附代码 DenseNet---Densely Connected Convolutional Networks
Densely Connected Convolutional Networks 论文解读
代码链接:https://github.com/bamos/densenet.pytorch
论文链接:https://arxiv.org/abs/1608.06993
摘要:
最近的研究表明,如果卷积网络包含靠近输入的层和接近输出的层之间的较短的连接,那么它们就可以更深入、更准确、更高效地进行训练。在本文中,我们接受了这一观察结果,并引入了密集卷积网络(DenseNet),它以前馈的方式将每一层连接到其他每一层。传统的L层卷积网络有L个连接,每一层和后续层之间有一个,我们的网络有L*(L+1)/2直接连接
优点:
DenseNets有几个令人信服的优点:它们缓解了消失梯度问题,增强了特征的传播,鼓励了特征的重用,并大大减少了参数的数量,密集的连接具有正则化效应,这减少了对训练集规模较小的任务的过拟合。
Dense block:
通过连接的方法,将每一层的输入都设置为前几层的输出,即第L层的输入,是前L-1层的输出,在Dense block中,每次卷积的顺序为:BN->ReLU->Conv,也可以换成瓶颈结构,即(BN->ReLU->1x1Conv->BN->ReLU->3x3Conv)。在卷积过程中,不存在下采样的功能,尺寸都相同,同时每一层的输出通道数相同,以便于可以直接进行连接,而不需要crop。结构如下图。
ResNet增加了旁路连接,可以写作,Hl为非线性函数,即BN->ReLU->Conv
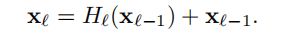
第L层的输入是前L-1层的输出:


DenseNets
网络结构如下:

其中,卷积操作顺序为:BN->ReLU->Conv。
在Dense block中,图像并没有下采样操作,然而,卷积网络的一个重要组成部分是可以改变特征映射大小的降采样层。为了便于在我们的架构中进行下采样,我们将网络划分为多个紧密连接的密集块;见图2。我们将块之间的层称为过渡层,它可以进行卷积和池化。(第一层卷积并没过渡层,为3*3卷积,用于扩展通道数和下采样)。在最后一个密集块的最后,执行一个全局平均池,然后附加一个softmax分类器。
我们实验中使用的过渡层:BN层和1×1卷积层,然后是2×2平均池化层
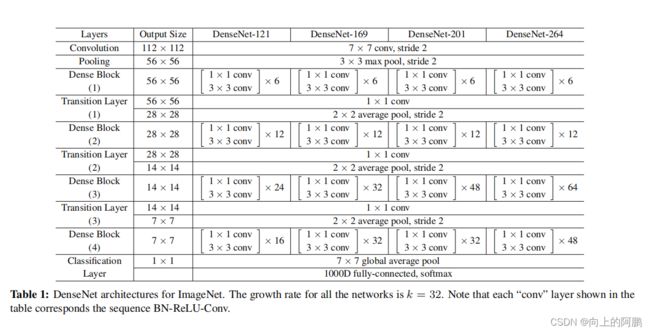
在Dense Net中,还需要设置超参数k,L。其中,k为增长率,为Dense block中每一层卷积的输出通道数。一般设置为12, k0 +k ×(l−1), L为网络深度。
具体参数:
压缩模型:
为了进一步提高模型的紧致性,我们可以减少过渡层上的特征映射的数量。如果一个密集的块包含m个特征映射,我们让下面的过渡层生成b个θ*m输出特征映射,其中0<θ≤1被称为压缩因子。当θ=1时,跨过渡层的特性映射的数量保持不变。我们将θ<1的DenseseNet-c,并在实验中设置了θ=0.5。当同时使用θ<1的瓶颈层和过渡层时,模型称为DenseNet-BC。
改变Dense block 为 Bottleneck:
虽然每个层只产生k个输出特性映射,但它通常有更多的输入。在每次3×3的卷积之前,可以引入一个1×1的卷积作为瓶颈层,以减少输入特征图的数量,从而提高计算效率。我们发现这种设计对DenseNet特别有效,我们将我们的具有这样一个瓶颈层的网络,即BN-ReLU-Conv(1×1)-BN-ReLU-Conv(3×3)版本,称为DenseNet-B。在我们的实验中,我们让每个1×1卷积产生4k个特征映射。
Result:

