基于图神经网络的图表征学习方法
图表征学习是指将整个图表示成低维、实值、稠密的向量形式,用来对整个图结构进行分析,包括图分类、图之间的相似性计算等。 相比之前的图节点,图的表征学习更加复杂,但构建的方法是建立在图节点表征的基础之上。为了高效地理解图表征学习的原理、掌握实现图表征的的工具和方法,本文先从最早的图表征方法开始介绍,然后介绍基于GNN的图表征学习方法及其Python实践。
1. 最早的图表征方法:Weisfeiler-Leman
1.1 图同构(Graph Isomorphism)
同构图是图论中的一个重要概念,一般认为如果两个图中对应节点的特征信息(attribute)和结构信息(structure)都相同,则称这两个图同构,如下图所示:

上图的映射关系为:A − 3; B − 1; C − 2; D − 5; E−4。 这个还算比较简单,但是如果节点和边的数量都增加了,可能就没法一眼看出,如下图所示。
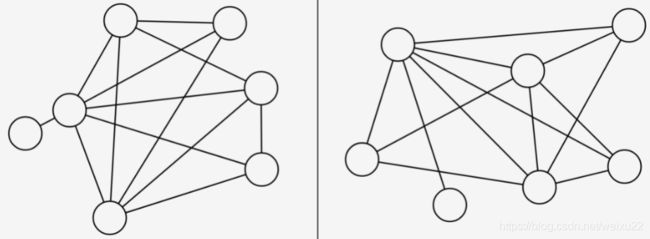
在真实世界中,我们可能需要计算社会网络、蛋白质、基因网络等可能具有几百万节点,几千条万条边的图的相似性,这是无法依赖人工是识别和计算的。
1.2 图同构测试(Graph Isomorphism Test)
在计算机科学领域,图同构测试是一个NP问题,即给定两个图,返回他们的结构是否相同。 图同构问题是一个非常难的问题,目前为止还没有多项式算法能够解决它。为了能够同时考虑图节点的特征和结构信息,将节点的不同类型信息合并转换为一个数值向量是一个解决思路。最后,两个图的相似度问题可以转化为两个图的节点数值向量集合的相似度问题。 目前最有效的算法是 Weisfeiler-Lehman 算法,可以在准多项式时间内进行求解。
1.3 WL算法的步骤
给定两个图 G 和 G‘ ,每个节点拥有标签,图同构判断的过程如下:
-
聚合邻居节点:合并自身标签与邻接节点的标签,中间用 “,” 分隔。
-
合并标签排序:按升序排列邻居节点的标签(例如 4,3151 → 4,1135)
-
标签压缩映射:将较长的字符串映射到一个简短的标签。
-
更新节点标签:给节点打上新映射好的短标签。
迭代 N 轮后,可利用计数函数分别得到两张图的特征向量,然后计算图之间的相似性。如下图:

直观上来看,WL-test 第 k 次迭代时节点的标号表示的是结点高度为 k 的子树结构:

以节点 1 为例,右图是节点 1 迭代两次的子树。因此 WL-test 所考虑的图特征本质上是图中以不同节点为根的子树(整个子树是作为特征)的计数。 值得注意的是,与 WL 算法类似,GNN 也是通过递归更新每个节点的特征向量,从而捕获其周围网络结构和节点的特征。
1.4 作业实践
请画出下方图片中的6号、3号和5号节点的从1层到3层到 WL 子树。

WL 子树如下图所示:

2. 基于GNN的图表征学习:GIN
基于图同构网络的图表征学习主要包含以下两个过程:
-
计算得到图节点的表征
-
对图上各个节点的表征做图池化(Graph Pooling),或称为图读出(Graph Readout),得到图的表征(Graph Representation)。
2.1 基于图同构网络的图表征模块
此模块首先采用 GINNodeEmbedding 模块对图上每一个节点做节点嵌入(Node Embedding),得到节点表征;然后对节点表征做图池化得到图的表征;最后用一层线性变换对图表征转换为对图的预测。代码实现如下:
import torch
from torch import nn
from torch_geometric.nn import global_add_pool, global_mean_pool, global_max_pool, GlobalAttention, Set2Set
from gin_node import GINNodeEmbedding
class GINGraphRepr(nn.Module):
def __init__(self, num_tasks=1, num_layers=5, emb_dim=300, residual=False, drop_ratio=0, JK="last", graph_pooling="sum"):
"""GIN Graph Pooling Module
Args:
num_tasks (int, optional): number of labels to be predicted. Defaults to 1 (控制了图表征的维度,dimension of graph representation).
num_layers (int, optional): number of GINConv layers. Defaults to 5.
emb_dim (int, optional): dimension of node embedding. Defaults to 300.
residual (bool, optional): adding residual connection or not. Defaults to False.
drop_ratio (float, optional): dropout rate. Defaults to 0.
JK (str, optional): 可选的值为"last"和"sum"。选"last",只取最后一层的结点的嵌入,选"sum"对各层的结点的嵌入求和。Defaults to "last".
graph_pooling (str, optional): pooling method of node embedding. 可选的值为"sum","mean","max","attention"和"set2set"。 Defaults to "sum".
Out:
graph representation
"""
super(GINGraphPooling, self).__init__()
self.num_layers = num_layers
self.drop_ratio = drop_ratio
self.JK = JK
self.emb_dim = emb_dim
self.num_tasks = num_tasks
if self.num_layers < 2:
raise ValueError("Number of GNN layers must be greater than 1.")
self.gnn_node = GINNodeEmbedding(num_layers, emb_dim, JK=JK, drop_ratio=drop_ratio, residual=residual) #新定义的方法,可见下一届节
# Pooling function to generate whole-graph embeddings
if graph_pooling == "sum":
self.pool = global_add_pool
elif graph_pooling == "mean":
self.pool = global_mean_pool
elif graph_pooling == "max":
self.pool = global_max_pool
elif graph_pooling == "attention":
self.pool = GlobalAttention(gate_nn=nn.Sequential(
nn.Linear(emb_dim, emb_dim), nn.BatchNorm1d(emb_dim), nn.ReLU(), nn.Linear(emb_dim, 1)))
elif graph_pooling == "set2set":
self.pool = Set2Set(emb_dim, processing_steps=2)
else:
raise ValueError("Invalid graph pooling type.")
if graph_pooling == "set2set":
self.graph_pred_linear = nn.Linear(2*self.emb_dim, self.num_tasks)
else:
self.graph_pred_linear = nn.Linear(self.emb_dim, self.num_tasks)
def forward(self, batched_data):
h_node = self.gnn_node(batched_data)
h_graph = self.pool(h_node, batched_data.batch)
output = self.graph_pred_linear(h_graph) # 线性层
if self.training:
return output
else:
# At inference time, relu is applied to output to ensure positivity
# 因为预测目标的取值范围就在 (0, 50] 内
return torch.clamp(output, min=0, max=50)2.2 基于图同构网络的节点嵌入模块
此节点嵌入模块基于多层GINConv实现结点嵌入的计算。
import torch
from mol_encoder import AtomEncoder
from gin_conv import GINConv
import torch.nn.functional as F
# GNN to generate node embedding
class GINNodeEmbedding(torch.nn.Module):
"""
Output:
node representations
"""
def __init__(self, num_layers, emb_dim, drop_ratio=0.5, JK="last", residual=False):
"""GIN Node Embedding Module"""
super(GINNodeEmbedding, self).__init__()
self.num_layers = num_layers
self.drop_ratio = drop_ratio
self.JK = JK
# add residual connection or not
self.residual = residual
if self.num_layers < 2:
raise ValueError("Number of GNN layers must be greater than 1.")
self.atom_encoder = AtomEncoder(emb_dim)
# List of GNNs
self.convs = torch.nn.ModuleList()
self.batch_norms = torch.nn.ModuleList()
for layer in range(num_layers):
self.convs.append(GINConv(emb_dim))
self.batch_norms.append(torch.nn.BatchNorm1d(emb_dim))
def forward(self, batched_data):
x, edge_index, edge_attr = batched_data.x, batched_data.edge_index, batched_data.edge_attr
# computing input node embedding
h_list = [self.atom_encoder(x)] # 先将类别型原子属性转化为原子表征
for layer in range(self.num_layers):
h = self.convs[layer](h_list[layer], edge_index, edge_attr)
h = self.batch_norms[layer](h)
if layer == self.num_layers - 1:
# remove relu for the last layer
h = F.dropout(h, self.drop_ratio, training=self.training)
else:
h = F.dropout(F.relu(h), self.drop_ratio, training=self.training)
if self.residual:
h += h_list[layer]
h_list.append(h)
# Different implementations of Jk-concat
if self.JK == "last":
node_representation = h_list[-1]
elif self.JK == "sum":
node_representation = 0
for layer in range(self.num_layers + 1):
node_representation += h_list[layer]
return node_representation2.3 计算得到图表征的池化方法
-
"sum":
-
对节点表征求和;
-
使用模块torch_geometric.nn.glob.global_add_pool。
-
-
"mean":
-
对节点表征求平均;
-
使用模块torch_geometric.nn.glob.global_mean_pool。
-
-
"max":取节点表征的最大值。
-
对一个batch中所有节点计算节点表征各个维度的最大值;
-
使用模块torch_geometric.nn.glob.global_max_pool。
-
-
"attention":
-
基于Attention对节点表征加权求和;
-
使用模块 torch_geometric.nn.glob.GlobalAttention;
-
来自论文 “Gated Graph Sequence Neural Networks” 。
-
-
"set2set":
-
另一种基于Attention对节点表征加权求和的方法;
-
使用模块 torch_geometric.nn.glob.Set2Set;
-
来自论文 “Order Matters: Sequence to sequence for sets”。
-
PyG中集成的所有的图池化的方法可见于 Global Pooling Layers。
参考资料
-
【GNN】WL-test:GNN 的性能上界
-
GNN教程:Weisfeiler-Leman算法!
-
Datawhale GNN组队学习开源资料
-
How Powerful are Graph Neural Networks?