数据可视化之Seaborn(3)
本篇文章主要补充上篇Seaborn(2)的绘制图表中没讲的内容。
关联图
- 线图 lineplot
- 分面网格关联图 relplot
分布图
- 直方图 distplot
- 密度图 kdeplot
矩阵图
- 连接图 jointplot
- 热力图 heatmap
回归图
- 线性回归图 regplot
- 分面网格线性回归图 lmplot
- 分面网格绘图 FacetGrid
一、关联图
1、线图——lineplot
参数解读:
hue:数据中变量名称(比如:二维数据中的列名)
作用:对将要生成不同颜色的线进行分组,可以是分类或数据。
size:数据中变量名称(比如:二维数据中的列名)
作用:对将要生成不同宽度的线进行分组,可以是分类或数据。
style:数据中变量名称(比如:二维数据中的列名)
作用:对将生成具有不同破折号、或其他标记的变量进行分组。
palette:调试板名称,列表或字典类型
作用:设置hue指定的变量的不同级别颜色。
hue_order:列表(list)类型
作用:指定hue变量出现的指定顺序,否则他们是根据数据确定的。
hue_norm:tuple或Normalize对象
sizes:list dict或tuple类型
作用:设置线宽度,当其为数字时,它也可以是一个元组,指定要使用的最大和最小值,会自动在该范围内对其他值进行规范化。
units:对变量识别抽样单位进行分组,使用时,将为每个单元绘制一个单独的行。
estimator:pandas方法的名称或回调函数或者None
作用:用于在同一x水平上聚合y变量的多个观察值的方法,如果为None,则将绘制所有观察结果。
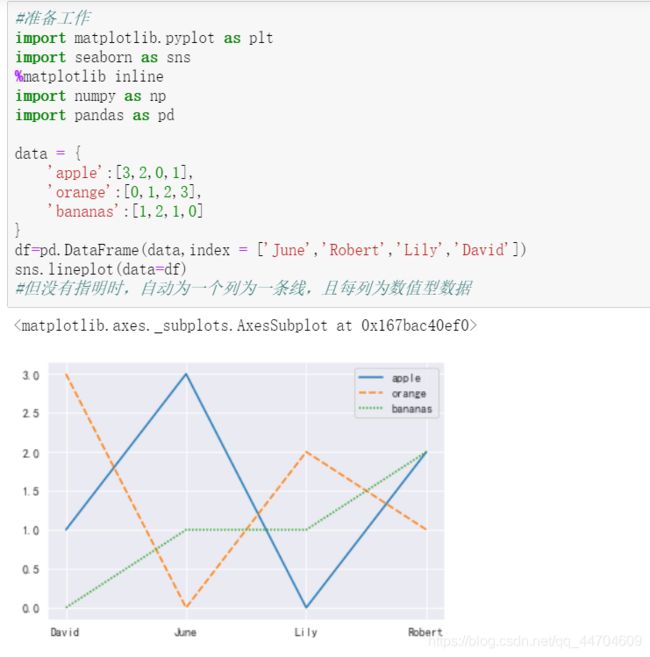 须注意的是,线图中传入的数据data必须全部是数值型数据。
须注意的是,线图中传入的数据data必须全部是数值型数据。
我们再用tips数据集介绍lineplot的基本参数。
首先先导入数据集:

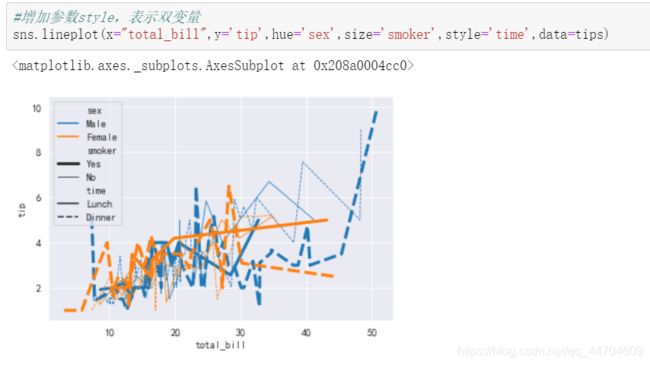
 加入了 hue 参数同时绘制多个类别图。这时候 seaborn 会把这个 hue的标签当做子标题。
加入了 hue 参数同时绘制多个类别图。这时候 seaborn 会把这个 hue的标签当做子标题。

