2021-11-07大数据学习日志——MySQL进阶——窗口函数
01_窗口函数概述
学习目标
- 了解窗口函数的优点
1.1 窗口函数
接下来的课程中我们来介绍窗口函数window functions.
- MYSQL 8.0 之后,加入了窗口函数功能,简化了数据分析工作中查询语句的书写
- 在没有窗口函数之前,我们需要通过定义临时变量和大量的子查询才能完成的工作,使用窗口函数实现起来更加简洁高效
- 窗口函数是数据分析工作中必须掌握的工具,在SQL笔试中也是高频考点
- 为什么说窗口函数可以使复杂的查询变得更加简单方便?
1.1.1 窗口函数示例
示例:聚合函数 VS 窗口函数
1)假设我们有如下这个 students 表格:

2)如果要按性别获取平均GPA,可以使用聚合函数并运行以下查询:
SELECT
Gender,
AVG(GPA) AS avg_gpa
FROM students
GROUP BY Gender;结果如下:

现在我们想得到如下结果:

3)我们当然可以用我们刚刚提到的聚合函数,然后再将结果join到初始表,但这需要两个步骤。
SELECT
s.*,
g.avg_gpa
FROM students s
JOIN (
SELECT
Gender,
AVG(GPA) AS avg_gpa
FROM students
GROUP BY Gender
) g
ON s.Gender=g.Gender;4)但如果我们使用窗口函数,我们则可以一步到位,并得到相同的结果:
SELECT
*,
AVG(GPA) OVER (PARTITION BY Gender) as avg_gpa
FROM students;通过上面的查询,就按性别对数据进行划分,并计算每种性别的平均GPA。然后,它将创建一个称为avg_gpa的新列,并为每行附加关联的平均GPA
1.1.2 窗口函数的优点
1)简单
- 窗口函数更易于使用。在上面的示例中,与使用聚合函数然后合并结果相比,使用窗口函数的 SQL 语句更加简单。
2)快速
- 这一点与上一点相关,使用窗口函数比使用替代方法要快得多。当你处理成百上千个千兆字节的数据时,这非常有用。
3)多功能性
- 最重要的是,窗口函数具有多种功能,比如:添加移动平均线、添加行号和滞后数据等等。
02_窗口函数基本用法
学习目标
- 掌握窗口函数的基本语法和OVER()的使用方法
2.1 OVER() 关键字
2.1.1 数据集介绍
本小节我们先介绍窗口函数中最重要的关键字 OVER()
在介绍具体内容之前先熟悉一下要用到的数据,我们选择了很常见的业务来介绍窗口函数的使用
- 三张表:员工表、部门表、采购表
- 员工表:员工id、姓名、员工所属部门id(
department_id)、工资(salary)、工龄(years_worked) - 部门表:部门id、部门名称
- 采购表:每个部门(
department_id)、采购的物品明细(item)、物品价格(price)
员工表(employee)
 部门表(department)
部门表(department)

采购表(purchase)
2.1.2 什么是窗口函数?
窗口函数是对表中一组数据进行计算的函数,一组数据跟当前行相关
例如:想计算每三天的销售总金额,就可以使用窗口函数,以当前行为基准,选前一行,后一行,三行一组如下图所示:

之所以称之为窗口函数,是因为好像有一个固定大小的窗框划过数据集,滑动一次取一次,对窗口内的数据进行处理。
窗口函数的语法:
OVER (...)
COUNT()、SUM()、AVG()等)- 也以是其他函数,比如ranking 排序函数、分析函数等,后面的课程中会介绍
OVER(...)窗口函数的窗口通过OVER(...)子句定义,窗口函数中很重要的部分就是通过OVER(...)定义窗口 (开窗方式和大小)
2.1.3 OVER()基本用法
练习1
需求:创建报表,除了查询每个人的工资之外,还要统计出公司每月的工资总支出
查询结果字段:
- first_name、last_name、salary(工资)、sum(公司每月工资总支出)
SELECT
first_name,
last_name,
salary,
SUM(salary) OVER() AS `sum`
FROM employee;OVER()意思是所有的数据都在窗口中SUM(salary)意思是要计算工资的和,加上OVER()意味着对全部数据进行计算,所以就是在计算所有人的工资之和,也就是公司每月的工资总支出
查询结果

练习2
需求:统计采购表中的平均采购价格,并与明细一起显示(每件物品名称,价格)
查询结果字段:
- item(物品名称)、price、avg(平均采购价格)
SELECT
item,
price,
AVG(price) OVER() as `avg`
FROM purchase;查询结果

2.1.4 将OVER()的结果用于进一步计算
通常,
OVER()用于将当前行与一个聚合值进行比较。
练习3
需求:创建报表统计每个员工的工资和平均工资之间的差。
查询结果字段:
- first_name、last_name、salary(工资)、avg(平均工资)、difference(工资和平均工资的差值)
SELECT
first_name,
last_name,
salary,
AVG(salary) OVER() AS `avg`,
salary - AVG(salary) OVER() AS `difference`
FROM employee;查询结果:

上面查询结果的最后一列显示了每名员工的工资和平均工资之间的差额,这就是窗口函数的典型应用场景:将当前行与一组数据的聚合值进行比较
练习4
需求:统计id为2的部门所采购的所有商品,并将计算了每项支出占总采购金额的占比
查询结果字段:
- id、item(物品名称)、price(采购价格)、percent(支出占采购总金额的占比)
SELECT
id,
item,
price,
price / SUM(price) OVER() AS `percent`
FROM purchase
WHERE department_id=2;查询结果

2.1.5 OVER()的作用范围
窗口函数是可以与 WHERE 一起使用的,但是 WHERE 与窗口函数那个先执行呢?
练习5
需求:创建报表统计 id 为1的部门中每个员工的工资和该部门平均工资之差
查询结果字段:
- first_name、last_name、salary(工资)、avg(平均工资)、difference(工资和部门平均工资的差值)
SELECT
first_name,
last_name,
salary,
AVG(salary) OVER() AS `avg`,
salary - AVG(salary) OVER() AS `difference`
FROM employee
WHERE department_id=1;查询结果

在上面的SQL中,我们通过WHERE department_id=1,过滤出部门ID为1的数据,窗口函数只作用于id = 1的部门
需要记住,窗口函数在
WHERE子句后执行!
练习6
需求:查询部门id为1、2、3三个部门员工的姓名,薪水,和这三个部门员工的平均工资
查询结果字段:
- department_id、first_name、last_name、salary(工资)、avg(三个部门的平均工资)
SELECT
department_id,
first_name,
last_name,
salary,
AVG(salary) OVER() as `ave`
FROM employee
WHERE department_id IN (1, 2, 3);查询结果

2.1.6 在过滤条件中使用OVER()
看下面的SQL,我们打算查询所有员工中,薪资高于平均薪资的员工:
SELECT
first_name,
last_name,
salary,
AVG(salary) OVER() AS `avg`
FROM employee
WHERE salary > AVG(salary) OVER();上面的 SQL 能否正确执行?
- 执行上面的SQL时会返回错误信息:
3593 - You cannot use the window function 'avg' in this context. - 原因是:窗口函数在WHERE子句之后执行,把窗口函数写在WHERE子句中会导致循环依赖
03_PARTITION BY
学习目标
- 掌握 OVER(PARTITION BY)的使用方法
3.1 PARTITION BY基本用法
3.1.1 PARTITION BY简介
接下来,我们来介绍如何在OVER()中添加 PARTITION BY,基本的语法如下:
OVER(PARTITION BY column1, column2 ... column_n)
PARTITION BY 的作用与 GROUP BY类似:将数据按照传入的列进行分组,与 GROUP BY 的区别是, PARTITION BY 不会改变结果的行数
PARTITION BY与GROUP BY区别:
1)普通的聚合函数用GROUP BY分组,每个分组返回一个统计值;而分析函数采用PARTITION BY分组,并且每组每行都可以返回一个统计值
2)在执行顺序上:
FROM > WHERE > GROUP BY > HAVING
PARTITION BY应用在以上关键字之后,可以简单理解为就是在执行完 SELECT 之后,在所得结果集之上进行PARTITION BY分组
3.1.2 数据集介绍
不同型号火车基本信息表(train)

first_class_places:一等座,second_class_places:二等座
运营线路表(route)

