Towards Sparse Hierarchical Graph Classifiers
文章目录
-
-
- 1 动机
- 2 相关工作
- 3 模型
-
- 卷积层
- 池化层
- readout层
- 4 实验
-
论文:Towards Sparse Hierarchical Graph Classifiers 稀疏层次图分类器的研究
来源: NIPS 2018 Workshop
论文链接:
Arxiv: https://arxiv.org/abs/1811.01287
1 动机
图表示学习的最新进展,主要是利用图卷积网络,对许多基于图的基准任务带来了实质性的改进。虽然新的学习节点embeddign的方法非常适合于节点分类和链接预测,但它们的在图分类(预测整个图的标签)的应用基本上还处于初级阶段,通常使用简单的全局池化步骤聚合特征或使用手动设计,模式固定的层次化粗化图结构的方法。改进这一点的一个重要步骤是在图形神经网络中,以自适应的、与数据相关的方式,对图进行粗化处理,这类似于CNNs中的图像下采样。但是,以前的SOTA的方法在训练时的池化需要O(N^2)的内存需求,因此不能扩展到大型图。文中结合了图神经网络设计的一些最新进展,以证明在不牺牲稀疏性的情况下,具有竞争力的层次图分类结果是可能的。
2 相关工作
DiffPool是第一个端到端的分层池化模型,DiffPool计算从原始图的节点到池化图中的节点的之间的软的聚类分配。DiffPool的主要局限性是对软聚类分配的计算,在训练阶段需要存储聚类分配矩阵,这个软分配矩阵是稠密的,需要 O ( k V 2 ) O(kV^2) O(kV2)( k k k表示聚类数, V V V表示节点数)的存储空间,因此不能扩展到大图上。
文中根据最新的图神经网络模型来证明不需要牺牲稀疏性就可获得具有池化功能的端到端图卷积架构的良好性能。实验部分展示了与DiffPool有可媲美的性能,同时仅需要 O ( V + E ) O(V+E) O(V+E)( E E E为边数)的存储空间。
3 模型
定义:
- 节点特征: X ∈ R N × F \mathbf{X} \in \mathbb{R}^{N \times F} X∈RN×F,如果节点没有特征可用,则可以使用节点的度作为人造特征,比如可以用one-hot编码。
- 邻接矩阵: A ∈ R N × N \mathbf{A} \in \mathbb{R}^{N \times N} A∈RN×N,文中主要处理的是无向图和无权图,因此邻接矩阵是二进制表示的对称矩阵。
和CNN对图像进行分类类似,文中的模型包括一个卷积层和池化层,此外,还需要一个readout层,它将学习到的表示转换成固定大小的向量表示,用于最终预测(例如简单的MLP)。
卷积层
由于需要在测试时对未知的图结构进行分类,因此,卷积层的设计应该是inductive的,即它不依赖于固定的和已知的图结构。最简单的此类层是mean-pooling传播规则,如GCN何GAT中使用的,文中使用的卷积层如下:
M P ( X , A ) = σ ( D ^ − 1 A ^ X Θ + X Θ ′ ) \mathrm{MP}(\mathrm{X}, \mathrm{A})=\sigma\left(\hat{\mathrm{D}}^{-1} \hat{\mathrm{A}} \mathrm{X} \Theta+\mathrm{X} \Theta^{\prime}\right) MP(X,A)=σ(D^−1A^XΘ+XΘ′)
后一步是跳跃连接,进一步促进了有关中心节点信息的保存。
池化层
DiffPool中的,池化率为 k ∈ { 0 , 1 } k \in{\{0,1\}} k∈{0,1},即池化前的节点数量为 N N N,则池化后的节点数为 k N kN kN。和DiffPool不同的是,文中采用Graph U-Nets中的池化架构,这种方式从原图中丢掉 N − k N N-kN N−kN个节点,然后池化后留下 k N kN kN个节点。
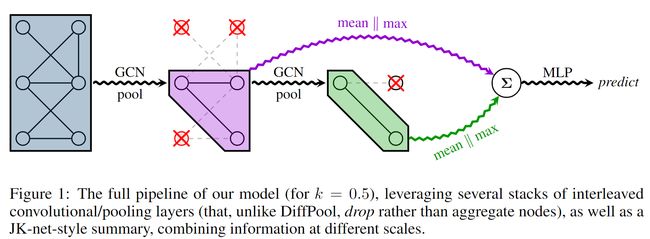
Graph U-Nets中通过计算投影分数来选择节点:
y ⃗ = X p ⃗ ∥ p ⃗ ∥ i ⃗ = top-k ( y ⃗ , k ) X ′ = ( X ⊙ tanh ( y ⃗ ) ) i ⃗ A ′ = A i ⃗ , i ⃗ \vec{y}=\frac{\mathbf{X} \vec{p}}{\|\vec{p}\|} \quad \vec{i}=\operatorname{top-k}(\vec{y}, k) \quad \mathbf{X}^{\prime}=(\mathbf{X} \odot \tanh (\vec{y}))_{\vec{i}} \quad \mathbf{A}^{\prime}=\mathbf{A}_{\vec{i}, \vec{i}} y=∥p∥Xpi=top-k(y,k)X′=(X⊙tanh(y))iA′=Ai,i
其中, ∥ ⋅ ∥ \|\cdot\| ∥⋅∥是L2范数, top-k \operatorname{top-k} top-k返回从给定的输入向量中选择前k的索引, ⋅ i ⃗ \cdot_{\vec{i}} ⋅i是一个索引操作,根据向量 i ⃗ \vec{i} i来切片。 X \mathbf{X} X的话是选出 i i i行, A \mathbf{A} A的话行列都取。这种切片索引操作可以保持稀疏性。
注:在 numpy中,矩阵的元素操作对矩阵维度的要求,通过一种叫做 broadcasting的机制实现。我们称两个矩阵相容(compatible),如果它们相互对应的维度(行对行,列对列)满足以下条件:
- 对应的维度均相等,或有一个维度的大小是1
- 矩阵的Hadamard积是一个元素运算,就像向量一样。对应位置的值相乘产生新的矩阵。
- 在 numpy 中,只要矩阵和向量的维度满足 broadcasting 的要求,便可以对他们使用 Hadamard 乘积运算。
readout层
最后,寻求一种“扁平化”操作,它将以固定大小的representation保存关于输入图的信息。在CNN中,一种很自然的方法是全局平均池化,即取所有学习到的节点embedding的平均值。文中还通过执行全局最大池化来进一步增强这一点。受JK-net架构的启发,文中在网络的每个conv-pool模块之后执行这个readout,并将所有的summaries汇总在一起。
s ⃗ ( l ) = 1 N ( l ) ∑ i = 1 N ( l ) x ⃗ i ( l ) ∥ max i = 1 N ( l ) x ⃗ i ( l ) \vec{s}^{(l)}=\frac{1}{N^{(l)}} \sum_{i=1}^{N^{(l)}} \vec{x}_{i}^{(l)} \| \max _{i=1}^{N^{(l)}} \vec{x}_{i}^{(l)} s(l)=N(l)1i=1∑N(l)xi(l)∥i=1maxN(l)xi(l)
x ⃗ i ( l ) \vec{x}_{i}^{(l)} xi(l)是第 i i i个节点的特征表示,最后的 summary vector 将这些summaries再汇总起来:
s ⃗ = ∑ l = 1 L s ⃗ ( l ) \vec{s}=\sum_{l=1}^{L} \vec{s}^{(l)} s=l=1∑Ls(l)
然后再放进MLP中进行预测,最后可以得到预测。
这种跨层的聚合是很重要的,不仅可以保存在不同尺度处理的信息,也可以有效地保存有些很容易很快池化成节点的小图上的信息。
4 实验
文中的实验是为了评估文中的稀疏模型可以在多层网络上压缩图的表示同时仍产生与分类相关的特征的能力。使用的模型包括三个conv-pool模块,卷积层的输出特征维度128或64,每个粗化阶段后的信息保留80%的节点。使用Adam优化器进行训练,学习率:0.005 was used for Proteins and 0.0005 for all other datasets。
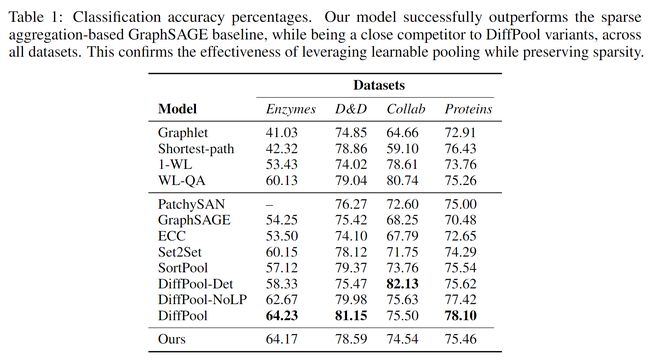
文章的主要亮点只是占的内存少而已,其他还不如DIFFPOOL及其变体。
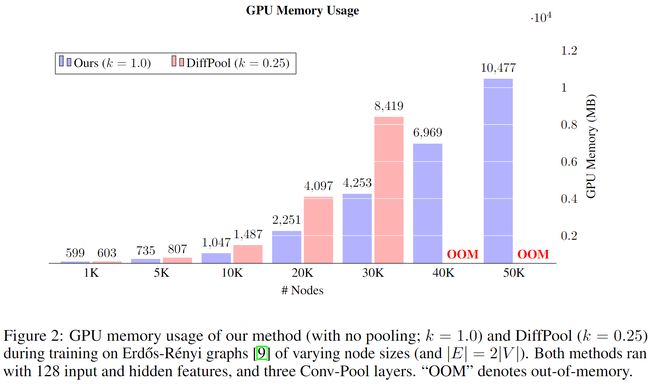
上图中的 k = 1 k=1 k=1表示不丢弃任何节点。可以发现当节点数量达到 40 K 40K 40K时,只保存 0.25 N 0.25N 0.25N节点的DiffPool就超内存了,原因是文中的模型是稀疏的,不需要 O ( k N 2 ) O(kN^2) O(kN2)的空间复杂度。
有错误的地方还望不吝指出,欢迎进群交流GNNs(入群备注信息!!!,格式:姓名(或网名) -(学校或其他机构信息)- 研究方向)。
