linux环境下,基于机器学习算法 KNN 的 MPI 并行分类器
目录
- 1.题目
- 2.使用说明
- 3.总体设计
- 4.使用到的MPI库函数
- 5.详细设计
- 6.结果分析
- 7.源码
1.题目
基于KNN算法的分类器
假如你有一个朋友一直使用在线约会网站寻找合适自己的约会对象。尽管约会网站会推荐不同的人选,但她没有从中找到喜欢的人。经过一番总结,她发现曾交往过三种类型的人:
1、不喜欢的人
2、喜欢的人
3、很喜欢的人
尽管发现了上述规律,你的朋友依然无法将约会网站推荐的匹配对象归入恰当的分类。朋友希望我们的分类软件可以更好的帮助她将匹配对象划分到确切的分类中。根据她的要求,收集了多条数据,数据包含三个特征(每年获得的飞行常客里程数,玩视频游戏所耗时间百分比,每周消费的冰淇淋公升数),而标签类型为:1代表“不喜欢的人”,2代表“喜欢的人”,3代表“很喜欢的人”。
2.使用说明
该程序在Linux的MPI并行环境下运行,在运行之前应此运行环境搭建好,然后把测试集数据ceshi.txt、训练集数据xunlian.txt、存放程序结果数据result.txt、源代码knn.c这四个文件放在同一个文件夹下。若是在集群环境下运行,则需要再增加mpi_config配置文件,并把里面的IP地址修改为集群各个主机的IP地址。
接着使用mpicc knn.c -lm -o knn编译,然后使用mpiexec -n N knn运行,其中N为进程个数,大于等于5小于等于100,且能整除5、被100整除。若是在集群环境下运行,则使用命令mpiexec -n N -f mpi_config knn,运行的结果保存到result.txt文件,控制台显示的则是各个进程所处的主机名、验证集错误个数、验证集错误率以及运行时间。
3.总体设计
首先进程0、1、2分别读入所需要的数据,包括训练集、测试机、验证集(如果需要验证的话),接着需要广播训练数集、分发测试集、验证集,之后需要找出各个进程拥有的数据的最值,然后通过规约函数找到所有进程的最值,并发给每个进程。然后需要通过最值归一化各个数据集,再计算它们的欧式距离、根据欧式距离从大到小进行排序、根据KNN算法的K值逐个计算出测试数据的所属类别,再通过聚合函数聚集每个进程所计算的结果,验证集的计算依照的也是此流程。最后再将测试集计算结果往文件输出即可,同时通过终端会输出显示验证集的错误率。
4.使用到的MPI库函数
4.1、MPI_Init(intargc, char argv[]),用于初始化MPI;
4.2、MPI_Comm_rank(MPI_Comm comm, int rank),获取本进程ID;
4.3、MPI_Comm_size(MPI_Comm comm, int size),获取进程个数size;
4.4、MPI_Wtime(),返回墙上时间,用于计算程序运行时间;
4.5、MPI_Abort(MPI_Comm comm, int errorcode),终止MPI程序,并返回errorcode;
4.6、MPI_Bcast(void* buffer, int count, MPI_Datatype datatype, int root, MPI_Comm comm),通过进程号为root广播数据;
4.7、MPI_Scatter(void* send_data, int send_count, MPI_Datatype send_datatype, void* recv_data, int recv_count, MPI_Datatype recv_datatype, int root, MPI_Comm comm),用于分发数据;
4.8、MPI_Allreduce(void* send_data, void* recv_data, int count, MPI_Datatype datatype, MPI_Op op, MPI_Comm comm),在计算归约的基础上,将结果分发到每一个进程;
