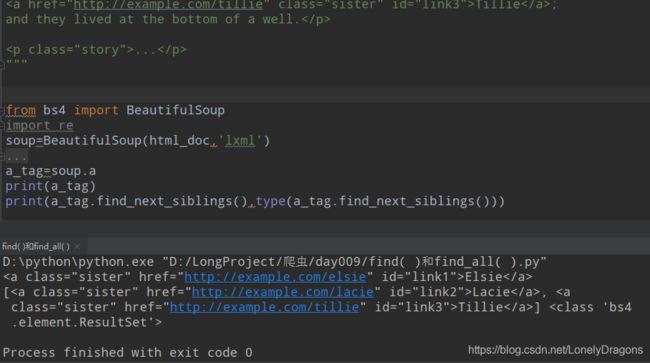
当然也可以传入’a’ (好像有点多此一举)
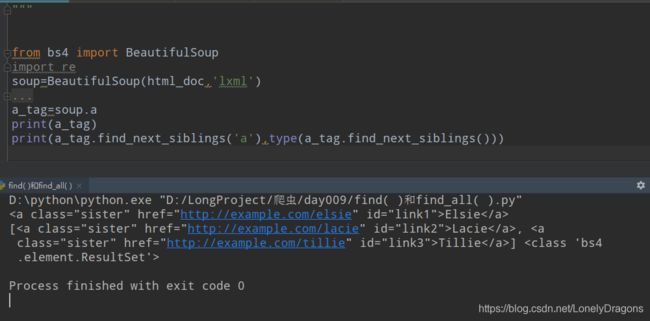
那试试这样
print(soup.find_next_siblings('a'))
果然还不行的
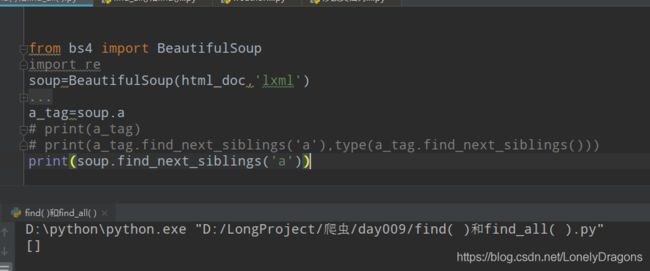
find_mext_siblings() 找到了link1的 所有的兄弟了 所有返回结果有包含link2 link3 的两个标签
调用find_mext_siblings() 和find_next_sibling()的对象得是个bs4.element.Tag 对象
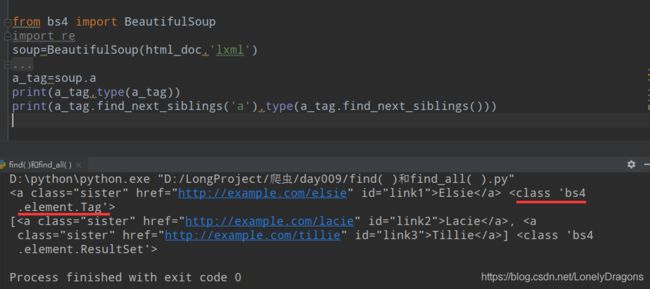
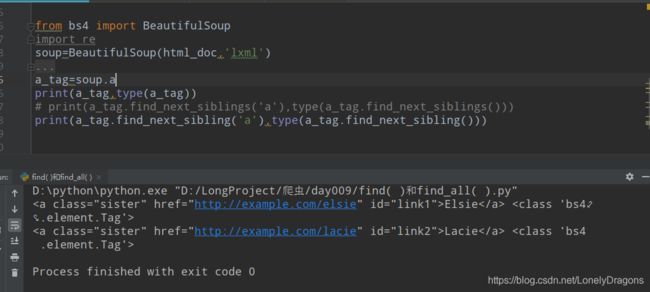
find_next_sibling() 找下一个的兄弟
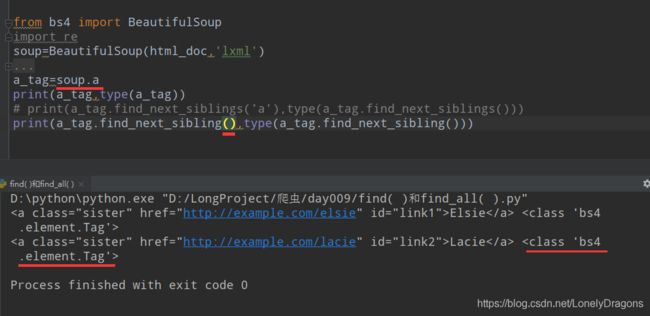
还算值得总结的是find_mext_siblings() 和find_next_sibling()方法中传入’a’的操作可有可无
因为 当然传入更保险的
a_tag=soup.a
find_next_sibling()返回的结果是bs4.element.Tag对象 找下一个的兄弟
find_next_siblings()返回的是bs4.element.ResultSet对象 像一个有很多bs4.element.Tag对象元素的列表 找所有的兄弟
7.3 find_previous_siblings() find_previous_sibling find_all_next() find_next()
• find_previous_siblings() 往上搜索所有兄弟
• find_previous_sibling() 往上搜索单个兄弟
• find_all_next() 往下搜索所有元素
• find_next()往下查找单个元素
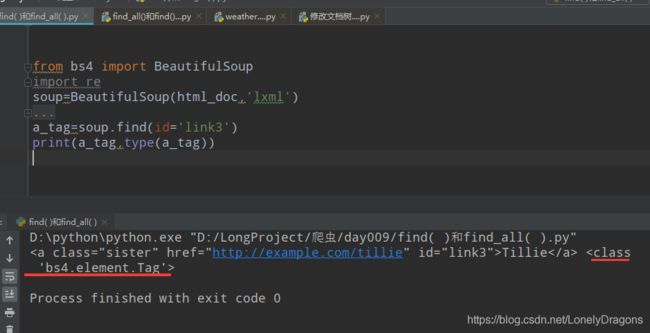
那结和上面的方法 如何使用往上搜索 比如找上面的含有link2的标签
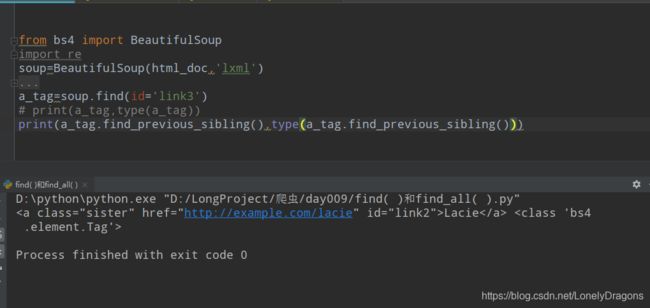
找含link3标签的前所有个兄弟标签
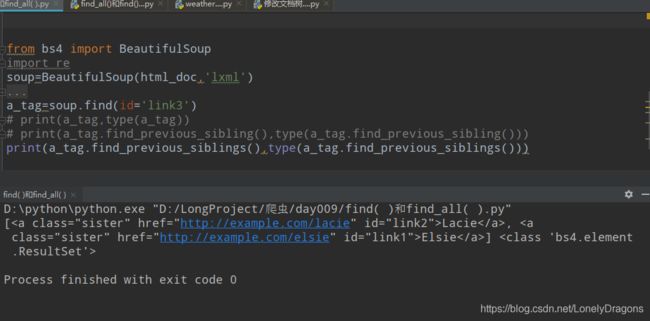
find_previous_sibling()的调用对象就是bs4.elements.Tag
find_previous_siblings()也是
find_previous_sibling()与find_previous_siblings()返回结果跟前面的方法一样的
• find_all_next() 往下搜索所有元素
• find_next()往下查找单个元素
all_next就是返回所有的 next就是返回一个
find_all_next() 往下搜索所有元素 就是从当前的位置往下查找所有的元素 可能是它的子节点或者是兄弟节点
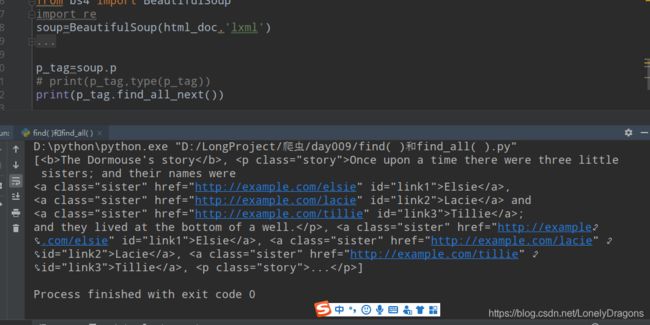
也就是应该从这开始的
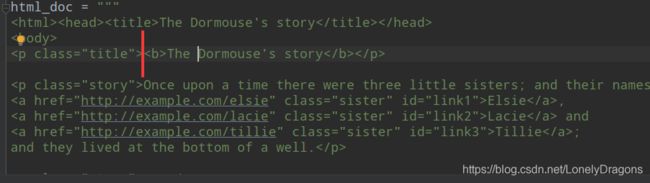
再来试试用find_next() 查找一个a标签
上面的这些比较多,但是容易理解使用 就是不太好记住的
8. 修改文档树
• 修改tag的名称和属性
• 修改string 属性赋值,就相当于用当前的内容替代了原来的内容
• append() 向tag中添加内容,就好像Python的列表的 .append() 方法
• decompose() 修改删除段落,对于一些没有必要的文章段落我们可以给他删除掉
现在要把class的属性改成content 就是class='concent’那该怎么做
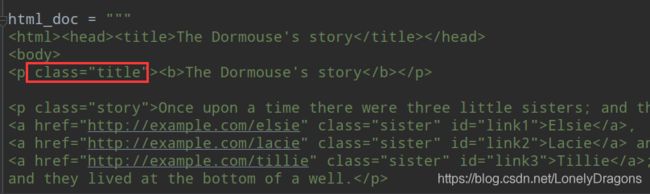
那就得先找到这个p标签
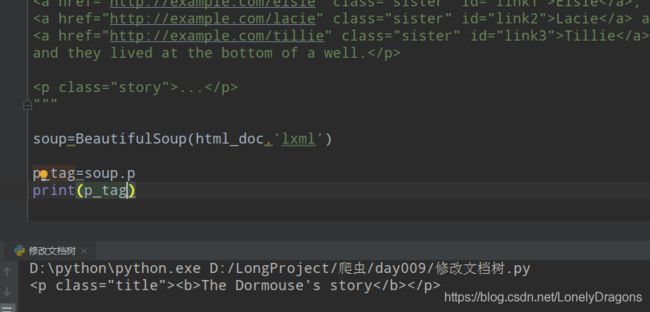
那样吧 我们先修改标签的名称 再修改标签的值
1.修改标签名称与修改标签的属性值
from bs4 import BeautifulSoup