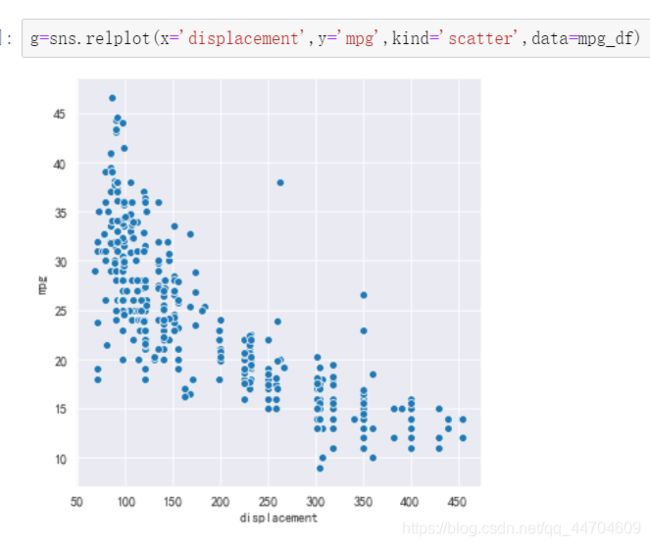
2、分面网格关联图 relplot
seaborn.relplot(x=None, y=None, hue=None, size=None, style=None, data=None, row=None, col=None, col_wrap=None, row_order=None, col_order=None, palette=None, hue_order=None, hue_norm=None, sizes=None, size_order=None, size_norm=None, markers=None, dashes=None, style_order=None, legend=‘brief’, kind=‘scatter’, height=5, aspect=1, facet_kws=None, **kwargs)
主要介绍这几个参数:x、y、data、col、col_wrap、row、kind
- kind: 取值为 line 或者 scatter, 默认值为scatter。
sns.replot(kind=“scatter”),相当于scatterplot() 用来绘制散点图
sns.replot(kind=“line”),相当于lineplot() 用来绘制曲线图
加载数据集:

 注:阴影部分是由于纵坐标上多个值导致的, 取值为均值, 阴影部分是置信区间.
注:阴影部分是由于纵坐标上多个值导致的, 取值为均值, 阴影部分是置信区间.
- ci (confidence interval)
ci参数来控制阴影部分, ci=None表示不要阴影。

- col: 列上的子图
- row: 行上的子图


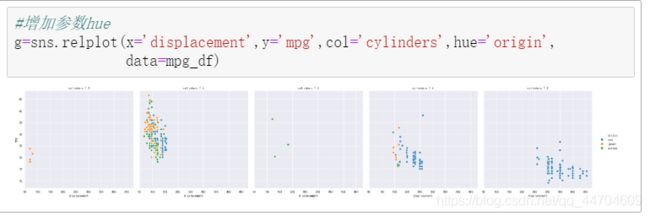
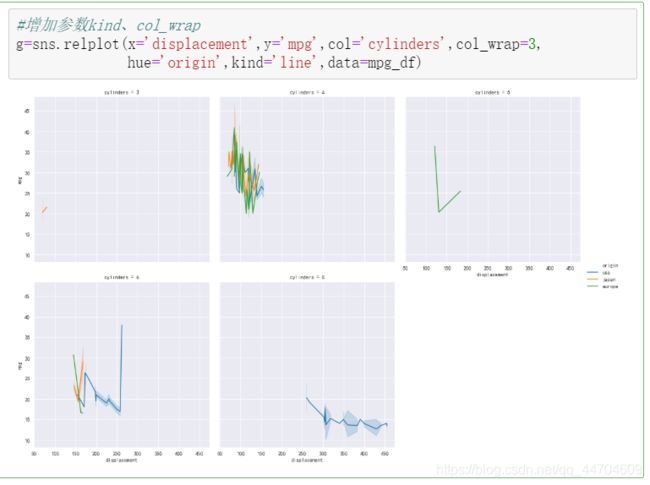
二、分布图
1.直方图——distplot

参数:
a:是单变量数据,可以是series、一维数组或列表。
bins:直方图中柱体的个数。
hist:是否绘制直方图。
kde:是否绘制密度图。
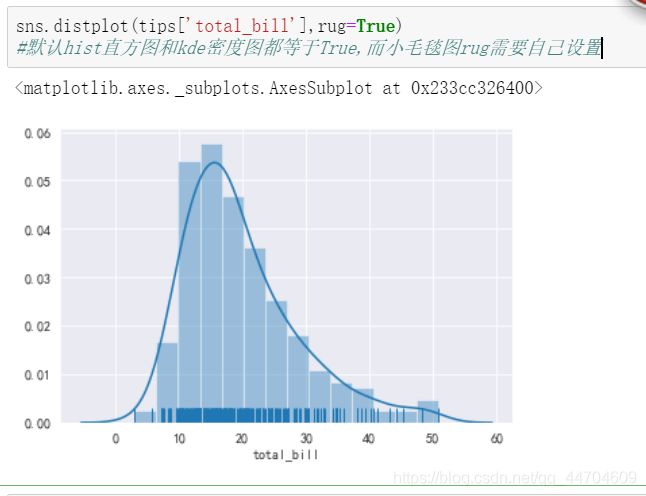
rug:是否绘制毛毯图。
默认hist=True ;kde=True 。