代码:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.autograd import Variable
import torchvision.datasets as dset
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import torchvision.models as models
import sys
import math
class Bottleneck(nn.Module):
def __init__(self, nChannels, growthRate):
super(Bottleneck, self).__init__()
interChannels = 4*growthRate
self.bn1 = nn.BatchNorm2d(nChannels)
self.conv1 = nn.Conv2d(nChannels, interChannels, kernel_size=1,
bias=False)
self.bn2 = nn.BatchNorm2d(interChannels)
self.conv2 = nn.Conv2d(interChannels, growthRate, kernel_size=3,
padding=1, bias=False)
def forward(self, x):
out = self.conv1(F.relu(self.bn1(x)))
out = self.conv2(F.relu(self.bn2(out)))
out = torch.cat((x, out), 1)
return out
class SingleLayer(nn.Module):
def __init__(self, nChannels, growthRate):
super(SingleLayer, self).__init__()
self.bn1 = nn.BatchNorm2d(nChannels)
self.conv1 = nn.Conv2d(nChannels, growthRate, kernel_size=3,
padding=1, bias=False)
def forward(self, x):
out = self.conv1(F.relu(self.bn1(x)))
out = torch.cat((x, out), 1)
return out
class Transition(nn.Module):
def __init__(self, nChannels, nOutChannels):
super(Transition, self).__init__()
self.bn1 = nn.BatchNorm2d(nChannels)
self.conv1 = nn.Conv2d(nChannels, nOutChannels, kernel_size=1,
bias=False)
def forward(self, x):
out = self.conv1(F.relu(self.bn1(x)))
out = F.avg_pool2d(out, 2)
return out
class DenseNet(nn.Module):
def __init__(self, growthRate, depth, reduction, nClasses, bottleneck):
super(DenseNet, self).__init__()
nDenseBlocks = (depth-4) // 3
if bottleneck:
nDenseBlocks //= 2
nChannels = 2*growthRate
self.conv1 = nn.Conv2d(3, nChannels, kernel_size=3, padding=1,
bias=False)
self.dense1 = self._make_dense(nChannels, growthRate, nDenseBlocks, bottleneck)
nChannels += nDenseBlocks*growthRate
nOutChannels = int(math.floor(nChannels*reduction))
self.trans1 = Transition(nChannels, nOutChannels)
nChannels = nOutChannels
self.dense2 = self._make_dense(nChannels, growthRate, nDenseBlocks, bottleneck)
nChannels += nDenseBlocks*growthRate
nOutChannels = int(math.floor(nChannels*reduction))
self.trans2 = Transition(nChannels, nOutChannels)
nChannels = nOutChannels
self.dense3 = self._make_dense(nChannels, growthRate, nDenseBlocks, bottleneck)
nChannels += nDenseBlocks*growthRate
self.bn1 = nn.BatchNorm2d(nChannels)
self.fc = nn.Linear(nChannels, nClasses)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
m.bias.data.zero_()
def _make_dense(self, nChannels, growthRate, nDenseBlocks, bottleneck):
layers = []
for i in range(int(nDenseBlocks)):
if bottleneck:
layers.append(Bottleneck(nChannels, growthRate))
else:
layers.append(SingleLayer(nChannels, growthRate))
nChannels += growthRate
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv1(x)
out = self.dense1(out)
out = self.trans1(out)
out = self.trans2(self.dense2(out))
out = self.dense3(out)
out = torch.squeeze(F.avg_pool2d(F.relu(self.bn1(out)), 8))
out = F.log_softmax(self.fc(out))
return out
if __name__ == '__main__':
input = torch.ones((1,3,224,224))
net = DenseNet(growthRate=12, depth=100, reduction=0.5,
bottleneck=True, nClasses=10)
out = net(input)