用飞桨扛起日本分类竞赛头旗!绽放你的能量!—— 训练篇(一)
点击左上方蓝字关注我们

【飞桨开发者说】于航:网名灰酱。飞桨开发者技术专家(PPDE),一名热爱推理部署的飞桨开发者!现任飞桨公众号小编。

大家好,我是飞桨公众号小编,灰酱~
今天给大家介绍一个比赛,该比赛来自日本算法竞赛网站signate。
参赛者需要构建一个算法,对柠檬的外观进行检测,并根据下面图像中的规则对柠檬的外观进行分类,共有4个等级,分别为“0:優良”、“1:良”、“2:加工品”、“3:規格外”。
本次比赛中,参赛者所用模型需在 Raspberry Pi(树莓派)等小型物联网设备上运行。因此,在推理时只允许使用一种训练模型(不允许使用模型集成)和TTA(测试时数据增强)。

图1 数据集说明
其中,训练集1102张图像,测试集1651张图像。分辨率均为640x640。
比赛链接:https://signate.jp/competitions/431
看到这个比赛以后,小编我花了一周的时间,使用飞桨框架2.0与Paddle Lite给大家搭建了一个比赛的Baseline。
本篇教程分为训练篇与部署篇,今天为大家讲解如何使用飞桨框架2.0自制一个分类任务。10号将继续为大家讲解如何把飞桨框架2.0的模型部署到嵌入式、移动端设备上。
希望大家看完以后可以用飞桨去参加国际竞赛喔,10万日元+10公斤柠檬等你来拿!
深度学习任务开发流程
首先,对于一个任务,当你想使用深度学习解决时,一般流程如下:
①问题定义->②数据准备->③模型选择与开发->
④模型训练和调优->⑤模型评估测试->⑥部署上线
以柠檬外观分类任务为例子:根据竞赛要求,我们使用竞赛方提供的有限数据集,自己搭建深度学习模型,训练并调优,最后还需要将模型部署到树莓派等IoT设备上,实现离线方式的部署。
因为受到部署侧限制,部署的设备算力并不高,内存也小。在没有GPU、NPU等加速的情况下,使用CPU进行深度学习运算。虽然深度学习的前向传播运算并没有反向传播那么地吃算力,但是对于移动端设备来说也是非常大的计算量了。所以,我们在模型选择时,需要轻量级小参数的模型。使用小模型还需要保证精度,这也是赛题的一个难点。

图2 应用深度学习开发的万能公式
在进行下面的内容之前,首先我们要明确一些概念,什么是训练?什么是模型?什么是部署?

