python高斯核函数_机器学习:SVM(核函数、高斯核函数RBF)
一、核函数(Kernel Function)
1)格式
K(x, y):表示样本 x 和 y,添加多项式特征得到新的样本 x'、y',K(x, y) 就是返回新的样本经过计算得到的值;
在 SVM 类型的算法 SVC() 中,K(x, y) 返回点乘:x' . y' 得到的值;
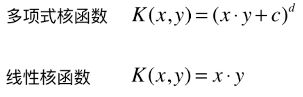
2)多项式核函数
业务问题:怎么分类非线性可分的样本的分类?
内部实现:
对传入的样本数据点添加多项式项;
新的样本数据点进行点乘,返回点乘结果;
多项式特征的基本原理:依靠升维使得原本线性不可分的数据线性可分;
升维的意义:使得原本线性不可分的数据线性可分;
例:
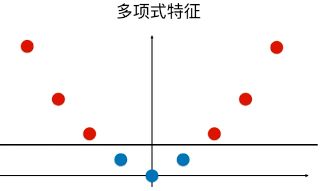
一维特征的样本,两种类型,分布如图,线性不可分:

为样本添加一个特征:x2 ,使得样本在二维平面内分布,此时样本在 x 轴升的分布位置不变;如图,可以线性可分:
3)优点 / 特点
不需要每次都具体计算出原始样本点映射的新的无穷维度的样本点,直接使用映射后的新的样本点的点乘计算公式即可;
减少计算量
减少存储空间
一般将原始样本变形,通常是将低维的样本数据变为高维数据,存储高维数据花费较多的存储空间;使用核函数,不用考虑原来样本改变后的样子,也不用存储变化后的结果,只需要直接使用变化的结果进行运算并返回运算结果即可;
核函数的方法和思路不是 SVM 算法特有,只要可以减少计算量和存储空间,都可以设计核函数方便运算;
对于比较传统的常用的机器学习算法,核函数这种技巧更多的在 SVM 算法中使用;
4)SVM 中的核函数
svm 类中的 SVC() 算法中包含两种核函数:
SVC(kernel = 'ploy'):表示算法使用多项式核函数;
SVC(kernel = 'rbf'):表示算法使用高斯核函数;
SVM 算法的本质就是求解目标函数的最优化问题;
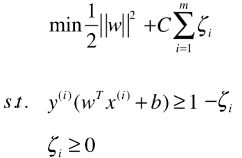
求解最优化问题时,将数学模型变形:

5)多项式核函数
格式:
from sklearn.svm importSVC
svc= SVC(kernel = 'ploy')
思路:设计一个函数( K(xi, xj) ),传入原始样本(x(i) 、 x(j)),返回添加了多项式特征后的新样本的计算结果(x'(i) . x'(j));
内部过程:先对 xi 、xj 添加多项式,得到:x'(i) 、 x'(j),再进行运算:x'(i) . x'(j) ;
x(i) 添加多项式特征后:x'(i) ;
x(j) 添加多项式特征后:x'(j) ;
x(i) .x(j)转化为:x'(i) .x'(j) ;
其实不使用核函数也能达到同样的目的,这里核函数相当于一个技巧,更方便运算;
二、高斯核函数(RBF)
业务问题:怎么分类非线性可分的样本的分类?
1)思想
业务的目的是样本分类,采用的方法:按一定规律统一改变样本的特征数据得到新的样本,新的样本按新的特征数据能更好的分类,由于新的样本的特征数据与原始样本的特征数据呈一定规律的对应关系,因此根据新的样本的分布及分类情况,得出原始样本的分类情况。
应该是试验反馈,将样本的特征数据按一定规律统一改变后,同类样本更好的凝聚在了一起;
高斯核和多项式核干的事情截然不同的,如果对于样本数量少,特征多的数据集,高斯核相当于对样本降维;
高斯核的任务:找到更有利分类任务的新的空间。
方法:类似
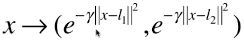 的映射。
的映射。
高斯核本质是在衡量样本和样本之间的“相似度”,在一个刻画“相似度”的空间中,让同类样本更好的聚在一起,进而线性可分。
疑问:
“衡量”的手段
,经过这种映射之后,为什么同类样本能更好的分布在一起?
2)定义方式
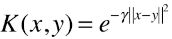 ;
;
x、y:样本或向量;
γ:超参数;高斯核函数唯一的超参数;
|| x - y ||:表示向量的范数,可以理解为向量的模;
表示两个向量之间的关系,结果为一个具体值;
高斯核函数的定义公式就是进行点乘的计算公式;
3)功能
先将原始的数据点(x, y)映射为新的样本(x',y');
再将新的特征向量点乘(x' . y'),返回其点乘结果;
计算点积的原因:此处只针对 SVM 中的应用,在其它算法中的应用不一定需要计算点积;
4)特点
高斯核运行开销耗时较大,训练时间较长;
一般使用场景:数据集 (m, n),m < n;
一般应用领域:自然语言处理;
自然语言处理:通常会构建非常高维的特征空间,但有时候样本数量并不多;
5)高斯函数

