计算机视觉期末复习笔记整理
计算机视觉期末复习笔记整理
- 第2章—图像局部特征描述子
-
- 1.图像匹配:
-
- 图像匹配:
- 特征匹配基本流程:
- 图像局部特征:
- 2.Harrris角点检测
-
- 基本思想:
- 角点响应函数R:
- 3.SIFT特征
-
- SIFT算法可以解决的问题
- SIFT算法实现步骤简述
- 关键点检测的相关概念
-
- 1. 哪些点是SIFT中要查找的关键点(特征点)?
- 2. 什么是尺度空间(scale space )?
- 3. 高斯模糊
- 4. 高斯金字塔
- 5.DoG(Difference of Gaussian)函数
-
- DoG的局部极值点
- 去除边缘响应
- 第3章—图像映射与全景拼接
-
- 1.基础流程
- 2.映射模型
- 3.RANSAC算法
- 4.图像分割——Graph Cut
- 第4章—相机标定
-
- 1.投影方程
- 2.张正友标定算法
- 第5章—多视图几何
-
- 1.基础矩阵F,本质矩阵E
- 2.基础矩阵F的性质
- 3.本质矩阵,基础矩阵推导
- 2.八点算法估算基础矩阵F
- 6.Structure from motion(SFM)
- 第7章—图像检索与识别
-
- 1.Bag of features: 基础流程
- 2.TF-IDF
-
- 投票值TF(词频(Term Frequency))
- 逆向文件频率(Inverse Document Frequency)
- 3.倒排表
- 第9章—图像分割
-
- 1.Graph cuts
- 2.基于Mean-Shift的分割方法
第2章—图像局部特征描述子
1.图像匹配:
图像匹配:
特征点/同名点匹配,是图像拼接、三维重建、相机标定等应用的关键步骤。
特征匹配基本流程:
1.根据特定准则提取图像中的特征点
2.提取特征点周围的图像块,构造特征描述符
3.通过特征描述符对比,实现特征匹配
特征点必须具有不变性,比如:几何不变性:(位移、旋转、尺度……),光度不变性:(光照,曝光)
图像局部特征:
角点: 局部窗口沿各方向移动,均产生明显变化的点;图像局部曲率突变的点
典型的角点检测算法: Harris角点检测,CSS角点检测

