Graph Survey
##Graph Embeding
###Deepwalk
核心思想是将图节点的表示像NLP句子中的单词一样进行表示,先进行随机游走,之后得到游走的n个序列,这里看作是NLP里面的句子,通过NLP的算法模型skip-gram来对这些序列学习,序列里面的节点相当于句子中的词汇。最终得到节点的embedding

(复习用)
这里我对deepwalk流程和思想到时搞明白了,但没有研究NLP那些模型,要是考虑攻击的话还是需要看看那些模型
###LINE
LINE可以在无向图与有向图做embedding,deepwalk只能无向
作者定义了一阶相似度与二阶相似度,与经验概率
一阶相似度

经验概率分布

两者使用KL-divergence算出距离,并使其最小

二阶相似度

二阶优化函数

一阶与二阶优化函数分别得到对应的一阶与二阶的节点表示,再将其拼接得到embedding
?:这里二阶相似度公式里的u‘每台搞懂,好像是说表示的是邻居节点信息的,但咋求出来的?
###Node2Vec
1.游走策略:

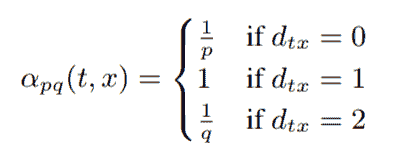
π[vx] = α[pq](t, x)·w[vx]
游走时的选择遵循上式概率π[vx] ,α(t, x)代表距离t节点0,1,2节点在便利到x节点后再便利的可能性,乘以W即得到总概率,因为有些节点与x节点没有直接的边
同时,当q值较小时最终embedding体现结构性更多一些,p值较小时,体现区域信息更多一些
2.优化策略:
与deepwalk类似,不过这里并不是随机游走,而是有策略的游走,获得到这些序列之后,通过skip-gram求embedding
3.总结:(复习用)

###SDNE(Structure Deep Network Embeding)
一阶相似度:代表两个节点是否相似
二阶相似度:代表两个节点临域是否相似
对图的邻接矩阵里每一行进行encode与decode,并缩小两端误差,在中间的向量就表示embedding(有点像cycleGAN),这个embedding内聚合了二阶临域信息
1.用以下lost function优化节点二阶相似度信息

这里B含义是当与节点i不相邻的节点若在decode后出现了数值则删掉,因为我们不关注
2.之后是一阶embedding优化函数

这里我对一阶相似度embedding计算有点小疑惑,这里是已知两节点一阶特性一样,然后再去优化他们的隐藏层(就是encode和decode之间的那个向量)达到一致这个意思吗?
3.总优化函数

后面加了一个正则项,其式:

总结:(复习用)

##Spectral method(暂未总结)
###Spectral Network
###ChebNet
###GCN
##Spatial method
###GAT
我认为GAT机制基本与GCN一样,虽说他是spatial method,感觉像是更新的过程很像?就是加入了一个attention coefficients(注意力系数),在更新特征时乘上这个系数
流程:
1.首先计算各个节点之间的attention coefficients
2.根据attention coefficients聚合邻居节点系信息
3.进行普通的更新计算
对于单个self-attention过程

这里aij即为归一化后的注意力系数
对于muti self-attention

这里K为注意力机制的个数
这里对于muti self-attention机制还是有点疑惑,为什么要每个注意力机制计算出来的结果一定要拼接而不是去平均值?
对于以上训练方面的内容,我认为和GCN无异,攻击方式也可认为是一样的。
对于GAT,我认为对他的攻击还可以从注意力系数下手。也就是attention coefficients的计算上