正态分布就是一个高斯函数;
高斯函数和高斯核函数,形式类似;
6)其它
高斯核函数,也称为 RBF 核(Radial Basis Function Kernel),也称为径向基函数;
高斯核函数的本质:将每一个样本点映射到一个无穷维的特征空间;
无穷维:将 m*n 的数据集,映射为 m*m 的数据集,m 表示样本个数,n 表示原始样本特征种类,样本个数是无穷的,因此,得到的新的数据集的样本也是无穷维的;
高斯核升维的本质,使得线性不可分的数据线性可分;
三、RBF 转化特征数据原理
1)转化原理
x:需要改变维度的样本;
np.array([l1, l2, ..., lm])== X == np.array([x1, x2, ... , xm]):Landmark,地标,一般直接选取数据集 X 的所有样本作为地标;(共 m 个)
对于 (m, n) 的数据集:转化为 (m, m) 的数据集;将 n 维的样本转化为 m 维的样本;
对于原始数据集中的每一个样本 x,也可以有几个地标点,就将 x 转化为几维;
2)主要为两部分
先将原始的数据点映射为一种新的特征向量,再将新的特征向量点乘,返回其点乘结果;
维度转化:样本 x1 转化x1' :(e-γ||x1 - x1||**2, e-γ||x1 - x2||**2, e-γ||x1 - x3||**2, ..., e-γ||x1 - xm||**2),同理样本x2 的转化 x2';(地标点就是数据集 X 的样本点)
点乘计算:x1' . x2' == K(x1, x2) == e-γ||x1 - x2||**2,最终结果为一个具体值;
3)实例模拟维度转化过程
一维升到二维
原始样本分布:
第一步:选取地标点:L1、L2 ;

第二步:升维计算
四、程序模拟
目的:将线性不可分的数据变为线性可分;
方法:一维数据升到二维;
1)模拟数据集
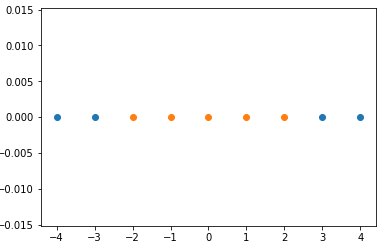
x 数据集:每一个样本只有一个特征,且分布规律线性不可分;
np.arange(m, n, l):将区间 [m, n) 按间距为 l 等分,等分后的数据点包含 m 值,不包含 n;
[0]*len(x[y==0]):[0] 是一个 list,list * C 表示将列表复制 C 份;
如:[0]*5 == [0, 0, 0, 0, 0]
importnumpy as npimportmatplotlib.pyplot as plt
x= np.arange(-4, 5, 1)
y= np.array((x >= -2) & (x <= 2), dtype='int')
plt.scatter(x[y==0], [0]*len(x[y==0]))
plt.scatter(x[y==1], [0]*len(x[y==1]))
plt.show()
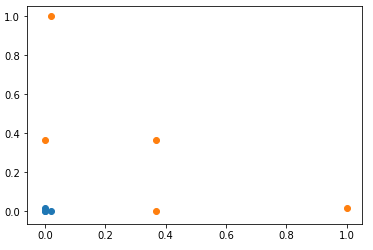
2)经过高斯核,得到新的数据集
np.exp(m):表示 e 的 m 次幂;
np.empty(元组):(元组)=(m, n),生成一个 m 行 n 列的空的矩阵;
enumerate(iterator):返回可迭代对象的 index 和 value;
for i, data in enumerate(x):i 存放向量 x 的 index,data 存放向量 x 的 index 对应的元素值;
defgaussian(x, l):#此处直接将超参数 γ 设定为 1.0;
#此处 x 表示一维的样本,也就是一个具体的值,l 相应的也是一个具体的数,因为 l 和 x 一样,从特征空间中选定;
gamma = 1.0
#此处因为 x 和 l 都只是一个数,不需要再计算模,可以直接平方;
return np.exp(-gamma * (x-l)**2)#设定地标 l1、l2 为 -1和1
l1, l2 = -1, 1x_new= np.empty((len(x), 2))for i, data inenumerate(x):
x_new[i, 0]=gaussian(data, l1)
x_new[i,1] =gaussian(data, l2)
plt.scatter(x_new[y==0, 0], x_new[y==0, 1])
plt.scatter(x_new[y==1, 0], x_new[y==1, 1])
plt.show()