图3 什么是训练?什么是模型?什么是部署?
由上图推断可知,在部署时我们需要一个推理部署的框架。这次,我们选用的推理部署框架是Paddle Lite,Paddle Lite是飞桨端侧推理引擎,为手机移动端和嵌入式端在内的端侧场景AI应用提供高效轻量的推理能力,支持广泛的硬件和平台。
使用Paddle Lite对模型进行推理部署的流程分两个阶段:
模型训练阶段:主要解决模型训练,利用标注数据训练出对应的模型文件。(PS:面向端侧进行模型设计时,需要考虑模型大小和计算量)
模型部署阶段:
模型转换:如果是Caffe、TensorFlow或ONNX平台训练的模型,需要使用X2Paddle工具将模型转换到飞桨格式。
(可选)模型压缩:主要优化模型大小,借助PaddleSlim提供的剪枝、量化等手段降低模型大小,以便在端上使用。
将模型部署到Paddle Lite。
在终端上通过调用Paddle Lite提供的API接口(C++、Java、Python等API接口),完成推理相关的计算。
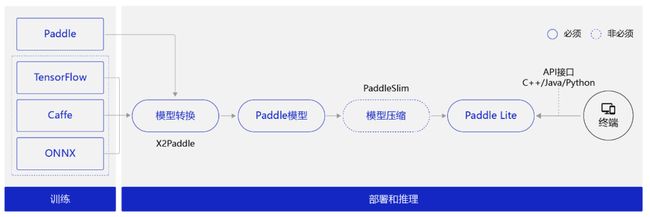
图4 推理部署流程
1 模型训练阶段
1.1 准备数据
准备数据时,小编我做了如下操作:
解压数据集
计算数据集的均值与标准差
使用transforms进行图像预处理
构建Dataset
配置VisualDL
在解压好数据集后,我们先计算一下数据集的均值与标准差。如果你知道均值与标准差是什么的话,这一部分可以先略过~
知识点 01:均值(mean,average)
【解释】
代表一组数据在分布上的集中趋势和总体上的平均水平;
常说的中心化(Zero-Centered)或者零均值化(Mean-Subtraction),就是把每个数据都减去均值;
【公式】
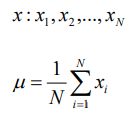
【代码】
# 引入 numpy 科学计算库
import numpy as np
# 一组数据
x = np.array([-0.02964322, -0.11363636, 0.39417967, -0.06916996,
0.14260276])
print('数据:', x)
# 求均值
avg = np.mean(x)
print('均值:', avg)
知识点 02:标准差(Standard Deviation)
【解释】
代表一组数据在分布上的离散程度;
方差是标准差的平方
【公式】
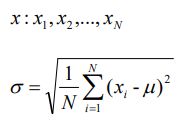
【代码】
# 引入 numpy 科学计算库
import numpy as np
# 一组数据
x = np.array([-0.02964322, -0.11363636, 0.39417967, -0.06916996,
0.14260276])
print('数据:', x)
# 求标准差
std = np.std(x)
print('标准差:', std)
然后,我们通过下面的代码计算数据集各通道的均值与标准差:
import numpy as np
import cv2
import os
img_h, img_w = 640, 640 #根据自己数据集适当调整,影响不大
means, stdevs = [], []
img_list = []
imgs_path = 'data/train_images'
imgs_path_list = os.listdir(imgs_path)
len_ = len(imgs_path_list)
i = 0
for item in imgs_path_list:
img = cv2.imread(os.path.join(imgs_path,item))
img = cv2.resize(img,(img_w,img_h))
img = img[:, :, :, np.newaxis]
img_list.append(img)
i += 1
# print(i,'/',len_)
imgs_path = 'data/test_images'
imgs_path_list = os.listdir(imgs_path)
len_ = len(imgs_path_list)
i = 0
for item in imgs_path_list:
img = cv2.imread(os.path.join(imgs_path,item))
img = cv2.resize(img,(img_w,img_h))
img = img[:, :, :, np.newaxis]
img_list.append(img)
i += 1
# print(i,'/',len_)
# print(len(img_list))
imgs = np.concatenate(img_list, axis=3)
imgs = imgs.astype(np.float32) / 255.
for i in range(3):
pixels = imgs[:, :, i, :].ravel() # 拉成一行
means.append(np.mean(pixels))
stdevs.append(np.std(pixels))
# BGR --> RGB , CV读取的需要转换,PIL读取的不用转换
means.reverse()
stdevs.reverse()
print("normMean = {}".format(means))
print("normStd = {}".format(stdevs))
-----------------------------------------------
normMean = [0.31169346, 0.25506335, 0.12432463]
normStd = [0.34042713, 0.29819837, 0.1375536]
得到各通道均值与标准差后,使用paddle.vision.transforms.Compose做数据预处理,主要是这几个部分:
以RGB格式加载图片
将图片resize,从640x640变成224x224
进行transpose操作,从HWC格式转变成CHW格式
将图片的所有像素值进行除以255进行归一化
对各通道进行减均值、除标准差
from paddle.vision import transforms
# 定义数据预处理
data_transforms = transforms.Compose([
transforms.Resize(size=(224)),
transforms.ToTensor(), # transpose操作 + (img / 255)
transforms.Normalize( # 减均值 除标准差
mean=[0.31169346, 0.25506335, 0.12432463],
std=[0.34042713, 0.29819837, 0.1375536])
#计算过程:output[channel] = (input[channel] - mean[channel]) / std[channel]
])
然后构建Dataset:
import paddle
# 构建Dataset
class MyDataset(paddle.io.Dataset):
"""
步骤一:继承paddle.io.Dataset类
"""
def __init__(self, mode='train'):
"""
步骤二:实现构造函数,定义数据读取方式,划分训练和测试数据集
"""
super(MyDataset, self).__init__()
self.data = []
# 借助pandas读csv的库
self.train_images = pd.read_csv('data/data71145/train_images.csv', usecols=['id','class_num'])
self.test_images = pd.read_csv('data/data71145/sample_submit.csv', usecols=['id','class_num'])
if mode == 'train':
# 读train_images.csv中的数据
for row in self.train_images.itertuples():
self.data.append(['data/train_images/'+getattr(row, 'id'), getattr(row, 'class_num')])
else:
# 读test_images.csv中的数据
for row in self.test_images.itertuples():
self.data.append(['data/test_images/'+getattr(row, 'id'), getattr(row, 'class_num')])
def load_img(self, image_path):
# 实际使用时使用Pillow相关库进行图片读取即可,这里我们对数据先做个模拟
image = Image.open(image_path).convert('RGB')
return image
def __getitem__(self, index):
"""
步骤三:实现__getitem__方法,定义指定index时如何获取数据,并返回单条数据(训练数据,对应的标签)
"""
image = self.load_img(self.data[index][0])
label = self.data[index][1]
return data_transforms(image), np.array(label, dtype='int64')
def __len__(self):
"""
步骤四:实现__len__方法,返回数据集总数目
"""
return len(self.data)
# 测试定义的数据集
train_dataset = MyDataset(mode='train')
