[论文阅读笔记12]MeMOT: Multi-Object Tracking with Memory, 有记忆的MOT算法
MeMOT是CVPR2022的文章, 最大的亮点是存储目标的之前所有帧的信息, 然后把之前所有帧的信息作为跟踪的线索进行编码, 从而实现同时检测与跟踪.
这种方式看似比较暴力, 而且网络的三部分组成都是Transformer结构(但同样也是CNN提取特征). 然而结合之前所有帧信息的思想(也许是想从batch方式借鉴一些, 助力online方式)还是值得思考的.
论文地址: 论文
目前没开源。
还是按文章顺序阅读.
1. Introduction
作者在引言里批评了近期关于Transformer的MOT工作,包括TrackFormer, MOTR等. 他说这些方法把检测跟踪弄在了一起(query-key机制, 查询向量代表已有轨迹与新检测的特征), 但是这种组合导致关联模块在对目标的实时变化进行建模时出现不必要的简化.
这句话的意思是, TrackFormer等方法对目标的实时变化很难在关联模块中体现(只用当前帧的特征), 实际上是为了强调后文用所有时间的特征的重要性.
为了解决这个问题,MeMOT就提出了长效的时空记忆机制,存储被跟踪目标过去所有帧的特征。MeMOT由三部分组成:
- 假设产生模块(Hypothesis Generation Module)
用以特征提取,得到当前帧目标可能的位置区域建议。可见主要是检测功能。用(Deformable)DETR实现。 - 记忆编码模块(Memory Encoding Module)
用以把每个跟踪目标给编码成一个向量,把这个向量叫做tracking embedding。 - 记忆解码模块(Memory Decoding Module)
顾名思义,是最后一个阶段,以假设产生模块的区域建议和记忆编码模块的轨迹特征(tracking embedding)为输入,联合进行匹配。
2. Related Work
在Related Work的最后一部分作者说了也许是灵感的来源,在NLP的时序推理任务,例如对话系统等,就有类似这种memory的工作。动作识别和视频实例分割的任务中也有用额外的memory去存储时序的特征。在近期一些单目标跟踪的算法中也用了memory,然而还没有人将memory用到MOT中去。
下面讲讲每一部分具体是怎么做的。
3. Multi-Object Tracking with Memory
3.1 假设产生 Hypothesis Generation
假设产生模块很简单, 用DETR或Deformable DETR即可. (Deformable) DETR利用CNN提取图像特征, 将其线性映射为二维向量组后输入至Transformer编码器. 在解码器端, 输入的是代表目标的查询向量, 解码器层中与编码器层输出进行交叉注意力计算, 最终输出一堆向量, 每个向量代表了目标特征. 随后对每个向量(目标)的边界框和类别进行预测.
MeMOT将(Deformable) DETR的输出先视作区域建议(region proposals), 记为 Q p r o t ∈ R N p r o t × d \textbf{Q}_{pro}^t\in \mathbb{R}^{N_{pro}^t \times d} Qprot∈RNprot×d, 其中"pro"代表proposal, t t t代表第t帧, N p r o t N_{pro}^t Nprot代表proposal的个数. d d d是特征维数.
这里与Trackor有异曲同工之妙. Trackor利用Faster RCNN可自动学习区域建议的特性, 直接将当前帧的区域建议视为当前帧目标的预测, 和过去的轨迹进行匹配. 所以论文叫"Tracking without bells and whistles", 意为可以利用纯检测器进行跟踪.
MeMOT借鉴它的做法, 把Deformable DETR的输出当做建议了.
3.2 时空存储器 Spatial-Temporal Memory
前文一直在说有个东西要存储轨迹的所有帧特征. 其实不是所有帧, 因为太久远也没有意义, 因此保存部分帧数的特征就可以了. 作者定义了一个FIFO(先入先出)的结构来存储, 记为 X ∈ R N × T × d \textbf{X} \in \mathbb{R}^{N\times T \times d} X∈RN×T×d, 其中 N N N为充分大的多余整个视频目标个数的数, 例如 N = 600 N=600 N=600, T T T为要存储的时间, 例如 T = 24 T=24 T=24.
因此, X \textbf{X} X存储了每个目标在每一帧的特征.
3.3 记忆编码器 Memory Encoding
前文说记忆编码模块要把每个目标编码成向量. 怎么做呢? 现在我们有的东西是Spatial-Temporal Memory里的一堆目标的一堆特征, 怎么转换为每个目标对应一个特定的tracking embedding呢?
作者设计了三个注意力模块:1) 短时block, 用来做相邻帧的注意力, 以平滑噪声; 2) 长时block, 关联很多帧的特征, 来进一步提取特征; 3) 混合(fusion)block, 用来把长短时block的输出混合, 并输出最终的track embedding. 以下分别说明.