import re
html_doc = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup=BeautifulSoup(html_doc,'lxml')
p_tag=soup.p
print(p_tag)
p_tag.name='w' #修改标签的名称
p_tag['class']='content' #修改属性值
print(p_tag)
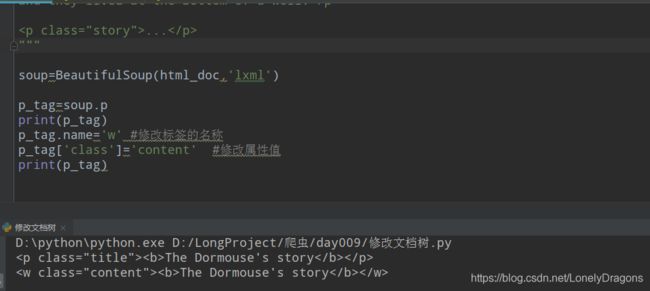
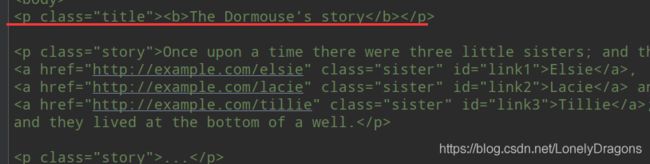
2.修改string 属性赋值
• 修改string 属性赋值,就相当于用当前的内容替代了原来的文本内容
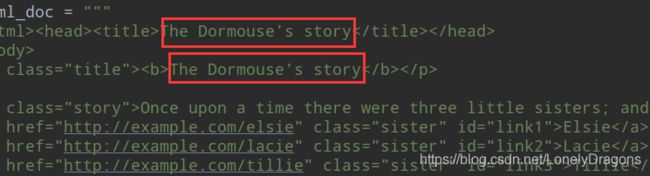
比如上面的的例子 两个内容重复了 我们可以以此为例修改一个
还是先找到你要修改的标签的
p_tag=soup.p
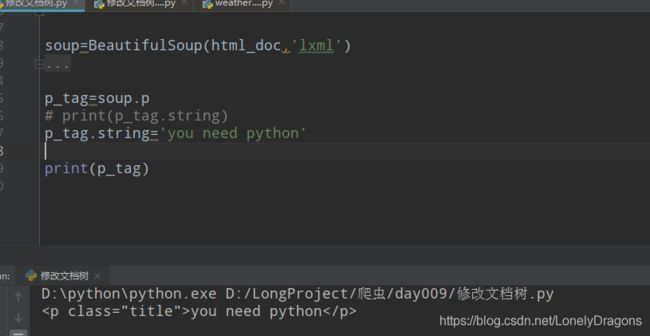
修改就是第一个p标签的
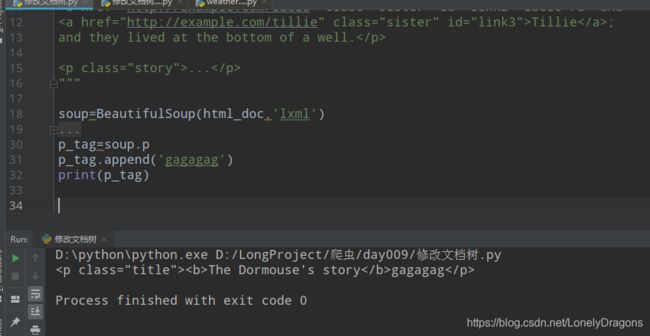
3.append() 向tag中添加内容
• append() 向tag中添加内容,就好像Python的列表的 .append() 方法
还是先来个p_tag=soup.p
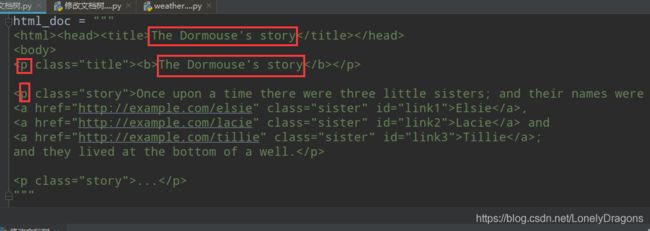
4.decompose() 修改删除段落
• decompose() 修改删除段落,对于一些没有必要的文章段落我们可以给他删除掉
html_doc中的
<p class="title"><b>The Dormouse's story</b></p>
与上下内容有些重复
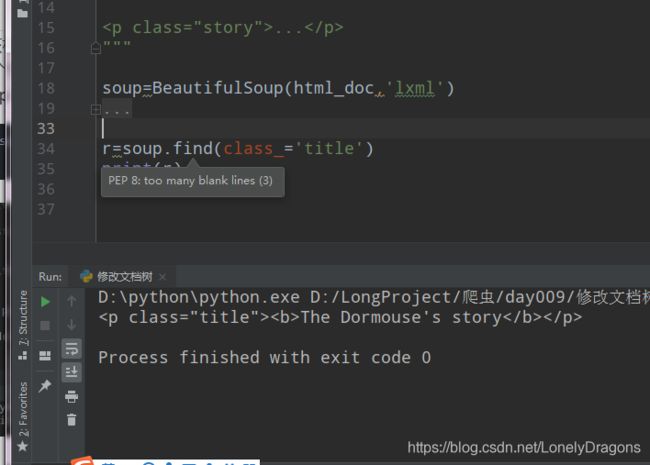
那么就得删除这段数据的 以此为例(由)来演试方法
那还就得找到该标签吧
怎么找 我们换个找法跟 p_tag=soup.p不一样的
soup.find(class_=‘title’)
r=soup.find(class_='title')
print(r)
那怎么删的呢 这有个返回值r对吧
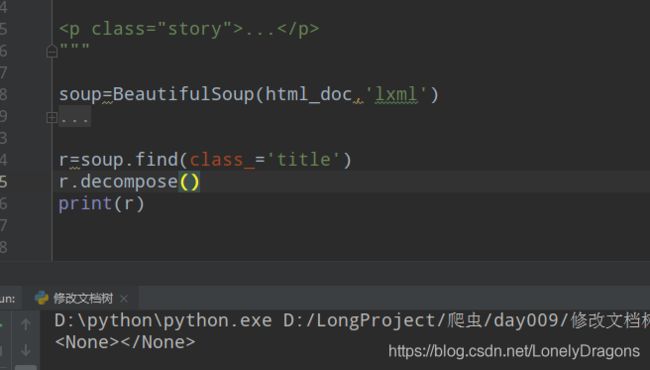
这个r就没了
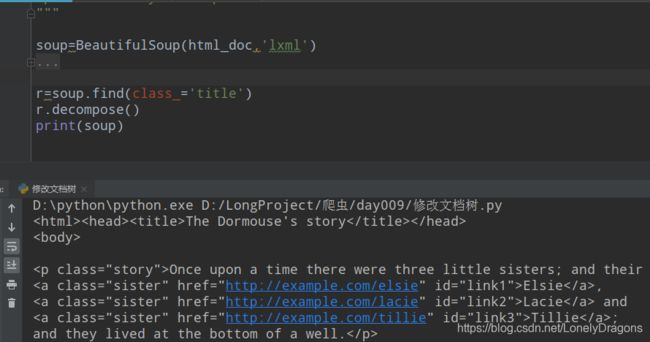
或者我们打印soup
中间的p标签已经删去不见了
小练习
先打开中国天气网页
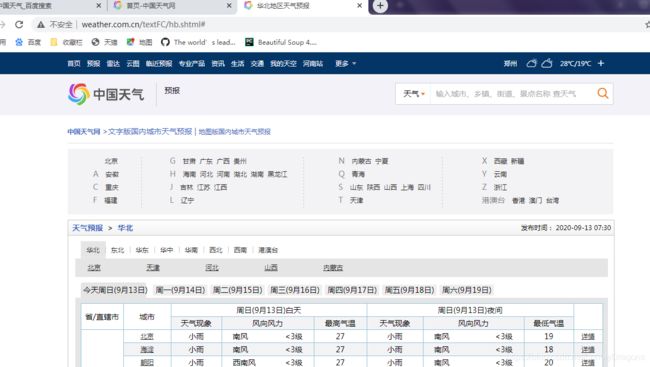
爬取全中国所有的城市对应的最低气温
但是这个全国的每个省份是分开的
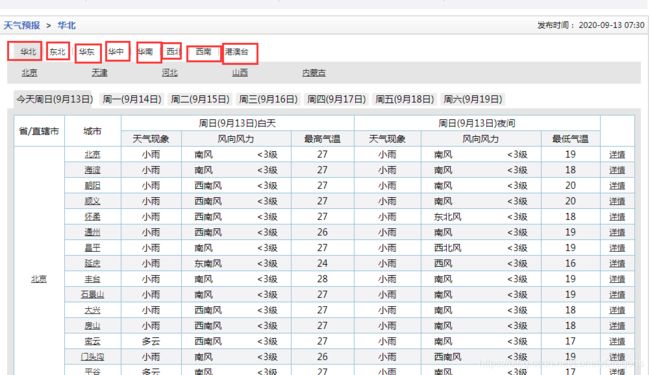
有华北的 还有东北的 华东的 华中的 … 就是依次爬取
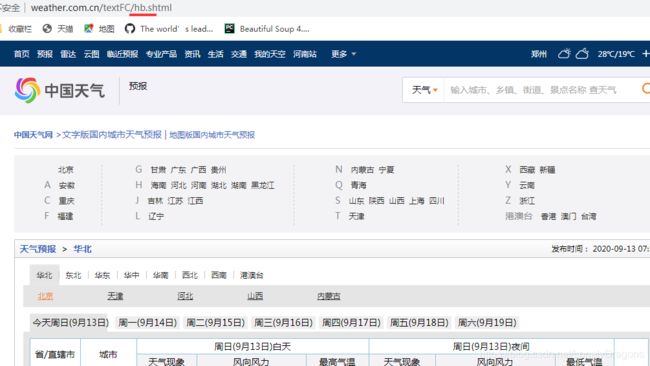
我们先看下华北的url
http://www.weather.com.cn/textFC/hb.shtml
再看一下东北的
http://www.weather.com.cn/textFC/db.shtml
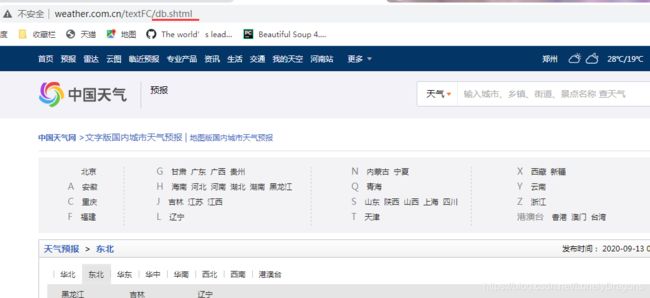
是有一点点小变化
就可以看出来每一个url地址 对应一个地区(对应一个华北 华东 东北这样的一个地区)
依次把这些地区的省份气温爬取完后 就是把全国的地区的气温(为了简演示 就拿夜间最晚的)爬取了
我们先搞清我们的需求
需求:爬去全中国所有城市以及对应的温度
然后就开始分析页面了 先来分析第一个华北这个页面 (分析页面是做爬虫中最重要的一个环节 如果不会分析页面就会导致老师讲的你会 但是换几个页面就不会了 )
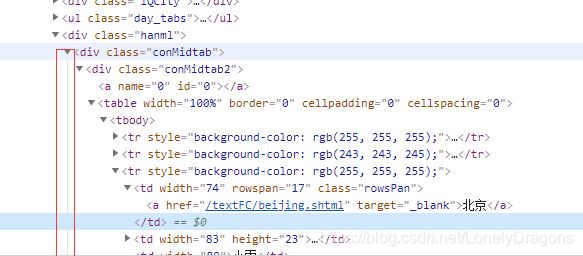
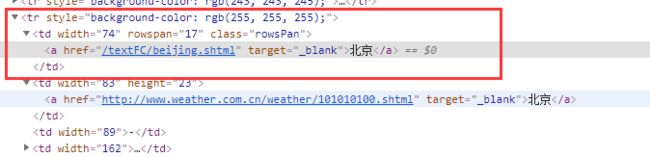
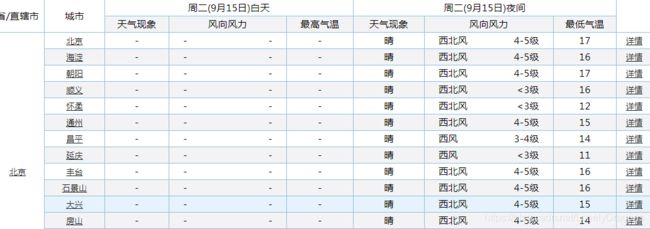
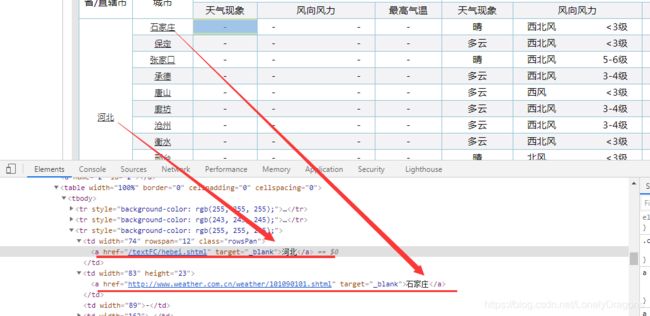
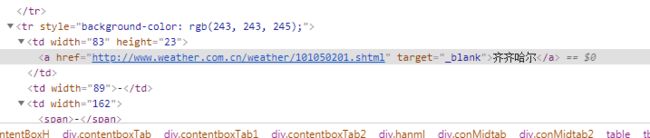