增加rug参数:
bins参数用于设置显示直方块的数量。

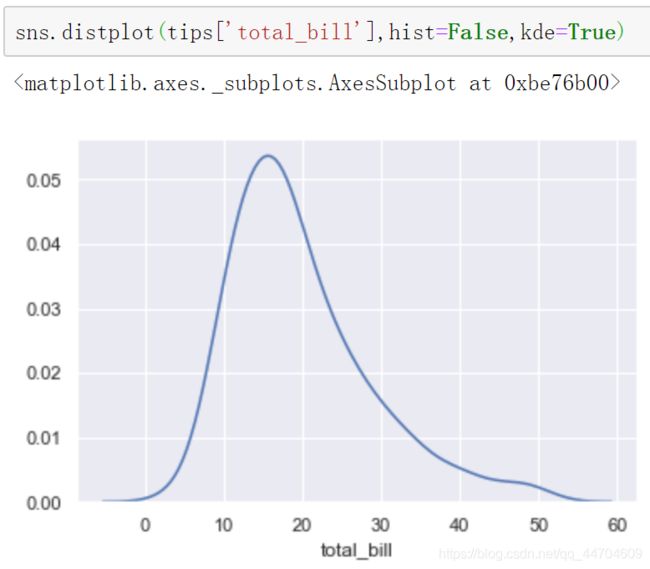 就等于密度图
就等于密度图
2.密度图——kdeplot


(1)单变量密度图:
bw(bandwidth)参数用于指定kde拟合的精度,类似于直方图中的bins的效果。
bw越小,曲线越精细。
 (2)双变量密度图:
(2)双变量密度图:


三、矩阵图
1.连接图——jointplot
 默认图
默认图
 添加线性回归线
添加线性回归线

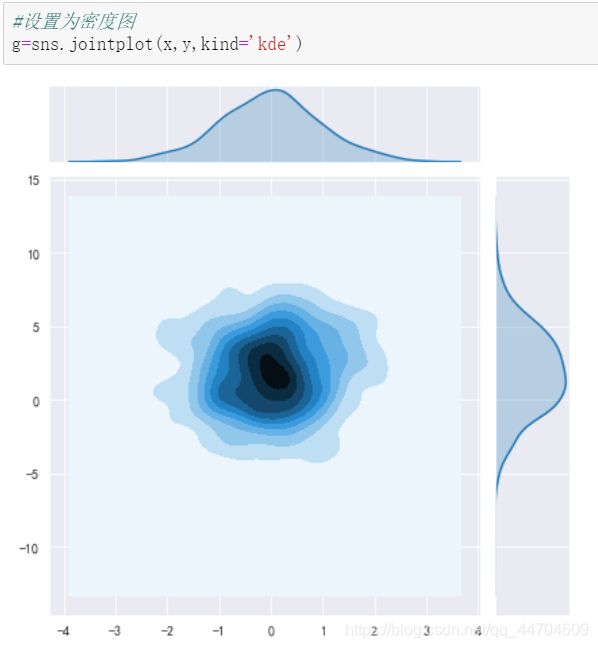
设置为密度图
 设置为六角形图
设置为六角形图

2.热力图——heatmap
以矩阵表示数据的方式,数据值在图中显示为颜色。
sns.heatmap(data,vmin=None,vmax=None,cmap=None,annot=None)
data:二维数据集
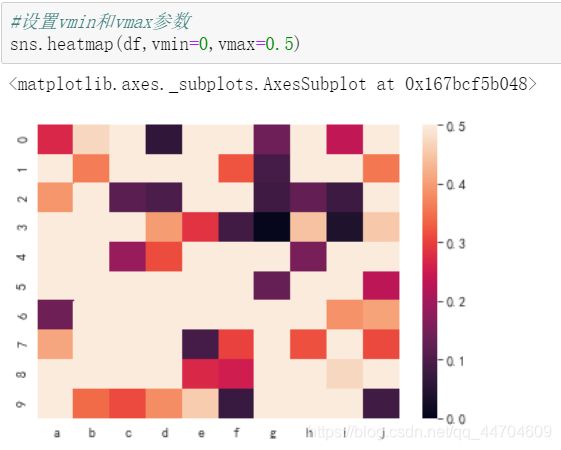
vmin和vmax:图例中最大值和最小值的显示值
cmap:设置颜色面板
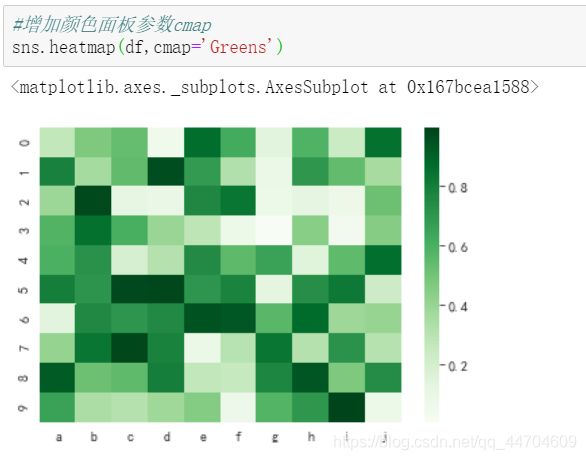
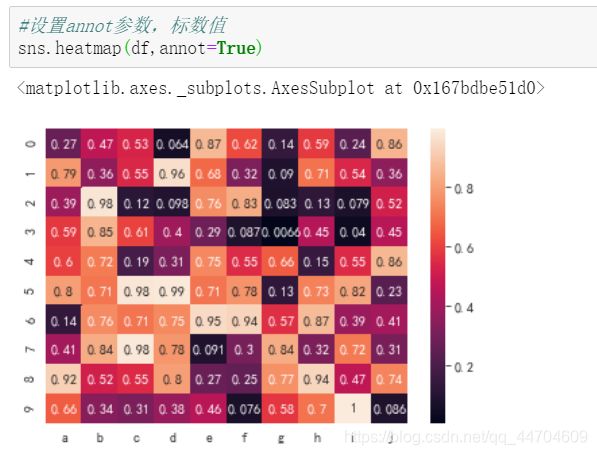
annot:设置热力图注解,True则在单元格中显示数据集 增加颜色面板参数cmap
增加颜色面板参数cmap
设置vmin和vmax参数
 设置annot参数,标数值
设置annot参数,标数值