test_dataset = MyDataset(mode='test')
1.2 搭建网络(高层API版)
使用Sequential形式组网,两层CNN组建模型(小量级参数,保证生成的模型小,在保证精度为前提尽量使移动端推理速度提快)
使用paddle.summary模型结构可视化
# Sequential形式组网
MyCNN = paddle.nn.Sequential(
paddle.nn.Conv2D(3, 16 ,3),
paddle.nn.ReLU(),
paddle.nn.MaxPool2D(3),
paddle.nn.Conv2D(16, 8, 3),
paddle.nn.ReLU(),
paddle.nn.MaxPool2D(3),
paddle.nn.Flatten(),
paddle.nn.Linear(4608, 4),
)
# 模型结构可视化
paddle.summary(MyCNN, (1, 3, 224, 224))
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-1 [[1, 3, 224, 224]] [1, 16, 222, 222] 448
ReLU-1 [[1, 16, 222, 222]] [1, 16, 222, 222] 0
MaxPool2D-1 [[1, 16, 222, 222]] [1, 16, 74, 74] 0
Conv2D-2 [[1, 16, 74, 74]] [1, 8, 72, 72] 1,160
ReLU-2 [[1, 8, 72, 72]] [1, 8, 72, 72] 0
MaxPool2D-2 [[1, 8, 72, 72]] [1, 8, 24, 24] 0
Flatten-1 [[1, 8, 24, 24]] [1, 4608] 0
Linear-1 [[1, 4608]] [1, 4] 18,436
===========================================================================
Total params: 20,044
Trainable params: 20,044
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 13.40
Params size (MB): 0.08
Estimated Total Size (MB): 14.05
---------------------------------------------------------------------------
{'total_params': 20044, 'trainable_params': 20044}1.3 模型训练&评估&保存(高层API版)
配置optimizer优化器
配置损失函数:CrossEntropyLoss
配置Accuracy
配置GPU训练(飞桨框架2.0可自动根据环境使用GPU,此步骤可省略)
使用model.fit开始训练
使用model.evaluate评估模型精度
使用model.save保存动/静态图模型
# 实例化模型
inputs = paddle.static.InputSpec(shape=[None, 3, 224, 224], name='inputs')
labels = paddle.static.InputSpec(shape=[None, 4], name='labels')
model = paddle.Model(MyCNN, inputs, labels)
# 模型训练相关配置,准备损失计算方法,优化器和精度计算方法
model.prepare(paddle.optimizer.Adamax(learning_rate=1e-3, parameters=model.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
# 设置GPU训练
paddle.set_device('gpu:0') # 切换CPU训练 paddle.set_device('cpu')
# 模型训练
model.fit(train_dataset,
# test_dataset,
epochs=5,
batch_size=64,
verbose=1)
# 模型评估
model.evaluate(test_dataset, batch_size=64, verbose=1)
# 保存模型参数
# model.save('Hapi_MyCNN') # save for training
model.save('Hapi_MyCNN', False) # save for inference
这里需要说明一下:模型部署需要静态图模型,而不能是动态图模型。
飞桨框架2.0新特性中:完善的动静结合体验。动态图训练,并且无缝衔接静态图导出部署模型。这一点上大大提高了部署落地的便利性,再也不用去费力进行代码层面修改的动转静了。
有关飞桨静态图、动态图说明详情参考课程《百度架构师手把手带你零基础实践深度学习》 第八章(3):《设计思想和静动态图》。
1.4 模型测试
使用Pillow做数据预处理(要与训练时transforms预处理对齐)
预测work目录下4张图片
预测时调用SoftMax算子查看预测概率的原因
这部分图像预处理使用Pillow库,注意这里的每一步操作是要和transforms对齐的!!!(再三强调)
def load_image(img_path):
'''
预测图片预处理
'''
img = Image.open(img_path).convert('RGB')
plt.imshow(img) #根据数组绘制图像
plt.show() #显示图像
#resize
img = img.resize((224, 224), Image.BILINEAR) #Image.BILINEAR双线性插值
img = np.array(img).astype('float32')
# HWC to CHW
img = img.transpose((2, 0, 1))
#Normalize
img = img / 255 #像素值归一化
mean = [0.31169346, 0.25506335, 0.12432463]
std = [0.34042713, 0.29819837, 0.1375536]
img[0] = (img[0] - mean[0]) / std[0]
img[1] = (img[1] - mean[1]) / std[1]
img[2] = (img[2] - mean[2]) / std[2]
return img
然后,使用下面的代码进行测试图片的遍历(因为是Baseline,测试图片选自训练集):
def infer_img1(path, model_file_path, use_gpu):
'''
模型预测
'''
paddle.set_device('gpu:0') if use_gpu else paddle.set_device('cpu')
model = paddle.jit.load(model_file_path)
model.eval() #训练模式
#对预测图片进行预处理
infer_imgs = []
infer_imgs.append(load_image(path))
infer_imgs = np.array(infer_imgs)
label_list = ['0:優良', '1:良', '2:加工品', '3:規格外']
for i in range(len(infer_imgs)):
data = infer_imgs[i]
dy_x_data = np.array(data).astype('float32')
dy_x_data = dy_x_data[np.newaxis,:, : ,:]
img = paddle.to_tensor(dy_x_data)
out = model(img)
print(out[0])
print(paddle.nn.functional.softmax(out)[0]) # 若模型中已经包含softmax则不用此行代码。
lab = np.argmax(out.numpy()) #argmax():返回最大数的索引
print("样本: {},被预测为:{}".format(path, label_list[lab]))
image_path = []
for root, dirs, files in os.walk('work/'):
# 遍历work/文件夹内图片
for f in files:
image_path.append(os.path.join(root, f))
for i in range(len(image_path)):
infer_img1(path=image_path[i], use_gpu=True, model_file_path="Hapi_MyCNN")
time.sleep(0.5) #防止输出错乱
Tensor(shape=[4], dtype=float32, place=CUDAPlace(0), stop_gradient=False,
[ 2.00457692, -4.16496420, -4.02241659, -1.69125152])
Tensor(shape=[4], dtype=float32, place=CUDAPlace(0), stop_gradient=False,
[0.97150403, 0.00203258, 0.00234398, 0.02411941])
样本: work/perfect.jpg,被预测为“0:優良”。
小结
至此,我们完成了模型训练阶段 ,得到了可以用于部署的静态图模型,也在AI Studio上对模型进行了测试。现在我们可以拿着这个Baseline去进行参数调优啦!部署部分我将在3月10日与大家仔细分享,包括部署时的难点以及解决的方案~
你说这部分太简单,着急想看部署?