右键点击北京 检查
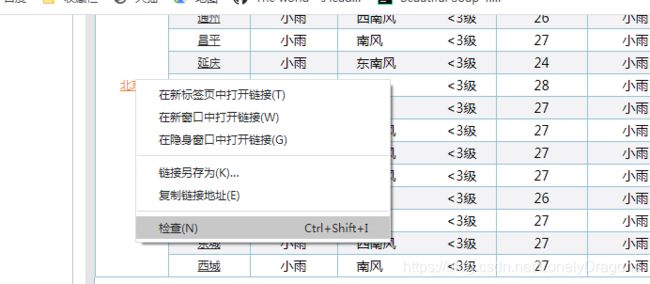
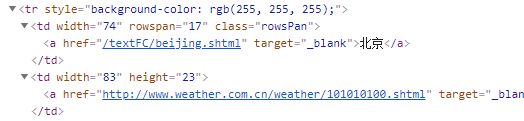
就定位到了北京这个文本内容所在的节点
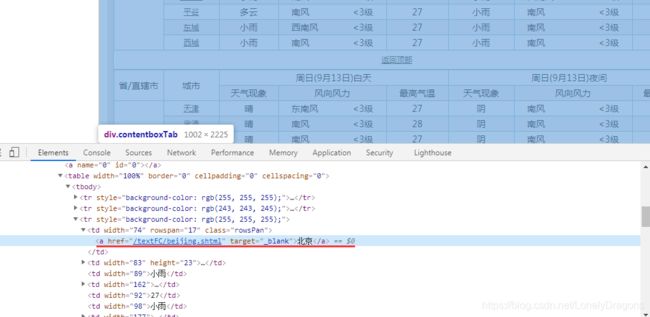
可以看出北京这个文本内容在a标签中 a标签的父标签是td标签
td标签的父标签是tr标签
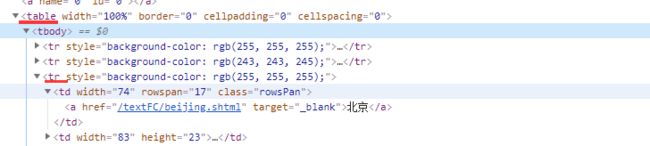

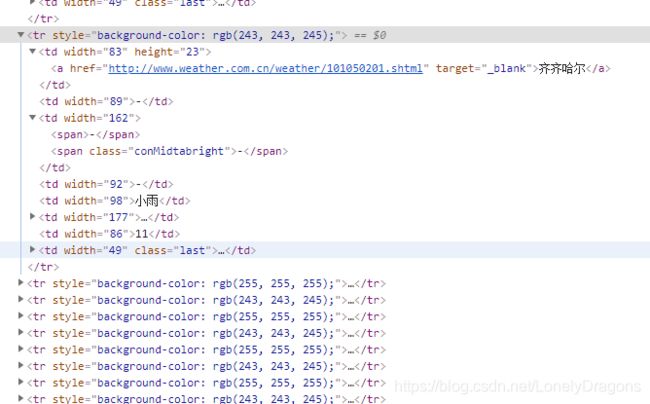
我们所需要的这个tr标签是table下的第三个 tr标签 也就是倒数第一个
而且我们鼠标放到table标签上 北京的区域全部属于一个高亮状态 而其他省份没有高亮的选中状态
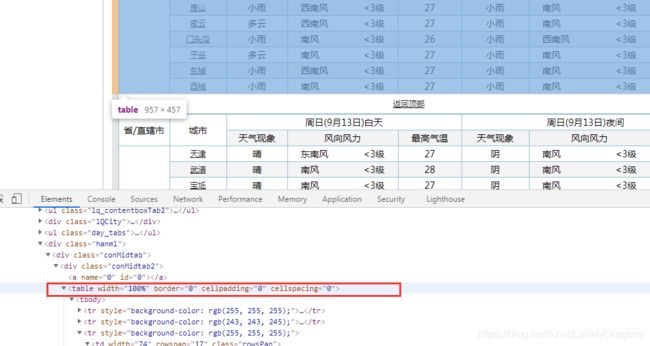
那么就是这个table只管北京这个直辖市 那么天津就也有一个table 河北也有一个table
所以这个table就有很多的 我们应该用find_all找所有
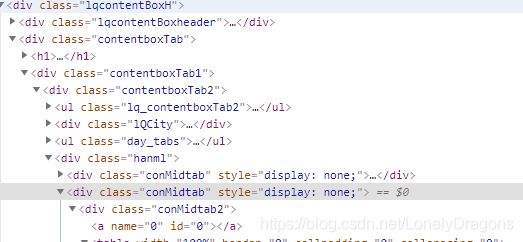
咱们再往上看
我们可以看到table标签有一个上级有一个属性为class="conMidtab"一个div标签
当我们鼠标放在这个属性值为conMidtab的div标签时 我们会发华北区所有省份/直辖市 (北京 天津 河北 山西 内蒙古…) 都是高亮状态
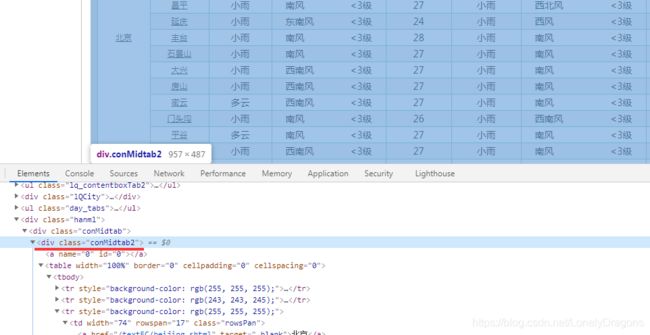
那么我们就捋一捋思路
class="conMidtab"这个div标签 找一个就行 用find 因为这个标签就包含这个页面的所有内容了的
而且我们发现这有个线
顺着这个线往下找
下面有还有很多属性值是conMidtab这样的标签
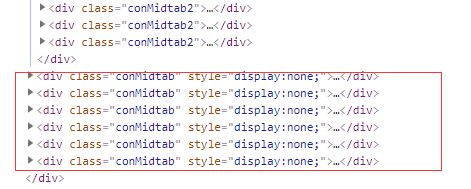
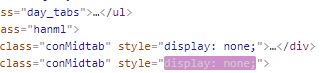
style=“display:none;” style 就是格式 display 就是显示 none就是没有的意思 就是格式是没有显示 (被隐藏的状态)
我们再点开周一的天气 会发现第二个属性值conMidtab的标签就不再是隐藏状态了 display: block 就是打开的意思
也就是可以发现每一个属性值conMidtab的div标签就是对应这个页面上周几的所有地方的天气
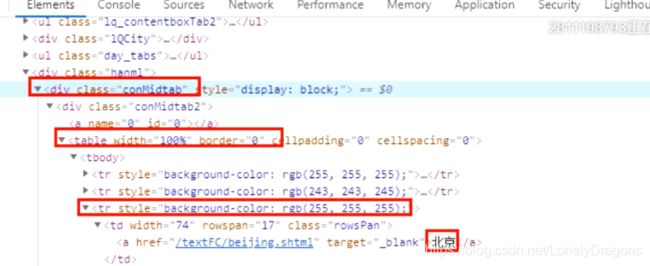
所以总的页面分析的思路就是 需求是先找到精准地方的夜间最晚天气
首先得先找到 属性值是conMidtab的div标签 然后再找下面的table标签
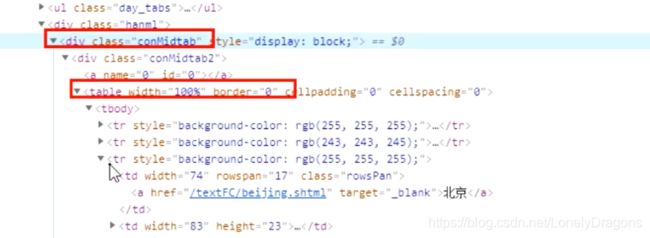
前两个tr标签都是表头 它们没有子节点(标签)
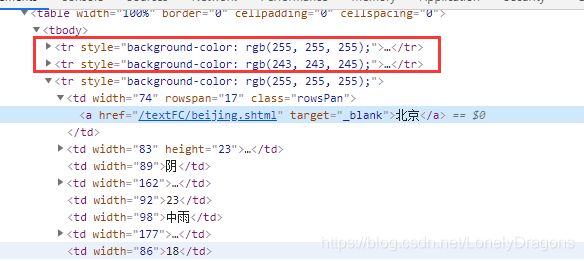
然后找第三个tr标签 找到其中的第0个td 就是要其中的地点文本内容 如北京
然后倒数第二个td是温度

操作
##
# 需求:爬去全中国所有城市以及对应的温度
import requests
from bs4 import BeautifulSoup
#定义一个函数来解析网页
def parse_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'
}
reponse=requests.get(url,headers=headers)
print(reponse)
def main():
url='http://www.weather.com.cn/textFC/hb.shtml'
parse_page(url)
if __name__ == '__main__':
main()
我们也可以先打印一下这个reponse.text(reponse只是一个响应状态对象)
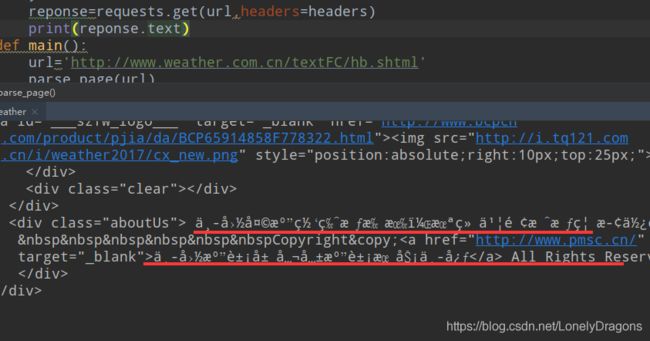
我们发现reponse.text有很多乱码
我们可以换种方式
print(reponse.content.decode('utf-8'))
