深度强化学习调度研究的心路历程

获取更多资讯,赶快关注上面的公众号吧!
文章目录
-
- 萌芽
- 开题
- 闭关学习
- 研究源码
- 环境搭建
- 第一篇论文-[基于深度强化学习的模糊作业车间调度问题研究](https://blog.csdn.net/hba646333407/article/details/110046802)
- 想法成熟
- 基于端到端深度强化学习的柔性作业车间调度问题研究
- 基于并行深度强化学习的柔性作业车间两级调度研究
- 写在最后
2021年5月19日,我顺利完成了博士学位论文答辩,之前我已经发布了现场答辩的视频,读博7年期间主要研究如何面向复杂作业车间进行智能调度,公众号有很多粉丝对这个问题也比较感兴趣,有很多私信和留言,其中有的小伙伴也希望让我分享一下我整个研究思路是如何一步一步构建起来的,所以今天我就和大家聊一聊使用深度强化学习求解调度问题的心路历程。
萌芽
2014年我刚到北航时,第一次接触调度问题,那时经常和师兄们交流,听他们讲目前我们自己的调度系统中存在的问题,那时候强调的是计算的快速性和可交互性,对结果的最优性要求不高,使用的主要是一些针对实际问题设计的启发式规则。后来我的师兄们又开始研究在交互约束的基础上使用元启发式算法(禁忌搜素、粒子群等)进行进一步的优化,由此开启了我们实验室的两级调度阶段。我记得很清楚,有一次在去食堂吃饭的路上,听师兄说到计算机领域出现了一种全新的神经网络,可以直接输入图像,而不再和普通的全连接网络那样需要手动设计特征,我当时就瞬间萌生了一种想法,这种网络可不可以用于调度问题求解呢?很简单,只要把调度问题变成一幅图像不就行了吗?当时因为没有具体了解过这种网络,并且也一直在忙项目上的事,这个想法也就抛之脑后了,但也无意间埋下了一颗种子。
开题
从2014年到2018年这四年期间,我基本一直在项目上,对车间的实际调度需求可以说是非常了解了,中间也会忙里偷闲看看论文,学习一些先进的调度方法,导师认为实践和理论上都算是达标了,才同意开题,导师对开题要求非常高,我记得是准备了有一年才成功开题。
2018年初,那时候还没有深度强化学习求解调度的文章,我开题的思路没有太多可以参考的东西,所以主要是从一般强化学习入手,来解决单目标和多目标问题,在最后一章才涉及深度神经网络的泛化问题。2018年下半年,调度领域出现了第一篇使用深度强化学习方法的文章,这一篇文章对我启发很大,那时才意识到开题的很多内容根本不够高级,最后是很难出成果的,所以当时下定决心认真学习深度学习相关理论。
闭关学习
自己本身不是计算机专业,强化学习和深度学习理论基础几乎为0,所以想着有没有一种方式可以更好地逼迫自己学习,于是想到了开通公众号,把自己的学习笔记写成公众号文章,如果读者能读懂,说明也基本算掌握了,由此开启了几个月的闭关学习阶段。
研究源码
随着深度强化学习的迅速发展,在游戏领域中的应用越来越成熟,网络上的资源也越来越丰富,在打牢了理论基础后,我逐步开始研究一些开源项目的代码,进一步加深了解之后,对于后续开展自己的实验研究也更加明朗。
环境搭建
我们自己的调度系统是用Java开发的,但是大多数强化学习代码都是基于Python的,所以我就用Python搭建了一个简易的调度实验环境,这样就和强化学习代理无缝集成了,调度环境是基于析取图模型的,里面也实现了常见的简单规则。
第一篇论文-基于深度强化学习的模糊作业车间调度问题研究
