利用python数据分析(2)
利用python数据分析
这是自己在练习的时候,一些用到的知识,所以会持续更新……
数据分析的目的一般是用于预测。
利用python进行数据分析首先要导入数据,一般导入数据使用的是下面命令:
import pandas as pd
# 通过pd读取的文件是Dataframe格式的文件
pd.read_csv('文件路径')
当然实际应用中的问题是非常复杂的,数据源的获取也要花费很多时间。
- 当实际中的数据是文本数据,这时候可能需要进行文本的处理:
当前最流行的一种文本处理过程:
- 在处理文本之前,对文本进行分词操作,将为本切分为一个个单元(token),最简单的情况是一个单词一个token。但直接对单词进行切分可能会损失一些信息,比如Santa Barbara应该是一个整体,但被分为2个token。
- 接下来需要正则化数据。对于文本而言,涉及到词干提取(stemming)和词形还原(lemmatization)方法。这两个方法是词形规范化的两类重要方式,都能够达到有效归并词形的目的。
- 当文档被转换为单词序列之后就可以使用向量表示,最简单的方法是(Bag of Words)模型:创建一个长度等于字典的向量,计算每个单词出现在文本中的次数,然后将次数放入到向量对应的位置中。
词袋模型:
import numpy as np
import pandas as pd
texts = ['i have a cat',
'you have a dog',
'you and i have a cat and a dog']
# 使用当前文本信息中的所有单词生成一个字典
vocabulary = list(enumerate(set([word for sentence in texts for word in sentence.split()])))
print('Vocabulary:', vocabulary)
# Vocabulary: [(0, 'and'), (1, 'i'), (2, 'cat'), (3, 'a'), (4, 'you'), (5, 'dog'), (6, 'have')]
# 生成文本向量
def vectorize(text):
vector = np.zeros(len(vocabulary))
for i, word in vocabulary:
num = 0
for w in text:
if w == word:
num += 1
if num:
vector[i] = num
return vector
print('Vectors:')
for sentence in texts:
print(vectorize(sentence.split()))
# Vectors:
# [0. 1. 1. 1. 0. 0. 1.]
# [0. 0. 0. 1. 1. 1. 1.]
# [2. 1. 1. 2. 1. 1. 1.]
当使用词袋模型,只是知道这一段文本中有这几个单词,但是丢失了文本的模型信息,为了避免这一问题,可以使用N-Gram模型:
# CountVectorizer是属于常见的特征数值计算类,是一个文本特征提取方法。对于每一个训练文本,它只考虑每种词汇在该训练文本中出现的频率。 CountVectorizer会将文本中的词语转换为词频矩阵,它通过fit_transform函数计算各个词语出现的次数。
from sklearn.feature_extraction.text import CountVectorizer
# ngram_range=(1, 1)可以对该参数进行改变,从而改变生成的字典
vect = CountVectorizer(ngram_range=(1, 1))
# fit_transform等价于先对模型进行fit,再进行transform函数操作
vect.fit_transform(['no i have cows', 'i have no cows']).toarray()
vect.vocabulary_
# {'no': 2, 'have': 1, 'cows': 0}
vect = CountVectorizer(ngram_range=(1, 2))
vect.fit_transform(['no i have cows', 'i have no cows']).toarray()
vect.vocabulary_
# {'no': 4, 'have': 1, 'cows': 0, 'no have': 6, 'have cows': 2, 'have no': 3, 'no cows': 5}
有时候,在语料库中罕见但在当前文本中出现的专业词汇可能会非常重要。因此,通过增加专业词汇的权重把它们和常用词区分开是很合理的,这一方法称为TF-IDF(词频-逆向文档频率)。
- 图像数据
现在图像的处理,可以直接使用卷积神经来处理。不需要从头设计网络架构,从头训练网络,下载一个当前最先进的预训练网络及其权重,“分离”网络的最后一个全连接层,增加针对特定任务的新层,接着再新数据上训练网络即可。这一让预训练网络适应特定任务的过程被称为微调(fine-tuning)。
通过调用Keras中的预训练网络进行图像特征抽取:
from tensorflow.keras.applications.resnet50 import ResNet50, preprocess_input
from tensorflow.keras.preprocessing import image
from scipy.misc import face
import numpy as np
# 由于原 ResNet50 模型托管在外网上,速度较慢。可以直接从阿里云下载模型。
# 通过ResNet50()函数来加载模型,并通过include_top参数来舍弃模型顶部的全连接层,这一层用于将图像分类,
# 如果舍弃这一层,可以用来自定义的功能
resnet_settings = {'include_top': False, 'weights': 'imagenet'}
resnet = ResNet50(**resnet_settings)
resnet.summary()
# 抽取图片的特征矩阵,所以这里的x表示输入网络的张量(batch_size、width、height、n_channels)
features = resnet.predict(x)
- 地理空间数据
地理空间数据相对于文本和图像并不常见,地理空间数据常常以地址或坐标(经纬度)的形式保存。根据任务的不同,可能需要两种互逆的操作:地理编码(由地址重建坐标点)和逆地理编码(由坐标点重建地址)。在实际项目中,这两个操作可以使用访问外部API(谷歌地图或OpenStreetMap)来使用。不同的地理编码器各有其特性,不同编码质量也不一样,GeoPy类封装了这些操作。如果有大量数据,很快便会达到外部API的限制。所以可是考虑使用本地版的OpenStreetMap。
如果只有少量的数据,可以考虑使用reverse_geocoder:
import reverse_geocoder as revgc
latitude = 40.74482
longitude = -73.94875
revgc.search((latitude, longitude))
# OrderedDict([('lat', '40.74482'), ('lon', '-73.94875'),
# ('name', 'Long Island City'), ('admin1', 'New York'),
# ('admin2', 'Queens County'), ('cc', 'US')])]
- web数据
web数据通常有用户的User Agent信息,这个信息非常重要,可以从中提取操作系统信息,可以创建[is_mobile]特征,还可以查看浏览器类别。
现在浏览器中的User_agent值格式一般如下:
Mozilla/[version] ([system and browser information]) [platform] ([platform details]) [extensions]
import user_agents
ua = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/56.0.2924.76 Chrome/56.0.2924.76 Safari/537.36'
# parse()函数对字段进行语法分析
ua = user_agents.parse(ua)
除了操作系统和浏览器之外,还可以查看referrer(网站来源)和Accept-Language 和其他元信息。
特征标准化
在进行数据分析之前,通常要将数据进行标准化处理。通常使用以下方法:
- z值标准化(Z-score normalization):

