一石二鸟:推荐系统多目标任务建模方法
「炼丹笔记」传送门: 这些我全要!推荐系统一石二鸟之道

在做推荐系统时,在系统刚刚搭建时,针对业务目标我们可能只需要去优化CTR或者CVR即可,但是不同的推荐场景下的优化目标不同。同时,随着系统的不断迭代,我们希望推荐算法能够同时优化多个业务目标。
比如,在内容信息流场景中,希望提高用户点击率CTR的基础上提高用户关注、点赞、评论、停留时长等行为,营造更好的社区氛围从而提高留存;而在电商场景中,则希望能够在优化GMV的基础上提高点击率,从而提高用户的粘性和复购行为等。因此,一个成熟的推荐系统,会向多目标、多任务方向进行演化,从而承担起更多的业务目标!
本文,我来分享一下在多目标优化问题上一些思路,包括多目标任务的技巧、算法模型MMOE、SNR、ESMM、PLE等。

通过Sample Weight进行多目标优化,保证一个主目标的同时,通过将其它目标转化为样本权重的方式改变数据分布,从而达到优化其它目标的效果。

这里我们以内容信息流场景为例。设定主目标为内容点击率CTR,用户在内容流中的点击行为定义为正样本。同时,在信息流点赞、评论、转发功能也同样定义为正样本,但是点赞、评论、转发、完播率大的样本可以设置更高的样本权重。对于样本权重大的行为,如果预测错误就会带来更大的损失。通过这种方法能够在优化A目标CTR的基础上,优化B目标停留时长。目标A会受到一定的损失换取目标B的增长。通过线上AB-Test和Sample Weight调整的联动,可以保证A目标损失较小的前提下,带来目标B的提升,实现初级的多目标优化。
这种方式模型简单,上线容易,仅在训练时通过梯度乘以样本权重实现对其它目标的加权即可。但本质上并不是多目标建模,而是将不同的目标转化为同一个目标,样本的加权权重需要根据线上AB测试才能确定。

多目标模型融合,通过一个模型同时训练多个目标(label的构造),线上进行融合。该方法的优点是各个任务之间能够共享信息,统一迭代方便,节省资源。但缺点也比较明显,目标越多模型越复杂,各任务之间相互影响,迭代速度慢等,尤其是在线上需要模型一定的响应时间时,该方法就变得有些笨重。

例如在视频信息流场景中,我们用分类模型优化点击率CTR,用回归模型优化停留时长。不同的模型得到预测的score之后,通过一个函数将多个目标融合在一起,融合的函数可以有很多,比如连乘或者指数相关的函数,这里和业务场景和目标的含义强相关,可以根据自己的实际场景探索。

推荐系统在给用户推荐一些热门内容的同时,也需要对这些内容的质量有一定的把控,比如用户的停留时长、点赞、转发、评论等,所以成熟的推荐系统的推荐模型会同时对多个目标进行优化,而如何对这多个目标进行并行优化,正是本篇论文MMOE关注的重点,在以往的一些模型当中,通常优化一方面的效果就会损失另一方面的效果,所以这是一个Trade-off的过程。除此之外无论是搜索、推荐还是广告,都存在一个的潜在的bias问题。
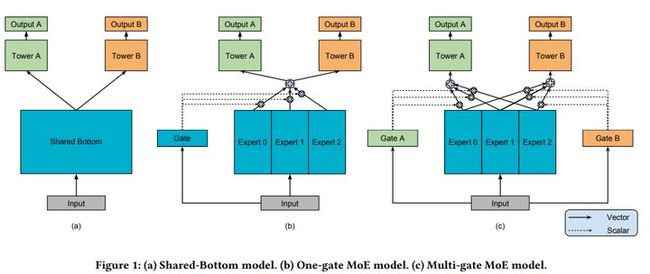
多任务模型通过学习不同任务的联系和差异,可提高每个任务的学习效率和质量。多任务学习的的框架广泛采用Shared-bottom的结构,不同任务间共用底部的隐层。这种结构本质上可以减少过拟合的风险,但是效果上可能受到任务差异和数据分布带来的影响。MMoE模型刻画了任务相关性,基于共享表示来学习特定任务的函数,避免了明显增加参数的缺点。
Shared-Bottom 网络通常位于底部,它通过浅层参数共享,互相补充学习。这种方式下任务相关性越高,模型的loss可以降低到更低。但是当任务没有好的相关性时,这种Hard parameter sharing会损害效果。

