商简智能学术成果|基于深度强化学习的联想电脑制造调度(Lenovo Schedules Laptop Manufacturing Using Deep Reinforcement Learning)

获取更多资讯,赶快关注上面的公众号吧!
文章目录
-
- 摘要
- 背景介绍
- 传统方法无法解决现有挑战
- 解决方案
- 提升模型表达能力
- 针对复杂约束的掩码机制
- 快速模型训练
- 配置多目标调度优化
- 结论
本篇论文作为商简智能的最新研究成果,发表于运筹学顶刊《INFORMS JOURNAL ON APPLIED ANALYTICS》,首次将深度强化学习落地于大规模制造调度场景,该先进排程项目入围国际运筹学权威机构INFORMS运筹学应用最高奖——Franz Edelman Award,并作为制造业企业技术转型典型案例被人民日报等多家媒体广泛报道。

第一作者梁翼,商简智能CEO兼CTO,人工智能、运筹优化算法专家,取得浙大竺可桢学院物理学学士、McMaster理论物理硕士、University of Alberta高能物理学博士,为中国科学院大学博士后。在高能物理、人工智能等领域发表论文十余篇,平均引用率>15。曾任联想研究院AI lab首席算法研究员,专注于人工智能在制造业的应用。

摘要
联想研究院与联想最大电脑制造工厂联宝科技LCFC的运营组成员合作,采用基于深度强化学习架构的决策支持平台替代传统的手动生产调度。该系统可以调度工厂内所有43条装配制造线的生产订单,均衡产量、换型成本和订单交付率的相对优先级,利用深度强化学习模型求解多目标调度问题。该方法将高计算效率与一种新的掩码机制相结合以保证运行约束,从而避免机器学习模型将时间浪费在探索不可行解。通过使用该新模型,改变了原有的生产管理流程,使得生产订单积压减少了20%,交付率提升了23%。还将整个调度过程从6小时缩短到30分钟,与此同时保留了多目标的灵活性,使工厂能够快速调整以适应不断变化的目标。该项研究工作在2019年和202年分别为工厂提升了19.1亿美元和26.9亿美元的收入。
背景介绍
联想合肥工厂LCFC是联想最大的电脑制造厂,其有4个制造工厂和43条装配生产线,平均每天大约接收5000个电脑订单,占据联想电脑生产的一多半和至少全球电脑的八分之一。这些电脑包含20多个产品系列和550个产品型号。在生产之前,这些订单会被分解成生产工单(MO),一个订单可包含数千台电脑,每个工单中的电脑具有相同的型号和相近的承诺发货日期。
电脑生产过程大致可以分为三个阶段:
- 第一阶段:主板的生产由表面装配技术车间负责。这一阶段,生产以自动执行为主,稳定性高,不需要人为干预;
- 组件车间完成生产的第二阶段,工人们将笔记本电脑的外壳与显示器和键盘连接起来;
- 第三阶段即装配阶段,组装笔记本电脑的内部部件。这一阶段最耗时和最不稳定,需要大量的人工干预,因此该阶段的效率通常是整个制造过程的瓶颈。
第三阶段,根据工单将半成品和备件分配到43条产线,在这些产线上,工人依次处理每个工单,即当前工单完成装配后下一工单才能开始。特定电脑型号的组装效率可能因分配的生产线的不同而有所不同。每小时的产出(Unit-per-hour,UPH)矩阵表达了产品与产线的对应效率。UPH很容易受员工出勤率波动、生产线的机器状态以及工具和材料的可用性影响而变化。每个工单对应一个工件,如图1所示,工单4从产线B移动到产线A,因为UPH变大,所以生产时间变短。而且,工单在每条产线上的排序会严重影响总生产时间。
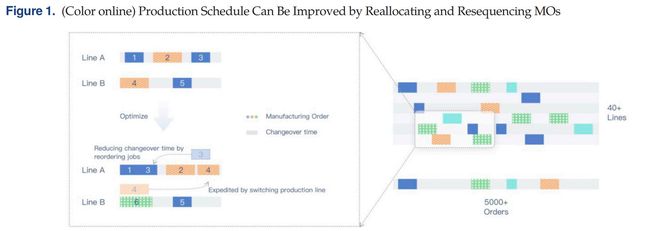