4.9、MPI_Gather(void* send_data, int send_count, MPI_Datatype send_datatype, void* recv_data, int recv_count, MPI_Datatype recv_datatype, int root, MPI_Comm comm),将通信子中的指定数据集中到root进程;
4.10、MPI_Barrier(MPI_Comm comm),用于一个通信子中所有进程的同步,调用函数时进程将处于等待状态,直到通信子中所有进程 都调用了该函数后才继续执行;
4.11、MPI_Finalize(),释放MPI资源。
5.详细设计
首先利用宏定义各个常量,然后下面逐个介绍在本程序中自定义的函数:
5.1、void Read(char* filename, int number, int dim, int* category, double* dataSet):读文件函数,形参分别为文件名、样本点个数、样本点维度、样本所属类别、样本数据集。利用fopen函数以读的方式打开文件,若出错则立即退出程序。打开完成后设置完全缓存模式,根据样本个数以及样本维度利用fscanf函数逐个读取数据并存到dataSet,catogory,其中两者读取的类型分别为double和int型,读取完成后利用fclose函数关闭文件。
5.2、void Write(int* result):写入文件函数,形参为要写进文件的数据。基本流程同上方的读文件函数一样,只不过是把fscanf替换成fprintf函数。
5.3、void FindMinMaxValue(int num, double* minValue, double* maxValue, double* data):在训练集/测试集中找出最值,形参分别为样本点个数、存储测试/训练数据集最小、最大值数组、训练/测试数据集。根据样本点个数num以及样本点维度利用两层循环逐个查找出data里面的最值并分别将三个维度中的最大、最小值保存到maxValue、minValue。
5.4、void FindMinMaxValueOfAll(double* xunlian_min, double* xunlian_max, double* ceshi_min, double* ceshi_max, double* min, double* max),通过对比在训练集、测试集中的最值找出最终的最值,形参分别为训练数据集最值、测试数据集最值、最终的最值。根据样本点的维度逐个对比训练集、测试集中的数据的最值并将最终的最值分别放到min、max数组里面。
5.5、void GuiYiData(int number, double* data, double* dataGuiyi, double* minValueOfAll, double* maxValueOfAll),归一化训练集/测试集数据,形参分别为样本点个数、要归一化的数据、归一后的数据、最小最大值。循环里面根据样本点个数以及样本点维度逐个归一化数据,通过(要归一的数据-最小值)/(最大值-最小值)这一公式进行归一化操作并将结果存放到dataGuiyi对应的位置。
5.6、void CalEuclidDistance(double* xunlianDataGuiyi, double* ceshiDataGuiyi, double* euclidDistance, int num),计算测试/验证集和训练集的样本点之间的欧式距离,形参分别为归一化后训练数据、归一化后的测试数据、欧式距离、样本点个数。同样地循环里面根据样本点个数以及样本点维度逐个计算欧式距离,通过测试集/验证集的各个维度的数据减去对应的训练集数据的平方和再开方这一公式逐个计算他们之间的欧式距离并将全部结果存放到数组eucliDistance对应的位置,其中数组eucliDistance以XUNLIANNUM(训练集样本点个数)为一组,共有CESHINUM(测试集样本点个数)/YANZHENGNUM(验证集样本点个数)组进行存储。