2.Harrris角点检测
具有旋转不变性,不具有尺度不变性
基本思想:
从图像局部的小窗口观察图像特征
•角点定义 ->窗口向任意方向的移动都导致图像灰度的明显变化
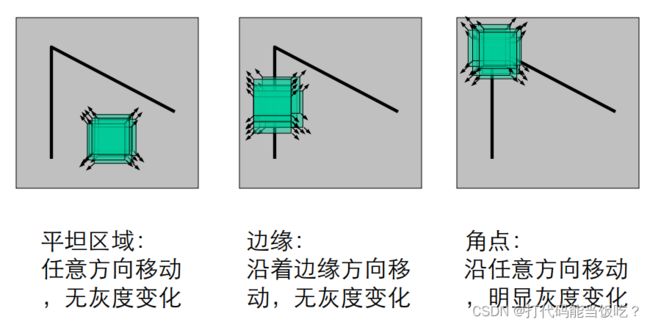
好的角点检测算法应该具有以下几个优点
1.能检测出图像中的“真实”角点
2.准确的定位性能
3.很高的稳定性
4.具有对噪声的鲁棒性
5.具有较好的计算效率
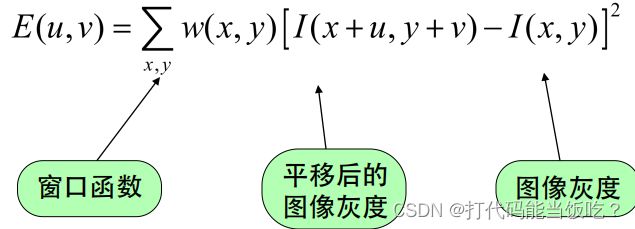
数学表达式:
将图像窗口平移[u,v]产生灰度变化E(u,v)
将I(x+u, y+v)函数在(x, y)处泰勒展开,得:
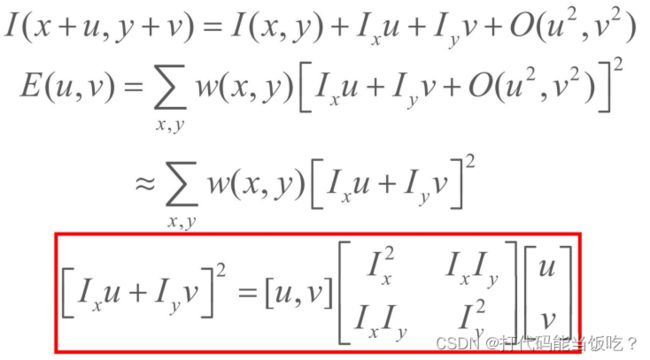
对于局部微小的移动量 [u,v],可以近似得到下面的表达:
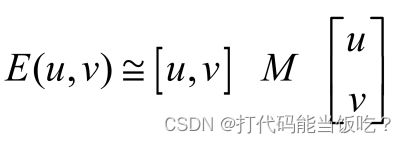
其中M是 2×2 矩阵,可由图像的导数求得:
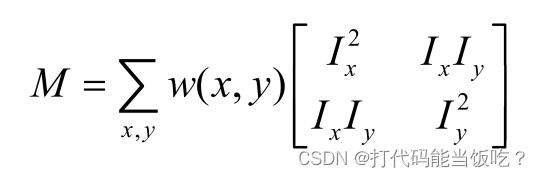
窗口移动导致的图像变化量:实对称矩阵M的 特征值分析记M的特征值为 λ1, λ2,
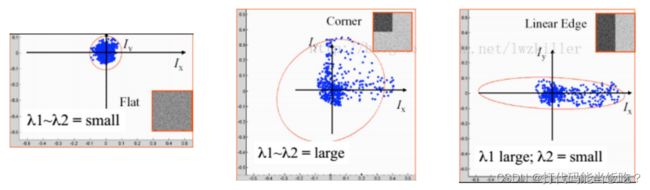
通过M的两个特征 值的大小对图像点 进行分类:
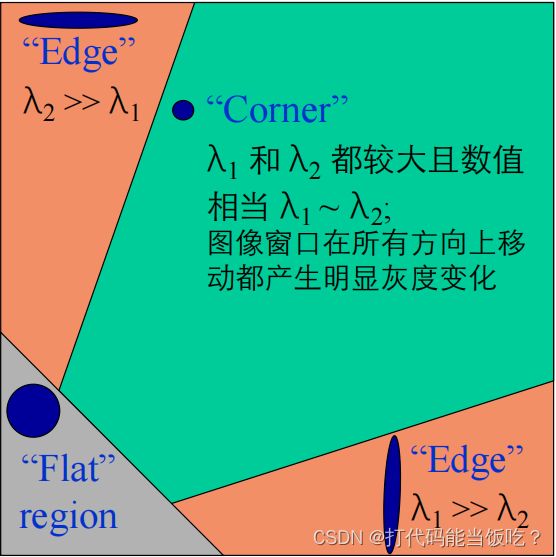
⬆如果 λ1 和 λ2 都很小, 图像窗口在所有方向上 移动都无明显灰度变化
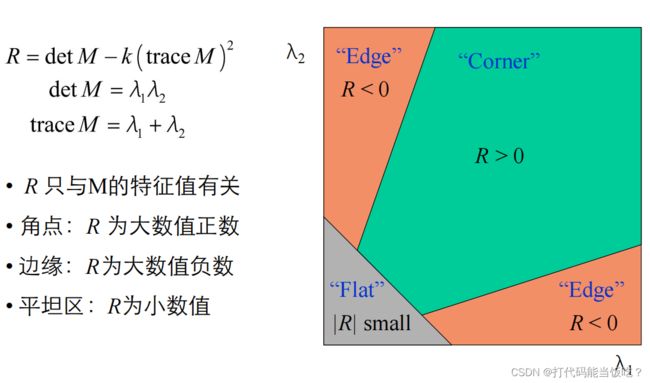
角点响应函数R:

重点:Harris角点检测流程
1.计算所有像素的图像梯度Ix、Iy
2.对于每个像素计算通过循环遍历相邻的x,y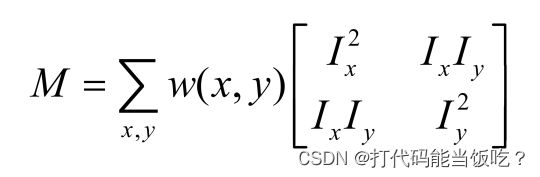
3.寻找角点响应函数R较大的点(R>threshold)
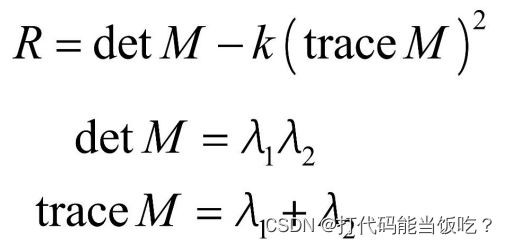
4.取局部最大的R点作为检测到的特征点
3.SIFT特征
SIFT算法可以解决的问题
目标的旋转、缩放、平移(RST)
图像仿射/投影变换(视点viewpoint)
弱光照影响(illumination)
部分目标遮挡(occlusion)
杂物场景(clutter)
噪声
SIFT算法实现步骤简述
实质可以归为在不同尺度空间上查找特征点(关键点)的问题。
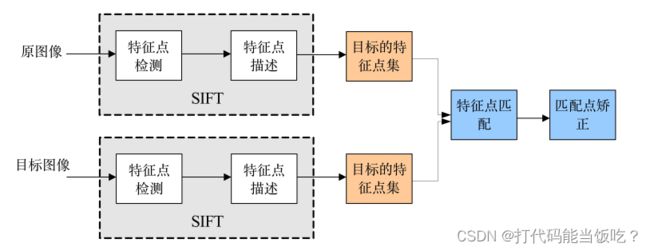
SIFT算法实现特征匹配主要有三个流程
1、提取关键点;
2、对关键点附加 详细的信息(局部特征),即描述符;
3、通过特征点(附带上特征向量的关 键点)的两两比较找出相互匹配的若干对特征点,建立景物间的对应关系。
关键点检测的相关概念
1. 哪些点是SIFT中要查找的关键点(特征点)?
这些点是一些十分突出的点,不会因光照、尺度、旋转等因素的改变而消 失,比如角点、边缘点、暗区域的亮点以及亮区域的暗点。
2. 什么是尺度空间(scale space )?
其主要思想是通过对原始图像进行尺度变换,获得图像多尺度下的空间表示。从而实现边缘、角点检测和不同分辨率上的特征提取,以满足特征点的尺度不变性。尺度越大图像越模糊
3. 高斯模糊
通常用它来减小图像噪声以及降低细节层次
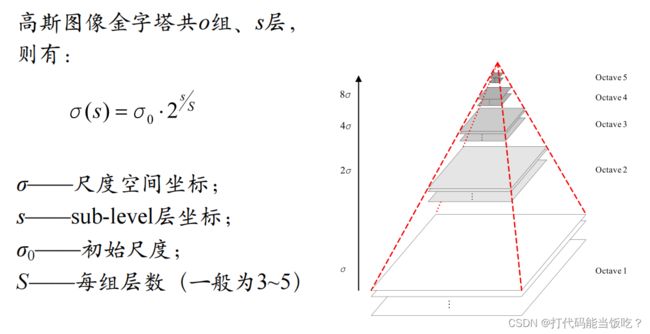
4. 高斯金字塔
高斯金字塔的构建过程可分为两步:
(1)对图像做高斯平滑;
(2)对图像做降采样
为了让尺度体现其连续性,在简单下采样的基础上加上了高斯滤波