当产线切换生产不同的型号时,会导致换型成本,通过合理的工单分派可以提升调度性能。考虑到生产线的数量和调度订单量,优化问题在计算上很难解决。因此第三阶段的装配段管理是所有联想工厂生产管理的重点和最具挑战性的部分。
传统方法无法解决现有挑战
在联想,基于人类经验和判断的生产调度需要数小时的工作时间。由于生产资源供应的波动性,当今现代制造业企业面临着巨大的压力。因此,联想需要一个具有以下特点的生产管理系统:
- 能够解决大规模调度问题。对于联想这样生产越来越复杂的企业来说,一个工厂必须能够每天处理多达数万个订单;
- 快速反应能力。供应端的波动性要求生产调度系统快速响应组件供应的变化。联想之前的调度流程,是基于计划人员的经验和判断,无法及时、充分地应对供应端的变化;
- 更优的KPI绩效。可以同时优化总产量、订单交付率、换型成本等;
- 多标准优化目标的灵活配置能力。从机械工作中解放出来后,计划人员有更多的时间进行战略工作。他们可以通过与系统交互,积极参与决策过程;例如,他们可以配置KPI阈值和设置优化目标的相对优先级(权重)。这对于建立规划人员对系统的信任至关重要,通过该工作流程提高他们的工作满意度,并提高调度过程的效率。
传统方法很难满足这样的需求。传统方法分为精确方法和近似方法。精确方法如分支定界和割平面法,追求全局最优解,仅限于解决小规模问题。为了解决大规模问题,传统的解决方案开发人员通过基于规则或启发式的方法来寻求近似最优解。但是,有些近似方法如禁忌搜索/路径重链接在中小规模问题集上表现良好,但在解决大规模问题时往往太慢,无法满足快速响应时间的需求。其他可以在合理时间内解决大型和小规模问题的近似方法通常在KPI优化方面表现不佳。在处理多目标优化问题时,响应速度和解决方案质量之间的冲突比使用传统方法时更加明显。综上所述,传统方法的这些缺陷给联想供应链管理带来了相当大的挑战。
解决方案
为了应对这些挑战,将**生产线计划问题(production line planning problem,PLPP)**问题建模为马尔科夫决策过程(MDP)。
假设一个工厂具有 K K K条产线和 N N N个工单,该生产调度问题对应的MDP可以表示为 { X t , A , P , R } \left\{\mathbf{X}_{\mathbf{t}}, \mathbf{A}, \mathbf{P}, \mathbf{R}\right\} {Xt,A,P,R}。
其中:
X t \mathbf{X}_{\mathbf{t}} Xt:每个事件 t t t的状态集合,由一系列向量构成 X t = { x t i } \boldsymbol{X}_t=\left\{\boldsymbol{x}_t^i\right\} Xt={xti}, x t i \boldsymbol{x}_t^i xti是一组描述输入 i i i状态的特征。在PLPP中, x t i \boldsymbol{x}_t^i xti表示工单 i i i系列、型号、数量、UPH和每条产线剩余能力的快照。
A \mathbf{A} A:动作集合。可以直接将 A \mathbf{A} A等同于MDP中的策略函数 P ( y ∣ x ) P(\boldsymbol{y} \mid \boldsymbol{x}) P(y∣x),其中 x \boldsymbol{x} x和 y \boldsymbol{y} y分别表示编码器和解码器状态。 P ( . ∣ . ) P(. \mid .) P(.∣.)是条件概率。根据链式法则,给定初始状态 x 0 \boldsymbol{x_0} x0,基于序列决策模型获得完整解的过程如下:
