CVPR 2022|从原理和代码详解FAIR的惊艳之作:全新的纯卷积模型ConvNeXt...
预训练比较大,
Convnext-tiny 250多m,yolov7 530多m。
https://github.com/jinfagang/yolov7_d2
ConvNeXt 可以看做是把 Swin Transformer 包括 ViT 的所有特殊的设计集于一身之后的卷积网络进化版,升级了 ResNet 架构,看看借助了2020年代 CV 设计范式之后的卷积网络的性能极限在哪里。这篇工作在年初炸起了CV圈子里又一股讨论的浪潮,因此本文从更加详细的角度去解读和理解作者的思路。
MLP三大工作超详细解读:why do we need?
Vision MLP网络架构超详细解读(二)
Vision MLP网络架构超详细解读(三)
专栏目录:https://zhuanlan.zhihu.com/p/348593638
本文目录
7. 匹敌 Transformer 的2020年代的卷积网络
(来自 FAIR,UCB)
7.1 ConvNeXt 原理分析
7.2 ConvNeXt 代码解读
7. 匹敌 Transformer 的2020年代的卷积网络
论文名称:A ConvNet for the 2020s
论文地址:
https://arxiv.org/pdf/2201.03545.pdf
7.1 ConvNeXt 原理分析
7.1.1 Motivation
回顾2010年代,这十年来以深度学习取得了巨大的进步和影响力。主要的驱动力是神经网络的复兴,尤其是卷积神经网络 (ConvNets)。在过去的十年里,视觉识别领域成功地从设计特征提取器转移到设计神经网络架构。尽管反向传播的发明可以追溯到20世纪80年代,但直到2012年末,我们才看到它真正的潜力。AlexNet 的发明诞生了 "ImageNet moment",开启了计算机视觉的新时代。此后,该领域发展迅速。像 VGGNet,Inceptions,ResNe(X)t,DenseNet,MobileNet,EfficientNet 和 RegNet 这样的代表性 ConvNets 侧重于精度、效率和可扩展性的不同方面,并推广了许多有用的设计原则 (design principles)。ConvNets 本身是计算高效的,因为它以滑动窗口的方式 (sliding-window manner) 进行计算,使得计算是共享的。ConvNets 的默认应用场景包括数字识别,人脸识别,行人识别等等。
与此同时, 自然语言处理 (NLP) 的神经网络设计走了一条非常不同的道路,因为 Transformer 模型取代了 RNN,成为主导的主干架构。
来到2020年代,尽管语言和视觉领域之间的任务存在差异,但这两个领域的主干架构却出人意料地融合在一起,改变了网络设计的面貌。在这些视觉识别模型中,Vision Transformer 是研究热点,在识别任务上首次超过了卷积模型。除了一开始的图片分块操作,原始的 ViT 结构没有引入任何归纳偏置。虽然图像识别任务的这些结果十分令人鼓舞,但是计算机视觉不限于图像分类。原始的 ViT 结构在检测,分割等等通用性视觉任务上收到输入图片分辨率导致的计算复杂度限制,最大的挑战是 ViT 的全局注意力设计 (global attention design),它相对于输入图片的大小 具有二次复杂度 。这对于 ImageNet 分类任务来讲可能是可以接受的,但是对于更高分辨率的输入来说会很快变得难以处理。
金字塔结构 (Hierarchical Transformers) 这种卷积模型先验 (如 Swin-T, PVT 等) 的引入解决了这一问题,使得 ViT 可以被用做其他视觉任务的骨干网络。Swin Transformer 使得 "滑动窗口" 策略被重新引入 Transformer 模型,使它们的行为更类似于卷积模型。Swin 的成功也揭示了卷积的本质并没有变得无关紧要。相反,它仍然备受期待,从未褪色。然而,这种混合方法的有效性仍然很大程度上归功于 ViT 模型的内在优势,而不是卷积固有的归纳偏置 (inductive bias)。
ConvNets 和 Hierarchical Transformers 都具备相似的归纳偏置,但在训练过程和宏/微观层次的架构设计 (macro/micro-level architecture design) 上有显著的差异。在这项工作中,作者重新检查和审视了卷积模型的设计空间,这项研究旨在弥合 pre-ViT 时代和 post-ViT 时代模型性能上的差距,并想要探索出一个纯的卷积网络所能够达到的性能极限。
为了做到这一点,作者从一个标准的 ResNet (ResNet-50) 开始,用改进的方法进行训练,逐渐将架构 "现代化 (modernize)"。这个研究想回答的问题是:ViT 模型中的设计决策会如何影响 ConvNets 的性能?