5.DoG(Difference of Gaussian)函数
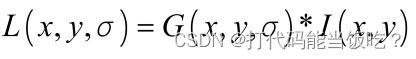
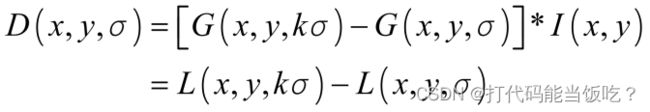
DoG在计算上只需相邻高斯平滑后图像相减,因此简化了计算!
DoG的局部极值点
特征点是由DOG空间的局部极值点组成的。为了寻找DoG函数的极值点, 每一个像素点要和它所有的相邻点比较,看其是否比它的图像域和尺度域 的相邻点大或者小。
去除边缘响应
由于DoG函数在图像边缘有较强的边缘响应,因此需要排除边缘响应
DoG函数的峰值点在边缘方向有较大的主曲率,而在垂直边缘的方向有较小的主曲率。

重点:如何判断关键点的旋转不变性?
1.首先寻找到图像的关键点
图像金字塔每层会得到一系列的DoG[Difference of Gaussian]极大值点,在极值中选取关键点【1.点的周围在邻域范围中是最大值;2.相邻金字塔层的邻域是最大值满足1,2的点具有缩放不变性】但是由于边缘响应,可能找到的点并不是关键点,因此,在此基础上需要计算该点的Hessain矩阵,通过Hessian计算该点的主曲率,利用阈值过滤主曲率较小的点,最后点认为是【关键点】
2.选择关键点的相邻点,计算周围所有点的梯度的角度,且将360°划分为36个方向,统计每个方向上的点的个数,画出对应的直方图,直方图最大值的索引方向记为主方向,峰值大于主方向峰值80%的方向作为该关键点的辅方向。记录该方向即可保证关键点的旋转不变性。
【尺度不变特征转化算法】:
得到关键点之后,在关键点周围的16个像素点(16x16区域),以每4个为一组,计算每组像素的梯度角度,然后根据像素梯度计算角度直方图【360°分成8份】,然后根据直方图的计算结果,最后可以给每个像素点分配16*8=128个特征。通过这128个特征构成的向量可以描述图像局部区域的特征信息。
第3章—图像映射与全景拼接
1.基础流程
①针对某个场景拍摄多张/序列图像
②计算第二张图像与第一张图像之间的变换关系
③将第二张图像叠加到第一张图像的坐标系中
④变换后的融合/合成
⑤在多图场景中,重复上述过程
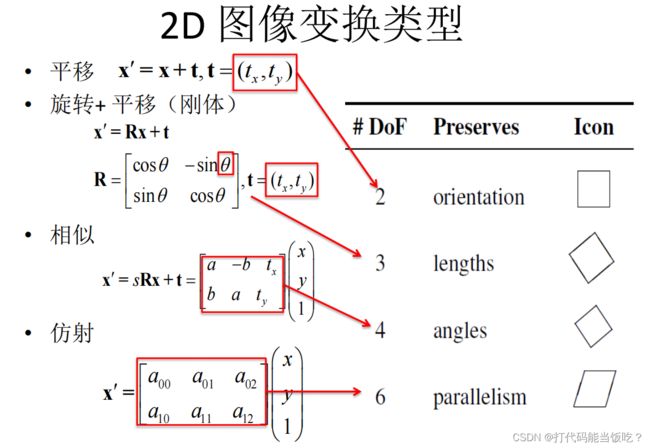
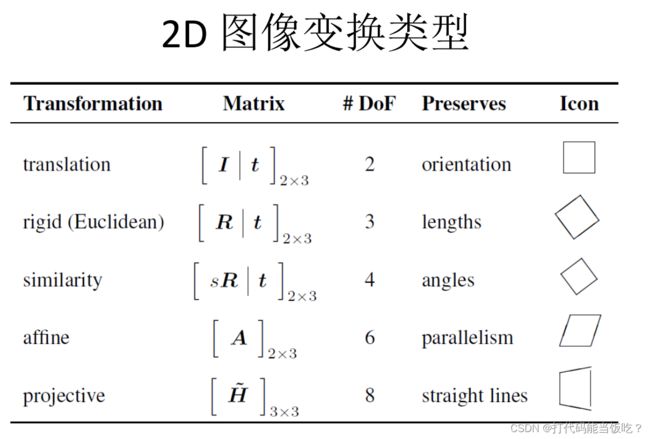
2.映射模型
•translation?(位移)
• rotation?(旋转)
• scale?(尺度/大小)
• affine?(仿射)
•Perspective?(透视)



