Http协议
目录
一、HTTP协议
1.http
2.url
url的组成:
url的保留字符:
3.http协议格式编辑
①http request
②http response
4.对request做出响应
5.GET与POST方法
①GET
②POST
7.HTTP常见Header
①Content-Type:: 数据类型(text/html等)在上文我们使用过。
②Content-Length: 正文的长度。
③Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上。
④User-Agent: 声明用户的操作系统和浏览器版本信息。
⑤referer: 表示当前页面是从哪个页面跳转过来的。
⑥Location: 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问。
⑦Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能。
一、HTTP协议
1.http
上篇文章我们体验了定制协议的繁琐,这次我们来讲述下真正成熟的有很多人使用的协议,例如:http、https、smtp、dns等。
Http协议:超文本传输协议。
客户端通过使用Http协议来向服务端获取资源。
2.url
我们俗称的“网址”就是url。
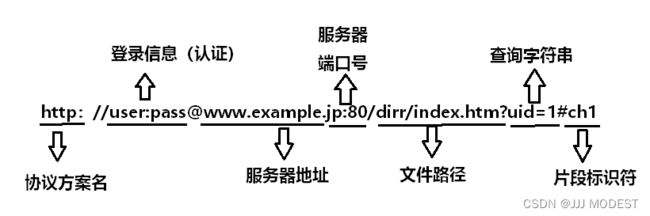
协议方案名:上例是http://,表示使用http协议。后面我会讲到https,这是http协议的加密版本,现在多数都使用的都是https。
登录信息:我们这次不考虑,一般会省略掉,在正文中携带登录信息。
服务器地址:是资源所在的网站名或服务器的名字,又称为域名。在网络通信中域名必须被转换为IP地址。
端口号:HTTP 协议的默认端口是80,如果省略了这个参数,服务器就会返回80端口的网站。在上上一篇文章中讲到网络之间的通信就是进程之间的通信,通过域名(IP地址)+端口号的方式就可以在全网中确定唯一一个进程。我们发现一些url会缺省port,一般由浏览器自动添加,而这些url对应的port都是公开的,一旦服务上线端口号就已经确定,httpserver->80,httpsserver->443,sshd->22。
文件路径:资源在服务器的位置。
查询字符串:提供给服务器的额外信息。
片段标识符:也叫做锚点,锚点是网页内部的定位点,浏览器加载页面之后,回滚到锚点锁定位的位置。
url的组成:
26个英文字母 10个阿拉伯数字 连词号(-)句典(.) 下划线(_)
url的保留字符:
有10个保留字符,只能在给定位置出现。
如果在其他位置去使用保留字符,就必须使用转义形式。
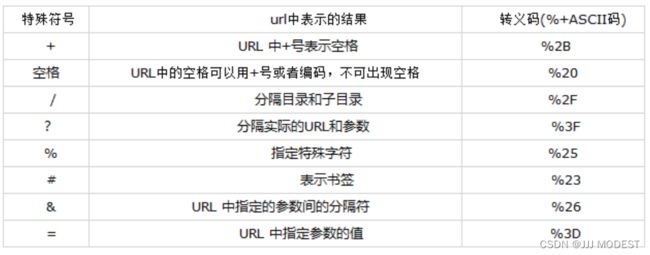
其中罗列一部分,都是关于特殊符号的转义,那我要在url中体现汉语怎么办?
我们可以现场搜索一下,见见实际情况。 
我们会发现汉字也会被转义,转义的规则为:将需要转码的字符转换为16进制,从右到左取四位,每两位做一位,前面加上%,编码成%XY格式。
3.http协议格式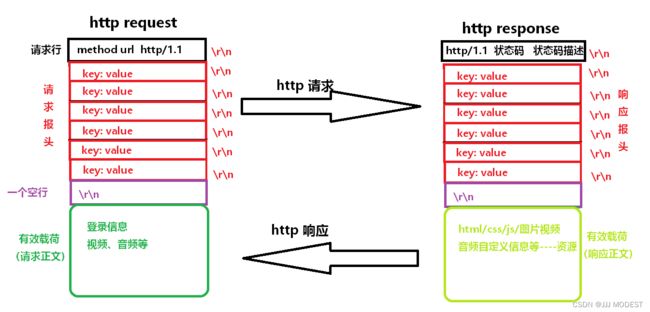
注意:
method为请求方法,常见的get方法、post方法。
key:空格value
http/1.1为当前版本为1.1
现在我们可以通过上节课代码,我们运行server,通过浏览器来访问我们的server,将接收到的东西打印出来,我们就可以真正的见到http request。
①http request
在浏览器中输入你主机的IP地址:你的server绑定的端口号。![]()
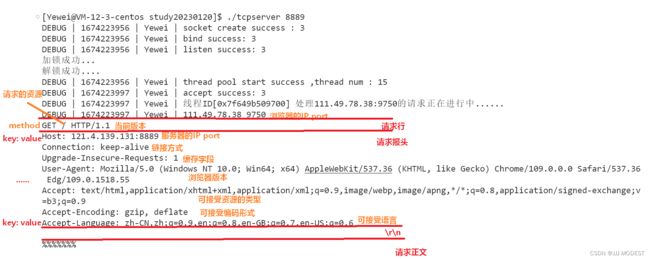 上图中关于服务器版本的信息,当我们换个浏览器使用就会有不同的效果。
上图中关于服务器版本的信息,当我们换个浏览器使用就会有不同的效果。
如图我是用iphone的safari浏览器依据我们的ip与port来访问的。![]()
