【Pytorch项目实战】之人脸检测与识别:基于face_recognition开源人脸识别库
文章目录
- 人脸检测与识别
-
- (一)实战:人脸检测(图片)
- (二)实战:人脸检测与识别(视频)
人脸检测与识别
face_recognition 是开源人脸识别库。Face Recognition官网。其依赖于python的两个库:dlib和CMake。安装分为三个步骤:(1)dlib安装(2)CMake安装(3)face_recognition安装。
人脸检测是目标检测的一种。人脸检测和人脸识别原理
- 目标检测 即找出图像中所有感兴趣的目标,确定他们的类别和位置。
(1)早期框架有Viola Jones、HOG;
(2)加入深度学习后的框架OverFeat、R-CNN、Fast R-CNN、Faster R-CNN等。
主要影响因素:分辨率、光照、模糊度、遮挡、角度等。- 人脸检测与识别 属于生物特征识别技术,通过对生物体本身的生物特征来区分生物体个体。生物特征包括:脸、指纹、手掌纹、虹膜、视网膜、声音、体型、签字等。
其主要的挑战:
(1)单一限定场景发展到广场、车站、地铁口等;
(2)人脸尺度多变、姿态多样性包括俯拍、搞帽子口罩、表情夸张、化妆伪装、光照条件恶劣、分辨率低到人眼难辩等。
如何实现人脸识别?
通过定位和对齐得到人脸的区域图像,然后卷积网络提取人脸特征进行分类识别。
- 定位(Detection):在图像中找到所有人脸的位置,并画出矩形框。
- 对齐(Alignment):找到人脸的若干个关键点(如眼角、鼻尖、嘴角等),然后通过相似变换(如旋转、缩放和平移)得到标准人脸(模板)。
- 特征提取(Feature Extraction):通过深度卷积网络提取特征(权重参数)。
基于CNN的人脸定位与对齐方法:MTCNN(Multi-task Cascaded Convolutional Networks)
主要由三个神经网络组成:PNet、RNet、ONet。
主要流程:
(1)resieze(预处理):对给定图像进行裁剪,生成不同大小的图像。构建图像金字塔,以便适应不同尺寸的人脸。
(2)PNet(一次过滤):使用PNet网络生成候选窗口,并利用边框回归方法矫正候选窗口,然后使用非极大值抑制NMS提取相关度最大的窗口。
(3)RNet(二次过滤):使用NRNet网络改善候选窗口。拒绝掉大部分假窗口,并继续使用边框回归矫正窗口和NMS提取窗口。
(4)ONet(检测人脸);使用ONet网络输出最终的人脸框和五个特征点的位置。
如何衡量人脸的相似性与不同?
设计有效的Loss Function,使得类内的变化程度最小,同时保持类间的可区分性。损失函数包括:(1)交叉熵损失(2)三元组损失(3)中心损失(4)ArcFace。
实战:人脸识别库face_recognition使用教程(人脸检测、人脸马赛克、人脸关键点识别、人脸涂色、人眼睁闭状态识别、人脸识别)
(一)实战:人脸检测(图片)

import face_recognition
import cv2 # opencv读取图像的格式BGR(图像的格式RGB)
img = face_recognition.load_image_file("女团.jpg") # 加载图片
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # BGR转换为RGB
face_locations = face_recognition.face_locations(img) # 提取人脸位置
print("I found {} face(s) in this photograph." .format(len(face_locations))) # 打印图像中的人脸数
#######################################################
# 提取图像中所有人脸
for face_location in face_locations:
top, right, bottom, left = face_location
start = (left, top)
end = (right, bottom)
cv2.rectangle(img, start, end, color=(255, 255, 255), thickness=3)
#######################################################
# 显示识别结果
cv2.namedWindow("face_recognition")
cv2.imshow("face_recognition", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
(二)实战:人脸检测与识别(视频)
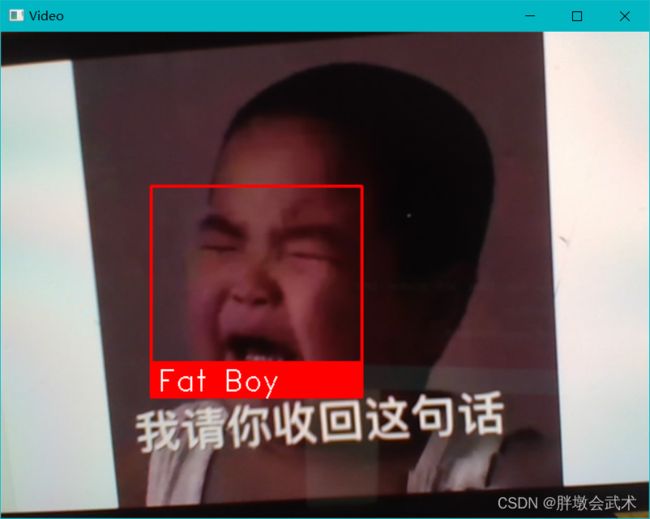
import face_recognition
import cv2
import numpy as np
#########################################################
# (1)自定义已知面孔及标签
video_capture = cv2.VideoCapture(0) # cv2.VideoCapture可以捕获摄像头,用数字来控制不同的设备