3.RANSAC算法
随机抽样一致算法(RANdom SAmple Consensus,RANSAC),采用迭代的方式从一组包含离群的被观测数据中估算出数学模型的参数。RANSAC算法假设数据中包含正确数和异常数据(或称为噪声)。正确数据记为内点(inliers),异常数据记为外点(outliers)
算法基本思想
1.选择出可以估计出模型的最小数据集;(对于直线拟合来说就是两个点,对于计算Homography矩阵就是4个点,平面圆形拟合3个点,椭圆拟合5个点)
2.使用这个数据集来计算出数据模型;
3.将所有数据带入这个模型,计算出“内点”的数目;(计算剩余点到模型距离,小于阈值则记为内点)
4.比较当前模型和之前推出的最好的模型的“内点“的数量,记录最大“内点”数的模型参数和“内点”数;
5.重复1-4步,直到迭代结束或者当前模型已经足够好了(“内点数目大于一定数量”)。

4.图像分割——Graph Cut
寻找最小割等同于在源点汇点间寻找最大流

第4章—相机标定
在图像测量过程以及机器视觉应用中,为确定空间物体表面某点的三维几何位置与其在图像中对应点之间的相互关系,必须建立相机成像的几何模型,这些几何模型参数就是相机参数。在大多数条件下这些参数必须通过实验与计算才能得到,这个求解参数的过程就称之为相机标定(或摄像机标定)。
一句话就是世界坐标到像素坐标的映射,当然这个世界坐标是我们人为去定义的,标定就是已知标定控制点的世界坐标和像素坐标我们去解算这个映射关系,一旦这个关系解算出来了我们就可以由点的像素坐标去反推它的世界坐标。标定过程涉及的矩阵主要包括以下三个:
1.外参数矩阵:告诉你现实世界点(世界坐标)是怎样经过旋转和平移,然后落到另一个现实世界点(相机坐标上)。
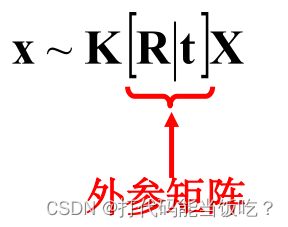
2.内参数矩阵:告诉你相机坐标系下的点,是如何继续经过摄像机的镜头、并通过针孔成像和电子转化而成为像素点的。

3.畸变矩阵:告诉你为什么上面那个像素点并没有落在理论计算该落在的位置上,还产生了一定的偏移和变形。
相机标定:就是确定相机的内外参数、畸变参数的过程。
两类参数:
1.相机内部参数/内方位元素: 焦距、像主点坐标、畸变参数
2.相机外部参数/外方位元素: 旋转、平移
1.投影方程