P ( y ∣ x 0 ) = ∏ t = 0 N P ( y t + 1 ∣ y t , x t ) P\left(\boldsymbol{y} \mid \boldsymbol{x}_0\right)=\prod_{t=0}^N P\left(\boldsymbol{y}_{t+1} \mid \boldsymbol{y}_{t}, \boldsymbol{x}_t\right) P(y∣x0)=t=0∏NP(yt+1∣yt,xt)
P \mathbf{P} P:状态转移概率函数。对于该问题,状态转移 P ( y ∣ x ) P(\boldsymbol{y} \mid \boldsymbol{x}) P(y∣x)是确定的,因此不存在随机状态转移。
R \mathbf{R} R:奖励函数集合。 r ( y ) ∈ R r(\boldsymbol{y}) \in \mathbf{R} r(y)∈R是系统转移到状态 y \boldsymbol{y} y的奖励函数值。对于多目标优化问题, r ( y ) r(\boldsymbol{y}) r(y)可以定义为一个包含多个生产指标加权值的向量。
在MDP表达中,一个解就是分配给每条生产线的工单序列。通过使用机器学习模型来获得问题的近似最优解决方案,该模型通过强化学习(RL)框架来学习提升生成所需序列的概率。
生产调度任务可以看成是学习如何排列订单顺序,即给定一个初始顺序,输出一个新的排序结果,因此可以考虑序列到序列模型(sequence-to-sequence,S2S)。
众所周知,典型的S2S模型包括编码器和解码器,编码器学习如何将输入序列编码为固定大小的向量,并将其发送给解码器,解码器学习将该向量转换回输出序列。在我们的问题中,编码器的输入为工单的初始序列,解码器生成优化的工单序列。输出序列为工单索引和分隔标志的排列,从最开始位置到第一个标志的索引标识对应工单分配到产线1,第一个标志和第二个标志之间的索引表示对应工单分派到第二条产线,以此类推,如下图所示。
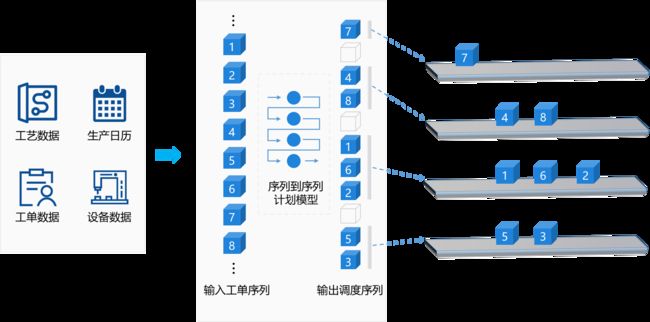
编码器网络迭代地将输入序列转换为高维张量。解码器网络通过注意机制生成选择每个MO的概率分布。
一旦训练良好,模型保持其学习参数并快速生成优化序列。与传统的OR方法相比,这提供了计算时间优势。在我们的模型中,运行时间不会随着问题规模的增加而呈指数增长,这使得能够在相对较小的问题上训练模型,并将其应用于更大的问题。
模型的输入包括订单相关和工厂相关信息,订单相关信息包括所需要的产品数量、产品系列和计划中的每个订单的产品ID。工厂相关方面的信息包括生产线的数量、每条生产线上每种型号的生产效率、每对生产型号之间的转换成本以及制造规则。
订单信息和相应的生产信息,包括机器可用性状态(例如,机器是否可用于生产、正在维护或修理)、UPH和生产日历,被组合到系统中的MO单元中。
将以上模型称之为编码器增强指针网络(EEPN)。通过强化学习来训练这个模型,通过重新排序输入MO序列和插入标记(白色立方体)来指示两条相邻生产线的位置,从而优化计划。
提升模型表达能力
用于优化生产调度的许多关键过程(例如,转换成本计算,生产线选择)对于使用先前的深度强化学习方法的模型来说是很难学习的。这些操作是高度非线性的。因此,简单的网络结构不能很好地建模。通过将传统的编码器升级为两层非线性卷积神经网络。随着信息抽象能力的提高,EEPN利用捕获的问题结构,在训练后立即获得高质量的生产调度解。
针对复杂约束的掩码机制
考虑到LCFC生产调度的规模,在如此大规模和复杂的生产系统中生成良好的生产计划具有挑战性。同时,调度必须遵循复杂的规则作为约束。下面我们列出了四个最重要的约束条件:
- 生产时间:每个订单的生产时间不能超过其预定义的时间窗口,即所有班次的最早开始时间与可用时间的交集。每个轮班都有一个配置的总时间,其中包括工人的休息时间和轮班交接时间;
