《PyTorch深度学习实践》学习笔记 【4】
《PyTorch深度学习实践》学习笔记 【4】
学习资源:
《PyTorch深度学习实践》完结合集
六、Logistics Regression(逻辑斯蒂回归模型)
虽然它叫做回归模型,但是处理的是分类问题
6.0 回归问题和分类问题
- 有监督学习:
- 回归问题
- 分类问题
- 二分类
- 多分类
回归问题:如果我们预测的结果是以连续数字进行表示,即我们将在连续函数中对多个输入变量建立映射关系时,则这样的问题称之为回归问题。
分类问题:如果我们预测的结果是以离散形式表示的,即我们将多个输入变量与多个不同的类别建立映射关系时,则这样的问题称之为分类问题。
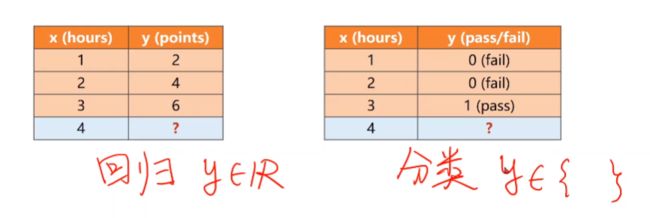
举个例子:
-
Minist数据集(0-9的数字手写图片)分类问题:
任务:将图片分类为10个类别(0-9的数字) 。
实际计算过程是各个数字对应的概率值
输出概率最大的那个作为分类结果。
多分类问题与二分类问题关系
首先,两类问题是分类问题中最简单的一种。其次,很多多类问题可以被分解为多个两类问题进行求解
6.1 torchvision
import torchvision
train_set = torchvision.datasets.MNIST(root='../dataset/mnist', train=True, download=True)
test_set = torchvision.datasets.MNIST(root='../dataset/mnist', train=False, download=True)
torchvision.datasets :包含了一些经典的数据集
参数说明 1. train:使用训练集 2. download:自动下载
数据集如MNIST,CIFAR10等
6.2 输出的处理
当计算出来的概率是0.5 时, 可以在输出的时候输出“不确定”,有时也直接输出概率
6.3 Logistics函数
功能:把输出的值,把实数值映射到0-1之间
因为多分类问题输出的是一个类别的概率,而不是一个确定的类别。
特点:超过某一个阈值之后,增长速度变慢。(饱和函数)(导数的形状是正态分布的)

相同功能的,还有sigmoid函数(激活函数,增加非线性变化)

现在y^head_1 代表的是概率值P(class=1)
KL散度,
交叉熵(cross-entropy): 描述两个概率分布之间的相似度(后面6.4用到)
6.4 BCE LossFunction (binary cross-entropy)
在二分类问题中,y=1或y=0,而y^head 是一个概率值取在[0,1]之间值。

不管y=0还是1,y_head与y越接近,BCE loss越小

6.5 与线性回归的不同
与线性回归只有两处不同
- 线性函数后加上了sigmod函数

- 损失函数由线性回归的MSE到BCE LossFunction

6.6 处理过程

- 数据集准备
- 设计模型
- 选择损失函数和优化器
- 训练
七、处理多维输入
当输入是一个多维数据,来预测对应的分类
7.1 数据集: 样本和特征

7.2 线性回归模型(向量形式处理多维输入)
线性回归模型如下,每一个x_i 都乘以一个权重,用向量表示。

(Pytorch 的sigmoid函数 支持向量操作)
线性层计算过程:整合成矩阵运算(向量化计算,可以利用并行化计算提高计算速度)
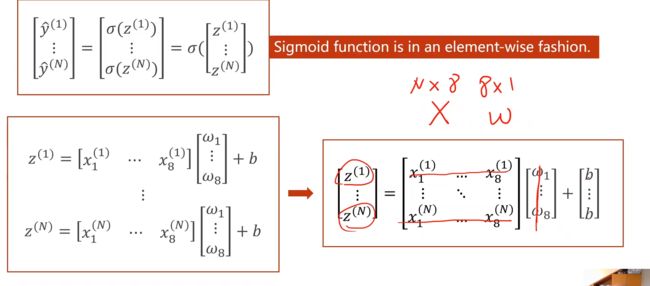
线性层的使用:
self.linear1 = torch.nn.Linear(8, 6)

非线性层的使用:
x = self.sigmoid(self.linear1(x))
7.3 学习能力与超参数
层与层的叠加,就是多层神经网络。每层之间的矩阵大小选择,也是超参数的搜索问题
层数太多,学习能力太强,会把噪声的规律也学进来,而抓不住学习的重点。所以层数,每层的维度,是一个超参数搜索问题。
7.4 代码
import torch
import numpy as np
##1. Prepare Dataset
xy = np.loadtxt('diabetes.csv.gz', delimiter=',', dtype=np.float32)
x_data = torch.from_numpy(xy[:,:-1])
y_data = torch.from_numpy(xy[:, [-1]])
##2. Define Model
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
##定义了三层线性层
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
##定义激活函数,除了sigmoid也有其他的如self.activate = torch.nn.ReLU()
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
##处理单元(线性层+非线性变化层),三层,用同一个变量x(每一层处理的结果都传递到下一层)
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
##3. Construct Loss and Optimizer
criterion = torch.nn.BCELoss(size_average=True)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
##4. Training Cycle
for epoch in range(100):
##Forward
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
# Backward
optimizer.zero_grad()
loss.backward()
# Update
optimizer.step();
代码的复用:
- 使用不同的激活函数
- activate Function
- Not Liner
八、加载数据集
为了加载数据集和支持索引,单位数据集是Mini-batch
8.1 MiniBatch的背景
上一节课的loaddata是使用 全部样本
全部的数据都用,叫做Batch,最大化地利用向量化的优势提高计算的速度。
随机梯度下降,每次只用一个样本:有好的随机性,克服“鞍点”问题。但是每次用一个样本,导致优化的速度很慢
Mini-Batch: 均衡 训练时间和训练效果的需求
一些词汇解释:
Epoch: 所有的训练集进行一次前馈和反向传播,称为一次Epoch
Batch-Size: 每一次前馈与反向传播的单元数据集大小
Iteration:( All_size/ Batch_size )
举个例子:
数据集大小All_size=10’000, Batch_size= 1000;
则Iteration=10’000/1000=10
8.2 DataLoader