参数求解
优点:
–所有的相机参数集中在一个矩阵中,便于求解
–通过矩阵可以直接描述世界坐标中的三维点到二维图像平面中点的映射关系。
缺点:
–无法直接得知具体的内参数和外参数
–求解出的11个未知量,比待标定参数(9个)更多。带来了参数不独立/相关的问题
–对噪声/误差敏感
–高精度的标定板难以制作
2.张正友标定算法
使用二维方格组成的标定板进行标定,采集标定板不同位置图片,提取图片中角点像素坐标,通过单应矩阵计算出相机的内外参数初始值,利用非线性最小二乘法估计畸变系数,最后使用极大似然估计法优化参数。
该方法介于摄影标定法和自标定法之间,既克服了摄影标定法需要的高精度三维标定物的缺点,又解决了自标定法鲁棒性差的难题。标定过程仅需使用一个打印出来的棋盘格,并从不同方向拍摄几组图片即可,任何人都可以自己制作标定图案,不仅使用灵活方便,而且精度很高,鲁棒性好。
流程:

优点:

第5章—多视图几何
1.基础矩阵F,本质矩阵E
这里先了解一下什么是外级几何:用两个相机在不同位置拍摄同一物体,两张照片中的景物有重叠部分,那么理论上这两张照片会存在一定的对应关系即外极几何。
为了描述对极几何,引入基础矩阵F。
本质矩阵则是基本矩阵的一种特殊情况,是在归一化图像坐标下的基本矩阵。
本质矩阵E(Essential Matrix):反映【空间一点P的像点】在【不同视角摄像机】下【摄像机坐标系】中的表示之间的关系。
基础矩阵F描述了空间中的点在两 个像平面中的坐标对应关系
2.基础矩阵F的性质
(1) 基础矩阵是秩为2、自由度为7的齐次矩阵。
(2)若x与x’是两幅图上的对应点,那么x′TFx=0。
(3)l’是对应于x的对极线,l′=Fx。
(4)若e是第二个摄像机光心在第一幅图像上的极点,那么Fe=0 。
3.本质矩阵,基础矩阵推导

2.八点算法估算基础矩阵F


优点: 线性求解,容易实现,运行速度快
==缺点:==对噪声敏感
6.Structure from motion(SFM)
运动恢复结构(SFM)是通过一系列的2D图像,来获取图像中场景的3D坐标,从而对3D场景进行重建。
两个流派:重建和定位
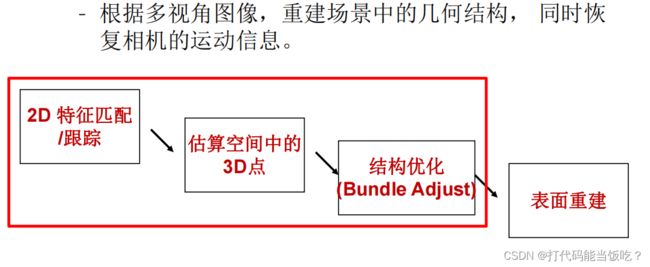
Step1: 检测稳定的角点/局部特征,在多帧图像之间建立特征关联
Step2: 估算m个投影矩阵 Pi ,根据关联点xij和投影矩阵反向计算n个3D点的坐标Xj
Step3: 利用非线性法同步优化结构(3D点)与运动(相机参数) ,最小化重投影误差

