ICCV2015(object detection):Fast RCNN-论文解读《Fast R-CNN》
文章目录
-
- 原文地址
- 论文阅读方法
- 初识(Abstract & Introduction & Conclusion)
- 相知(Body)
-
- 2. Fast R-CNN architecture and training
-
- 2.1 The RoI pooling layer
- 2.2 Initializing from pre-trained networks
- 2.3 Fine-tuning for object detection
-
- Multi-task loss
- Mini-batch sampling
- 2.4 Scale invariance
- 3. Fast R-CNN detection
-
- 3.1 Truncated SVD for faster detection
- 4. Main results
- 5. Design evaluation
-
- 5.1 Does multi-task training help?
- 5.2 Scale invariance: to brute force or finesse?
- 5.3 Do we need more training data?
- 5.4 Do SVMs outperform softmax?
- 5.5 Are more proposals always better?
- 回顾(Review)
- 关于代码
原文地址
https://arxiv.org/abs/1504.08083
论文阅读方法
三遍论文法
初识(Abstract & Introduction & Conclusion)
本文(Fast R-CNN)在之前RCNN的基础上应用了多种创新,提升了训练和测试的速度,同时也提升了检测的准确率。
首先,作者说明目标检测任务需要对物体进行精准的定位,从而产生两个问题:首先大量的候选proposal需要被处理,其次这些proposal只能提供粗略的定位,必须对其进行refine得到更精确的定位。而要解决这些问题,通常会降低模型的速度、准确度或简单性,因此本文提出了一个single-stage训练算法,可以同时学习分类object proposal以及refine空间位置。
作者指出RCNN存在以下几个缺点:
- 训练的流程是多阶段的:R-CNN首先需要对CNN进行fine-tuning,然后再利用CNN提取的特征训练SVM,最后还需要学习boundding-box回归模型。
- 训练占用了太多时间、空间资源:为了训练SVM和bounding-box回归模型,需要对所有图像的object proposal提取特征并存入磁盘,这需要耗费大量时间空间。
- 检测过程太慢:在测试时,每个测试样本中的所有object proposal都需要提取特征,速度太慢。
同时,本文也提到了SPPnet,SPPnet的核心思想就是计算整个输入图像的feature map,从这个共享feature map上提取每个object proposal所对应的特征向量进行分类。SPP会对proposal内的feature map特定区域进行max-pool操作,使其变为固定大小输出(例如. 6x6)。在spatial pyramid pooling中得到不同尺度的输出后,将其串联作为最后的特征(固定尺寸)。SPP的好处是只需要对全图提取一次feature map,并且可以接受任意大小的输入,如下图所示:

关于SPPNet详情可参考这篇博客:https://blog.csdn.net/v1_vivian/article/details/73275259
但SPPNet的缺点也类似于RCNN:训练过程也是多阶段的,fine-tune CNN+SVM+Bounding-box回归;CNN提取的特征也需要存入磁盘,并且其在fine-tuning过程中没有更新SSP之前的卷积层(固定的卷积层也限制了SPPNet的准确性)。
本文的贡献可以归纳为以下几点:
- 比R-CNN,SPPNet的检测质量更高(mAP);
- 训练过程是单阶段的,同时使用了multi-task loss;
- 训练能够更新所有的网络层;
- feature缓存不需要写入硬盘
相知(Body)
2. Fast R-CNN architecture and training