Shuffle: 打乱数据集(在训练数据时,要打乱顺序保证随机性;在测试时一般不用,便于观察结果)
Loader:分组成Batch1, Batch2…
8.2 RunTimeError 的解决
因为Windows下创建进程与Linus不同,会出现RunTimeError
解决方法:将loadder进行迭代的代码进行封装起来,不能直接写下程序里面。

(这里写在 if name == '__main__': 下,就能正常运行了)
8.3代码:
本节代码变化如下:
-
第一步Prepare Dataset 中 新定义了DataLoader
-
第四步 Trainning cycle 里面用了嵌套循环,便于使用Minibatch形式。
tip:
init:
读取数据集
- 数据容量不大,直接读进来(内存允许)。
- 数据很大,无法一次加载到内存中,动态读取。

import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader # 这里的Dataset是抽象类
##1. 准备数据集
class DiabetesDataset(Dataset):# 继承抽象类DataSet
##初始化读数据
def __init__(self, filepath):
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)
self.len = xy.shape[0] ##shape : [N* M]矩阵,则shape[0]=N; 这里的shape[0]就是样本数目
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
## 取一条数据
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
## 得到数据的数量
def __len__(self):
return self.len
dataset = DiabetesDataset('diabetes.csv.gz')
train_loader = DataLoader(dataset=dataset, #数据集
batch_size=32, #batch_size
shuffle=True, #是否要打乱
num_workers=2) #读数据时,并行进程的数量(和CPU核心进程有关)
##2. 实例化模型
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
## 3.损失函数和优化器
criterion = torch.nn.BCELoss(size_average=True)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
##4. 训练
for epoch in range(100):
for i, data in enumerate(train_loader, 0):
# 1. Prepare data
inputs, labels = data ## 这里的data 是一个(x,y)的向量
# 2. Forward
y_pred = model(inputs)
loss = criterion(y_pred, labels)
print(epoch, i, loss.item())
# 3. Backward
optimizer.zero_grad()
loss.backward()
# 4. Update
optimizer.step()
8.4 可用数据集
使用方法:

8.5 Exercise
构造分类器,对Titanic数据集进行分类(暂未完成)
九、多分类问题
9.1 与二分类的联系
输出的label只有两个(0/1) :二分类
只要计算出P(y=1)的概率,那么P(y=0)=1- P(y=1);所以只要一个参数。
输出的label有10个(Minist数据集):10分类
如何处理:
视为10个二分类问题(一个label和其他9个label),计算每一个label的概率。
问题在于,
- 每一个二分类问题的结果是独立的,不能保证10个结果加起来等于1
- 每一个结果不能保证>0
9.2 SoftMax函数
为了满足分布条件:

使用softMax Function

softmax函数的作用图

代码与对应的计算图

9.3 CrossEnpropyLoss =LogSoftMax+NLLLoss
CROSSENTROPYLOSS
This criterion combines
LogSoftmaxandNLLLossin one single class.

LOGSOFTMAX
Applies the \log(\text{Softmax}(x))log(Softmax(x)) function to an n-dimensional input Tensor. The LogSoftmax formulation can be simplified as:
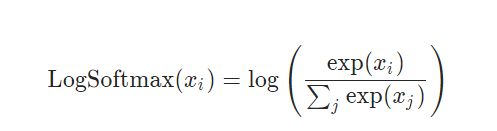
NLLLoss

9.4 在Minist数据集上实现多分类问题
Minsit 数据介绍:
一个数字图像“5” ,其实是一个28*28的矩阵
总体还是四步
(在第四步加上Test)
- Prepare Dataset
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307, ), (0.3081, ))
])
train_dataset = datasets.MNIST(root='../dataset/mnist/',
train=True,
download=True,
transform=transform)
train_loader = DataLoader(train_dataset,
shuffle=True,
batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/',
train=False,
download=True,
transform=transform)
test_loader = DataLoader(test_dataset,
shuffle=False,
batch_size=batch_size)
说明一下:
transform = transforms.Compose([
transforms.ToTensor(), #将PIL Image 格式 转换为 Tensor
transforms.Normalize((0.1307, ), (0.3081, )) ## 正则化: 使得数据满足0-1 分布(正态曲线),
##这里的0.1307 是均值 0.3081是标准差 (经验值/全部数据进来算出来的)
])
单通道图像和多通道图像

0-1 分布 对于神经网络的训练效果最好
- 模型设计

- 定义损失与优化函数
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
- 训练与测试
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data # 取出数据
optimizer.zero_grad() # 梯度清零
# forward + backward + update
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item() # 每300轮迭代后输出Loss
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad(): # 不会计算梯度
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1) # torch.max返回值有两个,最大值的下标+最大值的大小;
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy on test set: %d %%' % (100 * correct / total))
if __name__=="__main__":
for epoch in range(10):
train(epoch)
test()
Torchvision的安装: (不可直接Conda 安装, 需要在Conda 下 用pip安装
(安装参考)