SSD网络介绍
论文地址
参考这里
SSD
SSD,全称Single Shot MultiBox Detector,是Wei Liu在ECCV 2016上提出的一种目标检测算法,截至目前是主要的检测框架之一,相比Faster RCNN有明显的速度优势,相比YOLO又有明显的mAP优势(不过已经被CVPR 2017的YOLO9000超越)。
背景
目标检测主流算法分成两个类型:
(1)two-stage方法:RCNN系列
通过算法产生候选框,然后再对这些候选框进行分类和回归
(2)one-stage方法:yolo和SSD
直接通过主干网络给出类别位置信息,不需要区域生成
下图是给出的几类算法的精度和速度差异。

特点
1、从YOLO中继承了将detection转化为regression的思路,一次完成目标定位与分类
2、基于Faster RCNN中的Anchor,提出了相似的prior box
3、加入基于特征金字塔(Pyramidal Feature Hierarchy)的检测方式,即在不同感受野的feature map上预测目标
4、这些设计实现了简单的端到端的训练,而且即便使用低分辨率的输入图像也能得到高的精度
SSD网络结构
核心设计理念
(1)采用多尺度特征图用于检测
CNN网络一般前面的特征图比较大,后面会逐渐采用stride=2的卷积或者pool来降低特征图大小,这正如图3所示,一个比较大的特征图和一个比较小的特征图,它们都用来做检测。这样做的好处是比较大的特征图来用来检测相对较小的目标,而小的特征图负责检测大目标。
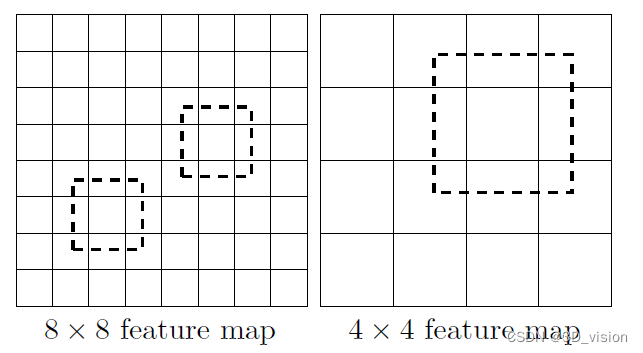
(2)采用卷积进行检测
SSD直接采用卷积对不同的特征图来进行提取检测结果。对于形状为mnp的特征图,只需要采用33p这样比较小的卷积核得到检测值。
(每个添加的特征层使用一系列卷积滤波器可以产生一系列固定的预测。)
(3)设置先验框
SSD借鉴faster rcnn中ancho理念,每个单元设置尺度或者长宽比不同的先验框,预测的是对于该单元格先验框的偏移量,以及每个类被预测反映框中该物体类别的置信度。
模型结构
SSD的模型框架主要由三部分组成,以SSD300为例,有VGG-Base Extra-Layers,Pred-Layers。
VGG-Base作为基础框架用来提取图像的feature,Extra-Layers对VGG的feature做进一步处理,增加模型对图像的感受野,使得extra-layers得到的特征图承载更多抽象信息。待预测的特征图由六种特征图组成,6中特征图最终通过pred-layer得到预测框的坐标,置信度,类别信息。
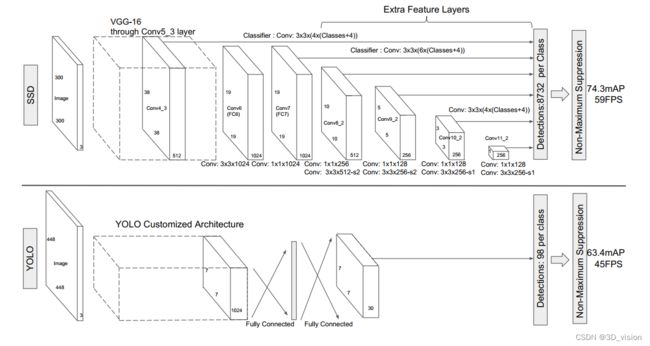