作者现了导致性能差异的几个关键因素。因此,提出了一个名为 ConvNeXt 的系列纯卷积模型。作者在各种视觉任务上评估 ConvNeXts,例如 ImageNet 图像识别,COCO 上的物体检测/分割,ADE20K 上的语义分割。作者希望这些新的观察和讨论可以鼓励人们重新思考卷积在计算机视觉中的重要性。
7.1.2 2020年代的卷积网络
在本文中,作者提出了一个从 ResNet 到与 Transformer 类似的 ConvNet 的 trajectory。作者根据计算了提出了两种不同的大小范式:FLOPs 约为 4.5×e9 的 ResNet-50 / Swin-T 和 FLOPs 约为 15.0×e9 的 ResNet-200 / Swin-B。从 ResNet-50 开始,以下所有的模型都在 ImageNet-1k 上进行训练和验证。
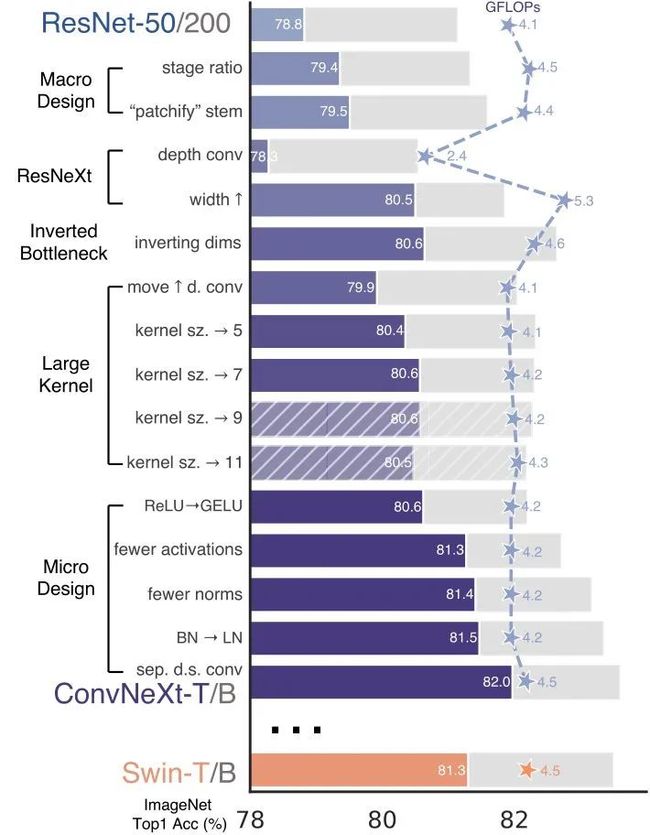
图1:从标准 ConvNet (ResNet) 到没有引入任何基于注意力的模块 hierarchical vision Transformer (Swin) 的路线。蓝色柱状图是 ResNet-50/Swin-T 模型,灰色柱状图是 ResNet-200/Swin-B 模型。
7.1.3 训练策略
除了网络架构的设计,训练过程也会影响最终的性能。Vision Transformer 不仅仅带来了一套新的模块和架构设计策略,也引入了不同的训练技术 (例如 AdamW 优化器)。这主要与优化策略和相关的超参数设置有关。因此,作者探索的第一步是用 Vision Transformer 的训练策略训练一个 ResNet50/200 基线模型。在研究中,作者使用了一个接近 DeiT 和 Swin Transformer 的训练方法,训练轮数从90 epochs 提升到了 300 epochs。使用了AdamW 优化器,数据增强技术包括 Mixup, Cutmix, RandAugment, Random Erasing。正则化方案包括 Stochastic Depth 和 Label Smoothing,如下图2所示。

图2:ImageNet-1K/22K 预训练实验设置
这种增强的训练方案将 ResNet-50 模型的性能从76.1% 提高到了78.8% (+2.7%),这意味着传统 ConvNets 和Vision Transformer 之间的性能差异的很大一部分可能是由于训练策略的不同所造成的。
7.1.4 宏观设计
Swin Transformer 遵循 ConvNet 使用多阶段设计,其中每个阶段都有不同的特征分辨率。作者借鉴了Swin-T的两个设计:
-