也就是第一种 reponse.text 方式会猜网页的编码方式 猜错就会出现乱码
print(reponse.content.decode(‘utf-8’))
而上面的代码就是 先.content拿到这个网页的这个字节流数据
再通过decode()转换成字符串 并且再设置一个‘utf-8’的编码方式
这样就可以了
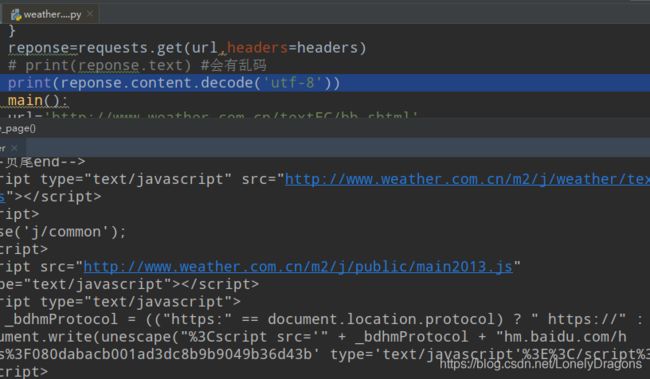
能确实拿到数据后就不用打印了 就可以设置一个值返回
text=reponse.content.decode('utf-8')
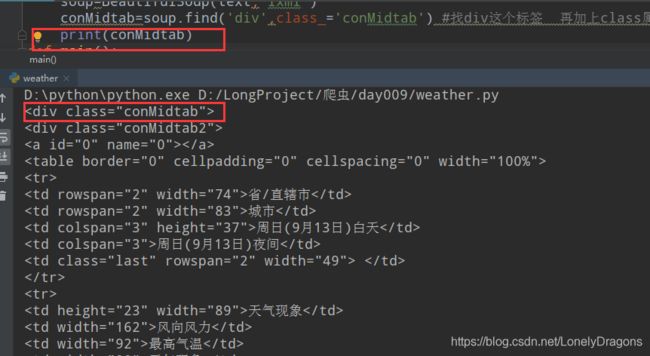
那么这个text就在这个华北的网页源代码
仅找第一个conMidtab属性值得div标签 方便练习 每个这样的标签都是有着不同的周几的全部此页面华北的所有省/直辖市的天气
所以找conMidtab属性值得div标签用find方法
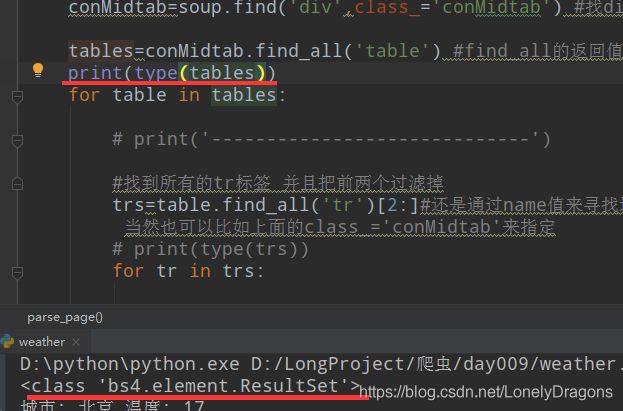
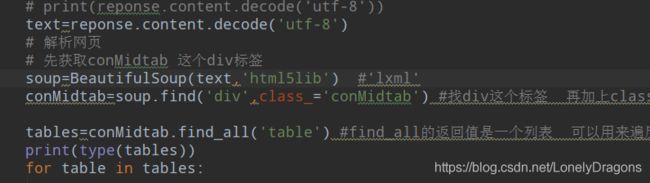
conMidtab=soup.find('div',class_='conMidtab') #找div这个标签 再加上class属性的值是conMidtab
那么这样我们就获取到属性值是conMidtab的div标签了 而且这里面有很多table 有北京的 天津的 河北的 山西的…所以我们得find_all 找table
soup=BeautifulSoup(text,'lxml')
conMidtab=soup.find('div',class_='conMidtab') #找div这个标签 再加上class属性的值是conMidtab
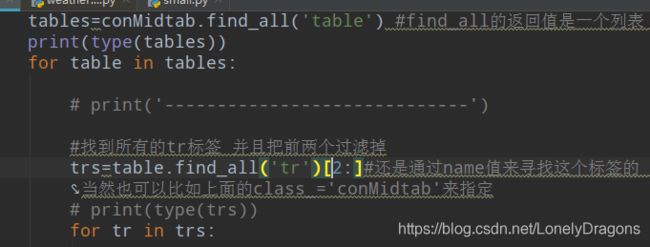
tables=conMidtab.find_all('table') #find_all的返回值是一个列表 可以用来遍历
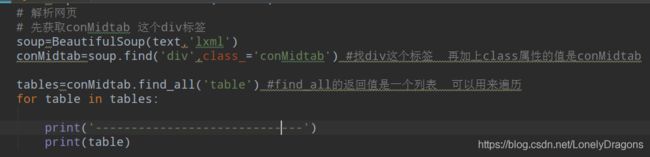
就能看到有很多table
那么接下来就要找table中的第三个tr标签 需要把前两个tr标签过滤掉
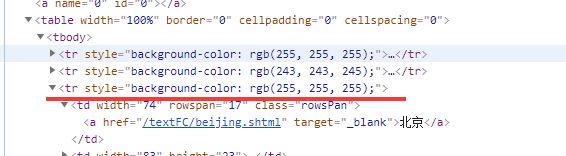
用find_all找到所有的tr 就是trs一个列表
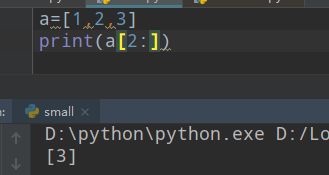
##
# 需求:爬去全中国所有城市以及对应的温度
import requests
from bs4 import BeautifulSoup
#定义一个函数来解析网页
def parse_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'
}
reponse=requests.get(url,headers=headers)
# print(reponse.text) #会有乱码
# print(reponse.content.decode('utf-8'))
text=reponse.content.decode('utf-8')
# 解析网页
# 先获取conMidtab 这个div标签
soup=BeautifulSoup(text,'lxml')
conMidtab=soup.find('div',class_='conMidtab') #找div这个标签 再加上class属性的值是conMidtab
tables=conMidtab.find_all('table') #find_all的返回值是一个列表 可以用来遍历
for table in tables:
# print('-----------------------------')
#找到所有的tr标签 并且把前两个过滤掉
trs=table.find_all('tr')[2:]#还是通过name值来寻找这个标签的 当然也可以比如上面的class_='conMidtab'来指定
for tr in trs:
print(tr)
break #找到北京结束
def main():
url='http://www.weather.com.cn/textFC/hb.shtml'
