作者:vivo 互联网服务器团队- Xiong yangxin
将某个通用解决方案包装成成熟的工具包,是每一个技术建设工作者必须思考且必须解决的问题。本文从业内流行的既有工具包入手,解析实现思路,沉淀一般方法。为技术建设的初学者提供一些实践思路的参考。尤其是文中提倡的“去中心化”的协作模式,和“关键链路+开发接口”的开发模式,具有一定的实际落地意义。当然本文在行文中,不可避免存在一定主观偏见性,读者可酌情阅读。
一、前言
熟悉JAVA服务器开发的同学应该都使用过日志模块,并且大概率使用过"log4j-over-slf4j"和“slf4j-log4j”这两个包。那么这两个包的区别是什么?为什么会互相引用包含呢?这篇文章会解释下这几个概念的区别。
首先说一下SLF4J。
二、从SLF4J开始
SLF4J全称"Simple Logging Facade for Java (SLF4J) ", 它诞生之初的目的,是为了针对不同的log解决方案,提供一套统一的接口适配标准,从而让业务代码无须关心使用到的第三方模块都使用了哪些log方案。
举个例子, Apache Dubbo和RabbitMQ使用到的日志模块便不相同。从某种意义上而言,SLF4J只是一个facade,类似于当年的ODBC(针对不同的数据库厂商而制定的统一接口标准, 下文会涉及到)。而这个facade对应的包名,是 “slf4j-api-xxx.xxx.xxx.jar”。所以,当你应用了"slf4j-api-xxx.jar"的包时,其实只是引入了一个日志接口标准,而并没有引入日志具体实现。
2.1、业内实现
SLF4J标准在应用层的核心类,就是两个: org.slf4j.Logger 和 org.slf4j.LoggerFactory。其中,自版本1.6.0后,如果并没有具体的实现,slf4j-api会默认提供一个啥也不干的Logger实现(org.slf4j.helpers.NOPLogger)。
在当前(本稿件于2022-03-01拟制)的市面上,既有的实现SLF4J的方案有以下几种:

整体层次如下图:

综上而言:以SLF4J-开头的jar包,一般指的是采用某种第三方框架实现的slf4j解决方案。
2.2 工作机制
那么整个SLF4J的工作机制是如何运作的呢,换句话说,系统是如何知道应该使用哪个实现方案的呢?
对于那种不需要适配器的原生实现方式,直接引入对应的包即可。
对于那种需要适配器的委托式实现方式,则需要通过另外的一个渠道来告知SLF4J应该使用哪个实现类: SPI机制。
举个例子,我们看一下slf4j-log4j的包结构:

我们先看pom文件,就包含两个依赖:
org.slf4j
slf4j-api
log4j
log4j
slf4j-log4j同时引入了slf4j-api和log4j。那么slf4j-log4j本身的作用不言而喻:使用LOG4j的功能,实现SLF4J的接口标准。
整体的接口/类关系路径如下图:

但是这仍然没有解决本章节开始提出的问题(程序怎么知道应该用哪个Logger)。
可以从源码入手:(slf4j/slf4j-log4j12 at master · qos-ch/slf4j · GitHub),我们看到了以下关键的文件:

