动手学强化学习第十章(Actor-Critic算法)
第十章:Actor-Critic算法
文章转载自《动手学强化学习》https://hrl.boyuai.com/chapter/intro
1.理论
Actor-Critic 算法本质上是基于策略的算法,因为这系列算法都是去优化一个带参数的策略,只是其中会额外学习价值函数来帮助策略函数的学习。在 REINFORCE 算法中,目标函数的梯度中有一项轨迹回报,来指导策略的更新。而值函数的概念正是基于期望回报,我们能不能考虑拟合一个值函数来指导策略进行学习呢?这正是 Actor-Critic 算法所做的。
在策略梯度算法中,梯度可以写成下面形式:
g = E [ ∑ t = 0 ∞ ψ t ∇ θ log π θ ( a t ∣ s t ) ] g=\mathbb{E}\left[\sum_{t=0}^{\infty} \psi_{t} \nabla_{\theta} \log \pi_{\theta}\left(a_{t} \mid s_{t}\right)\right] g=E[t=0∑∞ψt∇θlogπθ(at∣st)]

Actor-Critic算法
我们将 Actor-Critic 分为两个部分:分别是 Actor(策略网络)和 Critic(价值网络):
- Critic 要做的是通过 Actor 与环境交互收集的数据学习一个价值函数,这个价值函数会用于帮助 Actor 进行更新策略。
- Actor 要做的则是与环境交互,并利用 Ctitic 价值函数来用策略梯度学习一个更好的策略。
cirtic的更新:
L ( ω ) = 1 2 ( r + γ V ω ( s t + 1 ) − V ω ( s t ) ) 2 \mathcal{L}(\omega)=\frac{1}{2}\left(r+\gamma V_{\omega}\left(s_{t+1}\right)-V_{\omega}\left(s_{t}\right)\right)^{2} L(ω)=21(r+γVω(st+1)−Vω(st))2
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bzL2ffhY-1651305785154)(C:\Users\admin\AppData\Roaming\Typora\typora-user-images\image-20220430155726582.png)]](http://img.e-com-net.com/image/info8/b9a99ec2c37e4d09a427a95d5dcc9665.jpg)
这里具体操作结合代码中.detach()的用法实现应该是
算法流程:

2.实践
代码参考自动手学强化学习(jupyter notebook版本):https://github.com/boyu-ai/Hands-on-RL
使用pycharm打开的请查看:https://github.com/zxs-000202/dsx-rl
方便的话给个star~
import gym
import torch
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
import rl_utils
class PolicyNet(torch.nn.Module):
def __init__(self, state_dim, hidden_dim, action_dim):
super(PolicyNet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, action_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
return F.softmax(self.fc2(x), dim=1)
class ValueNet(torch.nn.Module):
def __init__(self, state_dim, hidden_dim):
super(ValueNet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, 1)
def forward(self, x):
x = F.relu(self.fc1(x))
return self.fc2(x)
class ActorCritic:
def __init__(self, state_dim, hidden_dim, action_dim, actor_lr, critic_lr,
gamma, device):
# 策略网络
self.actor = PolicyNet(state_dim, hidden_dim, action_dim).to(device)
self.critic = ValueNet(state_dim, hidden_dim).to(device) # 价值网络
# 策略网络优化器
self.actor_optimizer = torch.optim.Adam(self.actor.parameters(),
lr=actor_lr)
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(),
lr=critic_lr) # 价值网络优化器
self.gamma = gamma
self.device = device
def take_action(self, state):
state = torch.tensor([state], dtype=torch.float).to(self.device)
probs = self.actor(state)
action_dist = torch.distributions.Categorical(probs)
action = action_dist.sample()
return action.item()
def update(self, transition_dict):
states = torch.tensor(transition_dict['states'],
dtype=torch.float).to(self.device)
actions = torch.tensor(transition_dict['actions']).view(-1, 1).to(
self.device)
rewards = torch.tensor(transition_dict['rewards'],
dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(transition_dict['next_states'],
dtype=torch.float).to(self.device)
dones = torch.tensor(transition_dict['dones'],
dtype=torch.float).view(-1, 1).to(self.device)
# 时序差分目标
td_target = rewards + self.gamma * self.critic(next_states) * (1 -
dones)
td_delta = td_target - self.critic(states) # 时序差分误差
log_probs = torch.log(self.actor(states).gather(1, actions))
actor_loss = torch.mean(-log_probs * td_delta.detach())
# 均方误差损失函数
critic_loss = torch.mean(
F.mse_loss(self.critic(states), td_target.detach()))
self.actor_optimizer.zero_grad()
self.critic_optimizer.zero_grad()
actor_loss.backward() # 计算策略网络的梯度
critic_loss.backward() # 计算价值网络的梯度
self.actor_optimizer.step() # 更新策略网络的参数
self.critic_optimizer.step() # 更新价值网络的参数
actor_lr = 1e-3
critic_lr = 1e-2
num_episodes = 1000
hidden_dim = 128
gamma = 0.98
device = torch.device("cuda") if torch.cuda.is_available() else torch.device(
"cpu")
env_name = 'CartPole-v0'
env = gym.make(env_name)
env.seed(0)
torch.manual_seed(0)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
agent = ActorCritic(state_dim, hidden_dim, action_dim, actor_lr, critic_lr,
gamma, device)
return_list = rl_utils.train_on_policy_agent(env, agent, num_episodes)
episodes_list = list(range(len(return_list)))
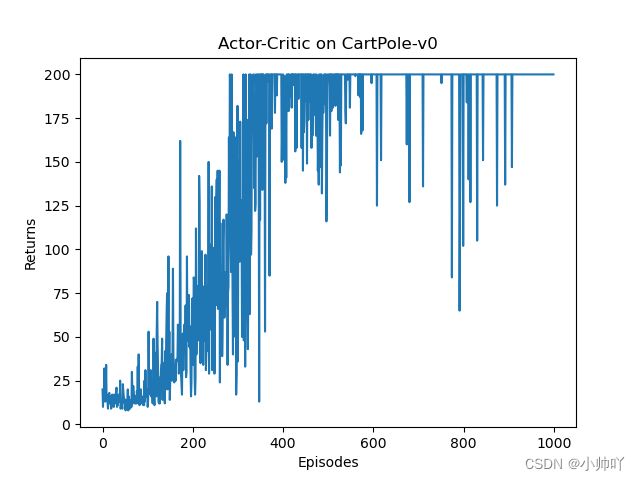
plt.plot(episodes_list, return_list)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('Actor-Critic on {}'.format(env_name))
plt.show()
mv_return = rl_utils.moving_average(return_list, 9)
plt.plot(episodes_list, mv_return)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('Actor-Critic on {}'.format(env_name))
plt.show()