在环境搭建好了之后,就着手开展各种试验,起初也是按照文献方法手动设计调度特征,采用的是当时最火热的DQN算法,但是发现调度结果并不是很好,收敛曲线也不明显,尝试了很多次之后结果仍然很不理想,所以就开始思考问题到底出现在哪呢?后来就和强化学习用于游戏领域的方法进行了对比,算法上应该是没有问题的,所以问题还是应该出现在调度状态,调度动作和调度奖励的设置上,即调度问题向序列决策问题的转化上,首先是调度状态的设计,在游戏领域,通常输入的都是调度图像,调度图像的好处就是可以不用手动设计特征,而是靠卷积神经网络去自动地提取特征,那么,在调动领域,是不是也可以这样去表达?然后突然想起以前就有过这种想法,于是开始思考怎么把调度问题转化为一幅图像。在一般的彩色图像中,一般分为了RGB三个通道,用于表达不同的颜色分量,所以就联想到是不是也可以使用不同的调度信息来表达不同的通道呢?我在第一篇文章中选用了工时信息、调度结果信息和机床利用率信息来构成调度状态,并转换为可视化的图像(实际上,并不是一定需要3层,2层或4层以上都是可以的,这里采用3层的目的仅仅是为了能作为图像可视化同时又不会丢失太多信息)。后来再进行实验时结果就比较理想了。
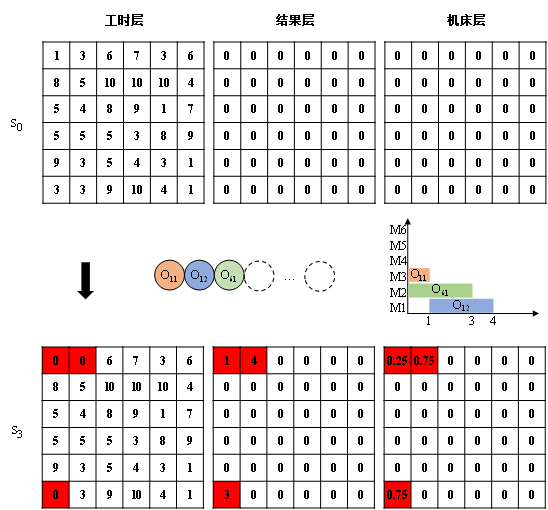
但是一旦采用了这种状态表达方式,也会带来无可避免的弊端,这种调度状态的表达将该方法限制于仅能求解工件数和工序数已知确定的一类调度问题,当这两个参数发生变化时就需要重新训练,怎样训练一个模型,保证在工件数和机床数是任意值的情况下都可用呢?
想法成熟
在出现上述问题后,我开始思考如何解决,以及如何从内容上和逻辑上构成一篇完整的博士论文。第一篇文章解决的是作业车间调度(JSP)问题,采用的是值函数法,但是柔性作业车间在实际中更加普遍,值函数法通常也无法用于连续动作空间问题,所以从问题角度和算法角度都可以进一步研究,就有了以下初步的构思。
这个构思也基本垫定了后续的研究内容。

基于端到端深度强化学习的柔性作业车间调度问题研究
这一章的研究内容得益于深度强化学习在组合优化领域的研究成果,不少学者开始采用端到端的方法,以给定问题实例作为输入,利用训练好的深度神经网络直接输出问题的解,而不再是通过选择启发式规则间接地构造解,具有求解速度快、模型泛化能力强的优势,为组合优化问题的求解提供了一种全新的思路,即输入一个序列输出一个序列,而与序列的长短无关,这种思路正好可以解决第一篇文章中存在的问题啊!
这里的网络也不能采用一般的神经网络结构,而是以循环神经网络为基础的指针网络,同时为了适应调度问题,还需要进行一定的改进,同时采用考虑基线的策略梯度法,具体的细节将在后续专门发文介绍。
这一章采用了端到端的深度强化学习算法求解不同规模的柔性作业作业车间调度问题,虽然该方法具有较强的泛化性,但没有考虑复杂加工车间中普遍存在的班次约束、加班以及工序间平顺物流等约束,而这一系列特征正是实际生产调度中必须考虑的关键因素,同时也是实现主观安排的调整手段,为此如何去考虑人机交互方面的调度呢,或者可不可以把人机交互作为动作去修复调度呢?
基于并行深度强化学习的柔性作业车间两级调度研究
我们实验室原本就是从人机交互调度起家的,系统中考虑了很多种不同的约束,外协、加班、平顺、锁定、合批、分批、机床调整、设置工序里程碑、设置不允许影响,但是调度员在交互调整前并不知道会对调度结果造成什么影响,因此调度员只能通过“试错”的方法不断地交互调整,当调度结果恶化时,会重新尝试新的调整,所以原先的交互效率非常低下。
强化学习本身就是一个不断“试错”的过程,一个自然的想法就是可不可以把重复的“试错”过程交由计算机来代替人工操作,利用计算机来学习结果未知的交互调整,然后给出交互建议呢?答案是肯定的,强化学习代理可以不断尝试这些调整,然后根据给定的目标通过基于先验知识的分派作出评价,当学习结束后,代理就可以给出后验知识,即在当前状态下的最优调整,调度员根据自己的判断和偏好有目的性地进行调整,不管执行的是不是该最优调整,代理在执行调整后仍然会根据新的状态给出新的建议,这样就可以避免调度员盲目性地交互,从而大大提高调度效率。
写在最后
其实在整个研究过程中,有很多想法由于时间关系无法深入的研究,总的来说,车间调度领域还是有很多问题值得研究的。进入企业工作之后才发现,只有在学校里才能静下心来安心的搞研究,所以还是奉劝那些正在吃科研苦的同学,好好珍惜学生这个身份,好好享受科研的自由。