prometheus使用 (七) 运算操作符、聚合查询、子查询
一. 运算操作符
运算符这个东西大家也不陌生了吧,这里就不列举所有案例了(~﹃~)~zZ
#算数操作符
+ (加法)
- (减法)
* (乘法)
/ (除法)
% (求余)
^ (幂运算)
#对比操作符
== (等于)
!= (不等于)
> (大于)
< (小于)
>= (大于等于)
<= (小于等于)案例 幂运算
突然发现连幂是什么都忘了,全还给老师了(っ °Д °;)っ
#查看文件描述符
process_open_fds{instance="192.168.1.21:9100",job="node"}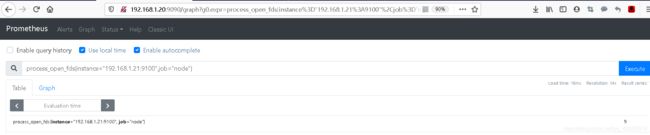
#简单来说,幂就是平方
#如下,我们将文件描述符 幂运算,相当于9*9*9=729
process_open_fds{instance="192.168.1.21:9100",job="node"} ^ 3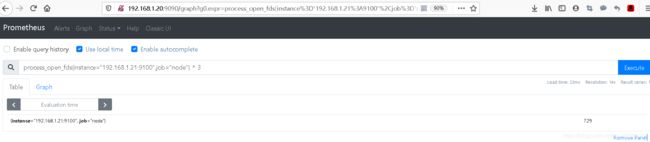
二. 聚合查询
聚合操作符,我们可以获取一个即时向量并聚合他的元素,从而得到一个新的瞬时向量
这个向量通常包含更少的元素,像这样的及时向量的每次聚合都以我们在垂直聚合中描述的方式工作
常用的聚合函数类型
sum #求和
min #最小值
max #最大值
avg #平均值
count #元素个数
count_values #等于某值的元素个数
bottomk #最小的 k 个元素
topk #最大的 k 个元素语法格式
#格式
<聚合函数>([parameter,] <指标查询语句>) [without|by (1.sum (求和)
# 查询系统所有http请求的总量
sum(http_request_total)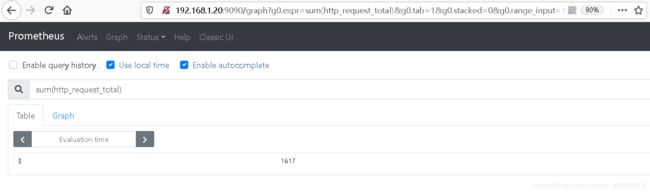
可以添加without或by 来筛选我们需要显示的标签
#可以移除或显示对应的标签
sum(http_request_total) without (instance)
#实际上等同于
sum(http_request_total) by (handler,job,method,statuscode)2. max (最大值)
#查看http请求最大值
max(http_request_total)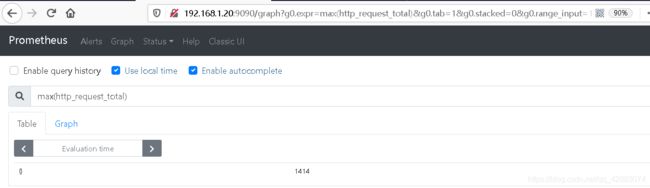