parse_page(url)
if __name__ == '__main__':
main()
就这样找到 北京(第三个tr中第一个td) 还有北京的天气(第三个tr中倒数第二个td)
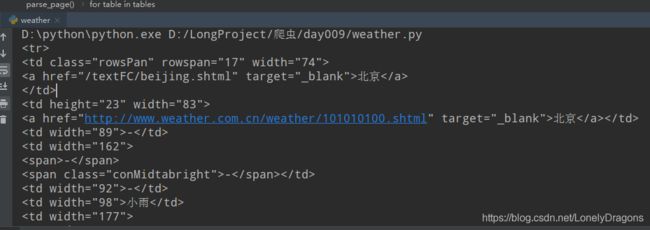
但是只要td标签中的内容 就不能再用string 此处不能用string
stripped_strings 就是获取去空格后的字符串
find_all的返回值是个列表中是一个td标签一个元素 第一个元素中就是第一个td然后提取其中的 内容北京
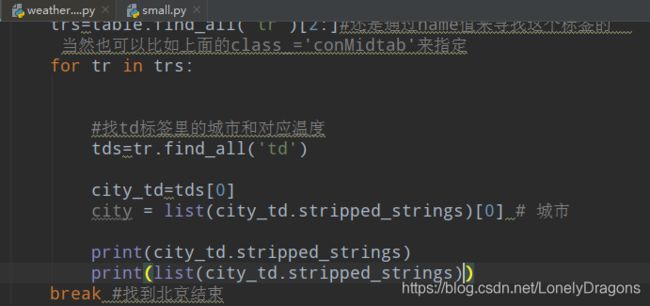

find_all返回的是
bs4.element.ResultSet对象
city_td.stripped_strings 这个方法直接将bs4.elements.Tag对象(也就是将bs4.element.ResultSet的元素)中的文本内容找到定位
其返回值是
返回值类型就是
然后
city = list(city_td.stripped_strings)[0] 就取到北京了

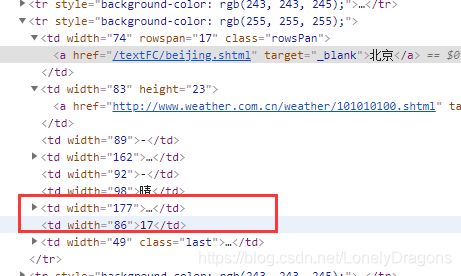
同理我们可以拿这个温度
在倒数第二个td中
##
# 需求:爬去全中国所有城市以及对应的温度
import requests
from bs4 import BeautifulSoup
#定义一个函数来解析网页
def parse_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'
}
reponse=requests.get(url,headers=headers)
# print(reponse.text) #会有乱码
# print(reponse.content.decode('utf-8'))
text=reponse.content.decode('utf-8')
# 解析网页
# 先获取conMidtab 这个div标签
soup=BeautifulSoup(text,'lxml')
conMidtab=soup.find('div',class_='conMidtab') #找div这个标签 再加上class属性的值是conMidtab
tables=conMidtab.find_all('table') #find_all的返回值是一个列表 可以用来遍历
for table in tables:
# print('-----------------------------')
#找到所有的tr标签 并且把前两个过滤掉
trs=table.find_all('tr')[2:]#还是通过name值来寻找这个标签的 当然也可以比如上面的class_='conMidtab'来指定
for tr in trs:
#找td标签里的城市和对应温度
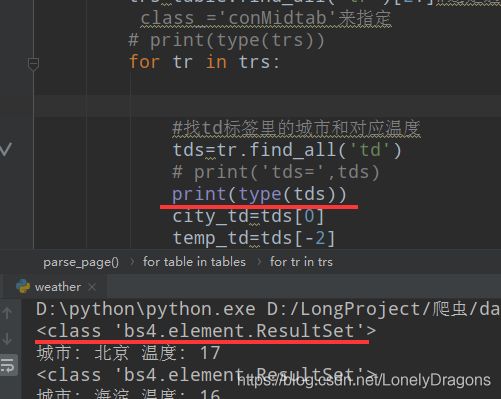
tds=tr.find_all('td')
# print('tds=',tds)
# print(type(tds))
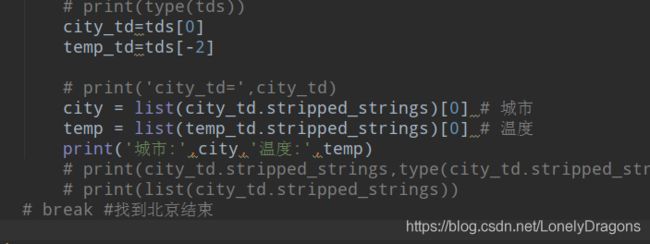
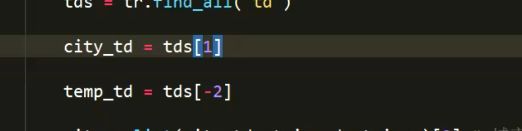
city_td=tds[0]
temp_td=tds[-2]
# print('city_td=',city_td)
city = list(city_td.stripped_strings)[0] # 城市
temp = list(temp_td.stripped_strings)[0] # 温度
print(city,temp)
# print(city_td.stripped_strings,type(city_td.stripped_strings))
# print(list(city_td.stripped_strings))
break #找到北京结束
def main():
url='http://www.weather.com.cn/textFC/hb.shtml'
parse_page(url)
if __name__ == '__main__':
main()