每阶段的计算量 (the stage compute ratio)
-
对输入图片下采样方法 (the "stem cell" structure)
小的 Swin Transformer 不同 stage 的层数之比是1:1:3:1,大的 Swin Transformer 不同 stage 的层数之比是1:1:9:1。根据这个设计,作者将每个阶段的块数从 ResNet-50 中的 (3,4,6,3) 调整为 (3,3,9,3) ,这也将 FLOPs 与Swin-T 对齐。这将模型精度从78.8%提高到79.4%。
第2点,作者不再使用 的卷积加上 MaxPooling 进行下采样了,而是像 Swin-T 模型那样把图片分成4×4 的 Patches (具体是通过 的一层卷积对输入图片进行下采样),这一步称为 "Changing stem to Patchify"。这样每次卷积操作的感受野不重叠,准确率由79.4%提升至79.5%。
7.1.5 模仿 ResNeXt 的设计
在这一部分中,作者试图采用 ResNeXt 的思想,它比普通的 ResNet 具有更好的 FLOPs/Accuracy Trade-off。核心部分是分组卷积 (grouped convolution),其中卷积滤波器被分成不同的组。具体在这里使用的是 group 数与 channel 数相等的 Depth-wise Convolution。作者注意到 Depth-wise Convolution 类似于 Self-attention 中的加权和运算,即,仅混合空间维度中的信息。深度卷积的使用有效地降低了网络 FLOPs,但是也降低了精度。按照 ResNeXt 中提出的策略,将网络宽度增加到与 Swin-T 相同的 channel 数 (从64增加到96)。随着 FLOPs (5.3G) 的增加,网络性能提高到80.5%。
7.1.6 Inverted Bottleneck
每个 Transformer Block 中的一个重要设计是,MLP 层的 hidden dimension 比 Input dimension 宽四倍。有趣的是,这种 hidden dimension 比 Input dimension 宽四倍的设计与 MobileNet 的 inverted bottleneck 设计很类似。所以作者也采用了这种办法,将 block 由下图3(a)变为3(b)。这一变化将整个网络的浮点运算量降至4.6G,这是由于两个1×1 卷积层的 FLOPs 显著减少。有趣的是,这导致性能略有提高 (80.5%到80.6%)。在ResNet-200/Swin-B体系中,这一步带来了更大的增益 (81.9%至82.6%),同时还降低了 FLOPs。
