CV 计算机视觉 常见网络 总结 应付面试版
文章目录
- AlexNet
- VGG
- GoogLeNet
- ResNet
- ResNeXt
- MobileNet
-
- MobileNet V1
- MobileNet V2
- MobileNet V3
- ShuffleNet
-
- ShuffleNet V1
- ShuffleNet V2
- EfficientNet
-
- EfficientNet V1
- EfficientNet V2
AlexNet
1、GPU加速、ReLu、LRN(局部响应归一化)、FC前两层Dropout
2、conv1 + max pooling1 +conv2 + max pooling2+ conv3 + conv 4 + conv5 + max pooling3 + FC1 + FC2 +FC3
VGG
1、多个3*3卷积核代替大尺度卷积核
2、网络D包含16个隐藏层的叫VGG-16;网络D包含19个隐藏层的叫VGG-19
3、感受野:feature map 上的一个单元对应输入层区域的大小GoogLeNet
GoogLeNet

1、Inception结构,用于融合不同尺寸的特征信息;
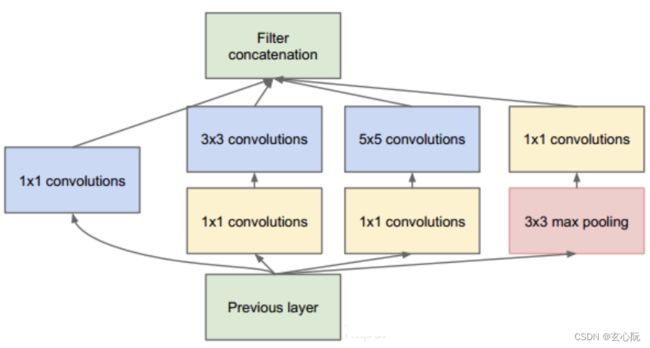
2、1×1的卷积核进行降维以及映射处理;
3、两个辅助分类器帮助训练


4、丢弃FC,使用average pooling,大大减少模型参数;
5、并行化
ResNet

1、网络结构可以突破1000层
2、提出risidual模块,通过add操作将特征合并

Concat与add的区别:
Concat:张量拼接,会扩充两个张量的维度,例如2626256和2626512两个张量拼接,结果是2626768。
add:张量相加,张量直接相加,不会扩充维度。例如104104128和104104128相加,结果还是104104128。add和cfg文件中的shortcut功能一样。
3、丢弃dropout,使用BN加速训练
4、解决梯度消失、梯度爆炸、退化问题
5、BN目的是使得同一通道的feature map满足均值为0,方差为1的分布规律。通常放在卷积层激活层之间
ResNeXt

1、ResNeXt中堆叠的模块本质就是就是采用分组卷积的residual模块
2、ResNet与Inception的结合体
3、residual模块的通道数要比ResNet多

ResNeXt论文中首先提出的是上图中(a)的形式,通过一系列等价变换,最终可以得到如图(c )所示分组卷积的形式
MobileNet
MobileNet V1
1、采用Depthwise Separable Convolution,减少运算量参数量
Depthwise Separable Convolution由两部分组成,分别是Depthwise Convolution和Pointwise Convolution


2、增加了控制卷积核卷积个数的超参数 α \alpha α和输入图像大小的 β \beta β,用户可以根据项目需求使用合适的超参数;
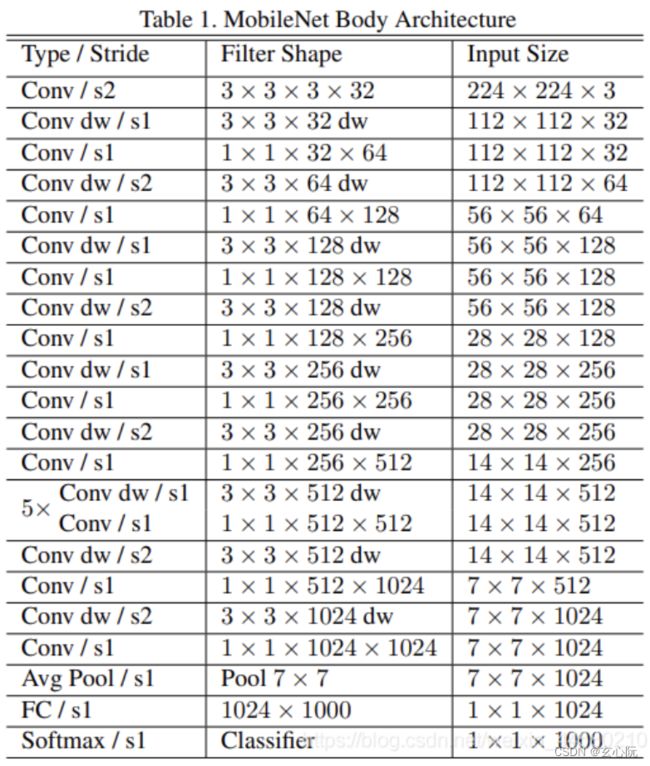
在实验过程中发现Depthwise Convolution参数大部分为零---->这部分卷积核是无效的,在MobileNet V2网络中对这个问题有所优化
MobileNet V2
1、Inverted Residual Block
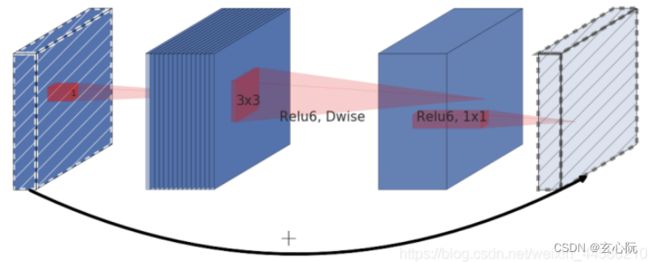
1×1卷积升维 + 3×3 Depthwise Separable Convolution + 1×1卷积降维
使用的Relu6激活函数: y = R e L U 6 ( x ) = m i n ( m a x ( x , 0 ) , 6 ) y = ReLU6(x) = min(max(x,0),6) y=ReLU6(x)=min(max(x,0),6)
在Inverted Residual Block模块中的最后一个卷积层使用的是线性激活函数,也就是Linear Bottleneck,论文中通过实验发现Relu激活函数对低维度特征信息造成大量损失,而Inverted Residual Block中使是"中间大两头小"的结构,因此输出是相对低维度的特征,因此需要使用线性激活函数来替代Relu函数来避免对低维度特征信息造成损失。具体结构如下:

当stride=1且输入特征矩阵与输出特征矩阵shape相同时才有shortcut连接,而并不是stride=1的Inverted Residual Block都会有shortcurt连接。

MobileNet V3
1、采用了bneck结构,进一步优化了Inverted Residual Block

添加了通道注意力机制:在进行Depthwise Convolution之后对特征矩阵按照通道进行池化,获得一个一维的向量,再在向量的基础上连接两个全连接层(第一层非线性激活函数为ReLU,第二层非线性激活函数为Hard-Sigmoid),输出获得向量相当于获得了特征矩阵各个Channel之间的权重关系,最终将该向量逐通道乘到原始的特征矩阵上。
更新了激活函数 H a r d − S i g m o i d = ReLU 6 ( x + 3 ) 6 Hard-Sigmoid = \frac{\operatorname{ReLU} 6(x+3)}{6} Hard−Sigmoid=6ReLU6(x+3)Hard-Sigmoid函数和Sigmoid函数是非常接近的,但是在计算求导过程中会变得更加简单:

2、使用了Neural Architecture Search搜索参数
3、重新设计了耗时层结构 ;

ShuffleNet
ShuffleNet V1
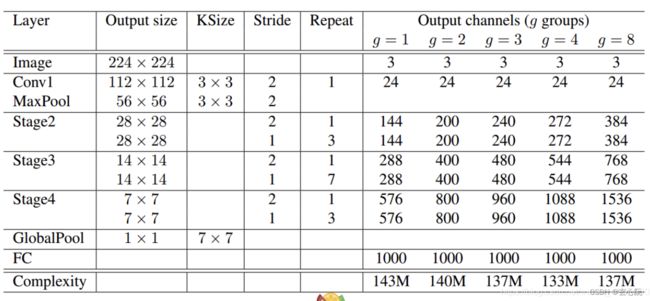
1、提出了Channel Shuffle的思想;

将经过第一次Group Convolution之后的结果,将不同Group间的Channel混乱后再进行第二次Group Convolution,这样就可以实现不同Group特征的融合。
2、ShuffleNet V1中采用的全是Group Convolution和Depthwise Separable Convolution

ShuffleNet V2


1、Equal Channel width minimizes memory access cost(MAC);在卷积和FLOPs不变的前提下,当卷积层的输入特征矩阵与输出特征矩阵Channel相等就能获得最小的Memory Access Cost
2、Excessive group convolution increases MAC;当FLOPs保持不变,GConv的groups增大时,Memory Access Cost也会增大
3、Network fragmentation reduces degree of parallelism;网络设计的碎片化程度越高,速度越慢,虽然这种设计通常可以增加模型的精度
4、Element-wise operations are non-negligible;Element-wise操作带来影响是不可忽视的,Element-wise操作包括ReLU、AddTensor、AddBias等操作,不加入ReLU和short-cut操作速度最快
EfficientNet
EfficientNet V1

文章同时探讨了输入分辨率,网路深度和宽度的影响:
a、增加网络的深度,能够得到更加丰富、复杂的特征并且能够很好的应用到其他任务中,但网络的深度过深会面临梯度消失,训练困难的问题。
b、增加网络的宽度,能够过得更高细粒度的特征并且也更容易训练,但对于width很大而深度较浅的网络往往很难学习到更加深层次的特征。
c、增加输入网络的图像分辨率能够获得更高细粒度的特征模板,但对于非常高的输入分辨,准确率增加的收益会减小,并且大分辨率图像会增加计算量。
EfficientNet V2

a、训练图像尺寸很大时,训练速度非常慢,针对这个问题解决方案就是降低训练图像的尺寸,使用更大的batch_size;
b、在网络浅层中使用Depthwise convolution速度会非常慢,无法充分利用现有的一些加速器,因此EfficientNet V2中引入了Fused-MBConv结构;
c、同等放大每个Stage是次优的,在EfficientNet V1中,每个Stage的深度和宽度都是同等放大的,但是每个Stage对网络的训练速度以及参数数量并不相同,所以直接使用同等缩放策略并不合理,因此在V2中采用了非均匀的缩放策略来缩放模型;
与Efficient V1的不同点主要在于:
a、处理使用MBConv模块,还使用了Fused-MBConv模块;

b、会使用较小的Expansion Ratio;
c、偏向使用更小的Kernel Size(3×3);
d、移除了Efficient V1中最后一个步距为1的Stage;