也就是说:slf4j-log4j使用了java的SPI机制告知JVM在运行时调用具体哪一个实现类。由于SPI机制暂不属于本文章讨论范围,读者可以去官网获取信息。
读者可以去GitHub - qos-ch/slf4j: Simple Logging Facade for Java看其他的实现方式的适配器是如何工作的。
那么本章开始的问题答案便是:
- SLF4J制定一套日志打印流程,然后把核心类抽象出接口给外部去实现;
- 适配器使用第三方日志组件实现了这些核心类接口,并采用SPI机制,让JAVA运行时意识到核心接口的具体实现类。
而上述两点,构成了本文接下来要讲述的知识点:委派模式。
三、委派模式
从上文中,我们从SLF4J的案例,引出了"委派模式"这个概念,下面我们就重点讨论委派模式(delegation)。
接下来我们按照认知流程,依次从三个问题,解释委派模式:
- 为什么使用委派模式
- 什么是委派模式
- 如何使用委派模式
然后会在下一章,用业内的典型案例,分析委派模式的使用情况。
3.1 为什么采用委派模式?
我们回到SLF4J。为什么它会用委派模式呢?因为日志打印功能存在各种不同的实现方式。对于应用开发者而言,最好需要一个标准的打印流程,其他第三方组件可以在某些地方有些不同,但是核心流程是最好不要变。对于标准制定者 而言,他无法控制每一个第三方组件的所有细节,所以只能暴露出有限的自定制能力。
而我们放大到软件领域,或者在互联网开发领域,不同的开发者的协作模式,主要靠jar包应用:第三方开发一个工具包,放在中心仓库中(maven, gradle), 使用者从其他信息渠道(csdn, stackoverflow等等)根据问题定位到这个jar包,然后在代码工程中引用。理论上,如果这个第三方jar包很稳定(例如c3p0),那么该jar包的维护者就很少甚至几乎不会和使用者建立联系。如果某些中间件开发者觉得不满足自己公司/部门的需求,会根据该jar包再做一次自定义封装。
纵观上述整个过程,不难发现两点:
- 工具包开发者和使用者没有建立稳定的协同渠道
- 工具包开发者对自己成品的发展掌控很薄弱
那么如果有人想要建立一套标准呢?比如log标准,比如数据库连接标准,那么只能有几个大公司联盟,或者著名的开发团队联盟,制定一个标准,并实现其中核心链路部分。至于为什么不实现全部链路,原因也很简单:软件领域的协同本身就是弱中心化的 ,否则你不带别人玩,别人也不会采用你的标准(参考当年IBM推广的COBOL)。
综上而言:委派模式是基于当前软件领域的协作特性,采取的较好的软件结构模式。

所以啥时候采用委派模式呢?
- 存在设定某个标准并由中心化团队负责的必要
- 使用者有强烈的需求自定制某些局部实现
这里就举一个硬件领域的反例:快充标准。在2018年甚至更早,消费者就需要一个快充的功能。但是快充需要定制很多硬件才能实现,所以此时就具备了条件一,但是当时并没有任何一个团队或者公司能够掌控安卓手机硬件整个生态,无法共同推出一个中心化团队去负责,从而导致各个手机厂商的快充功能百花齐放:A公司的快充线,无法给B公司的手机快充。
3.2 什么是委派模式?
基于上述的讨论,委派模式的核心构成就显而易见了:核心链路, 开放接口。
核心链路指的是:为了达到某个目的,特定的一组构件,按照特定的顺序,特定的协同标准,共同执行计算的逻辑。
开放接口指的是:给定特定的输入和输出,将实现细节交给外部的功能接口。
举个比较现实的例子:传统汽车。
几乎每一辆传统汽车,都按照三大件进行集成和协作:发动机,变速器,底盘。发动机做功, 通过变速器将动力传输给底盘(这么说并不标准,甚至在汽车工业的工人眼中,这种描述几乎是谬论,但是大致是这样)。也基于此,发动机的接口, 变速箱的接口,底盘的接口都已经固定,剩下的就各个厂商去实现了:三菱的发动机, 日产的发动机,爱信的变速箱,采埃孚的变速箱,伦福德的底盘,天合的底盘等等。甚至连轮胎的接口都制定好了:大陆的轮胎,普利司通的轮胎,固特异的轮胎。
不同的汽车厂商,选择不同公司的组件,集成出某个汽车型号。当然也有公司自己去实现某个标准:比如大众自己生产EA888发动机,PSA自己生产并调教的底盘并引以为傲。
如果大家觉得不够熟悉,那么可以举一个tomcat的例子。
经历过00年代的软件开发者,应该知道当时开发一个web应用是多么的困难:如何监听socket, 如何编码解码,如何处理并发,如何管理进程等等。但是有一点是共通的:每一个Web开发者都想要一个框架去管理整个http服务的协议层和内核层。于是出现了JBoss, WebSphere, Tomcat(笑到了最后)。
这些产品,都是指定了核心的链路:监听socket → 读数据包→ 封装成http报文 → 派发给处理池子 → 处理池的线程调用处理逻辑去处理 → 编码返回的报文 → 编组成tcp包 → 调用内核函数→ 发出数据。
基于这个核心链路,制定标准:业务处理逻辑的输入是什么,输出是什么,如何让web框架识别到业务处理模块。
Tomcat的方案就是web.xml。开发者只要遵从web.xml标准去实现servlet即可。也就是说,在整个http服务器链路中,Tomcat将特定的几个流程处理构件(listener, filter, interceptor, servlet)委派给了业务开发者去实现。
3.3 如何使用委派模式
在使用委派模式之前,先根据上文的模式匹配条件进行自我判断:
- 存在设定某个标准并由中心化团队负责的必要
- 使用者有强烈的需求自定制某些局部实现
如果并不符合条件一,那么就不需要考虑使用委派模式;如果符合条件一但是不符合条件二,那就先预留好接口,采用依赖注入的方式,自己开发接口实现类并注入到主流程中。这个做法在很多的第三方依赖包中能够看到,比如spring的BeanFactory, BeanAware等等,还有各个公司开发SSO时预留的一些hook和filter等等。
在确定使用委派模式后,第一件事就是“确定核心链路”,这一步最难,因为往往使用者都有某种期望,但是让他们具体描述出来,却又经常不够精准,甚至有时候后主次颠倒。笔者的建议是:直接让他们说出原始的需求/痛点,然后自己尝试给出方案,再对比他们的方案,进行沟通,并逐渐将两个方案统一。统一的过程也就是不断试探和确定的过程。