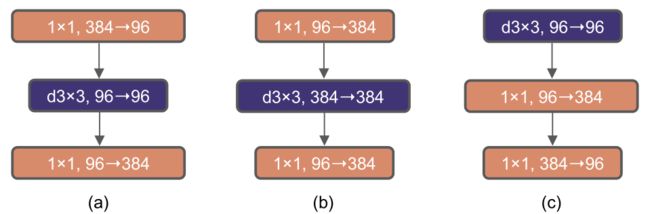
图3:Inverted Bottleneck
7.1.7 增大卷积kernel
作者认为更大的感受野是 ViT 性能更好的可能原因之一,作者尝试增大卷积的kernel,使模型获得更大的感受野。Swin Transformers 的 Window 大小至少是7×7的,明显大于 3×3 的 ResNe(X)t 卷积核大小。
首先是把计算复杂度比较高的 depthwise conv layer 往前移动,将 block 由下图3(b)变为3(c)。使得复杂的模块(MSA,大内核 conv) 将有更少的channel,而高效、密集的1×1层将有更多的channel。这一中间步骤将 FLOPs降至4.1G,导致性能暂时下降至79.9%。
接下来就是采用更大的卷积核大小。作者试验了几种内核大小,包括3,5,7,9,11。网络的性能从79.9% (3×3)提高到80.6% (7×7),而网络的 FLOPs 基本保持不变。结果显示使用7×7的卷积核是最优的。
7.1.8 微观设计
-
将 ReLU 替换为 GELU: GELU,可以被认为是 ReLU 的平滑变体,在最先进的变形金刚中使用,包括谷歌的BERT 和 OpenAI 的 GPT-2 ,以及最近的 ViT。在的 ConvNet 中,ReLU 也可以用 GELU 代替,但是精度保持不变 (80.6%)。
-
更少的激活函数和归一化层 (仅在1×1卷积之间使用激活函数,仅在7×7卷积和1×1卷积之间使用归一化层): Transformer 和 ResNet Block 之间的一个区别是 Transformer 的激活函数较少。MLP 块只有一个激活函数。相比之下,卷积网络的激活函数较多,每个卷积层都有一个激活函数,包括1×1卷积层。作者从残差块中消除了所有的 GELU 层,复制了 Transformer 的样式。这个过程将结果提高到81.3%,实际上与 Swin-T 的性能相当,如下图4所示。Transformer Block 通常也具有较少的标准化层。这里作者去掉了两个 BN 层,在 1×1 卷积层之前只剩下一个 BN 层。这个过程将结果提高到81.4%。
-
BN 替换为 LN: 作者观察到,ConvNet 模型在训练时使用 LN 没有任何困难;事实上将结果提高到81.5%。
-
将下采样层单独分离出来: 最后仿照 Swin-T,作者将下采样层单独分离出来,单独使用2×2卷积层进行下采样。为保证收敛,在下采样后加上 Layer Norm 归一化。最终加强版 ResNet-50 准确率82.0% (FLOPs 4.5G)。
ResNet-50,ConvNeXt-T 和 Swin-T 的结构差别如下图4,5:

