爬虫-将采集的数据存放到数据库
爬虫数据来源豆瓣电影排行榜
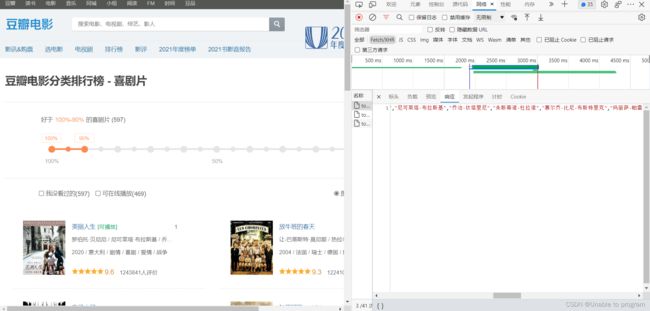
通过抓包工具找接口,然后就是简单的拿数据了
import requests
url = 'https://movie.douban.com/j/chart/top_list?'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.81 Safari/537.36 Edg/104.0.1293.47'
}
param = {
'type': '24',
'interval_id': '100:90',
'action': '',
'start':1,
'limit': '20'
}
# 获取json格式响应数据
response = requests.get(url=url, params=param, headers=headers)
list_data = response.json()由于得到的数据为json格式的,我们得处理一下:
![]()
# 遍历所需键值
for item in list_data:
Id = item['id']
name = item['title']
temp = item['regions']
where = temp[0]
year = item['release_date']这里我只提取了部分元素,由于上述代码只能提取单部电影数据,我们可以改善一下
import requests
url = 'https://movie.douban.com/j/chart/top_list?'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.81 Safari/537.36 Edg/104.0.1293.47'
}
# 遍历不同电影
for index in range(10):
param = {
'type': '24',
'interval_id': '100:90',
'action': '',
'start':index,
'limit': '20'
}
# 获取json格式响应数据
response = requests.get(url=url, params=param, headers=headers)
list_data = response.json()
# 遍历所需键值
for item in list_data:
Id = item['id']
name = item['title']
temp = item['regions']
where = temp[0]
year = item['release_date']到这里,爬虫部分就处理完了,非常简单的爬虫。意会就可以了;
接着,我们连接本地数据库,使用第三方库pymysql:
con = pymysql.connect(
host="127.0.0.1",
port=3306,
user='root',
password='mysql123',
database="person",
charset='utf8'
)然后就是执行SQL语句(注:创建表的过程未列出,如有需要,请自行根据效果图创建)
cur = con.cursor()
try:
# 增加
add_sql = "insert into movies values('{}','{}','{}','{}')".format(Id, name, where, year)
cur.execute(add_sql)
con.commit()将爬虫数据添加到数据表中的方式不唯一,我这里采用的是format(),Python3可使用 f“{}” 的形式格式化SQL语句更为简洁
完整代码如下:
import pymysql
import requests
url = 'https://movie.douban.com/j/chart/top_list?'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.81 Safari/537.36 Edg/104.0.1293.47'
}
# 遍历不同电影
for index in range(10):
param = {
'type': '24',
'interval_id': '100:90',
'action': '',
'start':index,
'limit': '20'
}
# 获取json格式响应数据
response = requests.get(url=url, params=param, headers=headers)
list_data = response.json()
# 遍历所需键值
for item in list_data:
Id = item['id']
name = item['title']
temp = item['regions']
where = temp[0]
year = item['release_date']
# 使用数据库存储
con = pymysql.connect(
host="127.0.0.1",
port=3306,
user='root',
password='mysql123',
database="person",
charset='utf8'
)
# 创建游标对象
cur = con.cursor()
try:
# 增加
add_sql = "insert into movies values('{}','{}','{}','{}')".format(Id, name, where, year)
cur.execute(add_sql)
con.commit()
except Exception as e:
print(e)
con.rollback()
finally:
cur.close() # 关闭游标对象
con.close() # 关闭连接对象
print('程序结束')效果图如下:
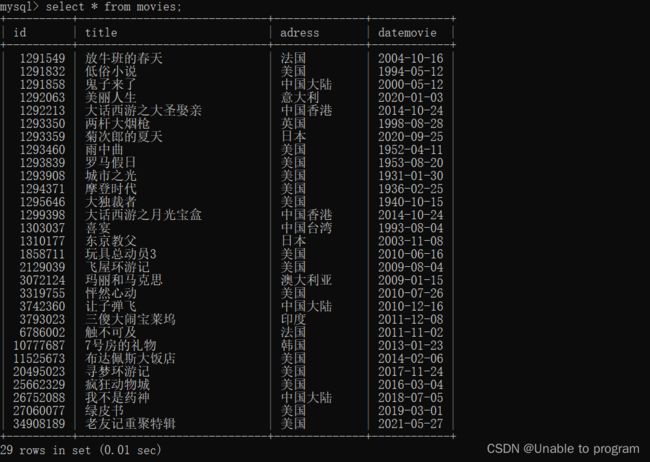
总结:
1.获取数据
2.处理数据
3.连接数据库
4.添加到数据库