马上扫码关注【飞桨】公众号
回复『柠檬分类』获取项目
欢迎大家也积极报名课程!
在AI Studio上的柠檬分类Notebook项目中,一键fork即可获得。项目内置数据集,无需再科学上网下载比赛数据集!一键运行全部,训练部署一条龙服务,从头到尾无bug!
(Emmmmm,万一发现了bug请评论区悄悄告诉我[手动狗头])
在评论区踊跃交流的小伙伴,小编将会随机抽取一位小伙伴赠送50小时算力卡。
欢迎大家扫描海报报名加入课程,小编将在3月8日,在飞桨B站直播间手把手教你飞桨2.0部署!

如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
·飞桨官网地址·
https://www.paddlepaddle.org.cn/
·飞桨开源框架项目地址·
GitHub: https://github.com/PaddlePaddle/Paddle
Gitee: https://gitee.com/paddlepaddle/Paddle

????长按上方二维码立即star!????
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,是中国首个开源开放、技术领先、功能完备的产业级深度学习平台,包括飞桨开源平台和飞桨企业版。飞桨开源平台包含核心框架、基础模型库、端到端开发套件与工具组件,持续开源核心能力,为产业、学术、科研创新提供基础底座。飞桨企业版基于飞桨开源平台,针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。
END

点击"阅读原文",立即报名加入课程!
↓↓↓