票价表(ticket)

时刻表(journey)

3.1.3 PARTITION BY基本使用
练习1
需求:查询每种类型火车的ID,型号,一等座数量,同型号一等座数量总量
查询结果字段:
- id、model(火车型号)、first_class_places(一等座数量)、sum(同型号一等座数量总量)

GROUP BY实现:
SELECT
id,
t.model,
first_class_places,
c.sum
FROM train t
JOIN (
SELECT
model,
SUM( first_class_places ) AS sum
FROM train
GROUP BY model
) c
ON t.model=c.model;窗口函数实现:
SELECT
id,
model,
first_class_places,
SUM(first_class_places) OVER (PARTITION BY model) AS `sum`
FROM train;如果用
GROUP BY实现上面的需求,我们需要通过子查询将结果与原始表JOIN, 对比起来,使用窗口函数的实现更加简洁
练习2
需求:查询每天的车次数量
查询结果字段:
- id(时刻表车次ID)、date(日期)、count(每天的车次数量)
SELECT
id,
date,
COUNT(id) OVER(PARTITION BY date) as `count`
FROM journey;查询结果

练习3
需求:按车型分组,每组中满足一等座>30,二等座>180的有几条记录
查询结果字段:
- id、model(车型)、first_class_places(一等座数量)、second_class_places(二等座数量)、count(该车型中一等座>30,二等座>180的有几条记录)
SELECT
id,
model,
first_class_places,
second_class_places,
COUNT(id) OVER (PARTITION BY model) AS `count`
FROM train
WHERE first_class_places > 30 AND second_class_places > 180;查询结果

3.1.4 PARTITION BY传入多列
练习4
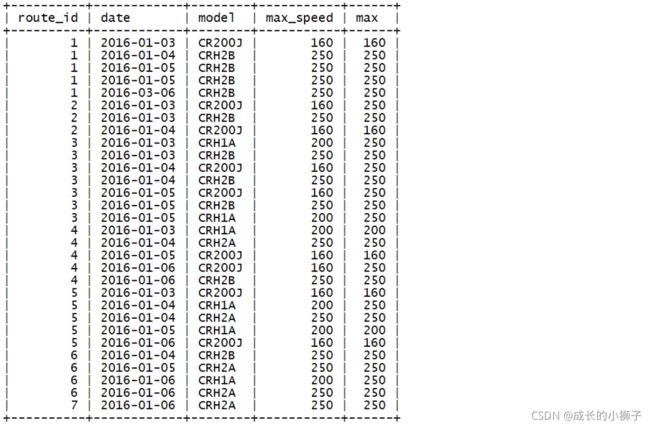
需求:查询每天、每条线路速的最快车速
查询结果字段:
- route_id(线路ID)、date(日期)、model(车型)、max_speed(该车型最大车速)、max(每天相同线路最大车速)
SELECT
j.route_id,
j.date,
t.model,
t.max_speed,
MAX(max_speed) OVER(PARTITION BY route_id, date) AS `max`
FROM journey j
JOIN train t
ON j.train_id=t.id;查询结果
练习5
需求:查询票价表信息,并统计每天的在售车票的平均价格,每天的在售车票种类。(注意:不统计运营车辆id为5的数据)
查询结果字段:
- id(票价ID)、date(日期)、price(票价)、avg(每天平均票价)、count(每天在售车票种类)
SELECT
t.id,
date,
price,
AVG(price) OVER(PARTITION BY date) AS `avg`,
COUNT(t.id) OVER(PARTITION BY date) AS `count`
FROM ticket t
JOIN journey j
ON t.journey_id = j.id
WHERE train_id != 5; 查询结果
04_排序函数
学习目标
- 掌握窗口函数中,排序函数(ranking function)的使用方法
4.1 排序函数使用
到目前为止,我们已经介绍了如何在窗口函数中使用聚合函数
SUM()、COUNT()、AVG()、MAX()和MIN()
接下来,我们将学习如何通过窗口函数实现排序,具体语法如下:
OVER (ORDER BY )
4.1.1 数据集介绍
游戏信息表(game)

游戏销售表(game_purchase)
4.1.2 RANK()函数
首先我们来介绍使用最多的 RANK 函数,使用方法如下:
RANK() OVER (ORDER BY ...)
ORDER BY按指定的列对数据进行排序,RANK()是一个函数,与ORDER BY配合返回序号
练习1
需求:对所有游戏数据按编辑评分排序,并返回排序后的排名序号
查询结果字段:
- name(游戏名称)、platform(平台)、editor_rating(编辑评分)、rank(排序后的排名序号)
SELECT
name,
platform,
editor_rating,
RANK() OVER(ORDER BY editor_rating) AS `rank`
FROM game;查询结果:

观察上面的查询结果:
- 最后一列 rank 中显示了游戏的得分排名,得分最低(4分)的三个游戏并列倒数第一
- 得分为5分的游戏,排名为4,这里并没有2和3 ,这个就是
RANK()函数的特点,当有并列的情况出现时,序号是不连续的
4.1.3 DENSE_RANK()函数
- RANK() 函数返回的序号,可能会出现不连续的情况
- 如果想在有并列情况发生的时候仍然返回连续序号可以使用
DENSE_RANK()函数
练习2
需求:将练习1的示例换成DENSE_RANK()函数
SELECT
name,
platform,
editor_rating,
DENSE_RANK() OVER(ORDER BY editor_rating) as `dense_rank`
FROM game;查询结果

- 从上面的结果中看出,
DENSE_RANK()列的序号是连续的,跟RANK()有明显的区别
4.1.4 ROW_NUMBER()函数
- 想获取排序之后的序号,也可以通过
ROW_NUMBER()来实现,从名字上就能知道,意思是返回行号
练习3
需求:将练习1的示例换成ROW_NUMBER()函数
SELECT
name,
platform,
editor_rating,
ROW_NUMBER() OVER(ORDER BY editor_rating) `row_number`
FROM game;查询结果
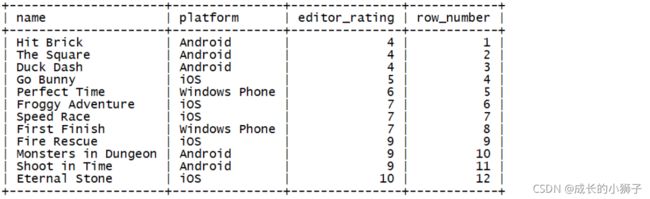
- 从上面的结果可以看出,
ROW_NUMBER()返回的是唯一行号,跟RANK()和DENSE_RANK()返回的是序号,序号会有并列情况出现
练习4
需求:对比
RANK()、DENSE_RANK()、ROW_NUMBER()之间的区别,对上面的案例同时使用三个函数
SELECT
name,
platform,
editor_rating,
RANK() OVER(ORDER BY editor_rating) as `rank_num`,
DENSE_RANK() OVER(ORDER BY editor_rating) as `dense_rank_num`,
ROW_NUMBER() OVER(ORDER BY editor_rating) as `row_num`
FROM game;查询结果

4.1.5 RANK()与ORDER BY多列排序
练习5
需求:查找比较新且安装包体积较小的游戏(
released,size),并使用RANK()返回序号查询结果字段:
- name(游戏名称)、genre(游戏类型)、released(发布日期)、size(包大小)、rank(序号)
SELECT
name,
genre,
released,
size,
RANK() OVER(ORDER BY released DESC, size ASC) `rank`
FROM game;查询结果