第7章—图像检索与识别
1.Bag of features: 基础流程
1.特征提取
2. 学习 “视觉词典(visual vocabulary)”
3. 针对输入特征集,根据视觉词典进行量化
4. 把输入图像,根据TF-IDF转化成视觉单词( visual words)的频率直方图
5. 构造特征到图像的倒排表,通过倒排表快速索引相关图像
6. 根据索引结果进行直方图匹配
2.TF-IDF
投票值TF(词频(Term Frequency))
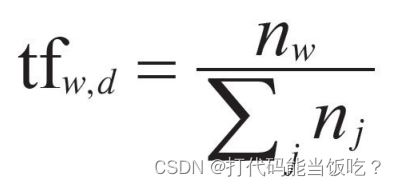
逆向文件频率(Inverse Document Frequency)
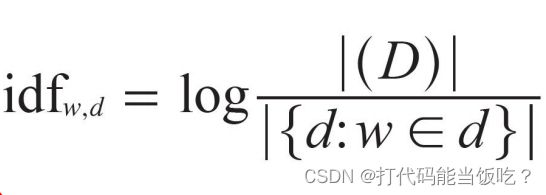
其中,|D| 是语料库中的文件总数。 |{d:w∈dj}| 表示包含词语 ti 的文件数目(即 ni,j≠0 的文件数目)。如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用 1+|{d:w∈dj}|
TF-IDF= TF × IDF
与一个词在文档中出现的次数成正比。
与该词在整个语言中出现的次数成反比。
3.倒排表
到排表是搜索引擎的核心架构
假设我们爬取了4个文档,里面的内容如下
基于4个文档,写出我们的词库 [我们,今天,运动,昨天,上,课,什么]
统计词库中的每个单词出现在哪些文档中,显然 我们 出现在[doc1,doc2] 中

这样我们就可以把文档以到排表的方式存储了,这样做有什么优点呢???
假如用户输入:我们上课
如果没有倒排表,则只能一篇一篇的去搜索文档中 是否既包含我们又包含上课,这样复杂度太高了有了倒排表:我们知道 我们[Doc1, Doc2], 上 [ Doc3,Doc4], 课[Doc3,Doc4], 如果有交集,我们可以直接返回交集,如果没有交集,那么直接返回
并集[ Doc1,Doc2, Doc3,Doc4]
第9章—图像分割
1.Graph cuts
每个像素节点都有一个从源点的传入边;
每个像素节点都有一个到汇点的传出边;
每个像素节点都有边连接到它的近邻;
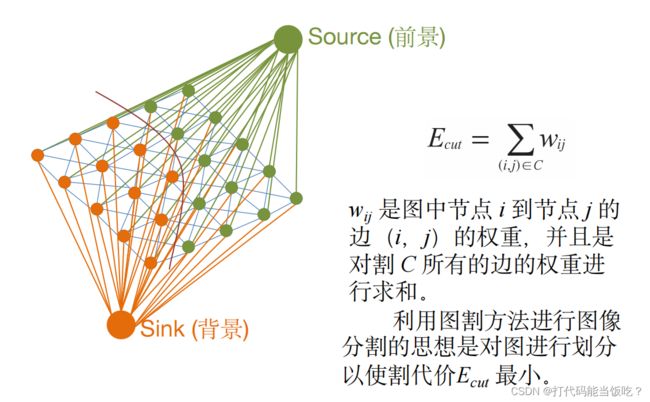

如何构造图?
1.节点:一般所有像素均作为图的节点 ,有时也可以在像素点中采样
2.边:每个像素与其上、下、 左、右等四个相邻像素相连,边带有权重 Wij , E.g. 权重可以和灰度差,或者RGB 差相关
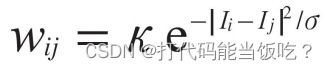

2.基于Mean-Shift的分割方法
Mean-Shift 算法通过在特征空间中搜索极值 (modes)来实现特征空间中像素点的划分。
流程:
定位特征点/像素点 (color, gradients, texture, etc)
针对输入特征初始化窗口
针对窗口计算Shift方向,并不断迭代进行位置更新
合并收敛到同一 “peak” 或者 mode的特征
(把图像中的所有RGB信息转化为三维空间的每一个点,每个点周围空间画一个球,再算出求球内部点的分布,并且让球往点密度较高的地方漂移,不断迭代并更新位置,到最后收敛停止,这样就可以把图像分割成不同类别)