最近在安卓群里看到了一个哥们面试被问Android特有的容器,当时我反问了一下自己这个问题就懵逼了,感觉做了3年的假安卓。后来才发现原来ArrayMap和SparseArray是安卓中特有的,虽然接触过,但关注的确实比较少,正好借这个机会总结一下。
本文会按以下顺序探讨问题,尽量不长篇大论讨论源码,关于这方面写的好的文章网上也很多,努力做到从宏观上关注整体设计思想和各自优缺点
image
Hash表
定义:Hash表/散列表是根据关键码值而直接进行访问的数据结构,它通过关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫散列函数,存放记录的数组叫做散列表。
上面的定义说人话就是,在关键字(key)和表中的存储位置建立一个函数关系,这个函数叫做散列函数/哈希函数。这种映射转换通常是一种压缩映射,因为散列值的空间通常小于输入的空间,不同的输入可能会散列出相同的结果。这种情况称之为哈希冲突。所以两个对象的HashCode有可能相同,当两个对象的内容(eqauls)不同。
散列表解决冲突的方式:
- 开放地址法
- 再散列函数法
- 链地址法
- 公共溢出区法
让我们从以下几点关注HashMap
- 存储结构
- 哈希函数
- 哈希冲突
- 扩容
那让我们通过HashMap源码(Java 7的源码),看看HashMap是如何解决上面几个问题的?还是从put方法开始一探究竟
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);//table为空则初始化
}
if (key == null)
return putForNullKey(value);
int hash = sun.misc.Hashing.singleWordWangJenkinsHash(key);//散列函数-step1
int i = indexFor(hash, table.length);//散列函数-step2
for (HashMapEntry e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
HashMap的初始化和数据结构
table就是散列表,看一下table的实现HashMapEntry。每个数组中存储着一个链表,所以HashMap的存储结构就是数组+链表。在存储数据的时候如果table为空,则初始化。
/**
* Inflates the table.
*/
private void inflateTable(int toSize) {
// Find a power of 2 >= toSize
int capacity = roundUpToPowerOf2(toSize);
// Android-changed: Replace usage of Math.min() here because this method is
// called from the of runtime, at which point the native libraries
// needed by Float.* might not be loaded.
float thresholdFloat = capacity * loadFactor;
if (thresholdFloat > MAXIMUM_CAPACITY + 1) {
thresholdFloat = MAXIMUM_CAPACITY + 1;
}
threshold = (int) thresholdFloat;
table = new HashMapEntry[capacity];
}
roundUpToPowerOf2是为了确保容量为2的n次方,并且是离number值最近的一个2的n次方。
Integer.highestOneBit(number)取出这个值最高位,且把其余位置0。Integer.bitCount(number) > 1判断number是否为2的n次方,如果是bitCount必然为1,不是则再乘2返回。
private static int roundUpToPowerOf2(int number) {
// assert number >= 0 : "number must be non-negative";
int rounded = number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (rounded = Integer.highestOneBit(number)) != 0
? (Integer.bitCount(number) > 1) ? rounded << 1 : rounded
: 1;
return rounded;
}
那么这里就需要注意了,如果在创建HashMap对象的时候调用无参构造方法,创建的数组长度为4。当存储内容超过75%就会触发扩容。所以通常会推荐,尽量预估容器需要的容量,调用有参构造方法。同时因为加载因子的作用,初始长度应为 n / loadFactor (n为预估的长度)
哈希函数
这两行便是HashMap的散列函数,先计算Key的哈希值,在保证这个哈希值不会超过数组的长度。
int hash = sun.misc.Hashing.singleWordWangJenkinsHash(key);
int i = indexFor(hash, table.length);
这里利用了与2的n次方求余可以利用与运算计算的特性,同时初始化、扩容的时候又保证了数组的长度为2的n次方。
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}
碰撞函数
计算出数据该存在在散列表的哪个位置,接下来就该存入数据了。在HashMap中,通过链地址法来解决碰撞问题,也就是说,每个数组中存放的都是一个链表。
看一下最基础的两种线性存储结构,HashMap正是集合了这两种线性存储结构设计出的容器。
| 数据结构 | 优缺点 |
|---|---|
| 顺序表 | 寻址容易,但插入删除开销大 |
| 链表 | 寻址困难,但插入删除开销小 |
扩容
当增加结点的时候,会判断当前散列表的长度,如果容量已经超过75%(默认的增长因子为0.75)。则会进行扩容,新的散列表长度是原先两倍。因为涉及到链表的拷贝,非常消耗性能,这也是为什么建议预估使用容量,调用有参构造方法的原因。
/**
* Transfers all entries from current table to newTable.
*/
void transfer(HashMapEntry[] newTable) {
int newCapacity = newTable.length;
for (HashMapEntry e : table) {
while(null != e) {
HashMapEntry next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
HashMap的版本变化
Java 8中,HashMap最重要的变化是存储结构的变化。由以前的数组+链表变成了数组+链表/红黑树,当冲突结点达到7个或7个以上的时候,会把链表转换为红黑树,然后进行存储。同时由于红黑树比链表的性能更好,即使冲突了查找的时间复杂度为O(logN),所以哈希函数也做了简化。
如果跟面试官聊到了版本变化,你又恰好说出了红黑树,恐怕顺口被问一句红黑树性质也不是什么奇怪的事情把?
那么红黑树有什么性质?