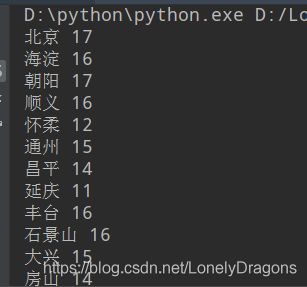
再把break注释掉
那么运行程序就会把属性值为conMidtab的div 每一个这样的div就是一个地区的
每个属性值为conMidtab的div就是http://www.weather.com.cn/textFC/hb.shtml#页面的一个周几的所有华北所有地区的气温
每个属性值为conMidtab2的div就是这天(一个周几)的 所有华北所有地区的气温

所以注释break后就不会从找到第一个地区(北京)后停止 而是把这个页面(hb.shtml#)今天的华北全部地区的天气 地区全部拿取出来都

拿不了一周全因为 上图中第一步用find方法找了最近的class="conMidtab"的div标签 也就是今天的华北全部地区的天气
display:block 就是打开 展示
![]()
![]()
因为每一个coMidta2 div标签都代表一个华北中的一个地区所以直接找所有的table标签 返回一个 bs4.elements.ResultSet对象(tables) 然后遍历它
还是得到bs4.elements.ResultSet对象(trs=table.find_all(‘tr’))
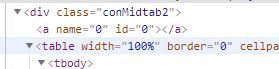
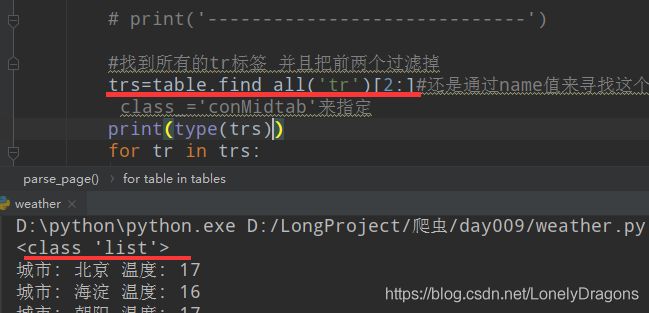
trs=table.find_all(‘tr’)[2:] 这步直接让这个 bs4.elements.ResultSet对象变成了list对象
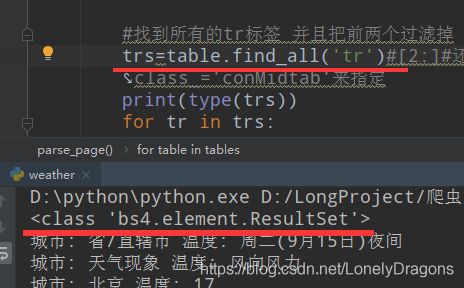
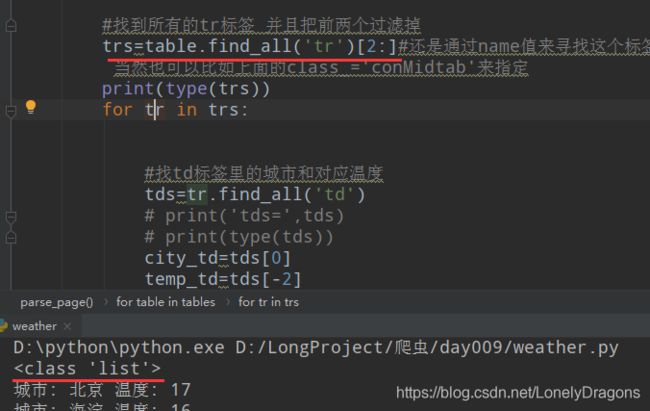
但其实也没啥关系因为 [2:]为了找第三个tr标签
因为其中有 地区和温度 但是包含地区和温度的标签第一个td 倒数第二个td
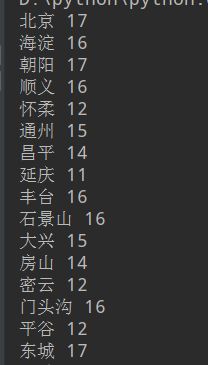
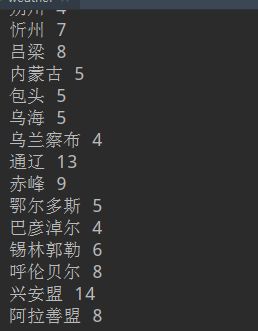
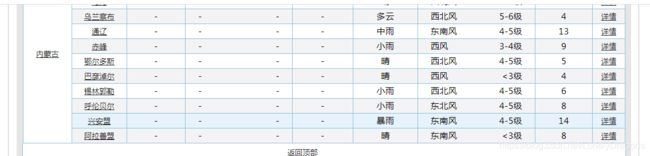
结果开头都没毛病
再换个东北的页面 http://www.weather.com.cn/textFC/db.shtml
头部有问题
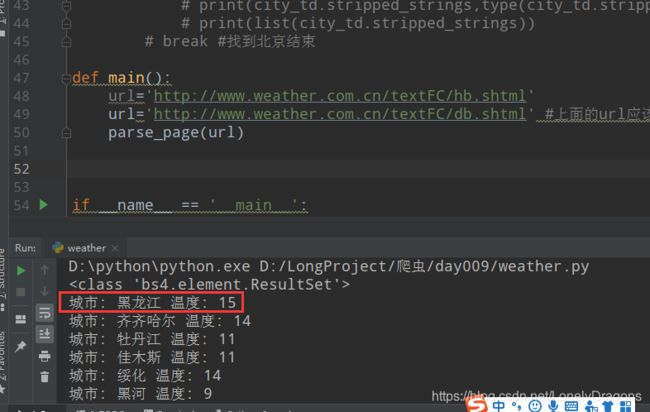
应该是哈尔滨开始的
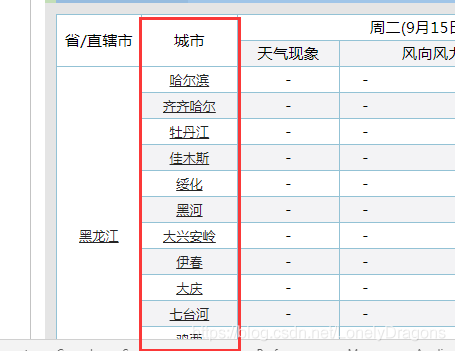
少这个哈尔滨了
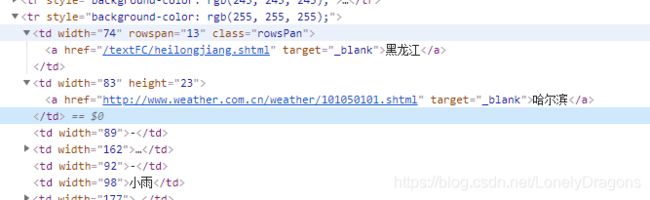
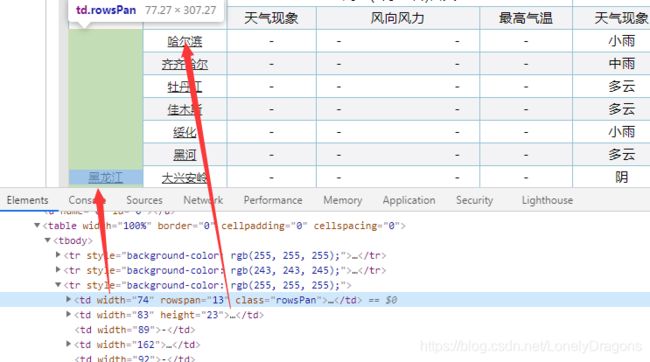
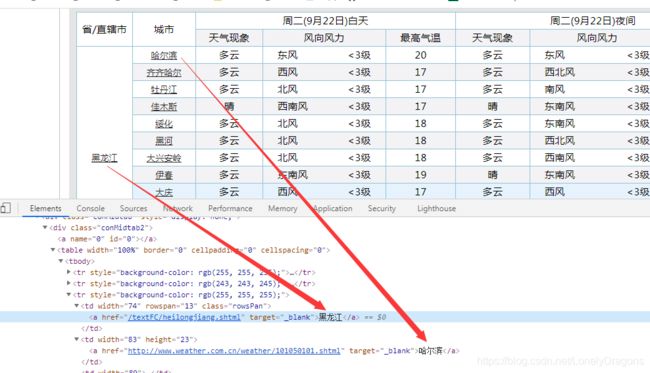
我们发现哈尔滨早第三个tr中第二个的td 中 而不是在第一个td中
而且我们发现华北页面中 北京在第一个td中 也在第二一个td中
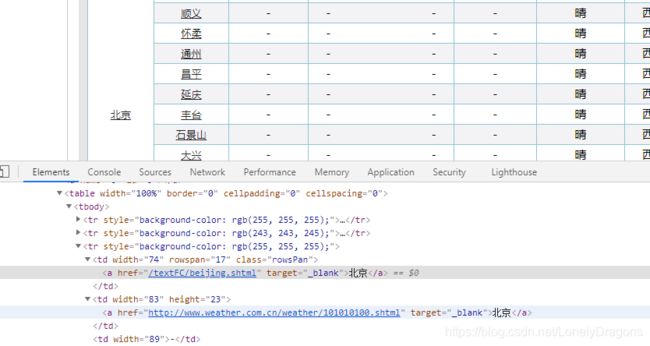
那么就可以知道第一个td中是
第二个td才是这个城市地区
而第一个地区是省/直辖市
如果这样
发现是没法粗鲁解决的
也就是什么时候取第一个td 黑龙江的 什么时候取第二td 哈尔滨的 是不确定的
我们可以拿到他们的索引值 什么时候拿到第一个td什么时候拿到第二个td
所以我们得想办法拿到tr坐标的索引值
我们加上index 拿到每个tr的下标索引值
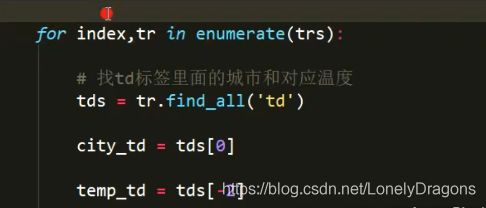
enumerate(trs)
enumerate(trs) 返回2个值 第一个是下标索引 第二个是下标索引所 对应的值
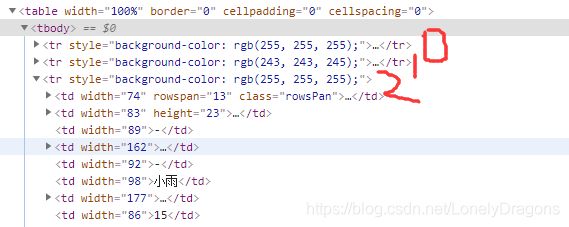
图中的tr的索引值分别是0 1 2 但是在咱们的程序中已经过滤前两个了

那么就是第三个tr索引值是0
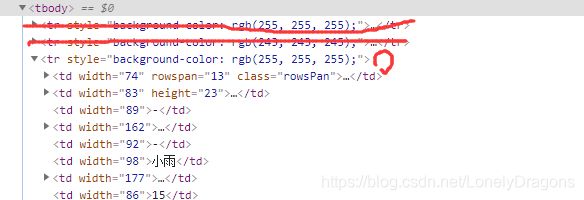


我们发现除了前两个tr 后面的tr中都是含有地区 天气 内容的 但是很特别的是 第三个tr(每个页面的第三tr都是这样)
第一个td是 省或者直辖城市 第二个td才是第一个城市