上述的过程是笔者自己的经验,仅当借鉴。
在确定核心流程后,再将流程中的一些需要自定制的功能抽象成接口暴露出去。接口的定义中,尽量减少对整个流程中其他类的调用依赖。
所以整体的流程分为三步:确认使用该模式;提取核心流程;抽象开放接口。
至于是采用SPI机制还是像TOMCAT一样使用XML配置识别,需要看具体情况,在此不做涉及。
四、 业内案例
4.1 JDBC
JDBC的诞生很大程度上是借鉴了ODBC的思想,为JAVA设计了专用的数据库连接规范JDBC(JAVA Database Connectivity)。JDBC期望的目标是让Java开发人员在编写数据库应用程序时,可以有统一的接口,无须依赖特定数据库API,达到“ 一次开发,适用所有数据库”。虽然实际开发中,经常会因为使用了数据库特定的语法、数据类型或函数等而无法达到目标,但JDBC的标准还是大大简化了开发工作。
整体而言,JDBC的接入结构大致如下图:

但是实际上,在JDBC诞生之初,市面上并未有很多的厂家响应SUN公司(那时候SUN还并未被ORACLE收购), 于是SUN公司就使用了本文介绍的桥接模式,如下图:

也是说,形式上,出现了初步委派的结构形式。
下文会只针对单次委托的JDBC层级做分析。
按照上文所言,每一个委派结构,必然存在两个要素:核心路径和开放接口。我们从这两个维度开始分析JDBC。
JDBC的核心路径分为六步, 包含委托机制需要的两步(引入包,声明委托承接人),总共八步,如下:
- 引入JDBC实现包
- 注册JDBC Driver
- 和数据库建立连接
- 发起transaction(必要的话),创建statement
- 执行statement并读取返回,塞入ResultSet
- 处理ResultSet
- 关闭ResultSet, 关闭Statement
- 关闭Connection
纵观整个过程,核心的参与者为:Driver, Connection, Statement, ResultSet。transaction实际上是基于Connection的三个方法(setAutoCommit, commit, rollback)包装而成的会话层,理论上不属于标准层。
以mysql-connector-java为例,具体实现JDBC接口的情况如下:

通过Java自带的overriding机制,只要使用com.mysql.jdbc.Driver,那么其他组件的实现类便直接被应用实现。具体细节不做讨论。那么mysql-connector-java是如何告知JVM应该使用com.mysql.jdbc.Driver呢?
两种模式
- 明文模式——在业务代码中明文使用Class.forName("com.mysql.jdbc.Driver")
- SPA机制
其实上述的两种方法,核心就是初始化com.mysql.jdbc.Driver,执行以下类初始化逻辑。
try {
DriverManager.registerDriver(new Driver());
} catch (SQLException var1) {
throw new RuntimeException("Can't register driver!");
}也就是说,JDBC通过DriveManager维护委托承接者的信息。读者如果有兴趣查看DriverManager的源码,会发现JDBC的另一种实现类发现方式。不过考虑行文长度,笔者在此不表。
4.2 Apach Dubbo
Dubbo的核心路径大致如下(不考虑服务管理那一套):
consumer调用 → 参数序列化 → 网络请求 → 接收请求 → 参数反序列化 → provider计算并返回 → 结果序列化 → 网络返回 → consumer方接收 → 结果反序列化
(斜体代表consumer方的dubbo职责,下划线代表provider方的dubbo职责)
Dubbo的可定制接口有很多,整体大量采用了“类SPI”机制,为整个RPC流程的很多环节,提供了自定制的注入机制。相较于传统的Java SPI, Dubbo SPI在封装性和实现类发现性上做了很多的扩展和自定制。
Dubbo SPI整体实现机制及工作机制不在本文范围,但为了行文方便,在此做一些必要说明。整体的Dubbo SPI机制可以分为三部分:
- @SPI注解——声明当前接口类为可扩展接口。
- @Adaptive注解——声明当前接口类(或者当前接口类的当前方法)能根据特定条件(注解中的value),动态调用具体实现类实现方法。
- @Activate注解——声明当前类/方法实现了某个可扩展接口(或者可扩展接口的某个具体方法的实现),并注明被激活的条件,以及所有的被激活实现类中的排序信息。
我们以Dubbo-Auth(dubbo/dubbo-plugin/dubbo-auth at 3.0 · apache/dubbo · GitHub)为例,从核心路径和开放接口两个维度进行分析。
Dubbo-Auth的实现逻辑,是基于Dubbo-filter的原理,也就是说:Dubbo-Auth本身就是Dubbo整体流程中的某一个环节的委派实现方。
Dubbo-Auth的核心入口(也就是核心路径的起始点), 是ProviderAuthFilter,
是org.apache.dubbo.auth.filter的具体实现, 也就是说:
- org.apache.dubbo.auth.filter是dubbo核心链路中对外暴露的一个开发接口(类定义上标注了@SPI)。
- ProviderAuthFilter是实现了dubbo核心链路中对外暴露的开发接口Filter(ProviderAuthFilter实现类定义上标注了@Activate)。
ProviderAuthFilter的核心路径比较简单:获取Authenticator对象,使用Authenticator对象进行auth验证。
具体代码如下:
@Activate(group = CommonConstants.PROVIDER, order = -10000)
public class ProviderAuthFilter implements Filter {
@Override
public Result invoke(Invoker invoker, Invocation invocation) throws RpcException {
URL url = invoker.getUrl();
boolean shouldAuth = url.getParameter(Constants.SERVICE_AUTH, false);
if (shouldAuth) {
Authenticator authenticator = ExtensionLoader.getExtensionLoader(Authenticator.class)
.getExtension(url.getParameter(Constants.AUTHENTICATOR, Constants.DEFAULT_AUTHENTICATOR));
try {
authenticator.authenticate(invocation, url);
} catch (Exception e) {
return AsyncRpcResult.newDefaultAsyncResult(e, invocation);
}
}
return invoker.invoke(invocation);
}
}注意,上文代码中url.getParameter(Constants.AUTHENTICATOR, Constants.DEFAULT_AUTHENTICATOR)是dubbo spi 的Adaptive机制中的选择条件,读者可以深究,本文在此略过。
由于核心路径包含了Authenticator ,那么Authenticator 自然就很可能是对外暴露的开发接口了。也就是说,Authenticator 的声明类中,必然是注解了@SPI。
@SPI("accessKey")
public interface Authenticator {
/**
* give a sign to request
*
* @param invocation
* @param url
*/
void sign(Invocation invocation, URL url);
/**
* verify the signature of the request is valid or not
* @param invocation
* @param url
* @throws RpcAuthenticationException when failed to authenticate current invocation
*/
void authenticate(Invocation invocation, URL url) throws RpcAuthenticationException;
}上述代码证明了笔者的猜想。
在Dubbo-Auth中,提供了一个默认的Authenticator :AccessKeyAuthenticator。在这个实现类中,核心路径被再次具体化:
- 获取accessKeyPai;
- 使用accessKeyPair, 计算签名;
- 对比请求中的签名和计算的签名是否相同。
在此核心路径中,由于引入了accessKeyPair概念,于是就引出一个环节:如何获取accessKeyPair, 针对此, dubbo-auth又定义了一个开放接口:AccessKeyStorage。
@SPI
public interface AccessKeyStorage {
/**
* get AccessKeyPair of this request
*
* @param url
* @param invocation
* @return
*/
AccessKeyPair getAccessKey(URL url, Invocation invocation);
}4.3 LOG4J
最后一个案例,我们又回到了日志组件,而之所以介绍LOG4J, 是由于它使用了非常规的“反向委派”机制。
LOG4J借鉴了SLF4J的思想(或者LOG4J在前?SLF4J借鉴的LOG4J ?), 也采用了 接口标准+ 适配器+第三方方案的思路来实现委派。