3. min (最小值)
#查看http请求最小值
min(http_request_total)
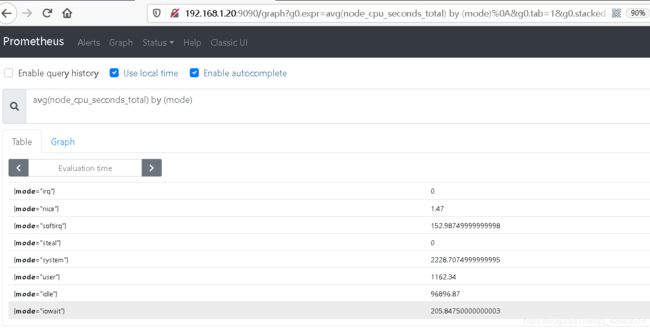
4. avg (平均值)
# 按照mode计算主机CPU的平均使⽤时间
avg(node_cpu_seconds_total) by (mode)
5. count (统计数量)
#请求http总量的个数
count(http_request_total)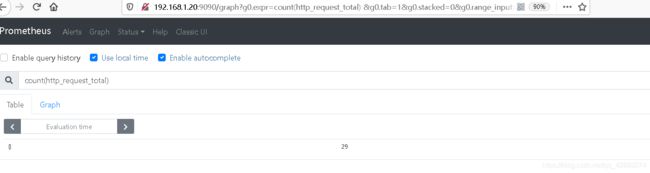
6. count_values (统计含义某个参数的值的数量)
#统计标签值中带有grafana的http请求
count_values("grafana", http_request_total)
#这个可以是标签的名称、也可以是标签的值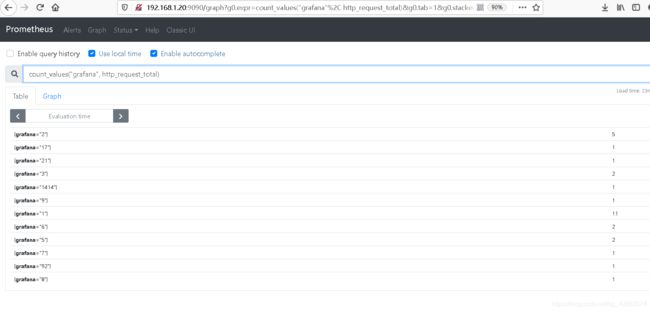
7. bottomk (统计最小的几个值)
#统计http请求总量中最小的5个值
bottomk(5,http_request_total)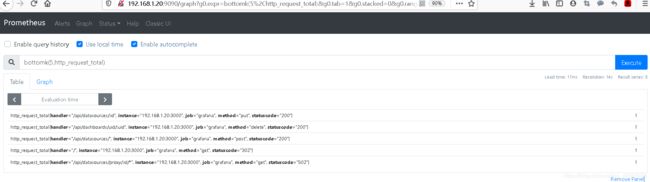
8. topk (统计最大的几个值)
#统计http请求总量中请求数量最大的5个值
topk(5,http_request_total)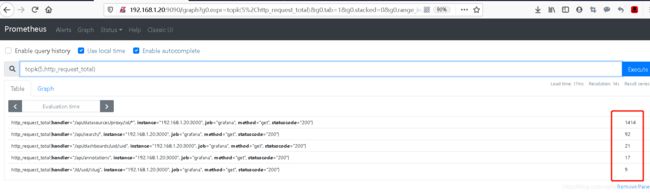
三. 子查询
avg_over_time() #指定间隔内所有点的平均值。
min_over_time() #指定间隔中所有点的最小值。
max_over_time() #指定间隔内所有点的最大值。
sum_over_time() #指定时间间隔内所有值的总和。案例1 avg_over_time
#查询一天空闲空间的平均值
avg_over_time(node_filesystem_files_free[1d])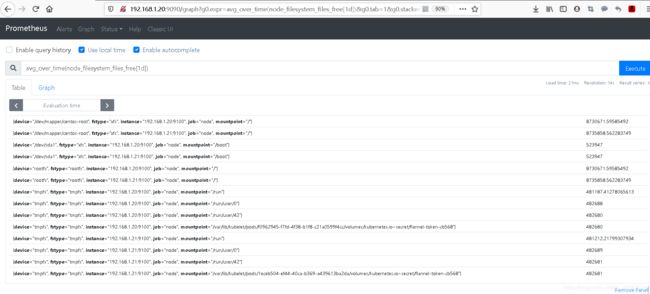
案例2 min_over_time
#一天 空闲空间的最大值
max_over_time(node_filesystem_files_free[1d])案例3 max_over_time
max_over_time(rate(http_request_total[5m])[1h:1m])