而像北京 这样的直辖市是北京 第一个城市还是北京 那么华北的页面第三个tr中的第一个td 和第二个td内容都一样的
都是北京
而第四个tr中第一个td是城市地区 而第二个是没有内容的 但是他们的倒数第二个td都是本城市的温度
##
# 需求:爬去全中国所有城市以及对应的温度
import requests
from bs4 import BeautifulSoup
#定义一个函数来解析网页
def parse_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'
}
reponse=requests.get(url,headers=headers)
# print(reponse.text) #会有乱码
# print(reponse.content.decode('utf-8'))
text=reponse.content.decode('utf-8')
# 解析网页
# 先获取conMidtab 这个div标签
soup=BeautifulSoup(text,'lxml')
conMidtab=soup.find('div',class_='conMidtab') #找div这个标签 再加上class属性的值是conMidtab
tables=conMidtab.find_all('table') #find_all的返回值是一个列表 可以用来遍历
print(type(tables))
for table in tables:
# print('-----------------------------')
#找到所有的tr标签 并且把前两个过滤掉
trs=table.find_all('tr')[2:]#还是通过name值来寻找这个标签的 当然也可以比如上面的class_='conMidtab'来指定
# print(type(trs))
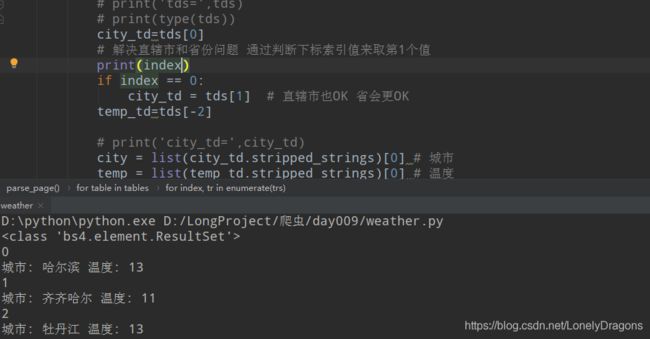
for index, tr in enumerate(trs):
#找td标签里的城市和对应温度
tds=tr.find_all('td')
# print('tds=',tds)
# print(type(tds))
city_td=tds[0]
# 解决直辖市和省份问题 通过判断下标索引值来取第1个值
if index == 0:
city_td = tds[1] # 直辖市也OK 省会更OK
temp_td=tds[-2]
# print('city_td=',city_td)
city = list(city_td.stripped_strings)[0] # 城市
temp = list(temp_td.stripped_strings)[0] # 温度
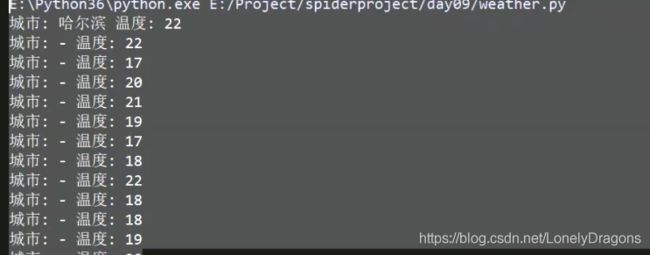
print('城市:',city,'温度:',temp)
# print(city_td.stripped_strings,type(city_td.stripped_strings))
# print(list(city_td.stripped_strings))
# break #找到北京结束
def main():
url='http://www.weather.com.cn/textFC/hb.shtml'
url='http://www.weather.com.cn/textFC/db.shtml' #上面的url应该是自动注销的 看字色
parse_page(url)
if __name__ == '__main__':
main()
所以下面使用enumerate(trs)记住比较好 理解
for index, tr in enumerate(trs):
#找td标签里的城市和对应温度
tds=tr.find_all('td')
# print('tds=',tds)
# print(type(tds))
city_td=tds[0]
# 解决直辖市和省份问题 通过判断下标索引值来取第1个值
print(index)
if index == 0:
city_td = tds[1] # 直辖市也OK 省会更OK 完美解决了
temp_td=tds[-2]
如果在试试港澳台地区.