1. 短时block
对每个轨迹:
(论文给我的感觉是对每个轨迹单独算)
短时block只关注该轨迹临近 T s T_{s} Ts帧的特征. 具体地, 对当前帧的特征 X t − 1 ∈ R d \textbf{X}^{t-1} \in \mathbb{R}^{d} Xt−1∈Rd和临近 T s T_{s} Ts帧的特征 X t − 1 − T s : t − 1 ∈ R T s × d \textbf{X}^{t-1-T_s:t-1} \in \mathbb{R}^{T_s \times d} Xt−1−Ts:t−1∈RTs×d, X t − 1 \textbf{X}^{t-1} Xt−1作为 Q Q Q, X t − 1 − T s : t − 1 \textbf{X}^{t-1-T_s:t-1} Xt−1−Ts:t−1作为 K , V K,V K,V进行交叉注意力计算.
再计算出每个轨迹的注意力结果后, 将其aggregate起来, 作为短时block的输出, 称作Aggregated Short Term Token, 记作 Q A S T t \textbf{Q}_{AST}^t QASTt.
Q A L T t \textbf{Q}_{ALT}^t QALTt的维度尚不清楚, 论文里没有提示.
2. 长时block
和短时block计算的方式基本一样, 不过长时block拿更多帧的特征进行注意力计算, 假设关注的帧数为 T l T_l Tl, 保证 T l > T s T_l>T_s Tl>Ts. 假设 T l T_l Tl内该目标的特征为 X t − 1 − T l : t − 1 ∈ R T l × d \textbf{X}^{t-1-T_l:t-1} \in \mathbb{R}^{T_l \times d} Xt−1−Tl:t−1∈RTl×d, 和短时block一样, X t − 1 − T l : t − 1 \textbf{X}^{t-1-T_l:t-1} Xt−1−Tl:t−1也是作为交叉注意力的 K , V K,V K,V.
那么 Q Q Q是谁呢?
这里作者用了一个循环结构(类似LSTM和RNN), Q Q Q就是整个Memory Encoding的输出, 也即Track Embedding, 作者起了个新名, 叫做动态记忆聚合token(dynamic memory aggregation token, DMAT), 记作 Q D M A T t − 1 = { q k t − 1 } ∣ k = 1 N ∈ R d × N \textbf{Q}_{DMAT}^{t-1}=\{q_{k}^{t-1}\}|_{k=1}^{N}\in \mathbb{R}^{d\times N} QDMATt−1={qkt−1}∣k=1N∈Rd×N, 其中 N N N为轨迹个数.
因此长时block把 X t − 1 − T l : t − 1 \textbf{X}^{t-1-T_l:t-1} Xt−1−Tl:t−1作为 K , V K,V K,V, 把 Q D M A T t − 1 \textbf{Q}_{DMAT}^{t-1} QDMATt−1作为 Q Q Q, 计算交叉注意力. 同理, 输出也要把每个目标聚合, 记为 Q A L T t \textbf{Q}_{ALT}^t QALTt.
3. 融合模块
随后, 将短时block和长时block的输出 Q A L T t \textbf{Q}_{ALT}^t QALTt, Q A L T t \textbf{Q}_{ALT}^t QALTtconcat在一起, 计算自注意力. 输出的就是tracking embedding, 也就是 Q D M A T t − 1 \textbf{Q}_{DMAT}^{t-1} QDMATt−1, 也就是下一帧的长时block的 Q Q Q矩阵.
编码器模块如下图所示.
![[论文阅读笔记12]MeMOT: Multi-Object Tracking with Memory, 有记忆的MOT算法_第1张图片](http://img.e-com-net.com/image/info8/f45854858e6a412e937ccf91436a06da.jpg)
消融实验中, 关于长时短时的 T T T的选择影响如下图:
![[论文阅读笔记12]MeMOT: Multi-Object Tracking with Memory, 有记忆的MOT算法_第2张图片](http://img.e-com-net.com/image/info8/dd57ccf99cd943cdb0855fe78973677e.jpg)
\space
3.4 记忆解码器 Memory Decoding
前面我们根据(Deformable) DETR得到了区域建议 Q p r o t \textbf{Q}_{pro}^t Qprot, 根据记忆编码器得到了tracking embedding, 记为 Q t c k t \textbf{Q}_{tck}^t Qtckt.
实际上 Q t c k t \textbf{Q}_{tck}^t Qtckt和 Q D M A T t \textbf{Q}_{DMAT}^t QDMATt应该是一个东西.