4.1.6 在窗口函数外使用ORDER BY
之前的例子中,ORDER BY 排序都是写在窗口函数OVER() 中,窗口函数也可以和常规的ORDER BY写法一起使用,看下面的例子
练习6
需求:按照游戏的编辑评分添加序号(使用RANK),最终结果使用游戏大小降序排列
查询结果字段:
- name(游戏名称)、size(游戏大小)、editor_rating(编辑评分)、rank(编辑评分序号)
SELECT
name,
size,
editor_rating,
RANK() OVER (ORDER BY editor_rating) `rank`
FROM game
ORDER BY size DESC;查询结果

- 从查询结果可以看出,
RANK()返回的序号是依据editor_rating列的大小进行排序的 - 最终的查询结果是按照安装包大小进行排序的
练习7
需求:在游戏销售表中添加日期排序序号(使用ROW_NUMBER函数)-按日期从近到远排序,最终结果按打分
editor_rating排序查询结果字段:
- name(游戏名称)、price(销售价格)、editor_rating(编辑评分)、date(日期)、row_number(日期序号)
SELECT
name,
price,
editor_rating,
date,
ROW_NUMBER() OVER(ORDER BY date DESC) `row_number`
FROM game_purchase gp
JOIN game g
ON gp.game_id = g.id
ORDER BY editor_rating;查询结果

4.1.7 NTILE(X)函数
NTILE(X)函数将数据分成X组,并给每组分配一个数字(1,2,3....)。
例如:
SELECT
id,
name,
genre,
editor_rating,
NTILE(3) OVER (ORDER BY editor_rating DESC)
FROM game;在上面的查询中,通过 NTILE(3) 我们根据editor_rating 的高低,将数据分成了三组,并且给每组指定了一个标记
- 1:这一组是评分最高的
- 2:这一组属于中等水平
- 3:这一组是评分较低的

注意:如果所有的数据不能被平均分组,那么有些组的数据会多一条,数据条目多的组会排在前面
练习8
需求:将所有的游戏按照安装包大小分成4组,返回游戏名称,类别,安装包大小,和分组序号
查询结果字段:
- name(游戏名称)、genre(类别)、size(安装包大小)、ntile(分组序号)
SELECT
name,
genre,
size,
NTILE(4) OVER (ORDER BY size DESC) `ntile`
FROM game;查询结果

4.1.8 排序函数综合练习
我们已经介绍了排序函数,由于数据量较小,我们将所有数据排序,并返回所有序号。接下来我们看一下如何返回指定排名的数据。
练习9
需求:查找打分排名第二的游戏
WITH ranking AS (
SELECT
name,
DENSE_RANK() OVER(ORDER BY editor_rating DESC) AS `rank`
FROM game
)
SELECT name
FROM ranking
WHERE `rank`=2;查询结果

练习10
需求:查询安装包大小最小的游戏,返回游戏名称,类别,安装包大小
查询结果字段:
- name(游戏名称)、genre(类别)、size(安装包大小)
WITH ranking AS (
SELECT
name,
genre,
size,
DENSE_RANK() OVER(ORDER BY size) AS `rank`
FROM game
)
SELECT
name,
genre,
size
FROM ranking
WHERE `rank`=1;查询结果

05_window frames 自定义窗口
学习目标:
- 掌握window frames的使用方法
5.1 windows frames 自定义窗口
5.1.1 数据介绍
本小节用到的数据来自一家冰雪相关产品的公司
产品表(product):记录该公司的产品信息

库存变化表(stock_change):记录了仓库中商品变化情况,出库,入库
id:每一次库存变化都对应一个idproduct_id:库存发生变化的产品IDquantity:库存变化数量(正数代表入库, 负数代表出库),changed:发生库存变化的时间

订单表(single_order):记录订单基本信息
id:订单IDplaced:下单日期total_price:订单总价

订单详情表(order_position)
id:主键product_id:订单中包含的商品idorder_id:该条记录对应的订单编号quantity:订单对应商品数量

5.1.2 window frames概述
窗口框架(window frames) 可以以当前行为基准,精确的自定义要选取的数据范围
例如:想选取当前行的前两行和后两行一共 5 行数据进行统计,相当于自定义一个固定大小的窗口,当当前行移动的时候,窗口也会随之移动
看下面的例子,我们选中了当前行的前两行和后两行,一共5行数据:

定义 window frames 有两种方式:
ROWS和RANGE
具体语法如下:
OVER (
...
ORDER BY
[ROWS|RANGE]
) 上面的SQL框架中,... 代表了之前我们介绍的例如 PARTITION BY 子句,下面我们先关注 ROWS 和 RANGE的用法,然后再加上PARTITION BY
练习1
需求:查询销售订单信息,按日期计算截止到每行的订单总价累加和
查询结果字段:
- id、placed(下单日期)、total_price(订单总价)、sum(截至到每行的订单总价累加和)
SELECT
id,
placed,
total_price,
SUM(total_price) OVER(
ORDER BY placed
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS `sum`
FROM single_order;- 在上面的查询中,我们对
total_price列求和。 对于每一行,我们将当前行与它之前的所有行(“ UNBOUNDED PRECEDING”)相加,total_price列相当于到当前行的累加和,这个值随着当前行的变化而增加
查询结果

5.1.3 window frames定义
上面小节中介绍过,我们有两种方式来定义窗口大小(window frames):
ROWS和RANGE
我们先介绍比较容易理解的ROWS方式,通用的语法如下:
ROWS BETWEEN upper_bound AND lower_bound
在上面的框架中,BETWEEN ... AND ... 意思是在... 之间,上限(upper_bund)和下限(lower_bound)的取值为如下5种情况:
UNBOUNDED PRECEDING:对上限无限制PRECEDING: 当前行之前的 n 行 ( n 表示具体数字如:5PRECEDING)CURRENT ROW:仅当前行FOLLOWING:当前行之后的 n 行 ( n 表示具体数字如:5FOLLOWING)-
UNBOUNDED FOLLOWING:对下限无限制 -
需要注意的是:upper_bound 需要在 lower_bound 之前,比如:
ROWS BETWEEN CURRENT ROW AND UNBOUNDED PRECEDING是错误的写法
练习2
需求:按日期统计到当前行为止的累计下单金额(running_total),以及前后3天下单金额总和(sum_3_before_after)
查询结果字段:
- id、placed(下单日期)、total_price(订单总价)、running_total(累计下单金额)、sum_3_before_after(前后3天累计下单金额)
SELECT
id,
placed,
total_price,
SUM(total_price) OVER(
ORDER BY placed ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS `running_total`,
SUM(total_price) OVER(
ORDER BY placed ROWS BETWEEN 3 PRECEDING AND 3 FOLLOWING
) AS `sum_3_before_after`
FROM single_order;查询结果

练习3
需求:仓库发货时需要手工拣货。 对于order_id = 5的订单,计算未分拣的商品数量总和
思路:对于该订单中的每种商品,按升序查询起出货明细中的ID,产品ID,产品数量和剩余未拣货商品的数量(包括当前行)
查询结果字段:
- id、product_id(产品ID)、quantity(产品数量)、sum(剩余未拣货的商品数量)
SELECT
id,
product_id,
quantity,
SUM(quantity) OVER(
ORDER BY id
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING
) AS `sum`
FROM order_position
WHERE order_id = 5;查询结果