结果就不对.
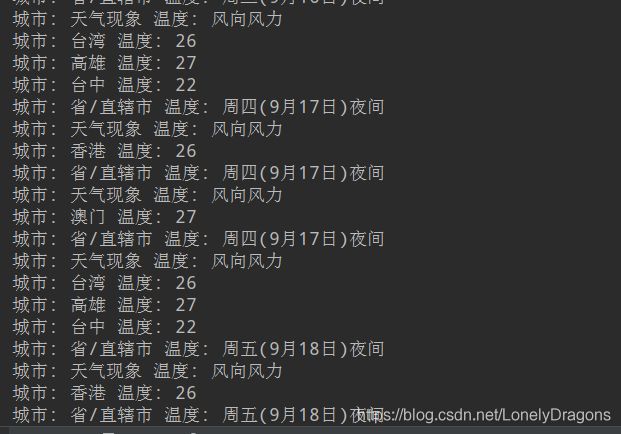
那么只能是这个港澳台的页面有问题
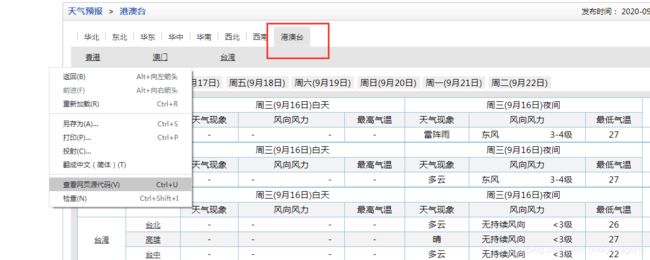
已知 class=“conMidtab” 的div标签(红框选中的)每一个这样的标签就是一个周几的华北页面的全部天气
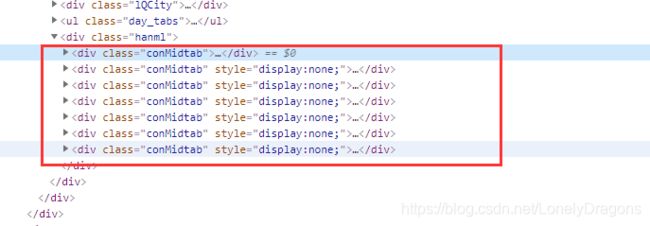
而且每一个class=“conMidtab2” 的div标签是华东页面中的每一个地区的天气
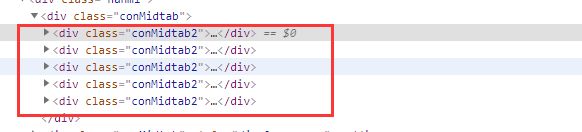
查看港澳台这个地区的网页源代码
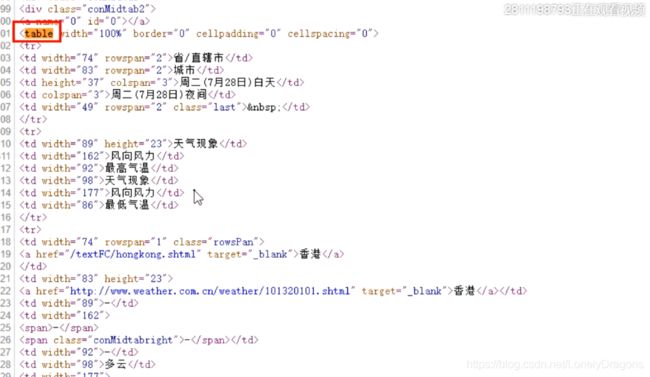

我们发现table 标签又开始 没有结束
说明是她的网页的标签有问题

而在检查中elements中是有这个结束标签的 因为这个Google Chrome功能十分强大 它把这些错乱的标签或者是不完整的标签给咱们补全了 但是在我们获得的网页源码中是没有的 咱门的天气 城市 数据都是从网页源码拿来的
只不过我们再检查中看elements可以更清楚地看数据
elements中的是最终呈现的结果
就是text(就是获取的网页源码)有问题 但是我们总不能自己手动补全吧
bs4的源代码里有一句话
但是很可惜报错了
bs4.FeatureNotFound: Couldn’t find a tree builder with the features you requested: html5lib. Do you need to install a parser library?
bs4.FeatureNotFound:找不到具有您请求的功能的树生成器:html5lib。你需要安装解析器库吗?
安装这个 换源安装 用豆瓣
pip install html5lib -i https://pypi.douban.com/simple
可能pip的版本不够 需要升级 升级后再pip install html5lib
python -m pip install --upgrade pip
原因就是html5lib他的解析能力更强 比如这个text网页源码 不全的 它就能够更强的这种网页错乱问题
# @Time : 2020/7/28 20:49
# @Author : Jerry
# @File : weather.py
# 第一个 分析页面结构
# 第二个 直辖市和省份问题 通过判断下标索引值来取第1个值
# 第三个 网页标签问题 soup = BeautifulSoup(text,'html5lib')
# 需求:爬去全中国所有城市以及对应的温度
import requests
from bs4 import BeautifulSoup
# 定义一个函数来解析网页
def parse_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'
}
response = requests.get(url,headers=headers)
# print(response.content.decode('utf-8'))
text = response.content.decode('utf-8')
#
# # 解析网页
# 先获取conMidtab 这个div标签 pip install html5lib
soup = BeautifulSoup(text,'html5lib')
conMidtab = soup.find('div',class_ = 'conMidtab')
# 找到所有的table标签
tables = conMidtab.find_all('table')
for table in tables:
# print('----------------------------')
# 找到所有的tr标签 并且把前2个过滤掉
trs = table.find_all('tr')[2:]
# enumerate(trs) 返回2个值 第一个是下标索引 第二个是下标索引所 对应的值
for index,tr in enumerate(trs):
# 找td标签里面的城市和对应温度
tds = tr.find_all('td')
city_td = tds[0]
# 解决直辖市和省份问题 通过判断下标索引值来取第1个值
if index == 0: #保证是过滤后前两个tr后 如果这个就是第一个tr(即原来的第三tr 因为第三个tr中前两个td 一个省会 一个城市容易出错 但是天气还是倒数第二个)
city_td = tds[1] # 直辖市也OK 省会更OK
temp_td = tds[-2]
city = list(city_td.stripped_strings)[0] # 城市
temp = list(temp_td.stripped_strings)[0] # 温度
print('城市:',city,'温度:',temp)
# print(tr)
# break # 找到北京结束
def main():
# url = 'http://www.weather.com.cn/textFC/hb.shtml' # 华东
# url = 'http://www.weather.com.cn/textFC/db.shtml' # 东北
# url = 'http://www.weather.com.cn/textFC/gat.shtml' # 港澳台
urls = ['http://www.weather.com.cn/textFC/hb.shtml','http://www.weather.com.cn/textFC/db.shtml','http://www.weather.com.cn/textFC/gat.shtml']
for url in urls:
parse_page(url)
if __name__ == '__main__':
main()
课堂复习