###GraphSAGE
我认为GraphSAGE同样也是在节点的邻居聚合上下功夫,在训练过程中并没有发生重大变动
流程:
1.选择需要聚合的层数
2.根据每个节点可聚合的个数,挑选邻居信息聚合,再与自身系信息链接,
3.根据所要聚合的层数一次对每个节点的信息更新
4.不断梯度优化学习W
其具体流程为:对于设定的K范围内的节点,聚合此范围内节点的信息。并通过拼接直接算入中心节点的信息
我认为这种网络容易受到干扰的但不大,因为K值越大代表着这个网络所需要的外在信息就越多,也代表着越难防御,不过相对的也比较难攻击,因为边缘节点的信息可能会随着聚合而稀释掉。但作者提到他的模型在K=2时效果比较好
所以我认为,可以造成攻击的地方(仅针对GraphSAGE)就是在
1.针对邻居节点较少的节点可以添加节点进行攻击,因为在边缘添加节点代价较少。
2.对其训练过程进行攻击?
3.aggregator architecture?考虑到它的排列不变性,所以我觉得应该无法影响
对于spatial method一点思考:
1.感觉各种方法在聚合邻居信息上采用的机制越复杂,越能更好的学到邻居信息,抗干扰性越强,因为其节点特征来自多个方向,每个方向贡献都很小。
##Heterogeneous Graph
###HAN(Heterogeneous GAT)
1.定义meta-path,找出同类节点邻居
2.遍历节点的所有meta-path找出它的邻居,求出节点的embedding
感觉这个模型作者主要贡献就是定义了异构图上的邻居关系
###GTN(Graph Transformer Network)
1.将多种边关系的邻接矩阵拼接在一起
2.考虑组合起来的邻接矩阵里面的各节点类别关系,设置可学习参数
感觉GTN与HAN不一样的地方在于GTN对图进行更新时,这个图是包涵不同种类的节点关系的。
而且,GTN可以学习任意长度的meta-path
###GATNE(General Attributed Multiplex Heterogeneous Network Embeding)
模型本意是希望节点在不同类型的边中用不同类型的表示:比如在购买商品时用户使用一种表示,在点击商品时用一种表示等
流程:
1.初始化每边类别对应的个节点的embedding
2.类似于GraphSAGE思想,节点v对r类型的边第k阶邻居进行聚合,得到此类型的edge embedding
3.把不同类型边的edge embedding进行concat聚合
4.考虑到每类变得不同权重,进行注意力机制计算权重
5.得出edge embedding
6.将一开始计算的base embedding与edge embedding结合得出在r类型边中的综合embedding
Bipartite graph
###BINE(Bepartite Betwork Embeding)
1.这里首先定义了显式关系与隐式关系,之后对于embedding求解方式与LINE里的基本一样
2.显式关系建模(Modeling Explicit Relations)
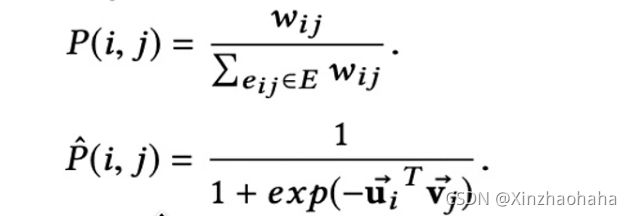
公式二分母ui与vj代表二分图两类节点
之后用KL-divergence最小化两个分布距离
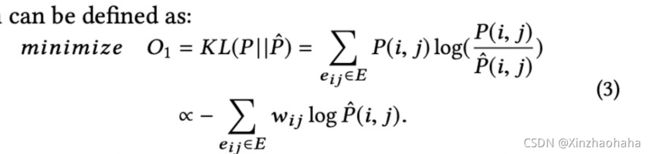
3.隐式关系建模(Modeling Implicit Relations)
隐式关系:相同类型节点之间存在路径
隐式关系权重计算:

式子一表示在U类别下,i,j节点距离,式子二同理
4.之后通过得到的显式,隐式关系用deepwalk来求得embedding
同时这里的deepwalk算法也有一些改动:
1.随机游走的序列长度是随机的
2.中心性越大的节点随机游走的概率越高
5.总结
游走流程流程:
1.计算每个节点中心性
2.计算节点间的权重
3.对于每一次游走,依照中心性规定游走次数,并规定哟一定可能性暂停

4.在得到两个语料库之后,使用skip-gram计算embedding,流程如下公式(5)(6),公式(5)表示当ui出此案的情况下,uj出现的概率,应使其最大化

概率计算公式(但实际使用的是负采样)

这里其实我对概率公式里第二个需要学习的参数θ有点困惑?
5.最终得到总体的优化函数

6.联合优化(joint optimization)(这步没太看明白)
优化总体函数也分为优化显式的部分和隐式的部分,分别对应step1与step2
step1:

step2:

这两个更新的公式看得我有点懵,这里更新的对象不是需要学习的吗?
(复习用)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xi8UGGrk-1630325097460)(https://raw.githubusercontent.com/zhengjingwei/image-bed/master/BiNE-4.jpg)]
##Signal Graph
###SGCN(Signal Graph Convolutional Network)
我对Signal Graph实际用途有点迷惑,对于这个平衡理论的用途有点摸不着头脑
1.Balance Theory
Balance cycle:包含偶数负路径,
unbalance cycle::反之
定义平衡与非平衡集合

2.节点特征表示

以上公式表示节点一阶的平衡集合里的特征与非平衡集合里的特征,那平衡举例:公式将于此节点正链接的节点取平均值后与此节点hi连接,乘上一个可学习参数再过激活函数,得出此节点的一阶平衡特征表示。公式(3)亦然
对于k阶

此公式可照一阶公式结构理解
最终将两个embedding拼在一起
3.损失函数(这个公式也是半懂)

我理解,此公式分为三部分:
1.第一部分代表节点之间边的类别(正,负,无),公式含义为预测的边正确的概率(当然这里取负了,就是使最小)
但这里对于分类器θ我有点懵?2.第二部分,作者认为正向边连接的两点i,j距离应该是要大于任意一个与i节点不相邻的k节点;其次,如果是两节点之间是负向连接的话,则两节点embedding之差因该是要小于任意一个与节点i不相邻的k节点。
3.正则项
原文链接:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8594922
##Dynamic Graph
###DySAT(Dynamic Self-Attention Network)
流程:
1.在分段的时间上,分别计算每个时间段上图的embedding
2.再将每个节点的每个时间段的embedding抽出来训练一个RNN模型,从而预测未来的embedding
1.计算某一时间片
用一个类似于GAT的算法计算embedding

这里与GAT不同之处为这里乘上了一个边的权重
之后再计算聚合邻居节点的embedding

##Framework
###MPNN(Message Pass neural Network)
1.消息函数Mt,邻域聚合
2.更新函数Ut,与自身特征结合
3.readout函数将上述结果组合
###NLNN(Non-Local Neural Network)

这里f相当于在求attentation系数,g在求对应的邻居j的特征表示结果y未归一化后的节点i特征
###GN
目前暂没看懂