协同过滤推荐算法-基于物品的协同过滤ItemCF及python实现
-
基于物品(项目)的协同过滤推荐(item-based CF)
- ItemCF的基本思想:是预先根据所有用户的历史偏好数据计算物品之间的相似性,然后把与用户喜欢的物品相类似的物品推荐给用户。
- 比如物品a和c非常相似,因为喜欢a的用户同时也喜欢c,而用户A喜欢a,所以把c推荐给用户A。ItemCF算法并不利用物品的内容属性计算物品之间的相似度, 主要通过分析用户的行为记录计算物品之间的相似度, 该算法认为, 物品a和物品c具有很大的相似度是因为喜欢物品a的用户大都喜欢物品c。
基于项目的协同过滤算法基于这样的假设:一个用户会喜欢与他之前喜欢的项目相似的项 目。因此,基于项目的协同过滤推荐关键在于计算物品之间的相似度。Item-based CF 认为两个项目被 越多的用户同时喜欢,两个项目就越相似。
- ItemCF算法主要包括两个步骤:
1. 计算物品之间的相似度
2.根据物品的相似度和用户的历史行为给用户生成推荐列表(购买了该商品的用户也经常购买的其他商品)


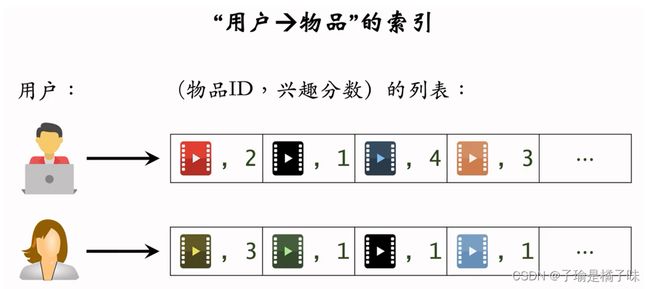
1.建立“用户→物品”的索引
- 记录每个用户最近点击、交互过的物品ID。
- 给定任意用户ID,可以找到他近期感兴趣的物品列表
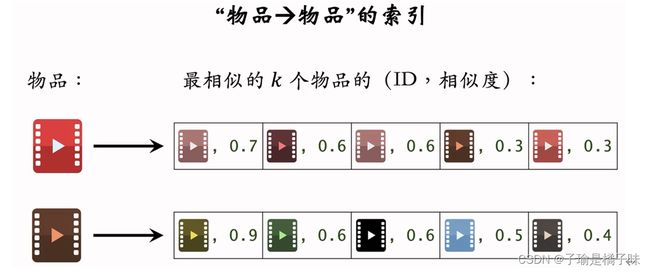
2.建立“物品→物品”的索引
- 计算物品之间两两相似度。
- 对于每个物品﹐索引它最相似的k个物品О
- 给定任意物品ID,可以快速找到它最相似的k 个物品
ItemCF的python实现过程为:

# 基于物品的协同过滤算法
import random
import math
from operator import itemgetter
def ReadData(file, data):
''' 读取评分数据
@param file 评分数据文件
@param data 储存评分数据的List
'''
for line in file:
line = line.strip('\n')
linelist = line.split("::")
data.append([linelist[0], linelist[1]])
def SplitData(data, M, key, seed):
''' 将数据分为训练集和测试集
@param data 储存训练和测试数据的List
@param M 将数据分为M份
@param key 选取第key份数据做为测试数据
@param seed 随机种子
@return train 训练数据集Dict
@return test 测试数据集Dict
'''
test = dict()
train = dict()
random.seed(seed)
for user, item in data:
if random.randint(0, M) == key:
if user in test:
test[user].append(item)
else:
test[user] = []
else:
if user in train:
train[user].append(item)
else:
train[user] = []
return train, test
def UserSimilarityOld(train):
W = dict()
for u in train.keys():
W[u] = dict()
for v in train.keys():
if u == v:
continue
W[u][v] = len(list(set(train[u]) & set(train[v])))
W[u][v] /= math.sqrt(len(train[u]) * len(train[v]) * 1.0)
return W
def ItemSimilarity(train):
''' 计算物品相似度
@param train 训练数据集Dict
@return W 记录用户相似度的二维矩阵
'''
C = dict()
N = dict()
# 计算没两个item共有的user数目
for u, items in train.items():
for i in items:
if i not in N:
N[i] = 0
N[i] += 1
for j in items:
if i == j:
continue
if i not in C:
C[i] = dict()
if j not in C[i]:
C[i][j] = 0
C[i][j] += 1
W = dict()
for i, related_items in C.items():
for j, cij in related_items.items():
if i not in W:
W[i] = dict()
W[i][j] = cij / math.sqrt(N[i] * N[j])
return W
def Coverage(train, test, W, N, K):
''' 获取推荐结果
@param user 输入的用户
@param train 训练数据集Dict
@param W 记录用户相似度的二维矩阵
@param N 推荐结果的数目
@param K 选取近邻的数目
'''
recommned_items = set()
all_items = set()
for user in train.keys():
for item in train[user]:
all_items.add(item)
rank = GetRecommendation(user, train, W, N, K)