#总的来说就是统计prometheus上/metrics页面在5分钟内区间向量的平均值的点
#在1个小时中每个点的值
rate(http_request_total[5m])[1h:1m]
#它将五分钟的数据聚合成一个瞬时向量。
#[1h就像范围向量选择器一样,它定义了相对于查询求值时间的范围大小。
#:1m]要使用的间隔值。如果没有定义,它默认为全局计算区间。
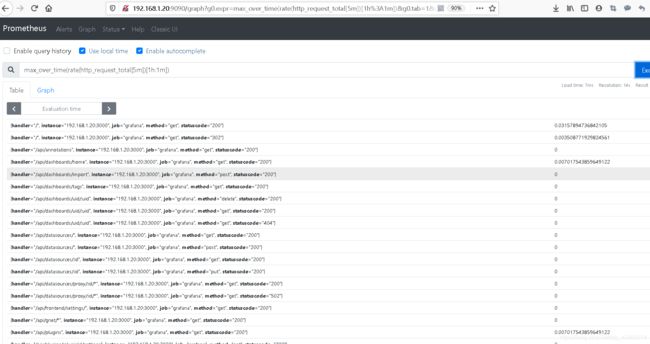
可能值全为0,是因为你的grafana太久没访问了,你打开刷一下
案例4 sum_over_time()
sum_over_time(rate(http_request_total[5m])[1h:1m])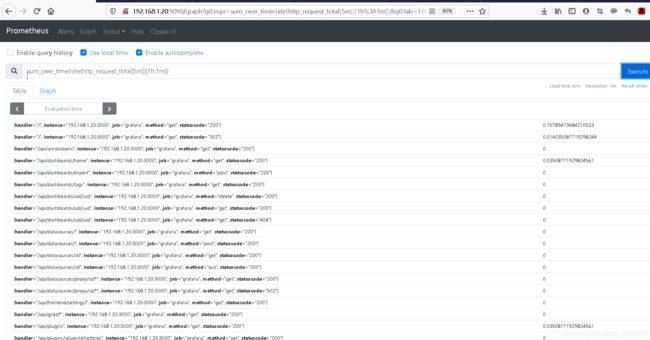
子查询通常会套用多层查询语句,消耗资源比较多。目前用的不算太多,看自己情况~( ̄▽ ̄)~
四. 逻辑运算(与、或、非)
and、or、unless 在座的都比我懂就不乱说了
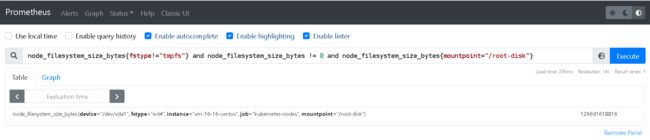
案例 and
#当多个条件被同时满足时进行显示,我这里相当于做个筛选
node_filesystem_size_bytes{fstype!="tmpfs"} and node_filesystem_size_bytes != 0 and node_filesystem_size_bytes{mountpoint="/root-disk"}
案例2 or
#当可用空间大于200000或者小于2500000都会显示
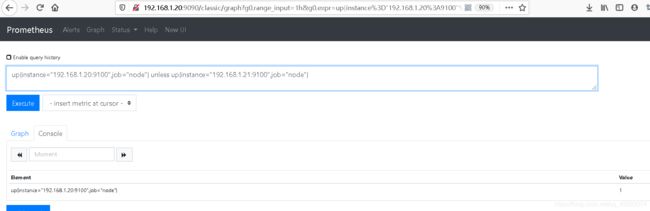
node_filesystem_avail_bytes > 200000 or node_filesystem_avail_bytes < 2500000案例3 unless
#当第一个值的标签和第二个值的标签不匹配的情况下会输出
up{instance="192.168.1.20:9100",job="node"} unless up{instance="192.168.1.21:9100",job="node"}
#当标签相同时则不输出
up{instance="192.168.1.20:9100",job="node"} unless up{instance="192.168.1.20:9100",job="node"}标签不同时输出值
标签相同时不输出值