z值标准化的目的是将不同量级的数据统一转化为同一量级,以保证数据之间的可比性。
from sklearn.preprocessing import StandardScaler
StandardScaler().fit_transform(data)
- 极大极小缩放(MinMaxScaling),目的是将所有数据点纳入一个预先规定的区间(通常是[0,1]):
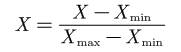
from sklearn.preprocessing import MinMaxScaler
MinMaxScaler().fit_transform(data)
特征缩放和极大极小缩放应用类似,常常可以相互替换。然而,当涉及到计算数据点或向量之间的距离时,默认使用特征缩放,而在可视化时,极大极小缩放很有用,因为它可以将特征纳入[0,255]区间。
特征选择
收集到了数据,要分析数据并选取所需的特征向量,特征选择的重要性如下:
- 数据越多,计算的复杂度越高。
- 部分算法会将噪声(不含信息量的特征)加入计算,导致过拟合。
选择特征向量的时候可以利用matplotlib、seaborn等可视化库分析每个变量与结果之间是否有线性关系,来自行选取特征向量。
import matplotlib.pyplot as plt
plt.subplot(221)
# TS是我的数据集,dataframe类型
plt.scatter(x=TS['G'], y=TS['Rk'])
plt.subplot(222)
plt.scatter(x=TS['MP'], y=TS['Rk'])
plt.show()
那么如下图这样的样本点就不是很好的样本点,可以考虑选择删去:
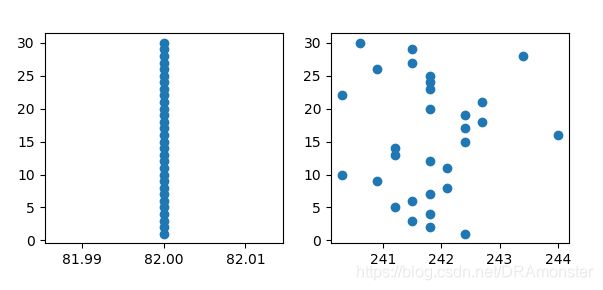
一些方差较低的特征可能不如方差较高的特征重要,有时可以考虑删除方差低于特定阈值的特征。
特征选择还可以使用某个模型评估特征重要性,常用的两类模型是:随机森林和搭配Lasso正则的线性模型。(sklearn.feature_selection库的应用)
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_selection import SelectFromModel
rf = RandomForestClassifier(n_estimators=10, random_state=17)
s_feature = SelectFromModel(estimator=rf)
分析日期型变量:可以将数据用以下命令转换成日期格式(在上一个文章的时间序列章节讲过)
import pandas as pd
x = pd.to_datetime(x)
# 可利用datetime类型的strftime函数截取小时和分钟
x = [a.strftime('%H:%M') for a in x]
# 新建figure对象
fig = plt.figure()
# 新建子图
ax = fig.add_subplot(1, 1, 1)
plt.plot(x, y)
# 设置x轴的数据格式
plt.xticks(rotation=30, fontsize='small')
plt.show()
效果如下:
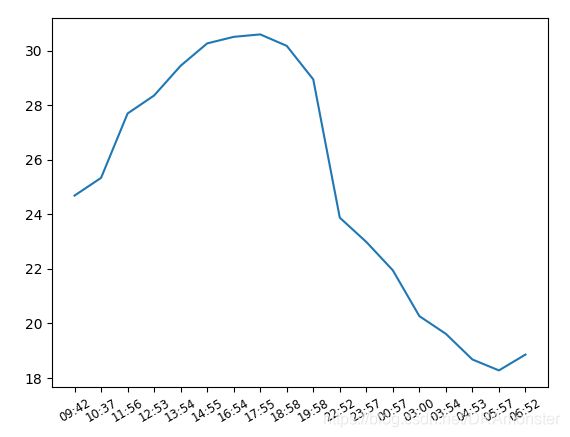
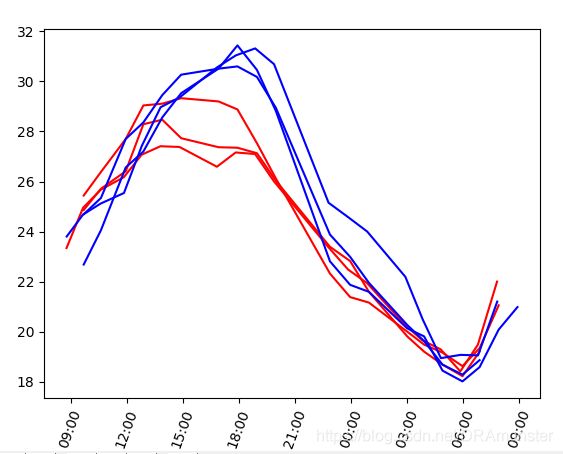
如果要在一个子图上划多条曲线图,可以使用如下方式:
ax.plot(x1, y1, 'r', x2, y2, 'r', x3, y3, 'r')
ax.plot(x4, y4, 'b', x5, y5, 'b', x6, y6, 'b')
效果如下:
选定了要选取的特征向量之后,就要进行数据清洗,
一般要进行的操作有:
- 去除不需要的特征值,或者是缺失值太多的值的特征值
- 缺失值的填补,采用中值,平均值等方法填补缺失数据
- 非数值数据的转换为数值。
- 如果原始数据是多表,可能还涉及到多表合并的操作。
去除不需要的特征值,使用的是之前介绍的:
# axis=1,列方向
TS = TS.drop(['Rk', 'G', 'MP'], axis=1)
使用之前文章中介绍的Dataframe连接,pandas库中的merge函数:
X = pd.merge(TS, OS, how='left', on='Team')
重置索引(注意两种重置索引方法的区别):
# reindex方法返回的是一个新表,值填充为NaN
print(X.reindex(X['Team']).head())
输出如下:

