NeurIPS 2021 | 助力半监督学习!一种课程伪标签方法FlexMatch和统一开源库TorchSSL...
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
本文转载自:王晋东不在家
本文介绍一篇最近被机器学习国际权威会议NeurIPS 2021接受的长文:「FlexMatch: Boosting Semi-Supervised Learning with Curriculum Pseudo Labeling」,第一作者为日本东京工业大学的张博闻和王一栋,其他作者来自东京工业大学和微软亚洲研究院。文章针对半监督提出了 「课程伪标签(Curriculum Pseudo Labeling, CPL)」 的方法,其能被简单地应用到多个半监督方法上,且「不会」引入新的超参数和额外的计算开销。多项实验证明,CPL不仅能提升已有方法的精度,也能大幅提升收敛速度(例如,在一些数据集上比Google的FixMatch快5倍)。特别地,文章中将CPL应用在FixMatch后的新算法命名为「FlexMatch」, 并在多个图像分类数据集上取得了state-of-the-art的效果。除此之外,本文还开源了一个统一的基于Pytorch的「半监督方法库TorchSSL」,公平地实现了诸多流行的半监督方法,方便相关领域进行进一步研究。
论文标题:FlexMatch: Boosting Semi-Supervised Learning with Curriculum Pseudo Labeling
论文地址:https://arxiv.org/abs/2110.08263
代码地址:https://github.com/TorchSSL/TorchSSL

算法动机
半监督学习(Semi-supervised Learning, SSL)一直受到研究者广泛的关注,因为它能高效地利用大量的未标注数据去提升模型性能。其中伪标签(Pseudo Labeling, PL)是一个很重要的技术。然而,随着模型训练而产生的伪标签往往伴随着大量错误标注,很多算法因此设定了一个「高而固定的阈值」,来选取那些置信度高的伪标签去计算无监督损失。高阈值可以有效地降低确认偏差(confirmation bias),过滤有噪数据,因此目前最先进的半监督算法如UDA和FixMatch都用到了这样的阈值。
然而本文作者提出「这种固定的高阈值存在一定问题。」
第一,对于分类任务而言,不同的类别的学习难度是不同的,模型在某一时刻对各类的学习情况也是不同的。学的比较好的类,或是简单的类,置信度自然会比较高,就更容易被固定阈值选取。而那些困难的类别,或是当下学的不是很好的类,由于置信度会偏低,就不容易被选到。这样就会导致模型有点“偏科”,比如一个孩子数学学得很好,家长又天天给他看数学书,于是他的数学分就越来越高。而语文本身学的就差,又很少去看语文书,导致语文分数一直提升不上来。表现到模型上就是:对困难类别的拟合不会很好,导致困难类别的最终精度不会很高。如图是FixMatch和FlexMatch的各类学习效果对比。
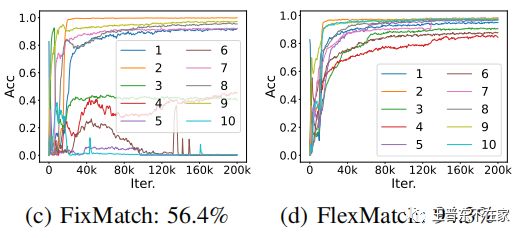
第二,在训练的起步阶段,受随机初始化影响,模型很可能把数据都「盲目地预测到一个类」里面去并且信心很高。如果一个batch中,只选出了这样错误的高信心伪标签,就会把模型往一个错误的方向优化。同时,即便一些样本的预测是正确的,由于开始阶段普遍置信度偏低,导致每个batch的「数据利用率不高」(大部分被过滤掉了),也会导致收敛很慢。如图是FixMatch和FlexMatch的收敛速度对比。

为了解决第一个问题,作者引入了课程学习的思想,把单独的固定阈值转化成了「逐类的动态阈值,根据类别难度给每个类不同的阈值,且这些阈值可以随着模型的学习情况进行实时调整。」
针对第二个问题,作者引入了阈值的warm-up。其思想是,前期由于置信度不是很可靠,我们并不完全根据置信度来选样本,而是让「所有类的阈值逐渐从0开始上升」,给所有样本一个被学习的机会,等模型逐渐稳定获得辨识能力后再恢复到设计的动态阈值,其思想类似学习率的warm-up,因此叫threshold warm-up。
核心思想
那么,各类的动态阈值是如何设计的呢?一个最简单的想法是通过类别准确率(class-wise accuracy)来确定。即:降低准确率更低的类的阈值,给这些类的数据更多被学习的机会,以让模型更好地拟合这些类。而对于准确率已经很高的类,就保持高阈值,以确保最终的精度。
这是一个很理想的方法,但是却存在一些问题。
首先,这种方式需要一个「额外的有标签的验证集」来评价各类的准确率,这在半监督学习下是一笔昂贵的开销,因为我们的标记数据已经很少了(本文实验中在最少的情况下每类只用了4个标记数据)。
其次, 这种方式需要「引入大量的额外计算」,因为要想实时调整动态阈值,需要在每一步迭代后都做一个额外的前向传播来计算类别准确率。这会大幅降低算法速度。
而CPL用了一种巧妙且简单的方法,使得既不需要额外验证集,也不引入额外计算,还不增加额外的超参数。如下图所示。