图4:Swin Block,ResNet Block 和 ConvNeXt Block 的结构
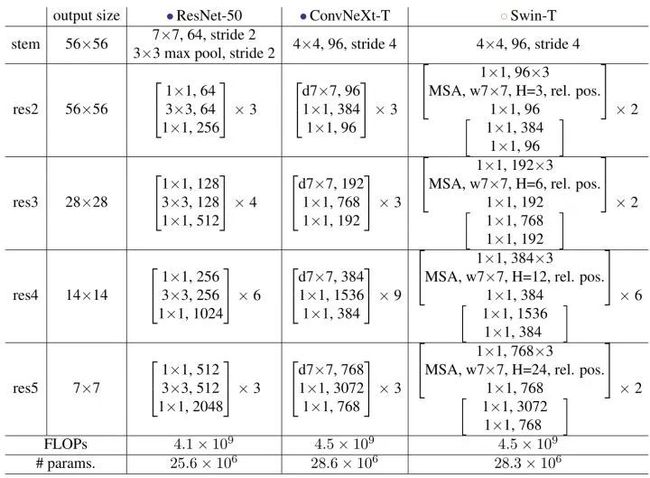
图5:Swin Block,ResNet Block 和 ConvNeXt Block 的总体结构
ConvNeXt 变体,ConvNeXt-T/S/B/L 与 Swin-T/S/B/L 的复杂度相似,不同大小的模型配置如下:

图6:不同大小的 ConvNeXt 模型配置
实验结果
Training on ImageNet-1K
300 epochs,优化器:AdamW,初始学习率:4e-3,linear warmup:20 epochs,学习率变化策略:cosine decaying schedule,batch size:4096,weight decay:0.05,EMA。
数据增强:Mixup , Cutmix , RandAugment , 和 Random Erasing。
Pre-training on ImageNet-22K
90 epochs,优化器:AdamW,初始学习率:4e-3,linear warmup:5 epochs,学习率变化策略:cosine decaying schedule,weight decay:0.05。
Fine-tuning on ImageNet-1K
30 epochs,优化器:AdamW,初始学习率:5e-5,学习率变化策略:layer-wise learning rate decay,batch size:512,weight decay:1e-8,EMA。
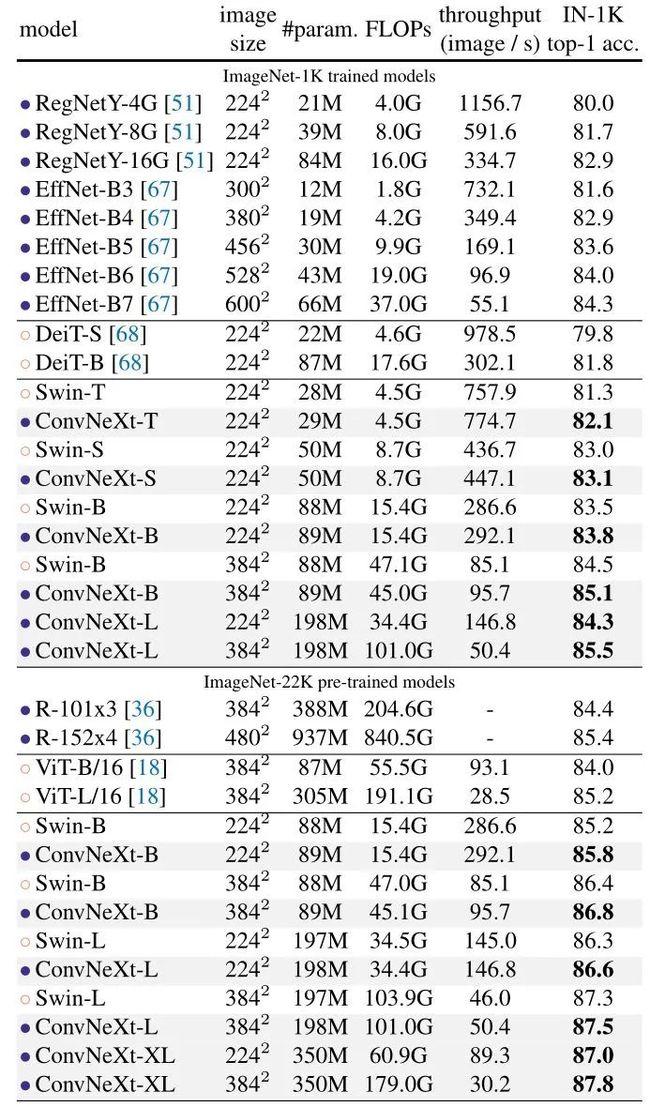
图6:ImageNet 实验结果
从实验结果上看 ConvNeXt-T 性能收益较为突出,在 Accuracy-Computation Trade-off 以及 Inference throughputs 方面,ConvNeXt 与两个强大的 ConvNet 基线模型 (RegNet 和 EfficientNet) 相当。整体表现也优于具有类似复杂性的 Swin Transformer。
Object detection and segmentation on COCO
作者在 COCO 数据集上微调了带有 ConvNeXt backbone 的 Mask R-CNN 和 Cascade Mask R-CNN 的检测模型,训练策略是 multi-scale training, AdamW optimizer, 3x schedule,结果如下图7所示。对于不同复杂度的模型,ConvNeXt 都实现了比 Swin Transformer 更好的性能。
