Yolov5代码/源码 技巧,训练方法分析
前言
yolov5在yolov4推出的一个月后就出现,且没有论文,很多理念和yolov4相同。
笔者春节假期有时间,把yolov4的论文和yolov5的源码学习了一下,不涉及分布训练的部分,欢迎交流讨论
混合精度运算
with torch.cuda.amp.autocast(amp):
pred = model(imgs) # forward
# print(targets)
print(pred[0].shape, pred[1].shape, pred[2].shape)
loss, loss_items = compute_loss(pred, targets.to(device)) # loss scaled by batch_size
if RANK != -1:
loss *= WORLD_SIZE # gradient averaged between devices in DDP mode
if opt.quad:
loss *= 4.
前向传播使用torch提供的混合精度求导函数包装。
注意使用混合精度运算会更快,但不知道为什么同样的batch使用的显存更多需要适度减少batch,但总体来说更快
注意: 混合精度运算存在bug,在forward时某些运算会导致结果出现nan,可能是fp16出现上溢,见pytorch混合精度训练,解决方案是把某些变量固定为fp32(使用嵌套autograd)
建议: 线性回归别用混合精度了
新学到的技巧,当混合精度训练出现nan时,累计梯度可以弥补精度不够的缺憾
Conv2d groups属性
nn.Conv2d
groups字段指定是否卷积核分开吃输入的channels
当gropus=in channels时,每个卷积核的out channel为 out_channels in_channels \frac{\text{out\_channels}}{\text{in\_channels}} in_channelsout_channels
)
YOLOv5中使用多线程函数(from multiprocessing.pool import ThreadPool)加快存储的进程

还有一招是把图片存储为.npy格式(体积增大十倍左右,存在disk中,据说可以加快加载速度)
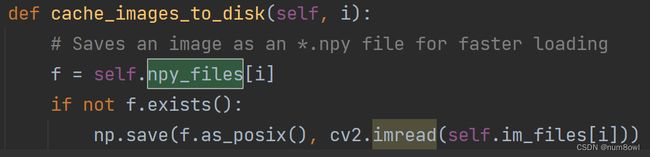
最终还是要加载到内存/虚拟内存中(脱裤子放屁,不学)
结论:load npy比load png快了但是不完全快
实验:load2000次 700x990x3 的数据 差了3s左右

与增加的磁盘占用相比得不偿失
随机Mosaic,MixUp数据增强 或 图片缩放
yolov5由一个参数阈值随机决定当前数据是进行mosaic+mixup的组合拳还是只进行图片缩放

最终都要经过上下翻转,左右翻转,颜色空间变换等操作

用yaml文件创建网络
主要语句

![]()
在forward中
![]()
glob文件查找
f += glob.glob(str(p / '**' / '*.*'), recursive=True)
DataLoader中的collate_fn参数
map-style风格的数据:内部使用__getitem__() ,和__len__()实现迭代产生数据 如自定义的dataset类
Iterable-style风格的数据:内部使用__iter__() 产生数据
当数据无法使用dataloader直接整合时(map-style风格的数据),例如出现,类别标签数量不一致无法堆叠等问题,使用collate_fn传入一个 callback函数处理使它整合成mini-batch, yolov5的code中使用collate_fn4将传入的数据再次堆叠。
其他
-
如果pin_memory=True的话,将数据放入GPU的时候,把non_blocking = True,这样就只把数据放入GPU而不取出,访问时间会大大减少

-
warm up 刚开始训练时,模型权重(weights)是随机初始化的,此时若选择一个较大的学习率,可能带来模型的不稳定,选择 Warmup 预热学习率的方式,可以使得开始训练的几个 epochs 或者一些 steps 内学习率较小,在预热的小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后在选择预先设置的学习率进行训练,使得模型收敛速度变得更快,模型效果更佳。
-
迭代器知识,Dataloader装载dataset后,迭代完就需要重新装载数据到内存(或是其他什么地方)耗费时间,yolov5使用自定义的包装类重新包装Dataloader使它成为一个无限迭代器,这样在训练时就无需每个epoch重新装载,节省大量时间。
class _RepeatSampler def __init__(self, sampler): self.sampler = sampler def __iter__(self): while True: yield from iter(self.sampler) class InfiniteDataLoader(DataLoader): def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) object.__setattr__(self, 'batch_sampler', _RepeatSampler(self.batch_sampler)) self.iterator = super().__iter__() def __len__(self): return len(self.batch_sampler.sampler) def __iter__(self): for _ in range(len(self)): yield next(self.iterator)torch自带的Dataloader作为迭代器可以重复使用(如用for迭代)但是每个epoch都要耗费重新装载的时间
使用tqdm包装时,如果只初始化一次tqdm(pbar = tqdm(Dataloader()) ),得到的迭代器pbar无法重复使用,在迭代完一次后,需要重新初始化tqdm否则pbar为空,同样的重新装载tqdm同样耗费时间。
yolov5使用包装类构造的无限迭代器在初始化时耗费较长时间,但一旦初始化完成使用包装类构造的迭代器无需重新装载,因为他本质上还处于一次迭代中,但该迭代器占用的内存也显著增加。
yolov5的代码真的屎山