如图,从图中左侧可以看到CPL考虑了所有的类的所有历史时刻的样本的置信度,对每个类会统计所有超过的样本数量,其中就是前文提到的FixMatch中使用的固定高阈值,将统计出的数量作为学习效果预估(estimated learning effect),并最终用其来调整动态阈值。这其中的关键假设是:「当阈值足够高的时候,高于该阈值且落入类别c的样本个数可以大致反映类别c的学习效果」。换句话说就是如果按FixMatch的算法来走,被选中样本越多的类学习效果就越好,反之亦然。这种设计的巧妙之处在于,FixMatch(UDA等算法同理)在训练的过程中就在选样本了,如果用他已经选出来的样本来调整动态阈值,那不就不需要额外的验证集,也不需要额外前向传播了吗。
具体步骤:
「Step1:学习效果预估。」 如前文所述,这里表示第c类在时刻t的预估学习效果,他其实就是在所有样本中对’高于固定阈值tau‘且’属于类别c‘的样本的一个计数。
「Step2:归一化。」 由于预估学习效果是对样本的一个计数,他的大小会随数据集包含样本数而变,因此需要对其进行归一化使其范围在0到1之间。注意这里归一化分母不是所有类的统计的求和,而是取所有类预估学习效果中的最大值。这样做的特点是,学的最好的类的学习效果为1,进而在应用公式(7)后,其阈值变为,也是动态阈值的上限。
「Step3:确定阈值?」 这里的公式(7)其实已经可以作为最终的动态阈值了,然而作者又提出了两个tricks。
「Step2+:阈值预热。」 如前文所述,文中引入了阈值预热来解决前期高确认偏差的问题。
公式(11)改写了归一化公式(6)的分母部分,“学习效果最大值”改为“学习效果最大值 和 尚未被选择过的样本数 二者的最大值”,其中即表示目前尚未被高阈值选择过的样本数。前期,尚未被选择的样本数量占优,因此后项在起作用,随着大部分样本被选择过至少一次,前项起作用,公式(11)变得等价公式(7)。
「Step3+:非线性映射。」 相比于公式(7)那样的直接scale固定阈值,非线性映射使得阈值的调整可以更加自由,你可以设计任意形状的函数来实现从“归一化预估学习效果”到“最终动态阈值”的映射。其中,本文提到,凸函数可能更加有效,因为凸函数在自变量较小时因变量的变化不是很大,而在自变量大时比较敏感。这比较符合预估学习效果的变化特性,即:前期当其值较小时可能存在较大波动而后期其值变大后波动较小,且中后期多处于较高的范围内变化,因此需要对这部分更敏感。

实验结果
我们在CIFAR10/100、SVHN、STL-10和ImageNet等常用数据集上进行了实验,对比了包括FixMatch、UDA、ReMixmatch等最新最强的SSL算法。实验结果如下表所示。
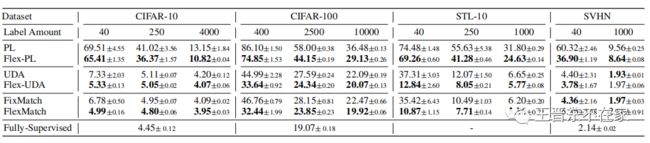
可以看到CPL在多数数据集上取得了很大的提升,除了SVHN上效果不如原版FixMatch,文中的解释是说,CPL不适合「数据分布不平衡且又很简单的任务」,对于简单的任务而言,一个固定的高阈值似乎已经足够了。在其他数据集上,可以发现,「标记数据越少,CPL带来的提升越大。任务越难,CPL的提升越大」。文章同样在ImageNet数据集上测试了算法的有效性,在次迭代后,应用了CPL的FlexMatch的top-1准确率已经比FixMatch高出将近8%了。证明在困难任务上的提升还是比较可观的,ImageNet的数据不平衡度应该和SVHN差不多,但是效果却差了很多。
开源代码库TorchSSL
除此之外,本文开源了TorchSSL代码库,是第一个基于PyTorch的SSL算法库,目前已支持算法有:Pi-Model,MeanTeacher,Pseudo-Label,VAT,MixMatch,UDA,ReMixMatch,FixMatch,和我们的FlexMatch。
了解更多内容,请关注我们的论文:arxiv 2110.08263
References
[1] Dong-Hyun Lee et al. Pseudo-label: The simple and efficient semi-supervised learning methodfor deep neural networks. InWorkshop on challenges in representation learning, ICML,volume 3, 2013.
[2] Qizhe Xie, Zihang Dai, Eduard Hovy, Thang Luong, and Quoc Le. Unsupervised data augmen-tation for consistency training.NeurIPS, 33, 2020.
[3] Kihyuk Sohn, David Berthelot, Nicholas Carlini, Zizhao Zhang, Han Zhang, Colin A Raf-fel, Ekin Dogus Cubuk, Alexey Kurakin, and Chun-Liang Li. Fixmatch: Simplifying semi-supervised learning with consistency and confidence.NeurIPS, 33, 2020.
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的两篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看