pytorch 单机多卡--DistributedDataParallel+混合精度--提高速度,减少内存占用
DataParallel巨慢,DistributedDataParallel巨快!

DataParallel的并行处理机制:DataParallel是将输入一个 batch 的数据均分成多份,分别送到对应的 GPU 进行计算,各 个 GPU 得到的梯度累加。与 Module 相关的所有数据也都会以浅复制的方式复制多份。每个 GPU 将针对各自的输入数据独立进行 forward 计算,在 backward 时,每个卡上的梯度会汇总到原始的 module 上,再用反向传播更新单个 GPU 上的模型参数,再将更新后的模型参数复制到剩余指定的 GPU 中,以此来实现并行。
DataParallel会将定义的网络模型参数默认放在GPU 0上,所以dataparallel实质是可以看做把训练参数从GPU拷贝到其他的GPU同时训练,这样会导致内存和GPU使用率出现很严重的负载不均衡现象,即GPU 0的使用内存和使用率会大大超出其他显卡的使用内存,因为在这里GPU0作为master来进行梯度的汇总和模型的更新,再将计算任务下发给其他GPU,所以他的内存和使用率会比其他的高。
参考链接:
Pytorch 分布式并行训练 + 半精度/混合精度训练
示例:
from torch.utils.data.distributed import DistributedSampler
from apex import amp # 使用混合精度
import torch.distributed as dist
import argparse, os
import MMVAE#my function file
#如果还import了其他子函数文件,无需对子函数文件中再进行这些操作
# from gpu_mem_track import MemTracker # 引用显存跟踪代码
os.environ['CUDA_LAUNCH_BLOCKING'] = '1'
os.environ['CUDA_VISIBLE_DEVICES']="4,5,2,8"
print('torch.cuda.device_count()',torch.cuda.device_count())
os.environ["WORLD_SIZE"]='4' #4个进程
os.environ['MASTER_ADDR']='127.0.0.1'
os.environ['MASTER_PORT']='29500'#此端口不可变,否则会卡住
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", type=int, default=0)
args = parser.parse_args()
dist.init_process_group("nccl", init_method='env://')
rank = dist.get_rank()
local_rank = os.environ['LOCAL_RANK']
master_addr = os.environ['MASTER_ADDR']
master_port = os.environ['MASTER_PORT']
print(f"rank = {rank} is initialized in {master_addr}:{master_port}; local_rank = {local_rank}")
torch.cuda.set_device(rank)
local_rank = rank
torch.cuda.set_device(local_rank)
device = torch.device("cuda", local_rank)
world_size = dist.get_world_size() # os.environ["WORLD_SIZE"]
print('world_size',world_size)
#数据并行
milan_datase = ……
sampler = DistributedSampler(milan_dataset, num_replicas=world_size, shuffle=True)
train_loader = DataLoader(dataset=milan_dataset,
batch_size=batch_size,
shuffle=False,
sampler=sampler)
#模型并行
model=……
model.to(device)
optimizer = torch.optim.Adam([{'params': model.parameters()}], lr=0.1)#
model = torch.nn.parallel.DistributedDataParallel(model,
device_ids=[local_rank],
output_device=local_rank)
#训练阶段整合loss,测试阶段类似。仅仅是为了打印的时候,打印四个卡的loss的平均。反向传播的时候还是用各自的loss传播。
if batch_i % 10 == 0:
# We manually reduce and average the metrics across processes. In-place reduce tensor.
reduced_loss = reduce_tensor(losses.data)
losses1.update(to_python_float(reduced_loss), all_input.size(1)) # update needs average and number
torch.cuda.synchronize()
epoch_loss += losses1.item()
运行:
#单机4个GPU
python3 -m torch.distributed.launch --nproc_per_node=4 trainModel_distr_gpus.py
出现错误:
RuntimeError: Expected to have finished reduction in the prior iteration before starting a new one. This error indicates that your module has parameters that were not used in producing loss. You can enable unused parameter detection by (1) passing the keyword argument find_unused_parameters=True to torch.nn.parallel.DistributedDataParallel; (2) making sure all forward function outputs participate in calculating loss. If you already have done the above two steps, then the distributed data parallel module wasn't able to locate the output tensors in the return value of your module's forward function. Please include the loss function and the structure of the return value of forward of your module when reporting this issue (e.g. list, dict, iterable)
使用单卡调试,在loss.backward()之后optimizer.step()之前加入下面代码:
for name, param in model.named_parameters():
if param.grad is None:
print(name)
打印出来的参数就是没有参与loss运算的部分,他们梯度为None