Fast R-CNN的整个流程如上图所示:网络以一张完整图像和一组object proposals作为输入,网络首先处理整幅图像从而产生Conv feature map(经过卷积+池化),对于每个object proposal,利用Region of Interest(RoI) Pooling层从对应的feature map提取固定长度的特征向量。随后,特征向量送入一系列的全连接层并得到两个输出层:一个用于预测类别的softmax层(K+1类),另一层为K类中的每一类object输出四个值(用于refine bounding-box的位置)
2.1 The RoI pooling layer
ROI pooling层主要使用max pool将每个ROI的feature转换为一个固定尺寸(H x W)的feature map,本文中ROI就是Conv feature map中的一个矩形窗口,每个ROI可以由一个四元组确定(x,y,h,w),(x,y)为左上角坐标,h为高,w为宽。
ROI pooling就是将h * w的ROI窗口分为H * W个子窗口,对每个子窗口进行max-pooling操作,最后就得到了H*W大小的固定输出。ROI pooling为SPP的一个特例,因为只用了一种尺寸(HxW)的子窗口。
2.2 Initializing from pre-trained networks
预训练网络要初始化为Fast R-CNN的backbone需要经历三个阶段:
- 最后一个pooling层被ROI pooling层所代替,并且H和W设置为对应的值以匹配后续的全连接层(例如VGG16,H=W=7);
- 最后的全连接层和softmax层用上文提到的两个输出层代替;
- 输入改为为两个输入:图像以及图像中的RoI。
2.3 Fine-tuning for object detection
首先说明SPPNet在fine-tuning阶段为什么不对SPP之前的卷积层更新,根本原因是由于SPPNet中每个训练样本(即RoI)来自不同图片,这导致反向传播过程非常低效:每个ROI可能有很大的感受野(通常覆盖整幅图),并且前向传递必须处理整个接收场,因此训练输入很大(通常是整个图像),反向传播算法计算时需要用到正向传递过程的数据,这导致需要存储的数据量巨大。
本文提出了一个更高效的训练策略:SGD的mini-batch为层次采样,采样N个图像,然后每幅图像采用R/N个ROI,这样来自于同一幅图像的ROIs可以在前向和后向传播中共享权重和内存(其中N越小计算量越小,比如N=2,R=128比ROI来自128幅不同图像的训练策略快了64x,这也是RNN和SPPNet所用的策略)。
除了层次采样,Fast RCNN使用one fine-tuning stage (RCNN为3阶段),同时优化softmax分类器以及bounding box回归器。
Multi-task loss
本文有两个任务分支,一个是分类,另一个是用于bounding-box回归,因此使用了多任务loss:

其中,第一个Lcls 用于衡量类别预测的log loss:
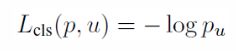
式(1)中第二个部分用来衡量对真实类别u预测的bounding-box与groundtruth间的差距,其中[·]为指示函数,意为不考虑类别u为背景的情况(u=0代表背景类,因为对于背景类的bounding-box没有真正的groundtruth),λ为超参数用于平衡loss间尺度差异。
对于类别u来说,其bounding-box回归的ground-truth为以下元组:
![]()
从bounding-boxregression支路预测出来的输出为:
![]()
预测元组中每个元素能够指定与object proposal相关的scale-invariant translation和log-space height/width shift (并不直接为坐标、长宽值)
其中,Lloc 的具体形式为:
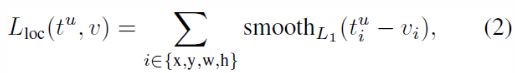
其中,smooth的具体形式为:
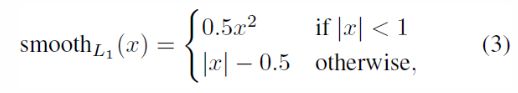
Mini-batch sampling
在fine-tuning阶段,N=2,R=128,每幅图像选取64个ROI。所选的ROI中IoU>0.5的占25%,这ROIs包含了前景(u≥1);剩余的75%在[0.1, 0.5)之间选取(从大到小依次选择);小于0.1的ROI可作为hard example mining。在训练阶段,使用概率为0.5的随机水平翻转用于数据增广。
2.4 Scale invariance
本文使用了两种方式来学习目标检测中的尺度不变性(不同尺度的图像都能被正确预测):
- "brute force" learning (单一尺度):在训练和测试时,每幅图像都要被处理为预先设定的尺寸。整个网络需要直接从训练数据中学到尺度不变性;
- Image Pyramid (多尺度):训练时随机从Image Pyramid Scale采样(类似于数据增广),测试时根据proposal来选择Pyramid中最相似的图像(详见下文)。
3. Fast R-CNN detection
Fast R-CNN经过fine-tuned之后,检测的过程实际就是做一次forward pass(假设proposal已经计算好)。以一张图片(或者是Image Pyramid,编码了一组图片)和一组object proposal(大小为R,为2000)作为输入,当使用Image Pyramid时,在Pyramid中选择ROI最接近2242 的feature map提取对应的ROI feature(例如Image Pyramid中image scale为{480, 576, 688, 864, 1200, itself}, 找到图像中proposal最接近224x224的feature map)。
对于每个ROI r,送入网络会得到类别概率p和与r相关的bounding-box offset,使用与R-CNN中的非极大值抑制算法对每个类的ROI进行筛选。
3.1 Truncated SVD for faster detection
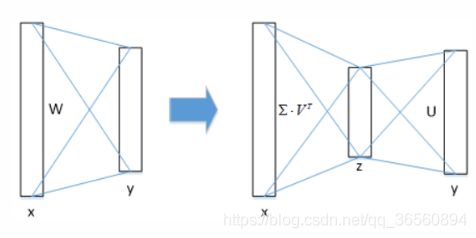
对于Fast RCNN来说,每张图都有大概2k个proposal,这样在前向计算时,全连接层计算会浪费很多时间,但它可以通过截断SVD进行压缩从而提升速度。
全连接层权重矩阵W的维度为u x v,可以使用SVD近似分解为:
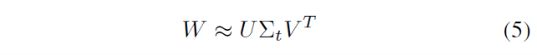
其中U为一个u x t的矩阵(压缩了W的前t个左奇异向量),∑t 为t x t矩阵(包含W的前t个奇异值),V是一个v x t矩阵(压缩了W的前t个右奇异向量)。截断SVD将计算量由uv减少为t(u+v)。压缩后的网络,与W对应的全连接层变为两个全连接层,如下图所示:
4. Main results
主要的实验结果如下:
- 在VOC 2007和2012benchmark上取得新的SOTA mAP
- 相比于R-CNN、SPPNet具有更快的训练和测试速度
- 在VGG16上对卷积层进行fine-tuning提高了mAP
这里就不贴实验结果了,有兴趣的可以参看原文对应段落
5. Design evaluation
为了更好地证明Fast RCNN结构设计的合理性,设计了一系列实验。
5.1 Does multi-task training help?
多任务训练可以提升性能,因为任务之间可以通过shared representation(CNN)相互影响,协同学习。