print(X.set_index('Team', drop=True, inplace=False).head())
输出如下:
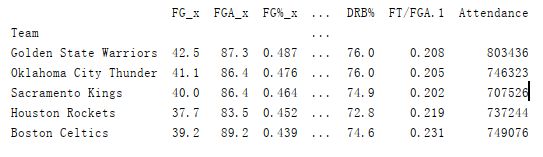
Elo等级分,Elo最初用于国际象棋中更好地对不同的选手进行等级划分。简单介绍一下Elo等级划分制度,pk双方对各自的胜率的期望计算公式。假设A和B的当前等级分为RA和RB,则A对B的胜率期望值为:

B对A的胜率期望为:
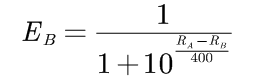
如果棋手在比赛中的真实得分SA(胜1分,和0.5分,负0分)和他的期望值不同,则它的等级要根据以下公式重新调整:
![]()
在国际象棋中,根据等级分的不同K值也会做相应的调整(基础elo等级分):
- 大于等于2400,K=16
- 2100~2400分,K=24
- 小于等于2100,K=32
CART算法在生成树的过程中,分类树采用了基尼指数(Gini index,和熵的概念很类似,数值相近但不同基尼指数在运算时速度会更快一点)最小化原则,而回归树选择了平方损失函数最小化原则。
CART算法也包含了树的修剪,CART算法从完全生长的决策树底端剪去一些子树,使得模型更加简单。而修剪这些子树时,是每次去除一棵,逐步修剪直到根节点,从而形成一个子树序列,最后,对该子树序列进行交叉验证,再选出最优的子树作为最终决策树。
UCI 机器学习数据集网站:https://archive.ics.uci.edu/ml/datasets.php
一般实验所用数据集是按照顺序进行排列的,这时最好的选择是在划分训练集和测试集之前打乱数据集,因为直接划分容易导致某一分类在训练集中一次都未出现过,这样训练的模型永远不会预测出这种分类:
from sklearn.model_selection import train_test_split
train_x, test_x, train_y, test_y = train_test_split(dataSet_feature, dataSet_target, test_size=0.33, random_state=42)
# 这样分类的结果直接就是乱序的,而且已经分好组了
利用pandas进行数据探索
pandas的info()方法可以输出Dataframe的一些总体信息
df.info()

astype()方法可以修改列的类型
df['Churn'] = df['Churn'].astype('int64')
describe()方法可以显示数值的基本统计学特性,
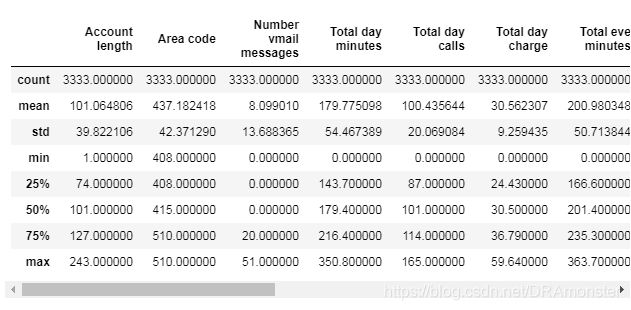
通过显式指定包含的数据类型,可以查看非数值特征的统计数据:
df.describe(include=['object', 'bool'])
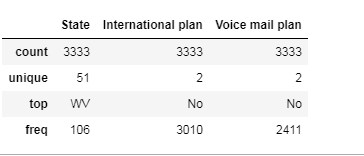
value_counts()可以查看object类型和布尔类型的特征:
df['Churn'].value_counts()

调用 value_counts() 函数时,加上 normalize=True 参数可以显示比例。
df['Churn'].value_counts(normalize=True)

DataFrame可以根据某个变量的值排序,(ascending=False倒序排序)
# 非原地操作
df.sort_values(by='Total day charge', ascending=False).head()
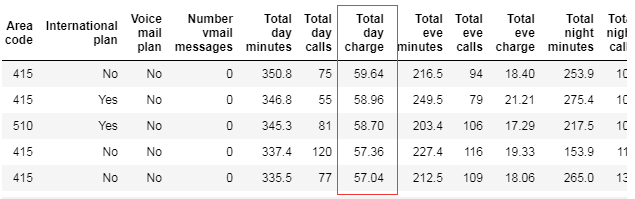
还可以根据多个列的值进行排序。比如先按Churn升序排列,再按Total day charge进行降序排列:
df.sort_values(by=['Churn', 'Total day charge'], ascending=[True, False]).head()
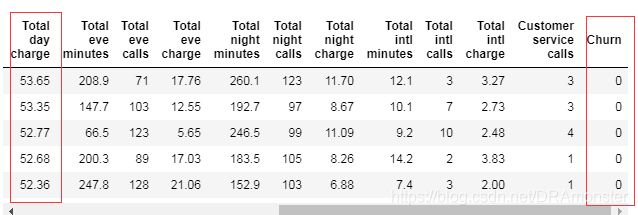
索引和获取数据
布尔索引的使用:
# 布尔索引获得的结果是符合条件的整行数据
df[df['Churn'] == 1].
DataFrame可以通过列名、行名、行号进行索引。loc方法通过行名索引,iloc方法通过数字(行号)索引
df.loc[0:5, 'State':'Area code']
df.iloc[0:5, 0:3]
# df[:1] 和 df[-1:] 可以得到 DataFrame 的首行和末行。
应用函数到单元格、列、行
通过apply方法应用函数至每一列或者每一行(默认是axis=0,跨行;axis=1,跨列)
df[df['State'].apply(lambda state: state[0] == 'W')].head()

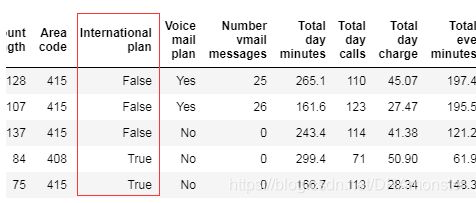
map()方法可以通过字典来替换数据:
d = {'No': False, 'Yes': True}
df['International plan'] = df['International plan'].map(d)
df.head()
replace()方法也可以达到同样的效果:
d = {'No': False, 'Yes': True}
df = df.replace({'Voice mail plan': d})
df.head()

分组(groupby)
# grouping_columns分组依据,
# columns_to_show展现效果的一列,如果没有这一项,则会选择除grouping_columns外的每一列
# function()所要应用的函数
# df.groupby(by=grouping_columns)[columns_to_show].function()
columns_to_show = ['Total day minutes', 'Total eve minutes',
'Total night minutes']
df.groupby(['Churn'])[columns_to_show].describe(percentiles=[])

汇总表
透视表是电子表格程序和其他数据探索软件中一种常见的数据汇总工具。他根据一个或多个键对数据进行聚合,并根据行和列上的分组将数据分配到各个矩阵中。
通过pivot_table()方法可以建立透视表,其参数如下:
- values表示要统计的数据列表
- index表示分组依据列表
- aggfunc表示需要计算哪些统计数据
df.pivot_table(['Total day calls', 'Total eve calls', 'Total night calls'],
['Area code'], aggfunc='mean')
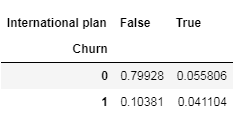
交叉表:是一种用于计算分组频率的特殊透视表,在pandas中使用crosstab()方法构建交叉表
pd.crosstab(df['Churn'], df['International plan'])

pd.crosstab(df['Churn'], df['International plan'], normalize=True)
增减DataFrame的行列
新增列的方法:insert()
total_calls = df['Total day calls'] + df['Total eve calls'] + \
df['Total night calls'] + df['Total intl calls']
# loc 参数是插入 Series 对象的指定列数
df.insert(loc=len(df.columns), column='Total calls', value=total_calls)
df.head()
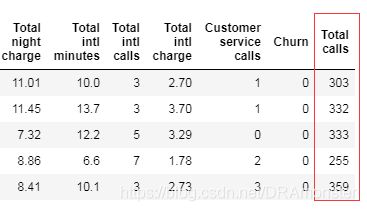
也可采用如下方法直接添加一列:
df['Total charge'] = df['Total day charge'] + df['Total eve charge'] + \
df['Total night charge'] + df['Total intl charge']
df.head()

使用drop()方法删除列和行(默认删除行,axis=1是删除列):
# 移除先前创捷的列
# inplace 参数表示是否修改原始 DataFrame (False 表示不修改现有 DataFrame,返回一个新 DataFrame,True 表示修改当前 DataFrame)。
df.drop(['Total charge', 'Total calls'], axis=1, inplace=True)
# 删除行
df.drop([1, 2]).head()