至于浏览器会表现出如此现象是因为我们做为服务器没有向浏览器响应发送任何东西。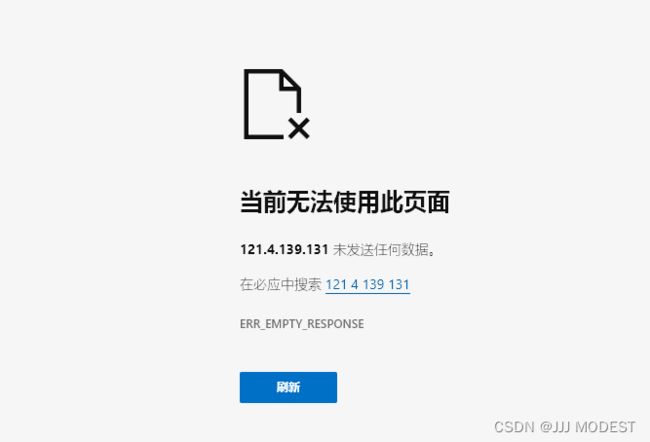
上文的tcpserver的代码是上篇文章写的,很是臃肿,于是我删删减减,得到了simple版本。
void handlerHttpRequest(int sock)
{
cout<<"++++++++++++++++++++++++"< 0)
{
cout << buffer << endl;
}
}
class Tcpserver
{
public:
Tcpserver(uint16_t port, const string &ip = "")
: _sock(-1), _port(port), _ip(ip)
{
_quit = false;
}
~Tcpserver()
{
if (_sock >= 0)
close(_sock);
}
public:
void init()
{
_sock = socket(AF_INET, SOCK_STREAM, 0);
if (_sock < 0)
{
exit(1);
}
struct sockaddr_in local;
memset(&local, 0, sizeof(local));
local.sin_family = AF_INET;
local.sin_port = htons(_port);
_ip.empty() ? INADDR_ANY : (inet_aton(_ip.c_str(), &local.sin_addr));
if (bind(_sock, (const sockaddr *)&local, sizeof(local)) < 0)
{
exit(2);
}
if (listen(_sock, 5) < 0)
{
exit(3);
}
}
void start()
{
signal(SIGCHLD, SIG_IGN);
while (!_quit)
{
struct sockaddr_in peer;
socklen_t len = sizeof(peer);
int servicesock = accept(_sock, (struct sockaddr *)&peer, &len);
if (_quit)
break;
if (servicesock < 0)
{
cerr << "accept error ..." << endl;
continue;
}
int clientport = ntohs(peer.sin_port);
string clientip = inet_ntoa(peer.sin_addr);
pid_t pid = fork();
assert(pid != -1);
if (pid == 0)
{
if (fork() > 0)
exit(4);
handlerHttpRequest(servicesock);
exit(0);
}
close(servicesock);
wait(nullptr);
}
}
void safequit()
{
_quit = true;
}
private:
int _sock;
uint16_t _port;
string _ip;
// 安全退出
bool _quit;
};
Tcpserver *svrp = nullptr;
void sighandler(int sig)
{
if (sig == 3 && svrp != nullptr)
svrp->safequit();
cout << "server quit" << endl;
} 上文我们可以看到http request的响应代码。接下来我们看一下http response的响应代码。
②http response
接下来,我们可以通过命令行的方式向baidu发送request获得response。
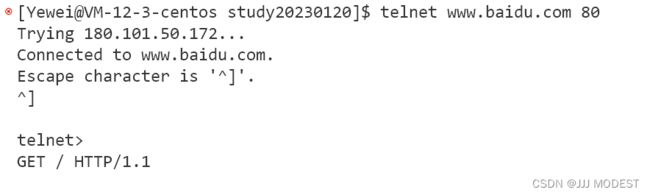
进入telnet后按ctrl+],再按回车输入GET / HTTP/1.1,然后按两下回车。