SSD300_Vgg16 整体检测输入以及中间值输出

主干网络
Vgg
ssd采用的是vgg16的特征提取,在vgg16中提取二个特征图,之后又通过额外的增加卷积操作再次提取四个特征图,一种6个特征图。先看vgg的构造:
import torch.nn.init as init
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
from math import sqrt as sqrt
from itertools import product as product
base = {
'300': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'C', 512, 512, 512, 'M',
512, 512, 512],
'512': [],
}
def vgg(cfg, i, batch_norm=False):
layers = []
in_channels = i
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
elif v == 'C':
layers += [nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
pool5 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
conv6 = nn.Conv2d(512, 1024, kernel_size=3, padding=6, dilation=6)
conv7 = nn.Conv2d(1024, 1024, kernel_size=1)
layers += [pool5, conv6,
nn.ReLU(inplace=True), conv7, nn.ReLU(inplace=True)]
return layers
layers=vgg(base[str(300)], 3)
print(nn.Sequential(*layers))
Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=True)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace)
(30): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)
(31): Conv2d(512, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(6, 6), dilation=(6, 6))
(32): ReLU(inplace)
(33): Conv2d(1024, 1024, kernel_size=(1, 1), stride=(1, 1))
(34): ReLU(inplace)
)
第一次的特征图输出是在(22)处,一共经历3次池化,所以特征图大小是38*38,之后用进行二次maxpool2d 特征图在最后输出应该是10x10的大小,但最后一层的maxpool2d的stride=1所以特征图大小还是19x19
额外卷积
SSD中还额外构造了7个卷积,通过1,3,5,7卷积之后的特征图用于输出,这里提取了4个特征图,加上从vgg网络里面提取的2个特征图一共6个特征图。
Sequential(
(0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(2): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))
(3): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(4): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))
(5): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1))
(6): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))
(7): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1))
)
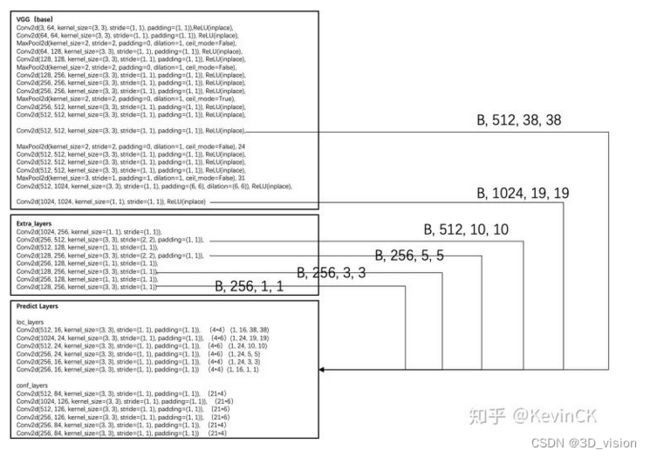
从上图可以看到六个特征图的尺寸:[38, 19, 10, 5, 3, 1],在Predict Layers中可以看到每个特征图中的每个像素点对应的先验框个数为:[4, 6, 6, 6, 4, 4] 。
训练
下载VOC2007,VOC2012数据集进行训练。
数据size为300x300,一共有21个类。
查看官方的mAP为77.7,基本保持了一致。
使用训练后的模型进行推理,推理速度达到了38FPS
结论
优点:
SSD算法的优点应该很明显:运行速度可以和YOLO媲美,检测精度可以和Faster RCNN媲美。
缺点:
需要人工设置prior box的min_size,max_size和aspect_ratio值。网络中prior box的基础大小和形状不能直接通过学习获得,而是需要手工设置。而网络中每一层feature使用的prior box大小和形状恰好都不一样,导致调试过程非常依赖经验。
虽然使用了pyramdial feature hierarchy的思路,但是对于小目标的recall依然一般,这是由于SSD使用conv4_3低级feature去检测小目标,而低级特征卷积层数少,存在特征提取不充分的问题。