python数据可视化
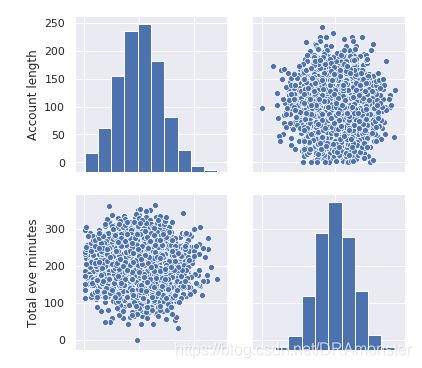
直方图和密度图:
# 设置画布的大小
plt.figure(figsize=(10, 8))
# df是Dataframe型数据
# 绘制直方图
df.hist()
# 密度图(density plots),(也叫核密度图KDE)。可以看做直方图的平滑版本。
df.plot(kind='density')
# 使用seaborn的displot()方法观测数值变量分布,默认情况下,该方法将同时显示直方图和密度图
sns.distplot(df)
箱型图:箱型图的主要组成部分是箱子(box),须(whisker)和一些单独的数据点(离群点),箱子显示了分布的四分位距,它的长度有25th(Q1,下四分位数)和75th(Q3,上四分位)决定。箱中的水平线表示中位数(50%)。须是从箱子中延伸出来的线,他们表示数据点的总体分布,具体而言,是位于区间(Q1-1.5IQR, Q3+1.5IQR)的数据点,其中IQR=Q3-Q1,也就是四分位距。离群值是须之外的数据点,他们作为单独的数据点,沿着中轴绘制。
# 使用seaborn的boxplot()方法绘制箱型图
sns.boxplot(x='column_name', data=df)
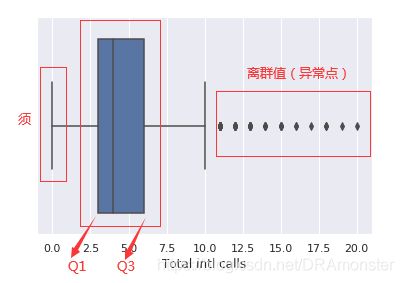
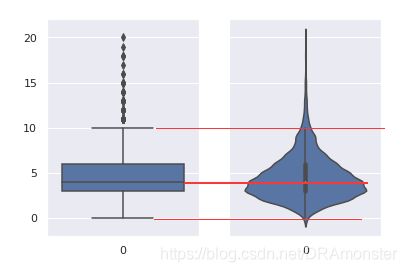
提琴型图(violin plot):提琴型图和箱型图的区别是,提琴型图聚焦于平滑后的整体分布,而箱型图显示了单独样本的特定统计数据。
sns.violinplot(data=df['columns_name'])
类别特征和二元特征
类别特征(categorical features take)反映了样本的所属的类别(category)
频率表:可以使用value_counts()方法获得频率表
条形图:频率表的图形化表示是条形图。
# 创建条形图
sns.countplot(x='column_name', data=df)
条形图和直方图的区别:
- 直方图适合查看数值变量的分布,而条形图用于查看类别特征。
- 直方图的X轴是数值;条形图的X轴可能是任何类型,如数字、字符串、布尔值。
- 直方图的X轴是一个笛卡尔坐标轴;条形图的顺序没有事先定义。
多变量可视化:多变量图形可以再单张图像查看两个以上变量的联系。