4.对request做出响应
上文我们对浏览器的request并没有做出任何响应,server仅仅是将接收到的http request中的内容,下文我们将对request做出响应。当然不是无所依据的responce,我们可以参照上文百度做出的responce。
这个函数的参数神似我们使用过的write,将flags设置为0,就和write等价。
代码:
void handlerHttpRequest(int sock)
{
char buffer[1024];
ssize_t sz = read(sock, buffer, sizeof(buffer));
if (sz > 0)
{
cout << buffer << endl;
}
// response
string response;
response += "HTTP/1.0 200 OK\r\n"; // response请求行
response += "\r\n"; // 本行为\r\n为请求报头与正文的分界线 请求报头暂且为空
response += "Hello world!"; // 正文
send(sock,response.c_str(),response.size(),0);
}结果:

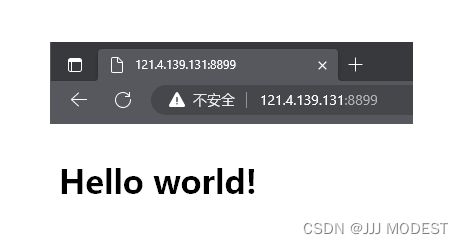
单纯Hello world!有点单一,我们可以让它成为这个网页的大标题,这个工作将由浏览器接收到我们的正文部分然后渲染就可以得到效果了。
代码:
response += "
Hello world!
"; // 正文
结果:
再次升级,我们将响应报头完善下。
Content-Type 内容类型 指出我们正文所对应的类型。
上文中的正文内容为.html,Content-Type就应该填text/html。
具体的对照类型,可以看这篇博客。
代码:
// response
string response;
response += "HTTP/1.0 200 OK\r\n"; // response请求行
response += "Content-Type: text/html\r\n";
response += "\r\n"; // 本行为\r\n为请求报头与正文的分界线 请求报头暂且为空
response += "Hello world!
"; // 正文
结果跟上文无疑。
如何保证将响应行与响应报头读完整呢?读到空行就可以保证。那如何保证正文读取完整呢?这就是响应报头中的内容来保证的。
Content-Length负责记录正文的长度。
代码:
// response
string html = "Hello world!
";
string response;
response += "HTTP/1.0 200 OK\r\n"; // response请求行
response += "Content-Type: text/html\r\n";
response += ("Content-Length: " + to_string(html.size()) + "\r\n");
response += "\r\n"; // 本行为\r\n为请求报头与正文的分界线 请求报头暂且为空
response += html; // 正文结果:这次通过使用telnet来检验成果,浏览器不会显示。
作为建设服务器的人员将网页构建的代码写到服务器中,是否有点挫,那应该放在什么地方?先前我们在讲url的时候提到过文件路径,由客户端依据文件路径请求资源,服务器依据请求放回资源。所有我们的html等资源都是放在文件里。
至于文件路径是否要从linux根目录中开始写,写到目标文件为止,会写出很长一段文件路径。其实不用,如果客户端要访问a/b/c.html,我们能说a文件就是linux的根目录吗,不能,这是web根目录,具体可以看下方代码。
request = "/a/b/c.html";
path = "linux/server/web"; // web根目录
path += request; ->linux/server/web/a/b/c.html // 最终的文件路径这次我们将我们的html放在文件中,由客户端申请客户端返回。
我们的主页在当前工作路径下的wwwroot里。
代码:
#define CRLF "\r\n"
#define SPACE " "
#define SPACE_LEN strlen(SPACE)
#define HOME_PAGE "index.html"
#define WEB_ROOT "./wwwroot"// 负责将http_request中的文件路径提取出来
string getPath(string http_request)
{
ssize_t pos = http_request.find(CRLF);
if (pos == string::npos)
return "";
string request_line = http_request.substr(0, pos);
// GET /a/b/c http/1.1
ssize_t firstSpace = request_line.find(SPACE);
if (firstSpace == string::npos)
return "";
ssize_t secondSpace = request_line.rfind(SPACE);
if (secondSpace == string::npos)
return "";
string path = request_line.substr(firstSpace + SPACE_LEN, secondSpace - (firstSpace + SPACE_LEN));
if (path.size() == 1 && path[0] == '/')
path += HOME_PAGE; // 如果只发了/ ,我们就将我们网址的主页返回过去
return path;
}// 负责打开文件将文件的内容读取出来
string readFile(const string &path)
{
ifstream in(path, std::ifstream::binary);
if (!in.is_open())
return "404";
string content;
string line;
while (getline(in, line))
content += line;
in.close();
return content;
}void handlerHttpRequest(int sock)
{
char buffer[10240];
ssize_t sz = read(sock, buffer, sizeof(buffer));
if (sz > 0)
{
cout << buffer;
}
string path = getPath(buffer);
cout << "path->" << path << endl;
string resource = WEB_ROOT;
resource += path;
cout << "resource->" << resource << endl;
string html = readFile(resource);
string response;
response += "HTTP/1.0 200 OK\r\n"; // response请求行
response += "Content-Type: text/html\r\n";
response += ("Content-Length: " + to_string(html.size()) + "\r\n");
response += "\r\n"; // 本行为\r\n为请求报头与正文的分界线 请求报头暂且为空
response += html; // 正文
send(sock, response.c_str(), response.size(), 0);
}index.html:
http server
TEST
Hello World!
telnet中的结果:无论是请求/ 还是/index.html 结果都一样因为我们当前只有一个主页。