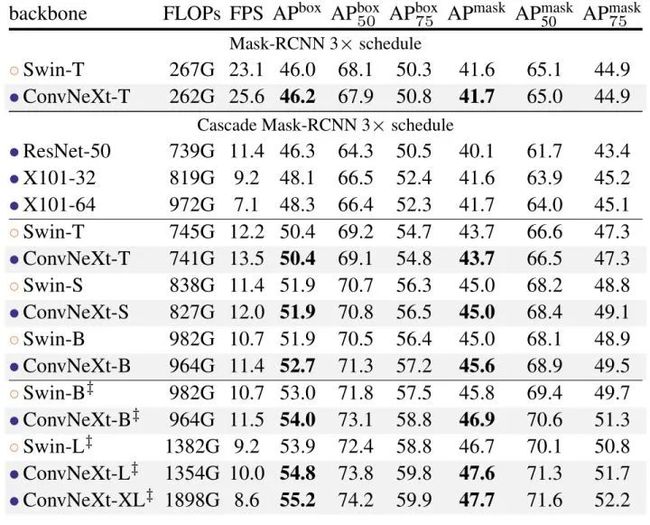
图7:Object detection and segmentation on COCO 实验结果
Semantic segmentation on ADE20K
作者还用 UperNet 评估了 ADE20K 语义分割任务中的 ConvNeXt 主干模型。所有模型都经过 160K iterations 的训练,Batch size 为16,结果如下图8所示。ConvNeXt 模型可以在不同的模型容量上实现有竞争力的性能。
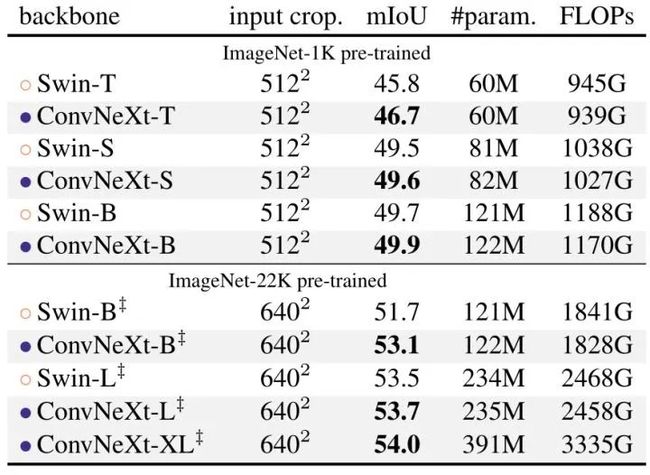
图8:Semantic segmentation on ADE20K 实验结果
7.2 ConvNeXt 代码解读
代码来自:
1 ConvNeXt Block
有2种实现方案:
(1) DwConv -> LayerNorm (channels_first) -> 1x1 Conv -> GELU -> 1x1 Conv; all in (N, C, H, W)
(2) DwConv -> Permute to (N, H, W, C); LayerNorm (channels_last) -> Linear -> GELU -> Linear; Permute back
二者的区别是第1种的 LN 是 channels_first 的,第2种的 LN 是 channels_last 的,实测第2种实现方案速度更快些。
class Block(nn.Module):
r""" ConvNeXt Block. There are two equivalent implementations:
(1) DwConv -> LayerNorm (channels_first) -> 1x1 Conv -> GELU -> 1x1 Conv; all in (N, C, H, W)
(2) DwConv -> Permute to (N, H, W, C); LayerNorm (channels_last) -> Linear -> GELU -> Linear; Permute back
We use (2) as we find it slightly faster in PyTorch
Args:
dim (int): Number of input channels.
drop_path (float): Stochastic depth rate. Default: 0.0
layer_scale_init_value (float): Init value for Layer Scale. Default: 1e-6.