四、回归图
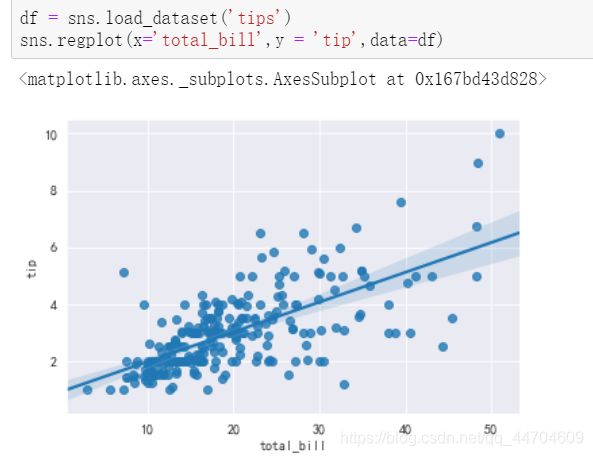
1.线性回归图——regplot
通过大量数据找到模型拟合的线性回归线。
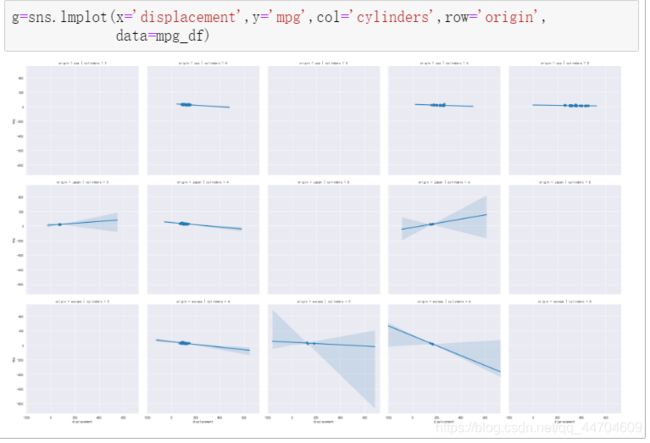
2.分面网格线性回归图——lmplot
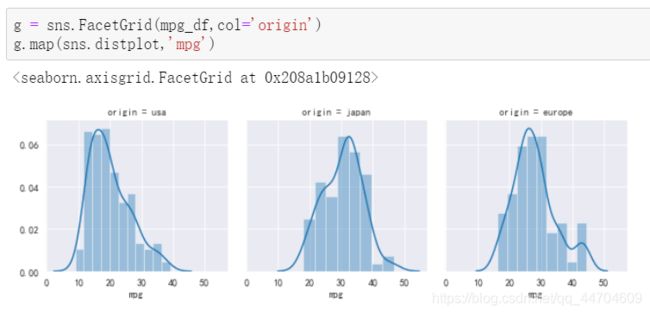
3.分面网格绘图 FacetGrid
通过sns.FacetGrid类 绘图分面网格,然后通过sns.FacetGrid.map方法 将一个绘图函数作用于一个网格,并绘制子图。
- sns.FacetGrid构造函数:
sns.FacetGrid(data,row=None,col=None,hue=True,col_wrap=None) - FaceGrid.map方法:
FacetGrid.map(func,*args,**kwargs)
绘制单变量分面网格