web中的结果:

5.GET与POST方法
①GET
下面我们来鉴别POST方法与GET方法的区别。
我们都知道上网的行为一般分两种:
1.从远端获取资源到本地 使用GET方法 //GET / HTTP/1.1
2.将本地的资源上传到远端 可以使用POST方法也可以使用GET方法。
我们这次使用表单将信息填写,然后先用GET方法发送。
代码:
http server
TEST
Hello World!

 现象:我们将信息填入点击submit
现象:我们将信息填入点击submit

提交过后会发现会出现404,那是因为网页代码中我们指定将数据提交的网址(abc/qwe/index.html)在服务器中并不存在。
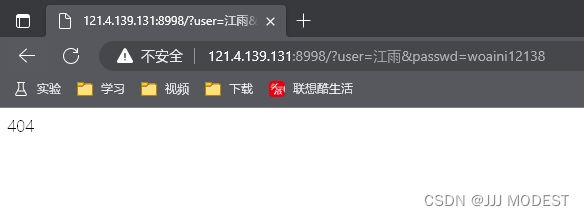
我们主要来分析下当前的url。

我们会发现在HTTP协议中GET方法会以明文的方式 将我们对应的参数信息,拼接到url中。
②POST
下面来看看POST方法。

我们会发现GET方法中会将信息拼接在url中,而POST方法不一样,它是将信息拼接到http requset中的正文中。
总结:
1. GET方法通过url传参
2. POST方法通过正文传参
3. GET方法传参不私密
4. POST方法传参通过正文,相对私密。至于为什么不说安全与不安全,HTTP协议在某种角度来说就是不安全的,不管通过GET还是POST方法提交数据都会通过抓包等软件获取到url或者正文,所以说都是不安全的,下面我们会学习HTTPS现在主流安全可靠的协议。
5. 网页中内容较少一般通过GET方法传参,内容较多通过POST方法传参。
6.HTTP状态码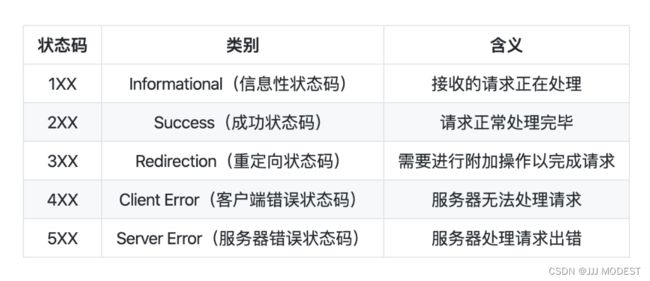
最常见的状态码,比如200(OK),404(Not Found),403(Forbidden),302(Redirect,重定向),504(Bad Gateway)。
我们向服务器申请一个并不存在的资源将会返回什么状态码呢?
会返回4XX,因为客户端申请的资源并不存在,服务器就算穷举也找不到,所以这是客户端出错。
什么时候会返回5XX呢?
客户端申请一些任务,服务器去执行,在其中会申请内存,线程,进程等手段执行任务,当服务器中一些资源到达载荷就会返回5XX。
我们主要研究下3XX。