5.7、void QuikSort(double* euclidDistance, int* category, int left, int right),快速排序算法,形参分别为要排序的欧式距离数组、所属类别、数组左边界、数组右边界。在本例子中是将数组从小到大进行排序,其基本思想是以左边界的值为基准,首先从后往前查找比基准小的值,然后交换它们的位置;否则继续向前查找。然后从前往后查找,找到比基准值大的值则交换位置,否则继续向后查找。经过此轮之后数组左边的都比基准值小,而右边的比它大,再利用递归利用同样的方法即可进行排序。
5.8、void SortEuclidDistance(double* euclidDistance, int* category, int num),利用快速排序算法对计算的欧式距离进行排序,注意:根欧式距离存储的特性,这里是以XUNLIANNUM为一组逐一进行快速排序,形参分别为欧式距离、所属类别、样本点个数。
5.9、void CalResult(int* categoryOfAll, int* result, int num),根据KNN算法的K值逐个计算出数据的所属类别,形参分别为要计算的数据的所属类别(是每个样本点根据欧式距离排序之后的对应类别)、存放结果数组、结果数组的大小。根据要归类的数据的个数以及K值,统计前K个里面的各个类别的个数,最后再比较它们的大小即可的出该样本属于哪一类并将结果保存到result数组。
5.10、int main(int argc, char* argv[]),主函数。首先需要利用MPI_Init函数对MPI初始化,然后利用MPI_Wtime记录当前时间,用于计算程序运行时间,接着MPI_Comm_rank获取当前进程ID、MPI_Comm_size获取总进程数。根据进程个数判断训练集、测试集、验证集是否可以被平均分配。如果不可以,则利用MPI_Abort退出程序;否则进行接下来的计算。接下来是一大堆变量的声明,这里就不再一一赘述。然后分别利用进程0、1、2通过Read函数读入训练集、测试集、验证集(如果需要验证的话)。
之后利用0号进程利用MPI_Bcast将训练集广播给其他进程、1号进程利用MPI_Scatter分发测试集。若常量ISYANZHNG为1,则继续利用该函数分发验证集数据。之后各个进程通过FindMinMaxValue函数分别找到训练集、测试集的最值,然后利用MPI_Allreduce规约函数求得最终的最大最小值并分发给每个进程。接着各个进程就可以利用求得的最值通过函数GuiYiData对数据集进行归一处理,紧接着就是通过CalEuclidDistance函数计算测试集和训练集之间的欧式距离并通过SortEucliDistance对计算的欧式距离从小到大进行排序,再利用CalResult函数即可得到测试集数据的所属类别,再通过MPI_Gather聚集函数将各个进程的结果收集并放到1号进程。
验证集的计算和上面的步骤基本一致,这里就不再赘述。然后1进程通过Write函数将计算测试集所得结果往文件result.txt输出即可。至于验证集的结果,逐个对比计算结果同正确结果之间的数据就可以计算出在K的情况下计算的错误率了。再通过free函数逐个释放分配的数组空间,再将其指空防止出现野指针即可,最后再利用MPI_Wtime获取当前时间并减去开始时间就可以获得程序运行时间了。
6.结果分析
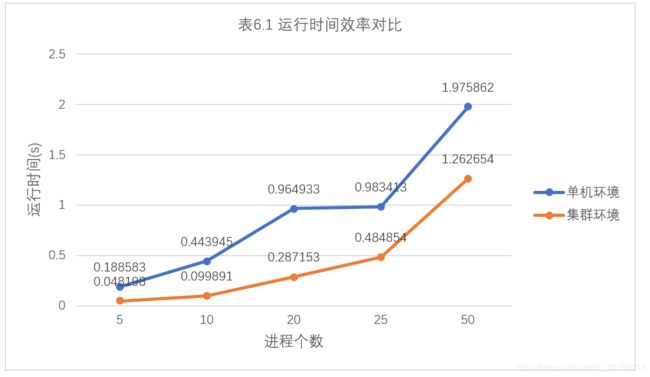
分析下表6.1(表中数据均是由计算多次取它们平均值得出)容易得出,无论是在何种情况,集群运行环境的运行时间效率都是明显优于单击运行环境的;且无论哪个运行环境,可以看到运行时间都是随着进程数的增多而增加,这主要是由于进程间通信也要消耗一部分的时间,所以在进行高性能计算时应该考虑该因素,在两者之间做平衡。
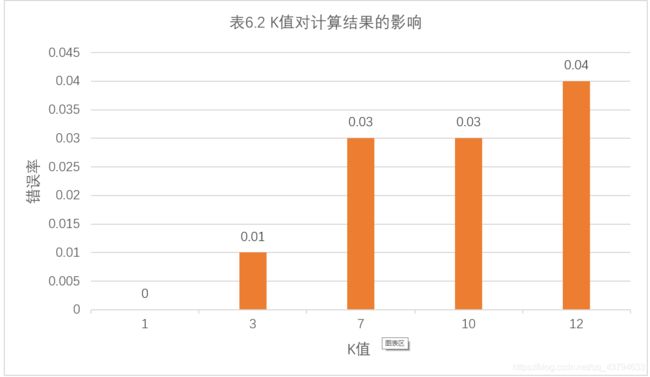
对于KNN算法,K的取值对计算结果影响很大。看下表6.2可以得出,在测试的5个K值中,K取0时错误率为0,在取12时达到0.04,且随着K值得增大,错误率呈攀升的趋势。当然,在不同的例子中K的取值会有不同的结果。
7.源码
https://github.com/zhuhezhang/parallel-KNN-algorithm
https://gitee.com/zhuhezhang/parallel-KNN-algorithm