练习4
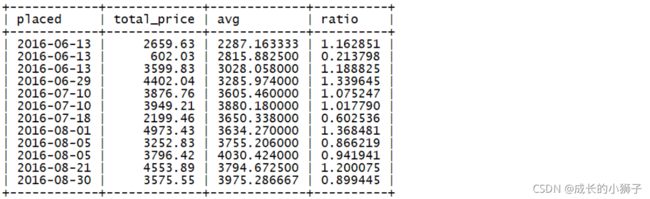
需求:针对每一笔订单,统计下单日期,订单订单总价,每5笔订单计算一次平均价格(当前行,前后各两行,按下单日期排序),并计算当前订单总价和每5笔订单平均总价的比率
查询结果字段:
- placed(下单日期)、total_price(订单总价)、avg(前后2笔订单平均订单总价)、ratio(比率)
SELECT
placed,
total_price,
AVG(total_price) OVER(
ORDER BY placed
ROWS BETWEEN 2 PRECEDING AND 2 FOLLOWING
) AS `avg`,
total_price / AVG(total_price) OVER(
ORDER BY placed
ROWS BETWEEN 2 PRECEDING AND 2 FOLLOWING
) AS `ratio`
FROM single_order;查询结果
5.1.4 window frames定义的简略写法
如果在我们定义 window frames 的边界时,使用了CURRENT ROW作为上边界或者下边界,可以使用如下简略写法:
ROWS UNBOUNDED PRECEDING等价于BETWEEN UNBOUNDED PRECEDING AND CURRENT ROWROWS n PRECEDING等价于BETWEEN n PRECEDING AND CURRENT ROW-
ROWS CURRENT ROW等价于BETWEEN CURRENT ROW AND CURRENT ROW -
注意,这种简略的写法不适合
FOLLOWING的情况
练习5
需求:统计product_id 为3的商品库存变化情况,按照进出库日期排序,并统计库存变化当日的累计库存
查询结果字段:
- id、product_id(商品id)、changed(库存变化日期)、quantity(数量)、sum(累计库存)
SELECT
id,
product_id,
changed,
quantity,
SUM(quantity) OVER(
ORDER BY changed
ROWS UNBOUNDED PRECEDING
) AS `sum`
FROM stock_change
WHERE product_id = 3;查询结果

练习6
需求:统计每个订单的下单日期,总价,每4个订单的平均总价(当前行以及前3行,按下单日期排序)
查询结果字段:
- id、placed(下单日期)、total_price(订单总价)、avg(每4个订单的平均总价)
SELECT
placed,
total_price,
AVG(total_price) OVER(
ORDER BY placed
ROWS 3 PRECEDING
) AS `avg`
FROM single_order;查询结果

5.1.5 使用 RANGE 定义window frames
ROWS和RANGE
练习7
需求:从订单表中,提取出下单日期,订单总价,按日期排序统计到当前行为止的累计下单金额
查询结果字段:
- id、placed(下单日期)、row_number(唯一行号)、total_price(下单金额)、running_sum(累计下单金额)
SELECT
id,
placed,
ROW_NUMBER() OVER(ORDER BY placed) as `row_number`,
total_price,
SUM(total_price) OVER(
ORDER BY placed
ROWS UNBOUNDED PRECEDING
) AS `running_sum`
FROM single_order;
在上面的SQL查询中,使用 ROWS 会对所有行号小于等于当前行的total_price求和
- 这里 window frames 是
ROWS UNBOUNDED PRECEDING - 相当于
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW当前行之前所有行
练习8
需求:从订单表中,提取出下单日期,订单总价,按日期排序统计到每天为止的累计下单金额
查询结果字段:
- id、placed(下单日期)、rank(按下单日期排名序号)、total_price(下单金额)、running_sum(累计下单金额)
SELECT
id,
placed,
RANK() OVER(ORDER BY placed) as `rank`,
total_price,
SUM(total_price) OVER(
ORDER BY placed
RANGE UNBOUNDED PRECEDING
) AS `running_sum`
FROM single_order;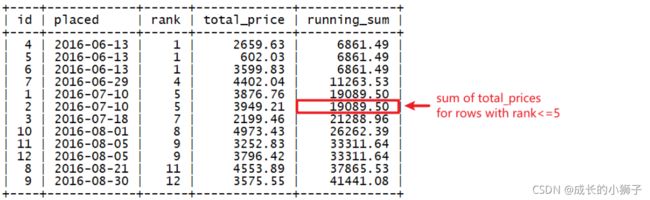
上面的SQL中使用了RANGE , 对所有RANK()小于或等于当前行的排名的所有行total_price求和
RANGE使用BETWEEN AND
和使用 ROWS一样,使用RANGE 一样可以通过 BETWEEN ... AND... 来自定义窗口
在使用RANGE 时,我们一般用
RANGE UNBOUNDED PRECEDINGRANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWINGRANGE CURRENT ROW
注意:在使用
RANGE确定窗口大小时,一般 不与 n PRECEDING 或 n FOLLOWING 一起使用原因:
- 使用ROWS,通过当前行计算前n行/后n行,很容易确定窗口大小
- 使用RANGE,是通过行值来进行判断,如果使用3 PRECEDING 或 3 FOLLOWING 需要对当前行的值进行-3 或者+3操作,具体能选中几行很难确定,通过WINDOW FRAMES我们希望定义的窗口大小是固定的、可预期的,但当RANGE 和n PRECEDING 或 n FOLLOWING 具体会选中几行数据,跟随每行取值不同而发生变化,窗口大小很可能不固定
练习9
需求:统计product_id 为7 的产品的每天的库存变化
查询结果字段:
- id、quantity(数量)、changed(变化日期)、count(每天库存变化的次数)
SELECT
id,
quantity,
changed,
COUNT(id) OVER(ORDER BY changed RANGE CURRENT ROW) AS `count`
FROM stock_change
WHERE product_id = 7;查询结果

练习10
需求:统计库存变化情况
查询结果字段:
- id、changed(库存变化发生日期)、库存变化到当前日期为止的累计次数
count
SELECT
id,
changed,
COUNT(id) OVER(
ORDER BY changed
RANGE UNBOUNDED PRECEDING
) AS `count`
FROM stock_change;查询结果
练习11
需求:统计累计销售金额
查询结果字段:
- id、placed(下单日期)、total_price(订单金额)、sum(累计金额,按下单日期由远及近,统计当前日期之后的 total_price 之和)
SELECT
id,
placed,
total_price,
SUM(total_price) OVER(
ORDER BY placed
RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING
) AS `sum`
FROM single_order;查询结果

5.1.6 默认的window frames
在之前的小节中,我们并没有写RANGE 或 ROWS 这样的语句,这种情况下,会有一个默认的window frames 在工作,分两种情况:
- 如果在OVER(...)中没有ORDER BY子句,则所有行视为一个window frames
- 如果在OVER(...)中指定了ORDER BY子句,则会默认添加
RANGE UNBOUNDED PRECEDING作为window frames
示例1:
我们先看OVER(...)中没有ORDER BY子句的情况
SELECT
id,
placed,
total_price,
SUM(total_price) OVER() AS `sum`
FROM single_order;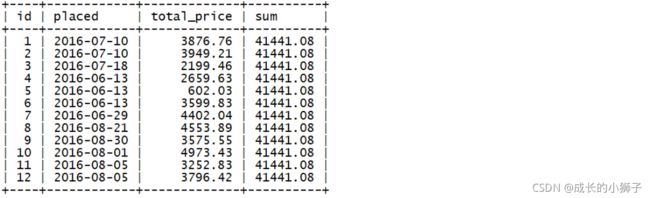
上面的SQL中查询了全部订单的总价,这里没有指定window frames ,默认情况就是计算全部数据
示例2:
我们再看一下包含ORDER BY 的情况
SELECT
id,
placed,
total_price,
SUM(total_price) OVER(ORDER BY placed) AS `sum`
FROM single_order;
上面的SQL来自之前的练习,统计了每笔订单的下单日期,订单金额,和以天为单位的累计订单金额。
我们可以在上面的OVER中,ORDER BY后面加上 RANGE UNBOUNDED PRECEDING, 最终会得到相同的结果
06_分析函数
学习目标
- 掌握 LEAD、LAG、FIRST_VALUE、LAST_VALUE、NTH_VALUE 函数的使用方法
6.1 分析函数使用
6.1.1 数据集介绍
接下来要使用的是一个点击广告业务的数据集,通过用户点击广告收费,共两张表格,一张访问信息统计表(statistics),一张网站表(website)
网站表(website)
idname(网站名字)budget(每月预算)opened(开始运营的日期)

访问信息统计表(statistics):此表记录了2016年5月的统计信息
website_id:网站IDday:访问日期user:显示当天该网站的UV(unique visit,独立IP,一个UV代表一个用户)impressions: 广告展示的次数clicks:是指广告的点击次数revenue:每日点击产生的收入