"""
def __init__(self, dim, drop_path=0., layer_scale_init_value=1e-6):
super().__init__()
self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim) # depthwise conv
self.norm = LayerNorm(dim, eps=1e-6)
self.pwconv1 = nn.Linear(dim, 4 * dim) # pointwise/1x1 convs, implemented with linear layers
self.act = nn.GELU()
self.pwconv2 = nn.Linear(4 * dim, dim)
self.gamma = nn.Parameter(layer_scale_init_value * torch.ones((dim)),
requires_grad=True) if layer_scale_init_value > 0 else None
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
input = x
x = self.dwconv(x)
x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)
x = self.norm(x)
x = self.pwconv1(x)
x = self.act(x)
x = self.pwconv2(x)
if self.gamma is not None:
x = self.gamma * x
x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
x = input + self.drop_path(x)
return x
这里需要注意的是 PyTorch 的 nn.LayerNorm 没办法直接对维度是 (N, H, W, C) 的张量使用,PyTorch 的 nn.LayerNorm 有2种情况:
# NLP Example
batch, sentence_length, embedding_dim = 20, 5, 10
embedding = torch.randn(batch, sentence_length, embedding_dim)
layer_norm = nn.LayerNorm(embedding_dim)
# Activate module
layer_norm(embedding)
# Image Example
N, C, H, W = 20, 5, 10, 10
input = torch.randn(N, C, H, W)
# Normalize over the last three dimensions (i.e. the channel and spatial dimensions)
# as shown in the image below
layer_norm = nn.LayerNorm([C, H, W])
output = layer_norm(input)
可以参考 PyTorch 的官方网站:
也就是说输入张量的维度要么是 N, C, H, W,那么使用时需要 nn.LayerNorm([C, H, W]),输入张量的维度要么是 N, L, D,那么使用时需要 nn.LayerNorm(D)。
所以对于输入维度是 的张量,就需要使用:
F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)
如果是 channels_last 数据结构,就直接 F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)。
如果是 channels_first 数据结构,就按照下面的代码形式手动计算 LN。
class LayerNorm(nn.Module):
r""" LayerNorm that supports two data formats: channels_last (default) or channels_first.
The ordering of the dimensions in the inputs. channels_last corresponds to inputs with
shape (batch_size, height, width, channels) while channels_first corresponds to inputs
with shape (batch_size, channels, height, width).
"""
def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):
super().__init__()
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.bias = nn.Parameter(torch.zeros(normalized_shape))
self.eps = eps
self.data_format = data_format
if self.data_format not in ["channels_last", "channels_first"]:
raise NotImplementedError
self.normalized_shape = (normalized_shape, )
def forward(self, x):
if self.data_format == "channels_last":
return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)
elif self.data_format == "channels_first":
u = x.mean(1, keepdim=True)
s = (x - u).pow(2).mean(1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.eps)
x = self.weight[:, None, None] * x + self.bias[:, None, None]
return x
2 ConvNeXt 整体结构
class ConvNeXt(nn.Module):
r""" ConvNeXt
A PyTorch impl of : `A ConvNet for the 2020s` -
https://arxiv.org/pdf/2201.03545.pdf
Args:
in_chans (int): Number of input image channels. Default: 3
num_classes (int): Number of classes for classification head. Default: 1000
depths (tuple(int)): Number of blocks at each stage. Default: [3, 3, 9, 3]
dims (int): Feature dimension at each stage. Default: [96, 192, 384, 768]
drop_path_rate (float): Stochastic depth rate. Default: 0.
layer_scale_init_value (float): Init value for Layer Scale. Default: 1e-6.
head_init_scale (float): Init scaling value for classifier weights and biases. Default: 1.