- 生产数量:当一个产品型号需要特殊设备时,其在规定时间内的总生产数量可能会受到限制(例如每两小时最多200台)。一旦达到限制,该型号将停止生产,直到指定的持续时间结束,这有助于质量控制;
- 可分配的生产线:每个订单只能分配给具有处理对应型号能力和产能的生产线。此外,由于夹具数量的限制(即在生产过程中专门用于约束PC的设备),一些型号在给定的班次中只能在固定数量的生产线上生产。
- 关联:一些订单被标记为关联,表明这些订单必须在指定的时间范围内在同一工厂完成。
这些约束关联到订单、生产线、时间和数量,约束个数可能超过 1 0 6 10^6 106。
在EEPN中,通过引入一种新的掩码机制来解决这些约束。掩码机制的核心技术是可控掩码张量(即多维矩阵)。掩码张量中的每个元素都可以被看作是一个门,用来控制一个订单在特定产线特定位置的放置是否可行。在模型处理一个订单的每个优化时间步骤中,如果在生产线上放置订单没有违反任何约束,闸门将被打开;否则门处于关闭状态。
因此,EEPN只选择打开门的订单,并按照时间步将其中一些订单放在生产线上。
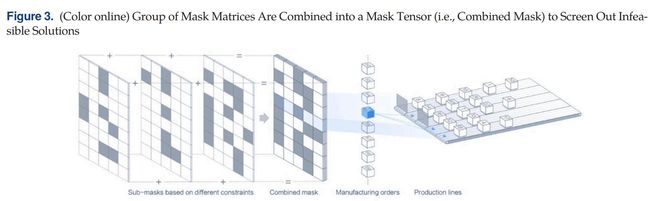
如上图所示,组合掩码由逻辑加法组合的几个子掩码组成,每个子掩码表示一个约束。掩蔽机制在生成解的过程中同时考虑多个约束,排除不可行解,这大大减少了模型训练的计算时间。
快速模型训练
在算法测试阶段,评估了有掩码机制和没有掩码机制以及包括各种问题大小的AI基准测试调度对运行时间的影响。
结果表明,与未使用此机制的测试相比,使用掩码机制的测试的运行时间略有增加。随着问题规模的增加,两种测试的运行时间增长率大致相同,导致较大问题的运行时间呈线性增加。尽管掩码机制在优化求解中会导致计算时间的增加,但它通过有效的约束强制显著减少了训练时间。此外,对于较大的问题,掩码机制不会导致模型运行时间的显著增加。
配置多目标调度优化
在每次调度运行中,EEPN应该在不同的目标优先级下同时生成一组解,当给定一组目标优先级时,决策者应该能够灵活地配置每个目标的偏好权重,并直观地选择所需的最优解。
因此,一种想法是更新EEPN,使其能够在多目标场景中学习不同优先级集的最优调度策略。
可以通过使用各种目标偏好权重作为机器学习模型的额外输入数据来做到这一点。
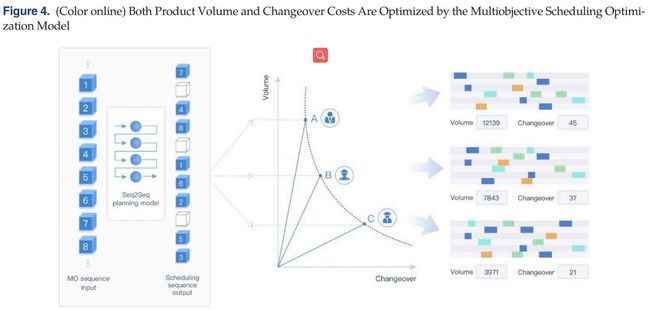
根据之前的研究,该目标需要设计多个EEPN实例,每个实例负责在特定的目标函数优先级集合下完成优化。然而,这种方法非常耗时,需要大量的计算资源。
相反,联想的研究团队决定使用单个EEPN来实现这一目标。EEPN的多目标版本以目标函数准则优先级(即偏好权重)作为输入。因此,EEPN在时变环境下不断学习目标优先级和调度数据的各种组合。
使用相同的调度数据,如果配置的目标优先级不同,EEPN可以在每种情况下快速生成最优调度结果。利用这种基于学习的方法,该算法成功地解决了多目标优化问题。
结论
综上所述,联想开发并经LCFC测试,通过OR和AI进行智能调度的EEPN框架,已被证明可以提高效率,增加收入,节省人力资本,保护环境。这种解决方案具有巨大的潜力,可以继续解决企业和社会面临的一些最复杂的问题。
该套解决方案不仅在联宝工厂落地,还在深圳和惠阳工厂等其他联想内部工厂的生产场景下进行了迁移和测试,POC阶段的结果表明,两家工厂的KPI都有了实质性的改善。除了PC行业以外,该解决方案同样适用于手机行业、半导体行业、离散机加工行业,尽管从OR的角度来看,这些行业的生产调度问题可能与联宝工厂的PLPP不同,因为每个工厂都有自己的一套生产流程和KPI偏好,但其可以通过修改掩码机制和设置目标函数来轻松适配这些差异。