6.1.2 LEAD(X)函数
与之前介绍的聚合函数和排序函数语法类似
OVER (...)
与聚合函数不同的地方是,分析函数只引用窗口中的单个行
LEAD(X)函数介绍
我们看下面的例子:
SELECT
opened,
name,
LEAD(name) OVER(ORDER BY opened)
FROM website;上面的SQL中,分析函数为LEAD(name)。 LEAD中传入name列作为参数,将以 ORDER BY 排序后的顺序,返回当前行的下一行name 列所对应的值,并在新列中显示,具体如下图所示:

注意:最后一列没有下一列结果所以这里显示NULL
- LEAD() 中传入的列名与排序的列可以不同
练习1
需求: 统计 id 为1的网站,每天访问的人数以及下一天访问的人数
查询结果字段:
- day(日期)、users(访问人数)、lead(下一天访问人数)
SELECT
day,
users,
LEAD(users) OVER(ORDER BY day) AS `lead`
FROM statistics
WHERE website_id = 1;查询结果

使用LEAD()函数计算增量
LEAD函数在计算增量的时候非常有用,比如我们想比较同一列两个值的差值
需求:计算 id 为 2 的网站当日广告点击次数和前一日广告点击次数的差值
查询结果字段:
- day(日期)、clicks(当日广告点击次数)、lead(前一日广告点击次数)、difference(点击次数差值)
SELECT
day,
clicks,
LEAD(clicks) OVER(ORDER BY day DESC) AS `lead`,
clicks - LEAD(clicks) OVER(ORDER BY day DESC) AS `difference`
FROM statistics
WHERE website_id = 2;
从业务角度来看,这可以很容易地告诉我们有关该网站的很多信息
- 如果大多数增量是正的,且增量在逐渐变大,那么该网站业务可能处于上升期
- 如果大多数是负的,那么需要找到下滑的原因
LEAD(x, y)
LEAD函数还可以传入两个参数:
- 参数1 跟传入一个参数时的情况一样:一列的列名
- 参数2 代表了偏移量,如果传入2 就说明要以当前行为基准,当前行向后移动2行的指定列作为返回值
练习 2
需求:统计 id 为 2 的网站,在2016年5月1日到5月14日之间,每天的用户访问数量以及7天后的用户访问数量
查询结果字段:
- day(访问日期)、users(用户访问量)、lead(7日后的用户访问量)
SELECT
day,
users,
LEAD(users, 7) OVER(ORDER BY day) AS `lead`
FROM statistics
WHERE website_id = 2
AND day BETWEEN '2016-05-01' AND '2016-05-14';查询结果
需要注意,最后7行最后一列会返回NULL,因为最后7行没有7日后的数据

LEAD(x, y, z)
- lead函数也可以接收三个参数,第三个参数用来传入默认值,应用场景是当使用lead函数返回null的时候,可以用第三个参数传入的默认值进行填充
需求:在练习2中,后7行出现了NULL,这里可以传入默认值,如-1,用来避免出现NULL的情况
SELECT
day,
users,
LEAD(users, 7, -1) OVER(ORDER BY day) AS `lead`
FROM statistics
WHERE website_id = 2
AND day BETWEEN '2016-05-01' AND '2016-05-14';查询结果

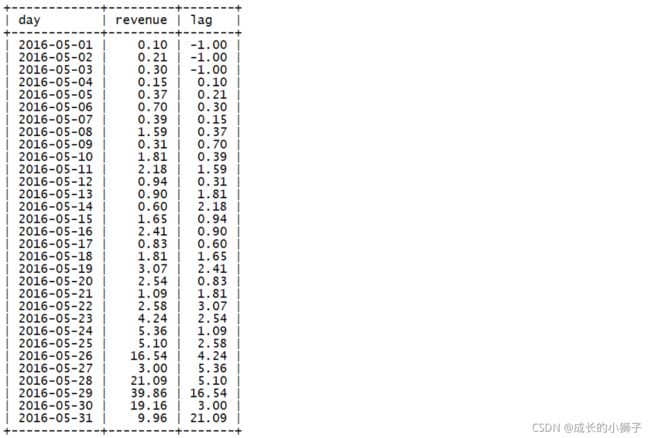
6.1.3 LAG(x)函数
LAG(x)函数与LEAD(x)用法类似,区别是LEAD返回当前行后面的值,LAG返回当前行之前的值
示例:
SELECT
opened,
name,
LAG(name) OVER(ORDER BY opened)
FROM website;上面的SQL会返回当前日期行的前一行的name:

练习3
需求:统计id为3的网站每天的广告点击数量,前一天的广告点击数量
查询结果字段:
- day(日期)、clicks(当天广告点击数量)、lag(前一天广告点击数量)
SELECT
day,
clicks,
LAG(clicks) OVER(ORDER BY day) as `lag`
FROM statistics
WHERE website_id = 3;查询结果

LAG(x, y)
与LEAD(x, y)类似,LAG(x, y)返回当前行的前第y行的x列的结果
练习4
需求:统计id = 3的网站每日广告收入以及三天前的广告收入
查询结果字段:
- day(日期)、revenue(当日广告收入)、lag(三天前的广告收入)
SELECT
day,
revenue,
LAG(revenue, 3) OVER(ORDER BY day) AS `lag`
FROM statistics
WHERE website_id = 3;查询结果

LAG(x, y, z)
与LEAD(x, y, z)一样,LAG(x, y, z) 最后一个参数是默认值,用来填补NULL值
需求:在练习4中,设置 -1.00 来填充出现的 NULL 值
SELECT
day,
revenue,
LAG(revenue, 3, -1.00) OVER(ORDER BY day) AS `lag`
FROM statistics
WHERE website_id = 3;查询结果
6.1.4 FIRST_VALUE(x)函数
FISRT_VALUE函数,从名字中能看出,返回指定列的第一个值
练习5
需求:统计id = 3 的网站收入情况,返回日期,收入,和第一天的收入
查询结果字段:
- day(日期)、revenue(当日收入)、first_value(第一天收入)
SELECT
day,
revenue,
FIRST_VALUE(revenue) OVER(ORDER BY day) AS `first_value`
FROM statistics
WHERE website_id = 3;查询结果

6.1.5 LAST_VALUE(x)函数
FIRST_VALUE(x)返回第一个值,LAST_VALUE(x)返回最后一个值
练习6
需求:统计id为1的网站,每日的访问用户数,最后一天的访问用户数
查询结果字段:
- day(日期)、users(当日访问用户数)、last_day_users(最后一天的访问用户数)
SELECT
day,
users,
LAST_VALUE(users) OVER(ORDER BY day) AS `last_day_users`
FROM statistics
WHERE website_id = 1;查询结果
查询结果与我们预期的有些出入,它只返回了当前行的结果,而不是我们想要的最后一个值