客户端向服务端发起请求,服务端响应中携带301 || 302 和new url,浏览器就会自动跳转到新的服务端去获得资源。
我们通过我们简单的代码,也可以验证下。
代码:
void handlerHttpRequest(int sock)
{
char buffer[10240];
ssize_t sz = read(sock, buffer, sizeof(buffer));
if (sz > 0)
{
cout << buffer;
}
string response = "HTTP/1.1 302 Moved Temporarily\r\n";
response += "Location: www.baidu.com\r\n";
response += "\r\n";
send(sock, response.c_str(), response.size(), 0);
}现象:
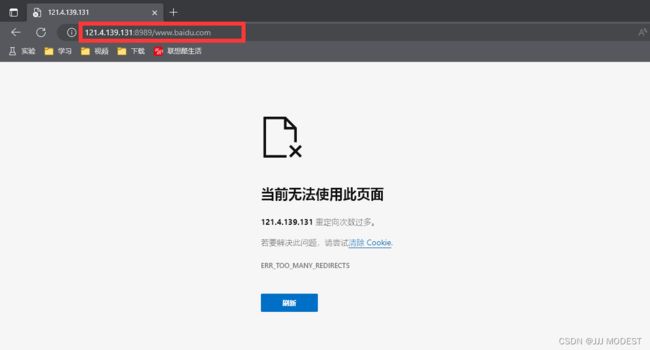
至于为什么没有显示我们重定向之后的页面呢,因为浏览器作为客户端并行的向我们的服务端发送请求,服务端则是向每一个请求都返回重定向,所以会显示出图片中的错误。
当然我们此时也没有完全写对,Location之后一定跟的是网址。写成www.baidu.com只是目前的站内跳转,要实现不同的域也就是服务器跳转,代码要变成:
response += "Location: https://www.baidu.com/\r\n";
现象:将IP地址和端口输入回车之后,就会跳转到我们重定向之后的界面。