1)每个结点要么是红的,要么是黑的。
2)根结点是黑的。
3)每个叶结点,即空结点(NIL)是黑的。
4)如果一个结点是红的,那么它的俩个儿子都是黑的。
5)对每个结点,从该结点到其子孙结点的所有路径上包含相同数目的黑结点。
SparseArray解析
数据结构
SparseArray通过数组+数组的方式存储数据,不需要开辟内存空间来额外存储外部映射,提高了内存效率。通过二分查找来找对象,执行效率相对于HashMap要慢一点。

public class SparseArray implements Cloneable {
private int[] mKeys;
private Object[] mValues;
//...
public void put(int key, E value) {
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
if (i >= 0) {
mValues[i] = value;
} else {
i = ~i;
if (i < mSize && mValues[i] == DELETED) {
mKeys[i] = key;
mValues[i] = value;
return;
}
if (mGarbage && mSize >= mKeys.length) {
gc();
// Search again because indices may have changed.
i = ~ContainerHelpers.binarySearch(mKeys, mSize, key);
}
mKeys = GrowingArrayUtils.insert(mKeys, mSize, i, key);
mValues = GrowingArrayUtils.insert(mValues, mSize, i, value);
mSize++;
}
}
}
核心就是二分查找
static int binarySearch(int[] array, int size, int value) {
int lo = 0;
int hi = size - 1;
while (lo <= hi) {
final int mid = (lo + hi) >>> 1;
final int midVal = array[mid];
if (midVal < value) {
lo = mid + 1;
} else if (midVal > value) {
hi = mid - 1;
} else {
return mid; // value found
}
}
return ~lo; // value not present
}
ArrayMap解析
ArrayMap中不再存储结点,维护了两个数组,mHashes存放每一项的HashCode,mArray存放键值对。需要注意的一点是,ArrayMap没有实现Serializable接口,而HashMap实现了这个接口。
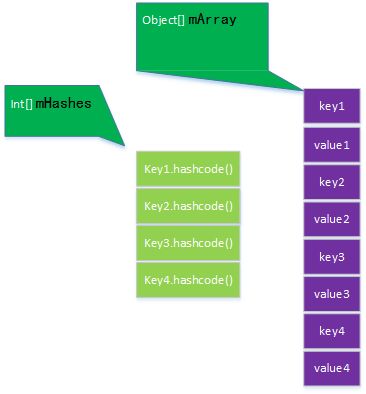
public final class ArrayMap implements Map {
int[] mHashes;//key的hashcode值
Object[] mArray;//key value数组
@Override
public V put(K key, V value) {
final int hash;
int index;
if (key == null) {
hash = 0;
index = indexOfNull();
} else {
hash = mIdentityHashCode ? System.identityHashCode(key) : key.hashCode();
index = indexOf(key, hash);
}
if (index >= 0) {
index = (index<<1) + 1;
final V old = (V)mArray[index];
mArray[index] = value;
return old;
}
index = ~index;
if (mSize >= mHashes.length) {
final int n = mSize >= (BASE_SIZE*2) ? (mSize+(mSize>>1))
: (mSize >= BASE_SIZE ? (BASE_SIZE*2) : BASE_SIZE);
if (DEBUG) Log.d(TAG, "put: grow from " + mHashes.length + " to " + n);
final int[] ohashes = mHashes;
final Object[] oarray = mArray;
allocArrays(n);
if (mHashes.length > 0) {
if (DEBUG) Log.d(TAG, "put: copy 0-" + mSize + " to 0");
System.arraycopy(ohashes, 0, mHashes, 0, ohashes.length);
System.arraycopy(oarray, 0, mArray, 0, oarray.length);
}
freeArrays(ohashes, oarray, mSize);
}
if (index < mSize) {
if (DEBUG) Log.d(TAG, "put: move " + index + "-" + (mSize-index)
+ " to " + (index+1));
System.arraycopy(mHashes, index, mHashes, index + 1, mSize - index);
System.arraycopy(mArray, index << 1, mArray, (index + 1) << 1, (mSize - index) << 1);
}
mHashes[index] = hash;
mArray[index<<1] = key;
mArray[(index<<1)+1] = value;
mSize++;
return null;
}
}
关于如何优化HashMap的一点思考
这个问题印象中也有人面试被问到过,当时我的第一反应是使用的时候尽量估算容量,避免扩容产生的开销。接着思考的方向是如何提高哈希计算的效率或者提高判断的效率,苦思冥想依然没有结果,也没有同行给出答案。这次重新总结3种容器,又想到了这个问题,同时对这个题目也有了新的思考,当然依然没有找到答案。
(每个容器设计出来必然有所取舍,如果改善缺点的同时保留优点,那必然是优化。如果为了改善缺点却摒弃了某些优点,那恐怕就不能称之为优化了。如果抛弃HashMap本身的设计特点,造一个更牛逼的容器,且不说我恐怕没这个造轮子的本事,这也不能叫做优化HashMap了吧)
那么HashMap该如何优化?其实我最初考虑的有些狭隘了,优化完全可以从几个方面入手
- 更友好的接口,使用起来更便捷
- 更高的效率
- 更少的空间
- 更简洁的代码
- 线程安全
- (你一定还能想到更多)
如果还是没有头绪,那么为以上的切入点加上定语再思考一下?
- 特定场景更高的效率
- 特定场景更少的空间
- (你一定还能想到更多)
这样一看是不是更有思路了,ArrayMap和SparseArray就是设计出来在部分场景中取代HashMap,那这些场景是不是正是HashMap可以优化的点呢?
所以这道题在我看来应该回答的是,哪些场景下可以用其他容器取代HashMap提高效率?
参考文档
HashMap,ArrayMap,SparseArray源码分析及性能对比