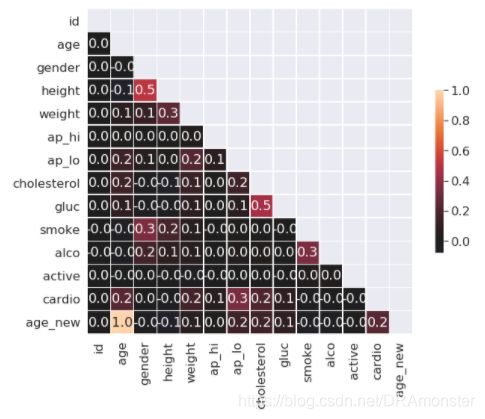
相关矩阵
相关矩阵可揭示数据集中变量的相关性,这一信息很重要,因为一些机器学习算法(比如线性回归和逻辑回归)不能很好地处理高度相关的输入变量。
首先,使用Dataframe的corr()方法计算每对特征间的相关性。接着,将所得的相关矩阵(correlation matrix)传给seaborn的heatmap()方法,该方法根据提供的数值,渲染出一个基于色彩编码的矩阵(热力图)。
# 丢弃非数值变量, 因为相关型矩阵要计算的数值型数据之间的相关性
numerical = list(set(df.columns)-set(['非数值变量']))
# 计算、绘图,在绘制热力图之前首先要进行相关型矩阵的计算
# corr()函数的参数说明:
# method:可选值为:{‘pearson’, ‘kendall’, ‘spearman’}
corr_matrix=df[numerical].corr()
# 创建Mask来隐藏相关矩阵的上三角形
mask = np.zeros_like(corr, dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
# 绘制图形
sns.heatmap(corr, mask=mask,vmax=1,center=0,annot=True,\
fmt='.1f',square=True,linewidths=.5,cbar_kws={'shrink':.5})
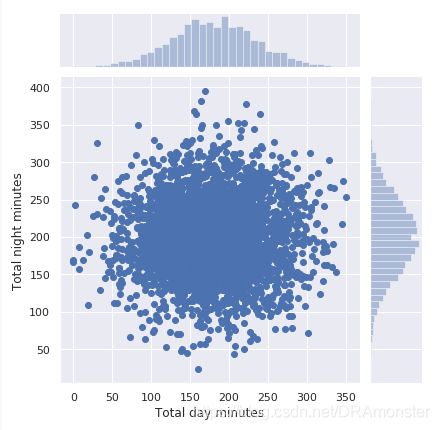
散点图(scatter plot):将两个数值变量的值显示为二维空间中的笛卡尔坐标。
# 绘制散点图
plt.scatter(x,y)
seaborn的jointplot()方法在绘制散点图的同时绘制两张直方图,在某些情形下可能会更有用:
sns.jointplot(x,y,data=df,kind='scatter')
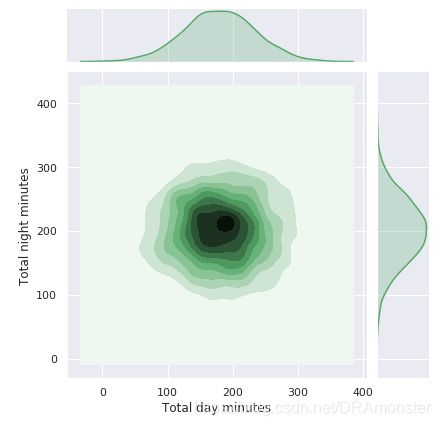
jointplot()方法还可以绘制平滑过的散点直方图。
sns.jointplot(x,y,data=df.kind='kde',color='g')
散点图矩阵(scatterplot matrix):它的对角线包含变量的分布,并且每对变量的散点图填充了矩阵的其余部分。
sns.pairplot(df)

数量和类别:可以尝试从数值和类别特征的相互作用中得到预测Churn的新信息。查看输入变量和目标变量的关系。使用lmplot()方法的hue参数来指定感兴趣的类别特征。
# lmplot在进行二维散点图的绘图时,会自动完成回归拟合fit_reg
sns.lmplot('column_name1', 'column_name2', data=df, hue='Churn', fit_reg=False)

利用箱型图来分析比较重要的分类特征变量
# 有时我们可以将有序变量作为数值变量分析
numerical.append('Customer service calls')
fig, axes = plt.subplots(nrows=3, ncols=4, figsize=(10, 7))
for idx, feat in enumerate(numerical):
ax = axes[int(idx / 4), idx % 4]
sns.boxplot(x='Churn', y=feat, data=df, ax=ax)
ax.set_xlabel('')
ax.set_ylabel(feat)
fig.tight_layout()

当想要一次性分析两个类别维度下的变量时,可以使用seaborn库的catplot函数:
# catplot()函数的参数 ,col指定按哪一列分成子图,height指定图片的宽度, kind指定绘图类型,这里是指定绘制箱型图
sns.catplot(x='Churn', y='Total day minutes', col='Customer service calls',
data=df[df['Customer service calls'] < 8], kind="box",
col_wrap=4, height=3, aspect=.8)

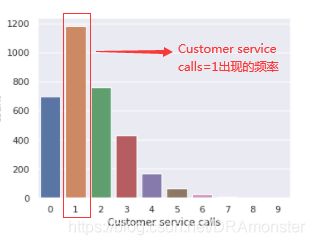
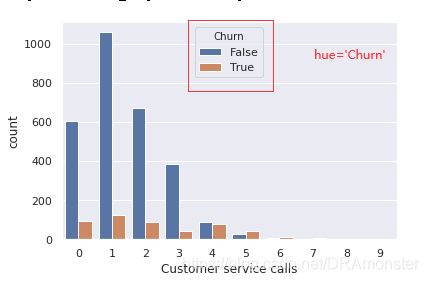
类别与类别:某一变量的重复值很多,因此,即可以看成数值变量,也可以看成有序类别变量,现在感兴趣的是有序特征和目标变量变量之间的关系。使用countplot()方法查看客服呼叫数的分布,再加上hue来区分不同的类别(或者说感兴趣的分类特征):
sns.countplot(x='Customer service calls', hue='Churn', data=df)
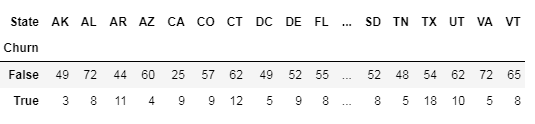
交叉表:
除了使用图形进行类别分析之外,还可以使用统计学的传统工具:交叉表,即使用表格形式表示多个类别变量的频率分布。通过它可以查看某一列或某一行以了解某个变量在另一变量条件下的分布情况:
pd.crosstab(df['column_name1', 'columns_name2']).T
全局数据集可视化数据降维与可视化
上面一直在研究数据集的不同方面(facet),通过猜测有趣的特征并一次选择少量的特征进行可视化。如果想一次性显示所有特征并仍能解释生成可视化,可以采用如下的一些方法。
降维:每一个特征都可以被看成数据空间的一个维度。因此,我们经常需要处理高维数据集,然而可视化整个高维度数据集相当难,因此要在不损失很多数据信息的前提下,降低用于可视化的维度。之一任务成为降维。降维是无监督学习问题,因此它需要在不借助任何监督输入的前提下,从自身数据得到新的低维特征。主成分分析(PCA)是一个著名的降维方法,局限性在于,它是线性算法,这意味着对数据有某些特定的限制。
与现行方法相对的,有许多非线性的方法,统称流行学习,著名的方法之一是t-SNE。
t-SNE:为高维特征空间在二维平面(或三维平面)上寻找一个投影,使得在原本的n维空间中的数据之间的相对距离不变(原来相距较远的现在仍然相距较远)。
在降维之前要进行均值归一化处理:
from sklearn.manifold import TSNE
from sklearn.preprocessing import StandardScaler
# 使用StandardScaler()方法来完成归一化处理
scaler = StandardScaler()
# 除以标准值
# X表示数据集
x_scaled = scaler.fit_transform(X)
# 构建t-SNE表示
tsne = TSNE(random_state=17)
tsne_repr = tene.fit_transform(X_scaled)
# 以图形的方式可视化
plt.scatter(tsne_repr[:, 0], tsne_repr[:, 1], alpha=.5)
t-SNE是目前来说最好的数据降维与可视化方法,但是它的缺点也很明显:计算复杂高,随机种子不同会导致形状大不相同,给解释带来了困难,这种方法可以给我们提供一个思路。但当我们想要对高维数据进行分类,有不清楚这个数据集有没有很好的可分性,可以通过t-SNE投影到二维或三维空间中观察一下。如果在低维空间中具有可分性,则数据是可分的,如果在低维空间中不可分,可能是数据不可分,也可能仅仅是因为不能能投影到低维空间。
TSNE将数据点之间的相似度转化为概率。原始空间中的相似度
seaborn绘图
seaborn将matplotlib参数分成两个独立的组。第一组设定了美学风格,第二组则是不同的度量元素。操作这些参数的接口是两对函数,为了控制样式,使用axesstyle()和setstyle()函数。为了扩展绘图,使用plotting_contex()和set_context()函数。第一个函数返回参数字典,第二个函数则设置matplotlib默认属性。
样式控制:axes_style() and set_style()
有5个seaborn主题:
-
darkgrid 黑色网格(默认)
-
whitegrid 白色网格
-
dark 黑色背景
-
white 白色背景