"""
def __init__(self, in_chans=3, num_classes=1000,
depths=[3, 3, 9, 3], dims=[96, 192, 384, 768], drop_path_rate=0.,
layer_scale_init_value=1e-6, head_init_scale=1.,
):
super().__init__()
self.downsample_layers = nn.ModuleList() # stem and 3 intermediate downsampling conv layers
stem = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
LayerNorm(dims[0], eps=1e-6, data_format="channels_first")
)
self.downsample_layers.append(stem)
for i in range(3):
downsample_layer = nn.Sequential(
LayerNorm(dims[i], eps=1e-6, data_format="channels_first"),
nn.Conv2d(dims[i], dims[i+1], kernel_size=2, stride=2),
)
self.downsample_layers.append(downsample_layer)
self.stages = nn.ModuleList() # 4 feature resolution stages, each consisting of multiple residual blocks
dp_rates=[x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]
cur = 0
for i in range(4):
stage = nn.Sequential(
*[Block(dim=dims[i], drop_path=dp_rates[cur + j],
layer_scale_init_value=layer_scale_init_value) for j in range(depths[i])]
)
self.stages.append(stage)
cur += depths[i]
self.norm = nn.LayerNorm(dims[-1], eps=1e-6) # final norm layer
self.head = nn.Linear(dims[-1], num_classes)
self.apply(self._init_weights)
self.head.weight.data.mul_(head_init_scale)
self.head.bias.data.mul_(head_init_scale)
def _init_weights(self, m):
if isinstance(m, (nn.Conv2d, nn.Linear)):
trunc_normal_(m.weight, std=.02)
nn.init.constant_(m.bias, 0)
def forward_features(self, x):
for i in range(4):
x = self.downsample_layers[i](x)
x = self.stages[i](x)
return self.norm(x.mean([-2, -1])) # global average pooling, (N, C, H, W) -> (N, C)
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
3 不同架构的 ConvNeXt
@register_model
def convnext_tiny(pretrained=False, **kwargs):
model = ConvNeXt(depths=[3, 3, 9, 3], dims=[96, 192, 384, 768], **kwargs)
if pretrained:
url = model_urls['convnext_tiny_1k']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)
model.load_state_dict(checkpoint["model"])
return model
@register_model
def convnext_small(pretrained=False, **kwargs):
model = ConvNeXt(depths=[3, 3, 27, 3], dims=[96, 192, 384, 768], **kwargs)
if pretrained:
url = model_urls['convnext_small_1k']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")
model.load_state_dict(checkpoint["model"])
return model
@register_model
def convnext_base(pretrained=False, in_22k=False, **kwargs):
model = ConvNeXt(depths=[3, 3, 27, 3], dims=[128, 256, 512, 1024], **kwargs)
if pretrained:
url = model_urls['convnext_base_22k'] if in_22k else model_urls['convnext_base_1k']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")
model.load_state_dict(checkpoint["model"])
return model
@register_model
def convnext_large(pretrained=False, in_22k=False, **kwargs):
model = ConvNeXt(depths=[3, 3, 27, 3], dims=[192, 384, 768, 1536], **kwargs)
if pretrained:
url = model_urls['convnext_large_22k'] if in_22k else model_urls['convnext_large_1k']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")
model.load_state_dict(checkpoint["model"])
return model
@register_model
def convnext_xlarge(pretrained=False, in_22k=False, **kwargs):
model = ConvNeXt(depths=[3, 3, 27, 3], dims=[256, 512, 1024, 2048], **kwargs)
if pretrained:
assert in_22k, "only ImageNet-22K pre-trained ConvNeXt-XL is available; please set in_22k=True"
url = model_urls['convnext_xlarge_22k']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")
model.load_state_dict(checkpoint["model"])
return model
总结
ConvNeXt 可以看做是把 Swin Transformer 包括 ViT 的所有特殊的设计 (包括结构,训练策略等等) 集于一身之后的卷积网络进化版,升级了 ResNet 架构,看看借助了2020年代 CV 设计范式之后的卷积网络的性能极限在哪里。其中 Swin Transformer 的 Self-Attention 层可以和 ConvNeXt 的 DW Conv 等价,所以作者将自注意力层替换为 DW Conv 模块,其他部分和 Swin Transformer 尽量保持一致 (金字塔结构的 details,1×1,GeLU 激活函数,Layer Normalization 等等)。作者从 ResNet-50 开始,逐步 Swin Transformer 化,最终得到了ConvNeXt-T 模型,性能超过了 Swin-T。ConvNeXt 在不同的 FLOPs 均可以超过 Swin,如果采用ImageNet21K 预训练后,模型性能有进一步的提升。ConvNeXt 是一个很好的工作,且它在吞吐量上的优势和鲁棒性使得 ConvNeXt 在工业部署上更有价值。我们想,不同神经网络架构的性能不同,并不是某一两种结构所带来的,而是神经网络的整体架构 (激活函数,归一化,金字塔不同阶段的配置等等) 和训练方式 (优化器,学习率,数据增强,数据集分辨率,数据集大小) 共同造成的。从这一点上而言,ConvNeXt 给我们带来了很好的设计范例和参考。