LAST_VALUE 与 window frame
在上面的例子中,我们没有得到想要的结果,回顾一下之前我们所介绍的 window frame
-
当
OVER子句中包含ORDER BY时,如果我们不显式定义window frame,SQL会自动带上默认的window frame语句:RANGE UNBOUNDED PRECEDING,意味着我们的查询范围被限定在第一行到当前行(current row) -
如果想通过LAST_VALUE 与ORDER BY配合得到所有数据排序后的最后一个值,需要吧window frame语句写成
RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING或者ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
修改练习6的SQL
SELECT
day,
users,
LAST_VALUE(users) OVER(
ORDER BY day
RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
) AS `last_day_users`
FROM statistics
WHERE website_id = 1;查询结果
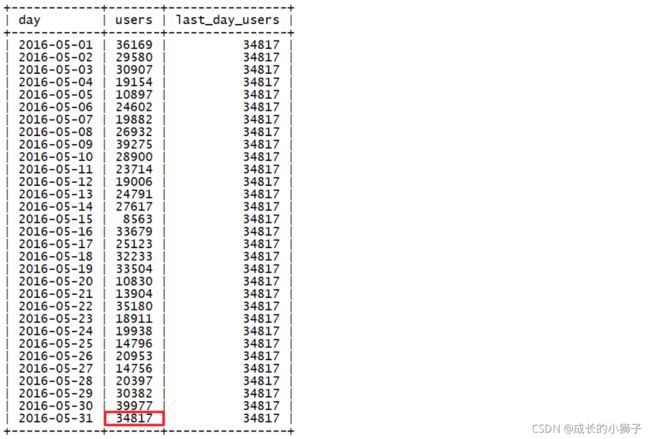
- 从上面的结果中可以看出,调整了window frame之后我们可以得到
LAST_VALUE想要的结果 FIRST_VALUE使用默认的window frame就可以正常工作,但是LAST_VALUE想要得到预期的结果需要手动修改window frame
6.1.6 NTH_VALUE(x,n)函数
NTH_VALUE(x,n)函数返回按指定顺序的第n行的x列的值
练习7
需求:统计id为2的网站的收入情况,在2016年5月15和2016年5月31日之间,每天的收入,以及这半个月内的第三高的日广告收入金额
查询结果字段:
- day(日期)、revenue(当日广告收入)、3rd_highest(半个月内的第三高的日广告收入金额)
SELECT
day,
revenue,
NTH_VALUE(revenue,3) OVER (
ORDER BY revenue DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
) AS `3rd_highest`
FROM statistics
WHERE website_id = 2
AND day BETWEEN '2016-05-15' AND '2016-05-31';- 需要注意,我们需要调整window frame 否则某些情况下不能返回正确的数据
- 提示:可以在排序的时候加上
DESC调整排序的顺序,配合NTH_VALUE(x,n)在某些场景下更加方便
查询结果

07_综合使用
学习目标
- 掌握排序函数、分析函数、window frame 与 PARTITION BY、ORDER BY 一起使用的用法
7.1 窗口函数综合使用
- 在本课程的第二部分,我们介绍了如何在OVER() 中使用PARTITION BY,它可以将数据按照列值进行分组,分组之后我们介绍了如何与
AVG()、COUNT()、MAX()、MIN()、SUM()等聚合函数配合使用- 我们在分组聚合计算时,数据的顺序并不会影响计算结果
- 在后面的课程中我们介绍了跟排序相关的内容,包括排序函数,window frames 和 分析函数
- 接下来我们将要介绍如何将 PARTITION BY 与排序函数,window frames 和 分析函数组合使用,此时需要将 PARTITION BY 与 ORDER BY 组合起来,需要注意,PARTITION BY 需要在 ORDER BY前面
7.1.1 数据集介绍
商店表(store)
- id:商店唯一编号
- country:所在国家
- city:所在城市
- opening_day:开业时间
- rating:用户对商店的评分(1-5)

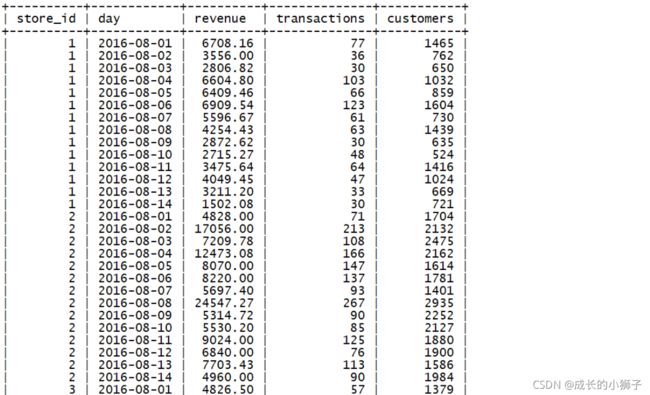
销售表(sales):表中收集了2016年8月1日至2016年8月14日期间每个商店的销售数据
- store_id:商店的ID
- day:日期
- revenue:当日总收入
- transactions:交易笔数
- customers:进店顾客数(进店不一定购买)
7.1.2 PARTITION BY回顾
练习1
需求: 统计每个商店的收入情况
查询结果字段:
- store_id(商品id)、day(日期)、revenue(当日收入)、avg_revenue(每个商店的平均收入)
SELECT
store_id,
day,
revenue,
AVG(revenue) OVER(PARTITION BY store_id) AS `avg_revenue`
FROM sales;查询结果

练习2
需求:统计2016年8月1日至8月7日之间的所有交易
查询结果字段:
- store_id(商品id)、day(日期)、transactions(交易数量)、sum(当天所有商店的总交易量)、percent(当天单店交易数量占总体的百分比四舍五入为整数值)
SELECT
store_id,
day,
transactions,
SUM(transactions) OVER(PARTITION BY day) AS `sum`,
ROUND(transactions/ SUM(transactions) OVER(PARTITION BY day)*100) AS `percent`
FROM sales
WHERE day BETWEEN '2016-08-01' AND '2016-08-07';查询结果

7.1.3 RANK() 与 PARTITION BY、ORDER BY
接下来,我们来看一下如何把 RANK() 与
PARTITION BY和ORDER BY一起使用
1)到目前为止,所有排名的计算都是基于对所有数据进行排序得到的,比如下面的SQL,我们通过对评分rating 降序排列可以将所有商店依据用户评分进行排名
SELECT
id,
country,
city,
rating,
RANK() OVER(ORDER BY rating DESC) AS `rank`
FROM store;
2)现在我们加上 PARTITION BY,可以用国家分组,对不同国家的商店按评分分别排序
SELECT
id,
country,
city,
rating,
RANK() OVER(
PARTITION BY country
ORDER BY rating DESC
) AS `rank`
FROM store;通过这种方式,我们可以得到每个国家区域内用户评分商店的第一名,第二名……

练习3
需求:统计2016年8月10日至8月14日之间的销售情况
查询结果字段:
- store_id(商品id)、day(日期)、customers(进店顾客数量)、rank(每个店铺这段时间内按顾客数量的排名)
SELECT
store_id,
day,
customers,
RANK() OVER (
PARTITION BY store_id
ORDER BY customers DESC
) AS `rank`
FROM sales
WHERE day BETWEEN '2016-08-10' AND '2016-08-14';查询结果

7.1.4 NTILE(x) 和 PARTITION BY、ORDER BY
我们也可以使用其它排序函数如NTILE(x), 用法与前面的RANK完全一致
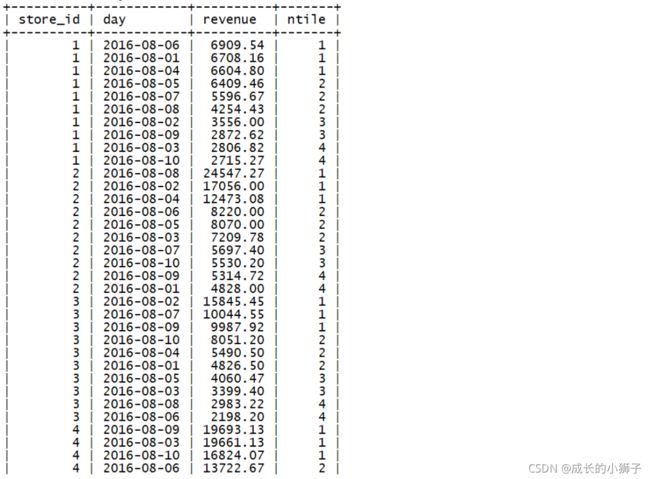
练习4
需求:统计2016年8月1日至8月10日之间的销售额,并将每个商店的销售数据按当日销售额(降序)分为4组
查询结果字段:
- store_id(商店ID)、day(日期)、revenue(当日收入)、ntile(分组编号)
SELECT
store_id,
day,
revenue,
NTILE(4) OVER (
PARTITION BY store_id
ORDER BY revenue DESC
) `ntile`
FROM sales
WHERE day BETWEEN '2016-08-01' AND '2016-08-10';查询结果
7.1.5 在CTE中使用PARTITION BY、ORDER BY
我们可以在 CTE 中使用PARTITION、BY ORDER BY将数据进一步分组,对每组进一步排序
练习5
需求:查询每个国家顾客评价最高的商店
查询结果字段:
- id、country(所在国家)、city(所在城市)、rating(顾客评分)
WITH ranking AS (
SELECT
id,
country,
city,
rating,
RANK() OVER(
PARTITION BY country
ORDER BY rating DESC
) AS `rank`
FROM store
)
SELECT
id,
country,
city,
rating
FROM ranking
WHERE `rank` = 1;- 通过在CTE中使用窗口函数来获取每个国家/地区按评分的商店排名
- 在外部查询中直接查询每个国家排名最高的店铺信息
查询结果

