第06期:Prometheus 存储

Description: 本文是介绍了Prometheus的两种储存类型和本地存储的原理
Author: 孙健,爱可生上海研发中心成员,研发工程师
一、前言
Prometheus 提供了本地存储,本文主要讲述 Prometheus 自带的 tsdb 时序数据库。
二、本地存储(tsdb)
1. 什么是时序数据库
时序数据库全称为时间序列数据库。时间序列数据库主要用于指处理带时间标签(按照时间的顺序变化,即时间序列化)的数据,带时间标签的数据也称为时间序列数据。主要用于存储周期性的采集各种实时监控信息。
2. 特点
- 垂直写,水平读

- 数据点写入分散,且数据量巨大
- 热点数据明显
3.存储配置
--storage.tsdb.path:数据存储目录。默认为 data/。--storage.tsdb.retention.time:数据过期清理时间。默认为15天。--storage.tsdb.wal-compression:此标志启用预写日志(WAL)的压缩。根据您的数据,您可以预期WAL大小将减少一半,而额外的CPU负载却很少。此标志在2.11.0中引入,默认情况下在2.20.0中启用。请注意,一旦启用,将Prometheus降级到2.11.0以下的版本将需要删除WAL。
4.目录结构
首先,block 在这里是一个数据块,每个数据块相对独立,由一个目录组成,该目录里包含:一个或者多个 chunk 文件(保存 timeseries 数据)、一个 metadata文件、一个 index 文件(通过 metric name 和 labels 查找 timeseries 数据在 chunk 文件的位置)。
./data
├── 01BKGV7JBM69T2G1BGBGM6KB12
│ └── meta.json
├── 01BKGTZQ1SYQJTR4PB43C8PD98
│ ├── chunks
│ │ └── 000001
│ ├── tombstones
│ ├── index
│ └── meta.json
├── 01BKGTZQ1HHWHV8FBJXW1Y3W0K
│ └── meta.json
├── 01BKGV7JC0RY8A6MACW02A2PJD
│ ├── chunks
│ │ └── 000001
│ ├── tombstones
│ ├── index
│ └── meta.json
└── wal
├── 00000002
└── checkpoint.000001
5.储存原理(write)
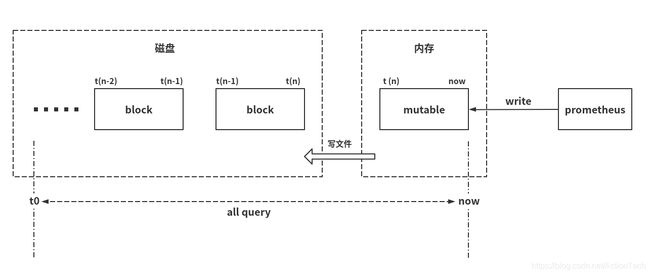
Prometheus 按2小时一个 block 进行存储,最新写入的数据保存在内存 block 中,达到2小时后写入磁盘。为了防止程序崩溃导致数据丢失,实现了 WAL(write-ahead-log)机制,启动时会以写入日志(WAL)的方式来实现重播,从而恢复数据。
这种水平分区增加了一些优势:
- 查询时间范围时,我们可以轻松忽略该范围之外的所有数据块。只需要读取时间范围内的 block 数据;
- 当完成一个块时,我们可以通过顺序写入一些较大的文件来保留内存数据库中的数据,避免随机带来的写放大;
- 最近 2 小时的数据放在内存,使得查询最多的数据始终缓存在内存中;
- 删除旧数据的开销很小,只需要删除一个目录。
6.mmap(read)
使用 mmap 读取压缩和合并的大文件(不占用过多的句柄),建立进程虚拟地址和文件偏移量之间的映射关系,并且仅在查询和读取相应位置时才将数据读入物理内存。 绕过文件系统页面缓存,减少一个数据副本。 查询结束后,Linux 系统会根据内存压力自动回收相应的内存,并可在回收之前将其用于下一个查询命中。 因此,使用 mmap 自动管理查询所需的内存缓存的优点是管理简单且处理效率高。
7.索引
一般 Prometheus 的查询是把 metric + label 做关键字的,而且是很宽泛,完全用户自定义的字符,因此没办法使用常规的 sql 数据库,Prometheus 的存储层使用了全文检索中的 倒排索引【文末链接】概念,将每个时间序列视为一个小文档。而 metric 和 label 对应的是文档中的单词。
例如,requests_total{path="/status", method=“GET”, instance=“10.0.0.1:80”}是包含以下单词的文档:
- name=“requests_total”
- path="/status"
- method=“GET”
- instance=“10.0.0.1:80”
提示:由于 Prometheus 索引定义很宽泛,label 会作为索引,官方不建议将 label 定义为动态的值,会导致索引的文件大小变大。
8.数据压缩
数据压缩的主要操作包括合并 block、删除过期数据、重构 chunk 数据。其中合并多个 block 成为更大的 block,可以有效减少 block 个数,当查询覆盖的时间范围较长时,避免需要合并很多 block 的查询结果。为提高删除效率,删除时序数据时,会记录删除的位置,并不会立即从 chunk 文件删除,而是将删除的记录先记录在 block 目录下的 tombstone 文件中,只有 block 所有数据都需要删除时,才将 block 整个目录删除。因此 block 合并的大小也需要进行限制,避免保留了过多已删除空间(额外的空间占用)。比较好的方法是根据数据保留时长,按百分比(如10%)计算 block 的最大时长。
三、远程存储
Prometheus 的本地存储在可伸缩性和持久性方面受到单个节点的限制。Prometheus 并没有尝试从本地存储中解决这个问题,而是提供了一组允许与远程存储系统集成的接口。
Prometheus 通过两种方式与远程存储系统集成:
- Prometheus 可以将提取的样本以标准格式写入远程 URL。
- Prometheus 可以以标准化格式从远程 URL 读取(返回)样本数据。

读取和写入协议都使用基于HTTP的快速压缩协议缓冲区编码。该协议尚未被认为是稳定的 API,当可以安全地假定 Prometheus 和远程存储之间的所有跃点都支持 HTTP / 2 时,该协议将来可能会更改为在 HTTP / 2 上使用gRPC。
四、参考
-
https://fabxc.org/tsdb/
-
https://prometheus.io/docs/prometheus/latest/storage/
-
https://docs.google.com/presentation/d/1TMvzwdaS8Vw9MtscI9ehDyiMngII8iB_Z5D4QW4U4ho
-
倒排索引:https://nlp.stanford.edu/IR-book/html/htmledition/a-first-take-at-building-an-inverted-index-1.html)
相关内容方面的知识,大家还有什么疑问或者想知道的吗?赶紧留言告诉小编吧!