什么时候会用到301或者302呢?
301作为永久重定向,一般是在网站更换网址时使用,比如,当时的url取的很随意当想改变跟换一个更好听的时候,会发现当前访问旧网址的人很多,为了避免再换url时损失大量用户,可以在用户访问旧url时,使用永久重定向跳转到新的url。
302作为临时重定向,当该网站临时维护时,不想拒绝访问的用户,可以用到临时重定向使网站跳转到另一个可以提供服务的网站。
7.HTTP常见Header
①Content-Type:: 数据类型(text/html等)在上文我们使用过。
②Content-Length: 正文的长度。
③Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上。
④User-Agent: 声明用户的操作系统和浏览器版本信息。
我们通过Windows环境下的浏览器打开qq的官网观察下载页面,会发现下载页面直接为Windows版本下载。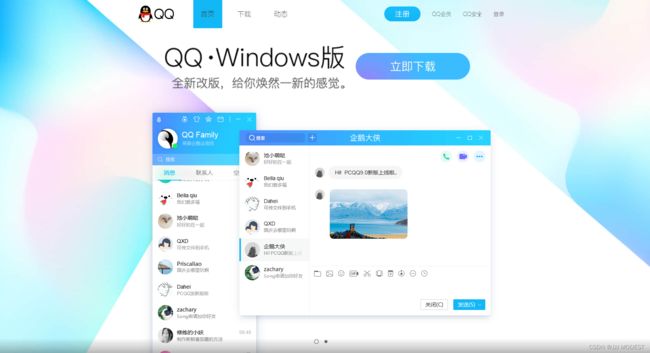
通过手机浏览器打开qq的官网,会发现下载页面会变为qq手机版。
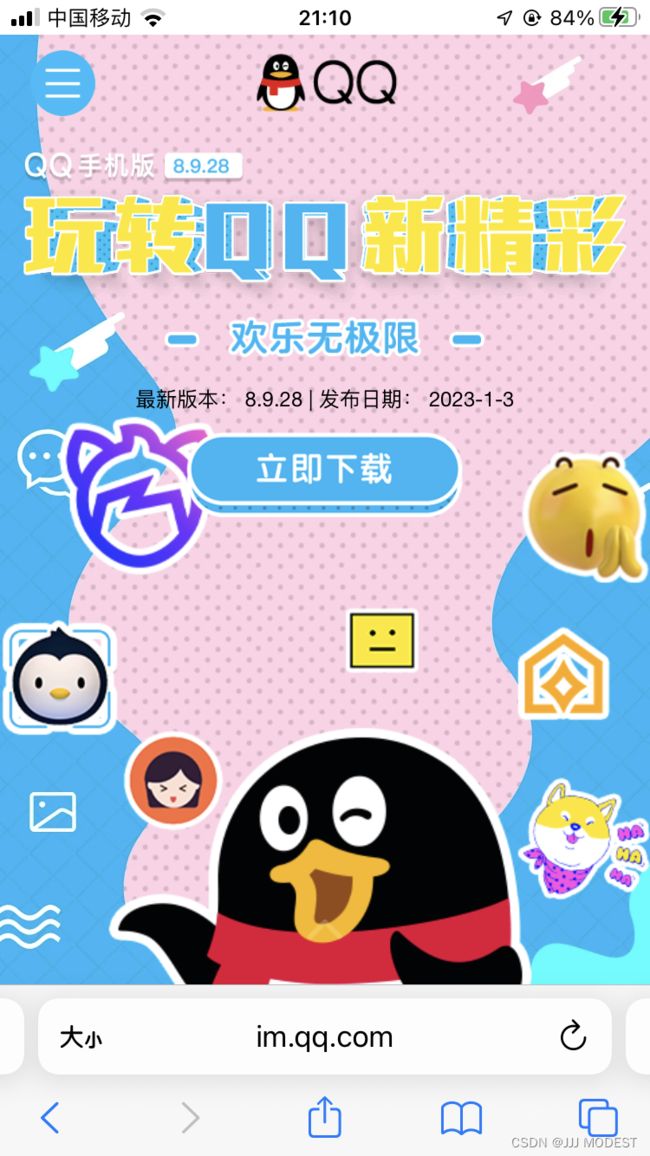
这是依据什么来改变响应界面呢,与User-Agent这个信息密切相关。
⑤referer: 表示当前页面是从哪个页面跳转过来的。
⑥Location: 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问。
⑦Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能。
在讲Cookie之前我们要知道HTTP协议的特点之一是无状态,什么是无状态呢,简单就是HTTP协议本事并不会记录你请求资源的行为,请求过了再请求HTTP协议本事并不会记录你当前已经请求过了。但是我们当前所知道的浏览记录等信息都是显而易见被记录下来的信息,这些信息都是依靠HTTP周边策略来实现的,比如说Cookie策略。
这个Cookie在哪其作用呢?
像我们每次登入一个常用的网站,关闭之后再次进入,会发现登陆的账号还在保持登陆状态,这就是cookie起了作用,当我们禁止cookie就会发现每次登陆之后关闭再打开,会让你再次登陆,并不会延续你上次登陆的用户。
我们尝试讲Cookie体现在代码中
代码:
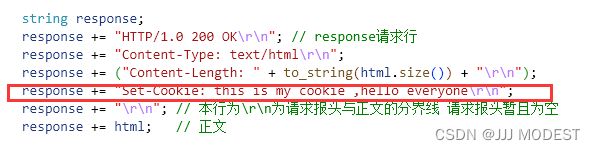
现象:

一般流程为我们客户端讲登陆信息输入,登录信息就会被记录到服务器中吗,当再次访问网站时, 登陆信息就会通过Set-Cookie发送到客户端。
当然Cookie不仅仅是存在于服务端,也有可能存在于浏览器维护的文件中。
我的登录信息这么简单的存储在本地文件中,那木马病毒等不正当手段随便就可以获取我的登陆信息岂不是我的上网安全岌岌可危,所以我们要使用Cookie和Session组合起来的方式来保证安全。
客户端输入登陆信息,然后将登陆信息发给服务端,服务端根据登陆信息形成Session文件,该文件的文件名具有唯一性,该文件名被称为session_id。服务端再将该session_id发给客户端,客户端会将session_id写入本地的cookie中。在cookie中的表现只出现session_id。下次登陆时客户端就会将session_id发送给服务端,服务端依据session_id来判断是否有权利享有对应的资源。
那这个session_id会不会也会被轻易盗取,也是会的,这个问题没有根本解决。但是session_id丢掉之后,你丢掉的只是session_id,你的信息会保存在服务端。大型的服务端有很不错的防护系统。至于更多的知识,感兴趣的同学可以去了解一下更细致的讲解。
目前此篇文章就写到这里,关于HTTPS协议将会在下篇与大家见面,如有错误请指出,感谢观看,我们下次再见。