项目实训(十)—提取视频特征
引言:
为了实现智能预览功能:将与视频进度条所在的视频片段的场景相似的场景视频展示给用户,即用户看到某个场景片段的同时也会看到相似的场景片段,并且当点击某个相似场景片段时,进度条会跳转到该场景片段。
提取视频特征:
使用 googlenet 网络进行特征的提取
Extract_Feature 类初始化函数(每个场景视频的图像的特征值保存都在一个h5文件中):
def __init__(self, video_path, save_path):
self.resnet = ResNet()
self.google = googlenet(pretrained=True)
self.google.float()
self.google.cuda()
self.google.eval()
self.video_list = []
self.video_path = ''
self.h5_file = h5py.File(save_path, 'w')
self._set_video_list(video_path)
获取所有的场景视频,创建相应的h5文件:
def _set_video_list(self, video_path):
# 如果video_path是目录,获取目录下的所有文件名并排序
if os.path.isdir(video_path):
self.video_path = video_path
self.video_list = os.listdir(video_path)
self.video_list.sort()
else:
self.video_path = ''
self.video_list.append(video_path)
for idx, file_name in enumerate(self.video_list):
# H5PY采用create_group命令进行创建
self.h5_file.create_group('video_{}'.format(idx + 1))
对图像进行特征提取:
def _extract_feature(self, frame):
# 改变图像的颜色空间
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# 对图片进行缩放
frame = cv2.resize(frame, (224, 224))
EF = [frame[:, :, 0], frame[:, :, 1], frame[:, :, 2]]
EF = np.array(EF)
# torch.from_numpy()方法把数组转换成张量,且二者共享内存,对张量进行修改比如重新赋值,那么原始数组也会相应发生改变
# unsqueeze(dim=0)对0维度扩展一维
frameTen = t.from_numpy(EF).unsqueeze(dim=0).cuda().float()
res_pool5 = self.google(frameTen)
frame_feat = res_pool5.cpu().data.numpy().flatten()
return frame_feat
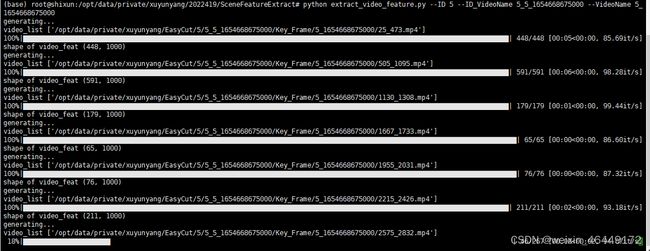
处理所有的场景视频,读取每个视频的每一帧,然后调用上面的_extract_feature方法提取每一帧的特征,并将每个视频的特征值写入相应的h5文件中,这里每个视频的特征表示为维数(帧数,1000)的张量
def generate_dataset(self):
print('generating...')