MOE由一组专家系统(Experts)组成的神经网络结构替换原来的Shared-Bottom部分,每一个Expert都是一个前馈神经网络,再加上一个门控网络(Gate)。
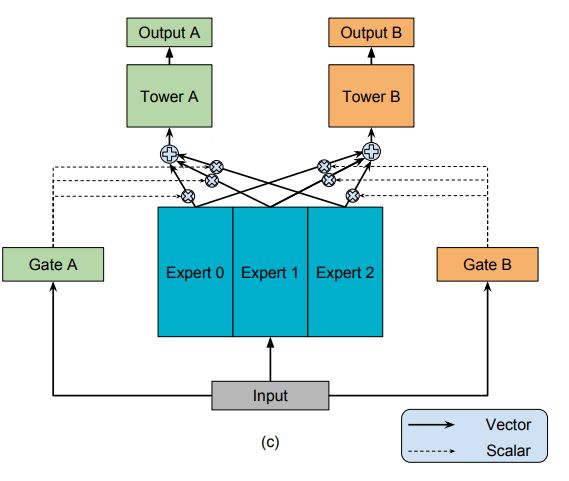
MMoE(Multi-gate Mixture-of-Experts)是在MOE的基础上,使用了多个门控网络, k个任就对应k个门控网络。MMoE包括两个部分,左侧的shallow tower部分和右侧的main tower部分,论文中提到的采用类似Wide&Deep模型结构就是指这两个tower,其中shallow tower可以对应Wide部分,main tower对应的是Deep部分。

谷歌在MMOE之后又做了什么?经典的Shared-Bottom网络结构存在一个明显的问题:当共同训练学习的多个任务之间联系不强的时,会严重损害各自任务的效果。因为相对于多个目标各自训练独立模型而言,Shared-Bottom的网络结构会在共享的网络底层引入了Bias,这个上文中我们已经提到了。
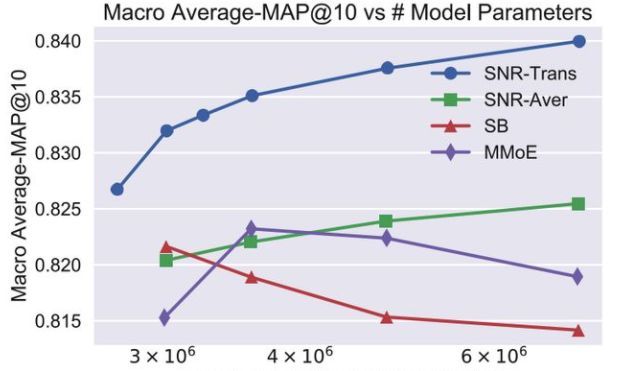
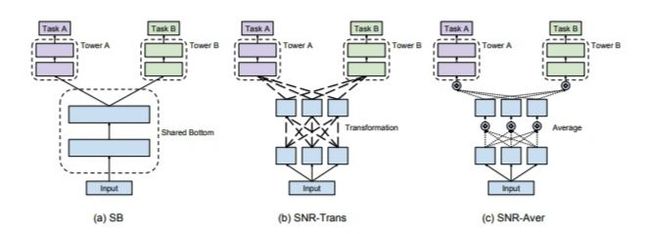
上面提到的MMoE模型存在的一个问题,它只能够针对共享的experts子网络进行有限的组合。因此,在MMoE模型结构的基础上,本文提出了优化的SNR模型来实现更灵活的网络参数共享。与MMoE类似,SNR模型将共享的底层网络模块化为子网络。不同的是,SNR模型使用编码变量来控制子网络之间的连接,并且设计了两种类型的连接方式:SNR-Trans和SNR-Aver。