我们将 [ Q p r o t , Q t c k t ] [\textbf{Q}_{pro}^t, \textbf{Q}_{tck}^t] [Qprot,Qtckt]作为解码器的 Q Q Q, 把图像特征 z t ∈ R d × H W z_t\in \mathbb{R}^{d\times HW} zt∈Rd×HW作为解码器的 K , V K,V K,V, 进行交叉注意力计算. 假设解码器的输出为 [ Q ^ p r o t , Q ^ t c k t ] [\hat{\textbf{Q}}_{pro}^t, \hat{\textbf{Q}}_{tck}^t] [Q^prot,Q^tckt]
记忆解码器的输出是什么呢? 不同于以往的一些方法, 它不仅输出对目标位置的估计和置信度, 而且输出对目标遮挡程度估计的一个概率.
文中把衡量遮挡程度的score称为objectness score, 把置信度的score称为uniqueness score, 第i个目标在第t帧的两种score分别以 o i t , u i t o_i^t, u_i^t oit,uit表示.
文章定义了最终的置信度, 就是objectness score和uniqueness score的乘积:
s i t = o i t u i t s_i^t=o_i^t u_i^t sit=oituit
因此对解码器的输出的预测结果就是两种置信度加位置. 对于输入 Q ^ p r o t \hat{\textbf{Q}}_{pro}^t Q^prot, 输出的置信度为 S p r o t \textbf{S}_{pro}^t Sprot, 同理对于输入 Q ^ t c k t \hat{\textbf{Q}}_{tck}^t Q^tckt输出的置信度为 S t c k t \textbf{S}_{tck}^t Stckt. 对每个目标都预测bbox b i t ∈ R 4 \textbf{b}_i^t\in\mathbb{R}^{4} bit∈R4.
和TrackFormer等算法一样,是对两部分输入对应的输出分别处理的.
那么关键问题是这样定义新置信度有什么用呢?
作者说了两点.
- 在推理阶段, 筛选跟踪检测的置信度就考虑 s i t ≥ ϵ s_i^t\ge\epsilon sit≥ϵ.
- 真值置信度的分配. 对已有轨迹 Q ^ t c k t \hat{\textbf{Q}}_{tck}^t Q^tckt分配objectness score, 然后对假设产生模块的建议 Q ^ p r o t \hat{\textbf{Q}}_{pro}^t Q^prot分配uniqueness score, 注意假设产生模块的输出不仅仅是新目标, 也有旧轨迹. 用二部图匹配把proposal和所有的输出向量匹配. 分配真值置信度的说明如下图:
![[论文阅读笔记12]MeMOT: Multi-Object Tracking with Memory, 有记忆的MOT算法_第3张图片](http://img.e-com-net.com/image/info8/ba431801295a4f5aa2e31059ffe9ccd2.jpg)
3.5 损失函数
整体的损失函数与MOTR中的相似, 对每个track query的损失都计算, 并且求平均.
![[论文阅读笔记12]MeMOT: Multi-Object Tracking with Memory, 有记忆的MOT算法_第4张图片](http://img.e-com-net.com/image/info8/cb26abe5d12143108ba4d6ec2f195145.jpg)
L t c k i , t L_{tck}^{i,t} Ltcki,t表示第 i i i个目标在第 t t t帧的跟踪损失, 定义为:
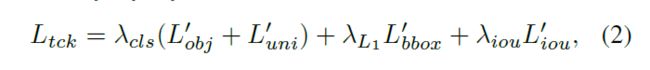
其中 L o b j ′ L_{obj}' Lobj′和 L u n i ′ L_{uni}' Luni′是对objectness score和uniqueness score置信度的focal loss, bbox就是L1 loss, iou就是广义IoU损失.
同理 L d e t j , t L_{det}^{j,t} Ldetj,t表示第 j j j个目标在第 t t t帧的跟踪损失, 定义为:
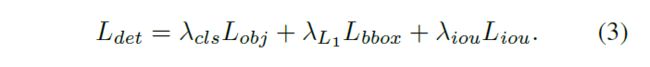
Note, 这个损失在计算时, 作者加了一个额外的线性解码层, 来对假设生成模块输出的proposals
投影成置信度和bbox(也就是相当于又单独算了个(Deformable)DETR的损失).
4. 评价
该方法的可取之处在于有意识地使用了过去很多帧的信息去算注意力, 相当于暴力地让模型融合很多帧的信息.
但是它用了太多的注意力结构, 在8块A100上训练的. 可见模型是过于复杂, 而且效果不如FairMOT一类.
疑惑之处是, 提出了两种score, 尤其是代表visible的score很有新意, 可是我没看懂除了在计算新一种的置信度和往loss里增加了一项之外, 它还起了哪些作用. 既然可以预测visible程度, 我觉得还是可以进一步研究用处, 比如对预测目标visible程度低的用低阈值匹配, 而对于visible程度高的用高阈值匹配. 这样相较于用全局低阈值匹配(例如ByteTrack), 可以减少FP.