7.1.6 PARTITION BY、ORDER BY 和 window frames 组合
我们可以将
PARTITION BY ORDER BY与 window frames组合起来,创建更复杂的窗口
练习6
需求:分析2016年8月1日到8月7日的销售数据,分别统计每个店铺截止到当前日期的单日最高销售收入
查询结果字段:
- store_id(商品ID)、day(日期)、revenue(销售收入)、best_revenue(截止当天该店铺单日最高收入)
SELECT
store_id,
day,
revenue,
MAX(revenue) OVER(
PARTITION BY store_id
ORDER BY day
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS `best_revenue`
FROM sales
WHERE day BETWEEN '2016-08-01' AND '2016-08-07';查询结果

练习7
需求:统计2016年8月1日至2016年8月10日期间,分别统计每个商店的五日平均交易笔数(以当前行为基准,从两天前到两天后共五天)
查询结果字段:
- store_id(商品ID)、day(日期)、transactions(交易笔数)、5day_avg(五日平均交易笔数)
SELECT
store_id,
day,
transactions,
AVG(transactions) OVER(
PARTITION BY store_id
ORDER BY day
ROWS BETWEEN 2 PRECEDING AND 2 FOLLOWING
) AS `avg`
FROM sales
WHERE day BETWEEN '2016-08-01' AND '2016-08-10';查询结果

7.1.7 分析函数 与 PARTITION BY 、ORDER BY组合
接下来我们来看将分析函数与PARTITION BY ORDER BY组合使用,看下面的例子
LEAD 和 LAG
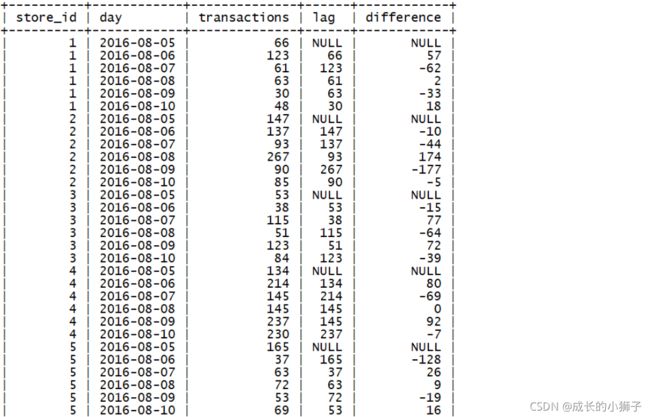
练习8
需求:统计2016年8月5日 到 2016年8月10日之间,每天的单店交易笔数,前一天交易笔数,当天和前一天的交易笔数的差值
查询结果字段:
- store_id(商品ID)、day(日期)、transactions(交易笔数)、lag(前一天交易笔数)、difference(当天和前一天的交易笔数的差值)
SELECT
store_id,
day,
transactions,
LAG(transactions) OVER(
PARTITION BY store_id
ORDER BY day
) AS `lag`,
transactions - LAG(transactions) OVER(
PARTITION BY store_id
ORDER BY day
) AS `difference`
FROM sales
WHERE day BETWEEN '2016-08-05' AND '2016-08-10';查询结果
FIRST_VALUE
练习9
需求: 统计2016年8月1日到2016年8月3日的销售数据,找到每个商店在这段时间内销售额最高的一天
查询结果字段:
- store_id(商品ID)、day(日期)、revenue(当日销售收入)、best_revenue_day(销售收入最高一天的日期)
SELECT
store_id,
day,
revenue,
FIRST_VALUE(day) OVER(
PARTITION BY store_id
ORDER BY revenue DESC
) AS `best_revenue_day`
FROM sales
WHERE day BETWEEN '2016-08-01' AND '2016-08-03';查询结果:

NTH_VALUE
练习10
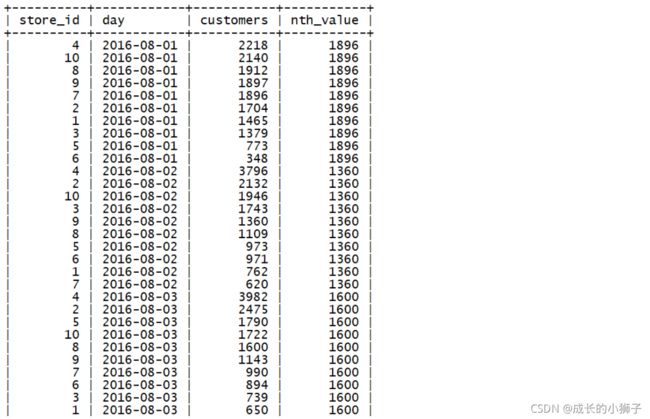
需求: 分析每天所有店铺的客流情况
查询结果字段:
- store_id(商店ID)、day(日期)、customers(客流数量)、nth_value(每天所有商店客流排名第5的客流数量)
SELECT
store_id,
day,
customers,
NTH_VALUE(customers, 5) OVER(
PARTITION BY day
ORDER BY customers DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
) AS `nth_value`
FROM sales;查询结果
08_窗口函数避坑指南
学习目标
- 知道哪些情况下不能使用窗口函数
- 掌握窗口函数与分组聚合一起使用时的技巧
8.1 数据集介绍
拍卖信息表(auction):该表存储了某在线拍卖网站的部分历史网拍信息。
包含以下几列:
id:拍卖的唯一IDcategory_id:类别的ID,例如:家具、卫生用品等asking_price:起拍价格final_price:最终成交价格views:拍卖的点击次数participants:参与拍卖的用户数量country:拍卖的国家ended:拍卖截止日期
8.2 不能使用窗口函数的情况
情况1:不能在 WHERE 子句中使用窗口函数
我们在第一小节介绍过,WHERE条件中不能使用窗口函数,原因是SQL的执行顺序决定了窗口函数实在 WHERE子句之后执行的。
具体执行顺序如下:
- FROM > WHERE > GROUP BY > 聚合函数 > HAVING > 窗口函数 > SELECT > DISTINCT > UNION > ORDER BY > OFFSET > LIMIT
上面的顺序意味着,在FROM、WHERE、GROUP BY或HAVING子句中的写窗口函数会报错
错误示例
需求:查询出所有拍卖中,最终成交价格高于平均成交价格的拍卖
查询结果字段:
- id、final_price(最终成交价格)
SELECT
id,
final_price
FROM auction
WHERE final_price > AVG(final_price) OVER();错误提示
![]()
正确写法可以使用子查询来实现
提示:在FROM子句中使用了子查询,在子查询中我们先计算了平均成交价格,子查询先执行,在外部查询中再去使用
SELECT
id,
final_price
FROM (
SELECT
id,
final_price,
AVG(final_price) OVER() AS `avg_final_price`
FROM auction) c
WHERE final_price > avg_final_price;查询结果
情况2:不能在HAVING子句中使用窗口函数
需求:查询出国内平均成交价格高于所有拍卖平均成交价格的国家
查询结果字段:
- country(国家)、avg(该国家所有拍卖的平均成交价)
SELECT
country,
AVG(final_price) AS `avg`
FROM auction
GROUP BY country
HAVING AVG(final_price) > AVG(final_price) OVER ();错误提示
![]()
正确写法可以使用子查询来实现
SELECT
country,
AVG(final_price) AS `avg`
FROM auction
GROUP BY country
HAVING AVG(final_price) > (SELECT AVG(final_price) FROM auction);查询结果