5.2 Scale invariance: to brute force or finesse?
比较single scale(brute)和multi-scale(Image Pyramid)两者对于测试性能的区别:

对于Large的深度模型,权衡速度-准确率,只使用single-scale方案。
5.3 Do we need more training data?
答案是毋庸置疑的,训练数据对于深度学习任务来说就是多多益善。
5.4 Do SVMs outperform softmax?
在Fast RCNN框架上,softmax比SVM要好一些,作者认为这是由于softmax在进行scoring ROI时引入了类别间竞争,并且使用softmax代替SVM能避免大量的内存消耗(不需要将feature map存入磁盘)。

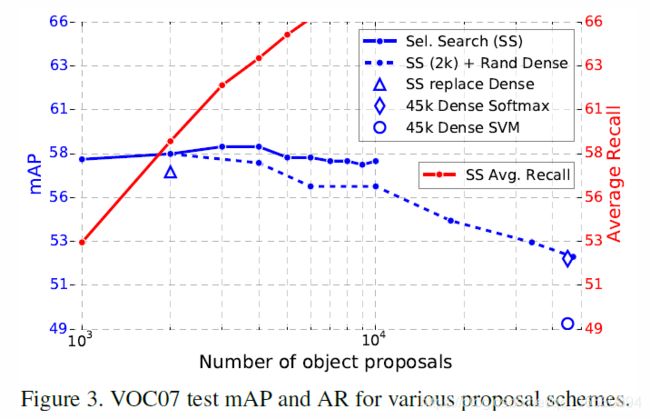
5.5 Are more proposals always better?
候选区域也并非越多越好
回顾(Review)
Fast RCNN发表于ICCV2015,为RCNN系列的第二版,其在RCNN的基础上提升了不少精度以及速度。其与RCNN的主要区别为:
- 首先同样适用Selective Search算法搜索proposals;
- 利用CNN对image进行前向计算,得到Conv Feature Map,然后从中选取proposal所对应的特征向量(ROI),而RCNN中需要将所有的proposal送入CNN进行特征提取;
- 受SPPNet的启发,设计ROI pooling层能够对任意的Input进行处理,从而得到固定尺度的特征向量用于后续的分类;
- 分类不再采用class-specific的线性SVM,也不再单独使用bounding-box regression模型来修正锚框,而是直接在ROI pooling层后使用全连接层,并产生两条分支,一条用于分类预测,一条用于bounding-box回归。
- 整个训练过程变得简化,除了ss算法生成proposal,剩下的训练变为了end-to-end learning。
虽然还有很多细节没有总结,但完全可以看出Fast RCNN在RCNN的基础上改进了不少,并且融入了新的结构与想法,在性能上也得到了很大提高。
关于代码
本文所用方法较老,这里就不贴代码链接以及复现了,大家有兴趣可以自行去github上搜素。
以上为个人的浅见,水平有限,如有不对,望大佬们指点。
未经本人同意,请勿转载,谢谢。