是因为encoder模型中定义了一个没有用到的initial模型,注释掉就好了!![]()
使用混合精度:
from apex import amp # 使用混合精度
model, optimizer = amp.initialize(model, optimizer,
opt_level="O1") # 如果使用apex混合精度训练,初始化放在model和optimizer定义之后,DDP之前
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
optimizer.step()
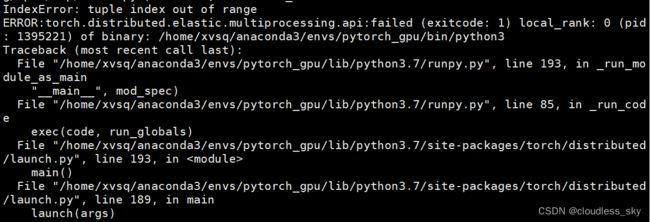

仔细看报错追溯信息,可以看到大概还是混合精度包apex未装好,

混合精度链接
因为安装amp包没成功,直接使用torch 原生支持的amp。
只需要安装有pytorch就能使用,而且代码也简单。限制条件只有一个就是pytorch的版本一定>1.6。主要是利用了这两个API——torch.cuda.amp.GradScalar 和 torch.cuda.amp.autocast。
from torch.cuda.amp import autocast as autocast, GradScaler
>>>>>>>>
other code
>>>>>>>>
# 在训练最开始之前实例化一个GradScaler对象
scaler = GradScaler()
>>>>>>>>
#alternatively #注意自定义的model中也要with autocast()
MyModel(nn.Module):
def forward(self, input):
with autocast():
...
data=*****
model = torch.nn.parallel.DistributedDataParallel(model,
device_ids=[local_rank],
output_device=local_rank)
optimizer=optim.SGD(model.parameters(),lr=0.1)
for epoch in epochs:
for input,target in data:
optimizer.zero_grad()
>>>>>>>>
# 前向过程(model + loss)开启 autocast
with autocast():
output = model(input)
loss = loss_fn(output, target)
# Scales loss,这是因为半精度的数值范围有限,因此需要用它放大
scaler.scale(loss).backward()
# scaler.step() unscale之前放大后的梯度,但是scale太多可能出现inf或NaN
# 故其会判断是否出现了inf/NaN
# 如果梯度的值不是 infs 或者 NaNs, 那么调用optimizer.step()来更新权重,
# 如果检测到出现了inf或者NaN,就跳过这次梯度更新,同时动态调整scaler的大小
scaler.step(optimizer)
# 查看是否要更新scaler,这个要注意不能丢
scaler.update()
>>>>>>>>
other code
>>>>>>>>
更加详细的混合精度教程
命令行改进
自动化启动多进程
单击多卡执行多个并行程序
注意:端口号和py文件名不能重复!
Pytorch distributed RuntimeError: Address already in use
CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --nproc_per_node=2 --master_port 29501 main.py
脚本顺序启动多个程序+传参交互
参考:
传参交互
import os
import argparse
parser = argparse.ArgumentParser()
parser.add_argument(‘-set_num’, help=‘dataset’, type=int, default=2)
parser.add_argument(‘-seq_length’, help=‘history_seq_length’, type=int, default=40)
parser.add_argument(‘-future_length’, help=‘future_seq__length’, type=int, default=1)
args = parser.parse_args()
set_num = args.set_num
脚本编写:run.sh
milan=1
london=2
#history=(40 60 80)
#future=(1 4 8)
history=(60 80 40)
future=(1 4 8)
for((i=0;i<=2;i++))
do
for((j=0;j<=2;j++))
do
python3 -m torch.distributed.launch --nproc_per_node=4 --master_port 29999 trainModel_distr_gpus.py \
-set_num $london\
-seq_length ${history[i]} \
-future_length ${future[j]}
wait
done
done
wait
#history1=(60 90 120)
#future1=(1 6 12)
history1=(60 120 90)
future1=(1 6 12)
for((i=0;i<=2;i++))
do
for((j=0;j<=2;j++))
do
python3 -m torch.distributed.launch --nproc_per_node=4 --master_port 29999 trainModel_distr_gpus.py \
-set_num $milan\
-seq_length ${history1[i]} \
-future_length ${future1[j]}
wait
done
done
运行:
bash ./run.sh
./run.sh: line 5: syntax error near unexpected token `$‘\r’’
解决
sed -i 's/\r//g' run.sh
挂在后台运行:
nohup bash ./run.sh &
一些坑:
1、如果运行程序时,卡在以下

大概率是因为运行命令中写的端口号或py文件名与源代码不一致,仔细检查一下!