obama_image = face_recognition.load_image_file("小胖墩.jpg") # 自定义已知面孔1
obama_face_encoding = face_recognition.face_encodings(obama_image)[0]
biden_image = face_recognition.load_image_file("obama.jpg") # 自定义已知面孔2
biden_face_encoding = face_recognition.face_encodings(biden_image)[0]
known_face_encodings = [obama_face_encoding, biden_face_encoding] # 创建已知人脸编码(数组)
known_face_names = ["Fat Boy", "obama"] # 创建已知人脸的名称(数组)
#########################################################
# 参数初始化
face_locations = []
face_encodings = []
face_names = []
process_this_frame = True
while True:
#########################################################
# 人脸检测与识别(匹配两张面孔的距离)
ret, frame = video_capture.read() # 循环读取视频的每一帧(图像)
if process_this_frame: # 为了节省时间,每隔一帧视频就处理一次
small_frame = cv2.resize(frame, (0, 0), fx=0.25, fy=0.25) # 调整视频帧的大小为1/4大小,以更快的人脸识别处理
rgb_small_frame = small_frame[:, :, ::-1] # 将图像从BGR颜色(OpenCV使用)转换为RGB颜色(face_recognition使用)
face_locations = face_recognition.face_locations(rgb_small_frame) # 查找当前视频帧中的所有人脸位置
face_encodings = face_recognition.face_encodings(rgb_small_frame, face_locations) # 查找当前视频帧中的所有人脸编码
face_names = []
for face_encoding in face_encodings:
name = "Unknown" # 若新面孔与已知面孔不同,则显示“ 未知”
matches = face_recognition.compare_faces(known_face_encodings, face_encoding) # 看这张脸是否与已知的脸匹配
face_distances = face_recognition.face_distance(known_face_encodings, face_encoding) # 计算与新面孔与已知面孔的距离
best_match_index = np.argmin(face_distances) # 计算与新面孔与已知面孔的最小距离
if matches[best_match_index]:
name = known_face_names[best_match_index]
face_names.append(name)
process_this_frame = not process_this_frame # 为了节省时间,每隔一帧视频就处理一次
#########################################################
# 框出人脸并显示标签
for (top, right, bottom, left), name in zip(face_locations, face_names):
# 由于我们检测到的帧被缩放到1/4大小,所以将面位置缩小
top *= 4; right *= 4; bottom *= 4; left *= 4
cv2.rectangle(frame, (left, top), (right, bottom), (0, 0, 255), 2) # 在脸周围画一个方框
cv2.rectangle(frame, (left, bottom - 35), (right, bottom), (0, 0, 255), cv2.FILLED) # 在脸下方画一个有名字的标签
font = cv2.FONT_HERSHEY_DUPLEX
cv2.putText(frame, name, (left + 6, bottom - 6), font, 1.0, (255, 255, 255), 1)
cv2.imshow('Video', frame)
if cv2.waitKey(1) & 0xFF == 27: # 27 表示退出键(Esc)
break
video_capture.release()
cv2.destroyAllWindows()