那么显然,这里就有个问题:SLF4J确认了自己的核心路径,然后暴露出待实现接口,SLF4J-LOG4J在尝试实现SLF4J的待实现接口时,又使用了委托机制,把相关的路径细节外包了出去,从而形成了一个环。
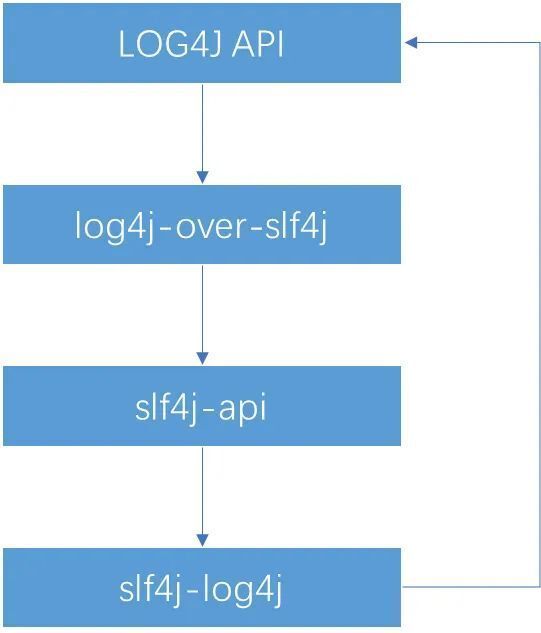
所以说,如果我同时引入了"log4j-over-slf4j"和"slf4j-log4j",会造成stackoverflow。
这个问题非常典型, google一下就可能看到很多的案例,比如Analysis of stack overflow exception of log4j-over-slf4j and slf4j-log4j12 coexistence - actorsfit等等, 官方也给出了警告(SLF4J Error Codes)。
由于此文的关注点在委派模式,所以关于此问题并不详细讨论。而此案例的重点,是说明了一件事:委派模式的缺点,就是对于开放接口的实现逻辑不可控。如果第三方实现存在重大机制性隐患,会导致整体核心流程出现问题。
五、总结
综上所述,
委派模式的使用场景是:
- 存在设定某个标准并由中心化团队负责的必要;
- 使用者有强烈的需求自定制某些局部实现。
委派模式的核心点: 核心路径, 开放接口。
委派模式的隐藏机制:实现方式的注册/发现。
参考资料:
- SLF4J Manual
- Using log4j2 with slf4j: java.lang.StackOverflowError - Stack Overflow
- Creating Extensible Applications (The Java™ Tutorials > The Extension Mechanism > Creating and Using Extensions) (oracle.com)
- slf4j/slf4j-log4j12 at master · qos-ch/slf4j · GitHub
- Delegation pattern - Wikipedia
- What is a JDBC driver? - IBM Documentation
- Lesson: JDBC Basics (The Java™ Tutorials > JDBC Database Access) (oracle.com)
- GitHub - apache/dubbo: Apache Dubbo is a high-performance, java based, open source RPC framework.