情况3:不能在GROUP BY子句中使用窗口函数
需求:将所有的拍卖信息按照浏览次数排序,并均匀分成4组,然后计算每组的最小和最大浏览量
查询结果字段:
- quartile(分组序号)、min_views(当前组最小浏览量)、max_view(当前组最大浏览量)
SELECT
NTILE(4) OVER(ORDER BY views DESC) AS `quartile`,
MIN(views) AS `min_views`,
MAX(views) AS `max_views`
FROM auction
GROUP BY NTILE(4) OVER(ORDER BY views DESC);错误提示
![]()
正确写法可以使用子查询来实现
SELECT
quartile,
MIN(views) AS `min_views`,
MAX(views) AS `max_views`
FROM
(SELECT
views,
ntile(4) OVER(ORDER BY views DESC) AS `quartile`
FROM auction) c
GROUP BY quartile;查询结果

8.3 能够使用窗口函数的情况
通过上面的例子我们知道,只能在SELECT 和 ORDER BY子句中使用窗口函数,WHERE HAVING GROUP BY中只能使用子查询
情况1:在ORDER BY中使用窗口函数
需求:将所有的拍卖按照浏览量降序排列,并均分成4组,按照每组编号降序排列
查询结果字段:
- id(拍卖ID)、views(浏览量)、quartile(分编号)
SELECT
id,
views,
NTILE(4) OVER(ORDER BY views DESC) AS `quartile`
FROM auction
ORDER BY NTILE(4) OVER(ORDER BY views DESC) DESC;查询结果

情况2:窗口函数与GROUP BY一起使用
之前我们介绍了,窗口函数在GROUP BY 子句之后执行,那么当我们在SQL中使用了GROUP BY 或者 HAVING对数据进行聚合之后,窗口函数能处理的数据是聚合之后的数据而不是原始数据
1)先看下面的例子:
需求:查询拍卖信息,并统计所有拍卖的平均成交价格
查询结果字段:
- category_id(类别ID)、final_price(最终成交价格)、avg_final_price(所有拍卖平均成交价格)
SELECT
category_id,
final_price,
AVG(final_price) OVER() AS `avg_final_price`
FROM auction;查询结果

2)接下来我们对上面的SQL做一个简单的调整,添加一个GROUP BY子句
SELECT
category_id,
final_price,
AVG(final_price) OVER() AS `avg_final_price`
FROM auction
GROUP BY category_id;错误信息
上面的SQL是错误的,因为经过
GROUP BY分组之后结果只有一列category_id, 此时再运行窗口函数,数据中并不包含final_price
3)我们再对上述窗口函数进行调整,看下这次能否正确执行
SELECT
category_id,
MAX(final_price) AS `max_final`,
AVG(MAX(final_price)) OVER() AS `avg_final_price`
FROM auction
GROUP BY category_id;查询结果
可以看到查询成功了,因为我们使用了聚合函数MAX(final_price),分组之后可以执行,执行之后可以再执行窗口函数。注意,聚合函数嵌套使用这是唯一场景
上面SQL计算的是所有分类的最高成交价的平均值

练习1
需求:将拍卖数据按国家分组,返回如下信息
查询结果字段:
- country(国家)、min(每组最少参与人数)、avg(所有组最少参与人数的平均值)
SELECT
country,
MIN(participants) AS `min`,
AVG(MIN(participants)) OVER() AS `avg`
FROM auction
GROUP BY country;查询结果

排序函数使用聚合函数的结果
我们可以在聚合函数的结果上使用RANK等排序函数
练习2
需求:按国家进行分组,计算了每个国家的拍卖次数,再根据拍卖次数对国家进行排名
查询结果字段:
- country(国家)、count(该国家的拍卖次数)、rank(按拍卖次数的排名)
SELECT
country,
COUNT(id) AS `count`,
RANK() OVER(ORDER BY COUNT(id) DESC) AS `rank`
FROM auction
GROUP BY country;查询结果
练习3
需求: 按商品分类分组,对成交价格求和,对所有类别按成交价格的总金额排序,并添加排名序号(连续可重复)
查询结果字段:
- category_id(分类ID)、sum(分类成交价格总金额)、dense_rank(按成交价格总金额排名)
SELECT
category_id,
SUM(final_price) AS `sum`,
DENSE_RANK() OVER(ORDER BY SUM(final_price) DESC) AS `dense_rank`
FROM auction
GROUP BY category_id;查询结果

利用GROUP BY计算环比
我们可以利用GROUP BY 分组之后,结合LEAD、LAG计算环比(相邻两天的差值)
练习4
需求:按结束拍卖日期对所有拍卖进行分组,对每天结束的所有拍卖的最终成交价格求和,并且计算了前一天的最终成交价格之和
查询结果字段:
- ended(结束拍卖日期)、sum_price(当天拍卖最终成交价之和)、lag_sum_price(前一天拍卖最终成交价之和)
SELECT
ended,
SUM(final_price) AS `sum_price`,
LAG(SUM(final_price)) OVER(ORDER BY ended) AS `lag_sum_price`
FROM auction
GROUP BY ended;查询结果

练习5
需求:按拍卖结束日期分组分析所有拍卖的浏览数据,返回如下信息
查询结果字段:
- ended(拍卖结束日期)、sum(当天总浏览量)、previous_day(前一天的总浏览量)、difference(当天总浏览量和前一天的总浏览量的差值)
SELECT
ended,
SUM(views) AS `sum`,
LAG(SUM(views)) OVER(ORDER BY ended) AS `previous_day`,
SUM(views) - LAG(SUM(views)) OVER(ORDER BY ended) AS `difference`
FROM auction
GROUP BY ended;查询结果

对GROUP BY分组后的数据使用PARTITION BY
我们可以对
GROUPY BY分组后的数据进一步分组(PARTITION BY) ,再次强调,使用GROUP BY之后使用窗口函数,只能处理分组之后的数据,而不是处理原始数据
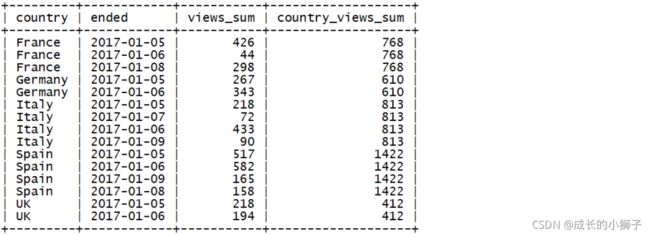
练习6
需求:将所有的数据按照国家和拍卖结束时间分组,返回如下信息
查询结果字段:
- country(国家)、ended(拍卖结束时间)、views_sum(该分组浏览量总和)、country_views_sum(分组聚合结果中不同国家拍卖的总浏览量)
SELECT
country,
ended,
SUM(views) AS `views_sum`,
SUM(SUM(views)) OVER(PARTITION BY country) AS `country_views_sum`
FROM auction
GROUP BY country, ended;- 我们先将所有的数据按照国家
country和拍卖结束时间ended分组,然后显示了国家名字,和拍卖结束日期 - 接下来的两句,
SUM(views) AS views_sum根据GROUP BY分组结果(先国家,后日期),对每组的浏览量求和 SUM(SUM(views)) OVER(PARTITION BY country) AS country_views_sum这是一个窗口函数,只对国家进行分组,计算每个国家拍卖的总浏览量
查询结果
练习7
需求:将所有数据按照类别和拍卖结束日期分组,返回如下信息
查询结果字段:
- category_id(类别ID)、ended(拍卖结束日期)、daily_avg_final_price(当前类别当日拍卖的平均成交价格)、daily_max_avg(每个类别日平均成交价格最大值)
SELECT
category_id,
ended,
AVG(final_price) AS `daily_avg_final_price`,
MAX(AVG(final_price)) OVER(PARTITION BY category_id) AS `daily_max_avg`
FROM auction
GROUP BY category_id, ended;查询结果