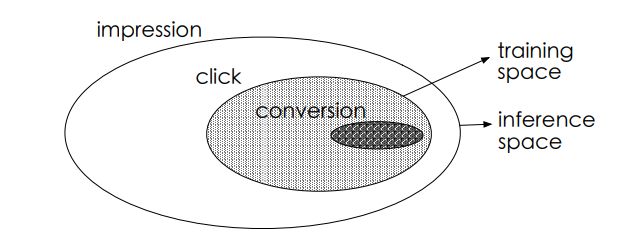
基于 Multi-Task Learning 的思路,阿里妈妈团队在SIGIR2018上提出一种新的CVR预估模型ESMM,它有效解决了真实场景中CVR预估面临的数据稀疏以及样本选择偏差这两个关键问题。CVR预估和CTR任务相比,有两个不同:
(1)Sample Selection Bias转化是在点击之后才“有可能”发生的动作,传统CVR模型通常以点击数据为训练集,其中点击未转化为负例,点击并转化为正例。但是训练好的模型实际使用时,则是对整个空间的样本进行预估,而非只对点击样本进行预估。
(2)Data Sparsity作为CVR训练数据的点击样本远小于CTR预估训练使用的曝光样本。
一些策略可以缓解这两个问题,但都没有从实质上解决上面任一个问题。
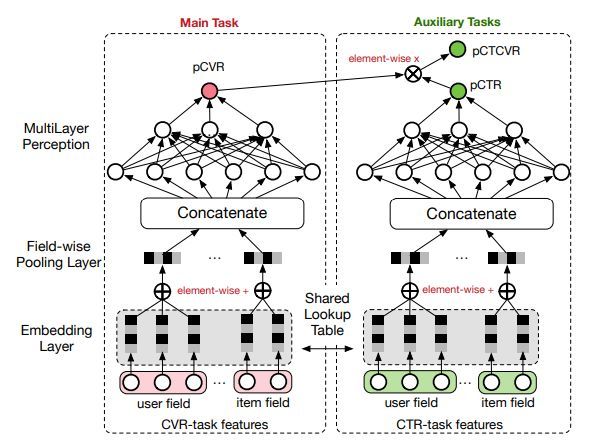
为了解决这个问题,ESMM提出了转化公式:
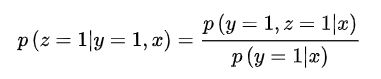
在全部样本空间中,CTR对应的label为click,而CTCVR对应的label为click & conversion,这两个任务是可以使用全部样本的。而PCTCVR和PCTR都可以在全样本空间进行训练和预估。但是这种除法在实际使用中,会引入新的问题。因为PCTR其实是一个很小的值,预估时会出现PCTCVR大于PCTR的情况,导致PCVR预估值大于1。ESSM巧妙的通过将除法改成乘法来解决上面的问题。它引入了PCTR和PCTCVR两个辅助任务,训练时loss为两者相加。
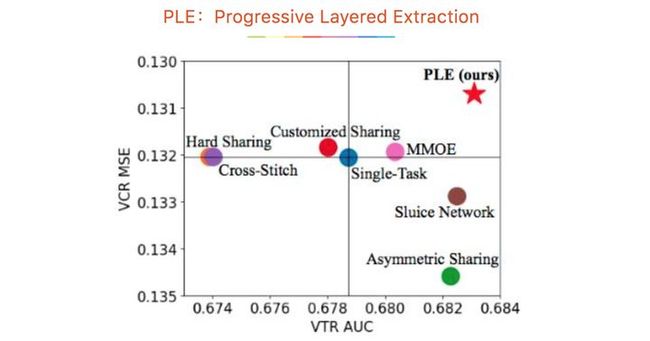
腾讯PCG在RecSys2020发表的最佳长论文PLE(Progressive Layered Extraction),是在视频推荐场景下多任务模型。相对于前面的MMOE、SNR和ESMM模型,PLE模型主要解决两个问题:(1)MMOE中所有的Expert是被所有任务所共享的,这可能无法捕捉到任务之间更复杂的关系,从而给部分任务带来一定的噪声;(2)不同的Expert之间没有交互,联合优化的效果有所折扣。
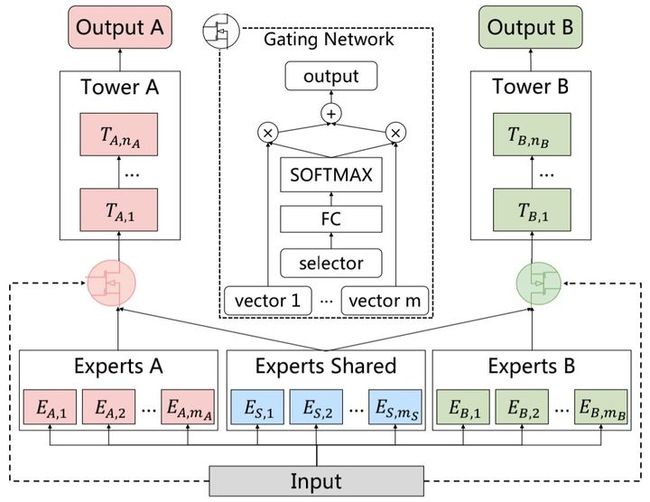
从图中的网络结构可以看出,CGC的底层网络主要包括shared experts和task-specific expert构成,每一个expert module都由多个子网络组成,子网络的个数和网络结构都是超参数。上层由多任务网络构成,每一个多任务网络(towerA和towerB)的输入都是由gating网络进行加权控制,每一个子任务的gating网络的输入包括两部分,其中一部分是本任务下的task-specific部分的experts和shared部分的experts组成。
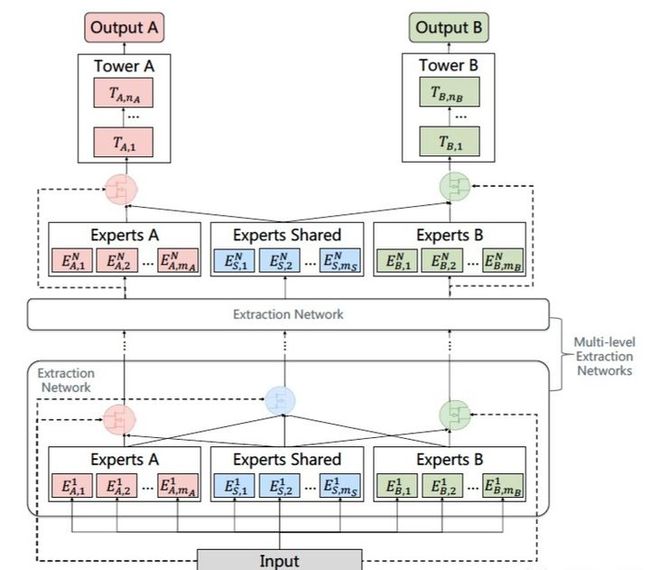
上面看到了CGC网络是一种single-level的网络结构,一个比较直观的思路就是叠加多层CGC网络,从而获得更加丰富的表征能力,而PLE网络结构就是将CGC拓展到了multi-level层中。

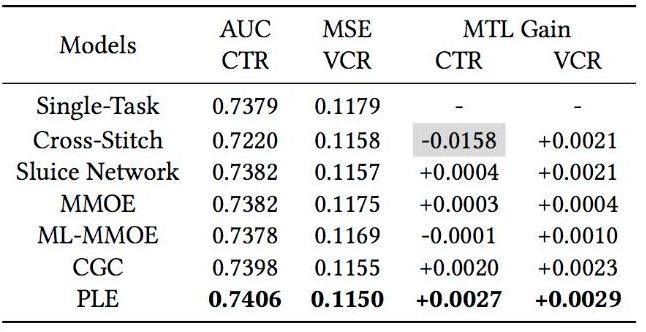
作者还将不同experts的平均权重展示出来,可以看出MOE不同experts权重基本相差不大,PLE模型共享experts和独有experts的权重相差更大,说明针对不同的任务,能够有效利用共享Expert和独有Expert的信息,这也解释了为什么其能够达到比MMoE更好的训练结果。