for item, pui in rank:
recommned_items.add(item)
print('len: ', len(recommned_items), '\n')
return len(recommned_items) / (len(all_items) * 1.0)
def GetRecommendation(user, train, W, N, K):
''' 获取推荐结果
@param user 输入的用户
@param train 训练数据集Dict
@param W 记录用户相似度的二维矩阵
@param N 推荐结果的数目
@param K 选取近邻的数目
'''
rank = dict()
ru = train[user]
for i in ru:
for j, wj in sorted(W[i].items(), key=itemgetter(1), \
reverse=True)[0:K]:
if j in ru:
continue
if j in rank:
rank[j] += wj
else:
rank[j] = 0
rank = sorted(rank.items(), key=itemgetter(1), reverse=True)[0:N]
return rank
def Recall(train, test, W, N, K):
''' 计算推荐结果的召回率
@param train 训练数据集Dict
@param test 测试数据集Dict
@param W 记录用户相似度的二维矩阵
@param N 推荐结果的数目
@param K 选取近邻的数目
'''
hit = 0
all = 0
for user in train.keys():
if user in test:
tu = test[user]
rank = GetRecommendation(user, train, W, N, K)
for item, pui in rank:
if item in tu:
hit += 1
all += len(tu)
print(hit)
print(all)
return hit / (all * 1.0)
def Precision(train, test, W, N, K):
''' 计算推荐结果的准确率
@param train 训练数据集Dict
@param test 测试数据集Dict
@param W 记录用户相似度的二维矩阵
@param N 推荐结果的数目
@param K 选取近邻的数目
'''
hit = 0
all = 0
for user in train.keys():
if user in test:
tu = test[user]
rank = GetRecommendation(user, train, W, N, K)
for item, pui in rank:
if item in tu:
hit += 1
all += N
print(hit)
print(all)
return hit / (all * 1.0)
def Popularity(train, test, W, N, K):
''' 计算推荐结果的流行度
@param train 训练数据集Dict
@param test 测试数据集Dict
@param W 记录用户相似度的二维矩阵
@param N 推荐结果的数目
@param K 选取近邻的数目
'''
item_popularity = dict()
for user, items in train.items():
for item in items:
if item not in item_popularity:
item_popularity[item] = 0
item_popularity[item] += 1
ret = 0
n = 0
for user in train.keys():
rank = GetRecommendation(user, train, W, N, K)
for item, pui in rank:
ret += math.log(1 + item_popularity[item])
n += 1
ret /= n * 1.0
return ret
if __name__ == '__main__':
data = []
M = 7
key = 1
seed = 1
N = 10
K = 10
W = dict()
rank = dict()
print("this is the main function")
file = open('../ml-1m/ratings.dat')
ReadData(file, data)
train, test = SplitData(data, M, key, seed)
W = ItemSimilarity(train)
recall = Recall(train, test, W, N, K)
precision = Precision(train, test, W, N, K)
popularity = Popularity(train, test, W, N, K)
coverage = Coverage(train, test, W, N, K)
print('recall: ', recall, '\n')
print('precision: ', precision, '\n')
print('Popularity: ', popularity, '\n')
print('coverage: ', coverage, '\n')
else:
print("this is not the main function")