-
ticks:和white展示出来的效果好像一样
如果想要定制seaborn的样式可以将参数字典传给axes_style()和set_style()的rc参数,只能通过该方法覆盖‘样式定义’一部分参数(更高层次的ste()可以接受任何matplotlib参数的字典)。
通过plotting_context()和set_context()调整绘图元素
首先,可以通过sns.set()重置参数
import seaborn as sns
# 表明通过sns.set()重置参数
sns.set()
# 调整线条粗细(越来越粗):paper,notebook,talk,poster
sns.set_context("paper")
# 使用rc属性来自定义覆盖参数的字典
sns.set_context('notebook', font_scale=1.5, rc={"lines.linewidth": 2.5})
参数scale
参数hue
构建结构化多绘图风格(FaceGrid()、map())
sns.FacetGrid(df, hue='gender',height=12).map(sns.kdeplot,'height')

numpy.meshgrid():生成网格点坐标矩阵
pcolormesh绘制分类图:
# xx表示网格矩阵的x轴,yy表示网格矩阵的y轴,
# plt.pcolormesh()会根据predicted(预测)的结果在cmap中选择颜色
plt.pcolormesh(xx, yy, predicted, cmap='autumn')
数据清洗的思路
- 分类问题的目标值是非数值型,如下是二分类问题(可用如下方法,具体还是根据实际情况分析):
df['goal'].map({'classifi_zero': 0,'classifi_one': 1})
- 检查数据集中变量的数据类型,如果有不对的,要改正
df.dtypes
# 如age的数据类型是object,但它应该是int型的
# 要注意这个操作是非原地操作
df['age'].astype(int)
- 缺失数据的填充,数据一般分为连续特征和离散特征(又叫分类特征),那么不同数据要有不同的填补缺失值得方法,比如离散值可以用众数填充。
# 首先进行不同类型值的区分
categorical_columns = [c for c in df.columns if df[c].dtype.name == object]
numerical_columns = [c for c in data_train.columns if data_train[c].dtype.name != 'object']
# 分类特征用众数填充,连续特征用中位数填补
for i in categorical_columns:
df[i].fillna(df[i].mode, inplace=True)
for i in numerical_columns :
df[i].fillna(df[i].median, inplace=True)
- 对类别特征进行独热编码处理,使得特征变量都变成数值型
# get_dummies 是利用pandas实现one hot encode的方式
df = pd.concat([df[numerical_columns ], pd.get_dummies(df[categorical_columns])], axis=1)