print("video_list",self.video_list)
for video_idx, video_filename in enumerate(self.video_list):
video_path = video_filename
if os.path.isdir(self.video_path):
video_path = os.path.join(self.video_path, video_filename)
video_capture = cv2.VideoCapture(video_path) # 读取视频
fps = video_capture.get(cv2.CAP_PROP_FPS) # 获取视频帧率
n_frames = int(video_capture.get(cv2.CAP_PROP_FRAME_COUNT)) # 获取视频总帧数
frame_list = []
picks = []
video_feat = None
video_feat_for_train = None
for frame_idx in tqdm(range(n_frames - 1)):
success, frame = video_capture.read() # 读取下一帧
if success:
frame_feat = self._extract_feature(frame)
picks.append(frame_idx)
if video_feat is None:
video_feat = frame_feat
else:
video_feat = np.vstack((video_feat, frame_feat))
else:
break
video_capture.release()
print("shape of video_feat",video_feat.shape)
self.h5_file['video_{}'.format(video_idx + 1)]['features'] = list(video_feat)
完整代码:
import argparse
import torch as t
import os
from torchvision.models import googlenet
# tqdm 进度条库
from tqdm import tqdm
import cv2
import numpy as np
import h5py
parser = argparse.ArgumentParser("Pytorch code for unsupervised video feature extraction with REINFORCE")
parser.add_argument('--ID', type=str)
parser.add_argument('--ID_VideoName', type=str)
parser.add_argument('--VideoName', type=str)
args = parser.parse_args()
# Pytorch 提供 torchvision.models 接口,里面包含了一些常用用的网络结构,并提供了预训练模型,可以通过简单调用来读取网络结构和预训练模型。
class Extract_Feature:
def __init__(self, video_path, save_path):
self.google = googlenet(pretrained=True)
self.google.float()
self.google.cuda()
self.google.eval()
self.video_list = []
self.video_path = ''
self.h5_file = h5py.File(save_path, 'w')
self._set_video_list(video_path)
# 获取所有的视频,创建相应的h5文件
def _set_video_list(self, video_path):
# 如果video_path是目录,获取目录下的所有文件名并排序
if os.path.isdir(video_path):
self.video_path = video_path
self.video_list = os.listdir(video_path)
self.video_list.sort()
else:
self.video_path = ''
self.video_list.append(video_path)
for idx, file_name in enumerate(self.video_list):
# H5PY采用create_group命令进行创建
self.h5_file.create_group('video_{}'.format(idx + 1))
# 提取特征
def _extract_feature(self, frame):
# 改变图像的颜色空间
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# 对图片进行缩放
frame = cv2.resize(frame, (224, 224))
EF = [frame[:, :, 0], frame[:, :, 1], frame[:, :, 2]]
EF = np.array(EF)
# torch.from_numpy()方法把数组转换成张量,且二者共享内存,对张量进行修改比如重新赋值,那么原始数组也会相应发生改变
# unsqueeze(dim=0)对0维度扩展一维
frameTen = t.from_numpy(EF).unsqueeze(dim=0).cuda().float()
res_pool5 = self.google(frameTen)
frame_feat = res_pool5.cpu().data.numpy().flatten()
return frame_feat
def generate_dataset(self):
print('generating...')
print("video_list",self.video_list)
for video_idx, video_filename in enumerate(self.video_list):
video_path = video_filename
if os.path.isdir(self.video_path):
video_path = os.path.join(self.video_path, video_filename)
video_capture = cv2.VideoCapture(video_path) # 读取视频
fps = video_capture.get(cv2.CAP_PROP_FPS) # 获取视频帧率
n_frames = int(video_capture.get(cv2.CAP_PROP_FRAME_COUNT)) # 获取视频总帧数
frame_list = []
picks = []
video_feat = None
video_feat_for_train = None
for frame_idx in tqdm(range(n_frames - 1)):
success, frame = video_capture.read() # 读取下一帧
if success:
frame_feat = self._extract_feature(frame)
picks.append(frame_idx)
if video_feat is None:
video_feat = frame_feat
else:
video_feat = np.vstack((video_feat, frame_feat))
else:
break
video_capture.release()
print("shape of video_feat",video_feat.shape)
self.h5_file['video_{}'.format(video_idx + 1)]['features'] = list(video_feat)
if __name__ == '__main__':
# 要处理的视频所在的目录
short_video_path_dir = '/opt/data/private/xuyunyang/EasyCut/' + args.ID + '/' + args.ID_VideoName + '/Key_Frame/' + args.VideoName
dirs = os.listdir(short_video_path_dir)
for file in dirs:
short_video_path = short_video_path_dir + '/' + file
short_video_name = short_video_path.split('/')[-1].split('.')[0]
# h5文件的保存地址
result_path_dir = '/opt/data/private/xuyunyang/EasyCut/' + args.ID + '/' + args.ID_VideoName + '/SceneFeature/'
if not os.path.exists(result_path_dir):
os.makedirs(result_path_dir)
result_path = os.path.join(result_path_dir, short_video_name + '.h5')
gen = Extract_Feature(short_video_path, result_path)
gen.generate_dataset()
gen.h5_file.close()
运行结果: