操作系统与磁盘交互的细节
目录
1.物理结构
①内部结构
②盘面结构
③抽象结构
2.数组空间
①分区
②对磁盘组的管理
问题:
1.物理结构
①内部结构
这是我们大家的电脑里存储数据的磁盘,它裹得这么严实里面究竟什么样?

我们描述一下重点区域:
磁头组件:由三部分组成读写磁头、传动手臂、传动轴。最主要的是磁头。在磁盘工作时,磁头通过感应旋转的盘片上磁场的变化来读取数据,通过改变盘片上的磁场写入数据。
盘片与主轴:盘片随着主轴电机转动而转动,盘片是硬盘存储的数据的载体。
②盘面结构
我们平视磁盘结构:
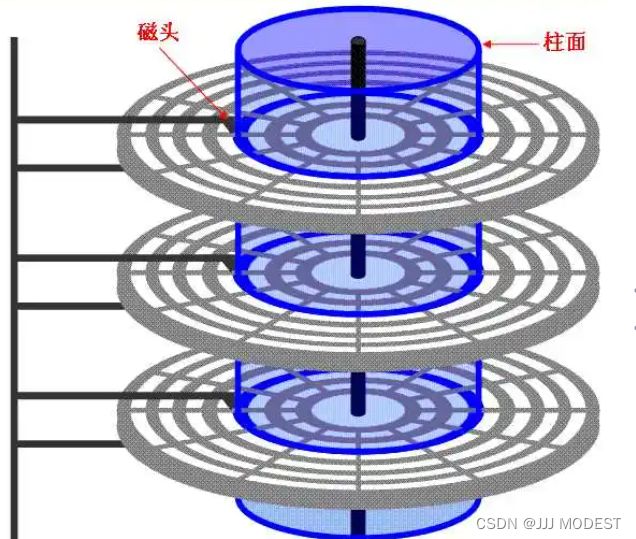
主轴带着盘面转动,磁头在盘面上读写。(不知道有没有同龄人,这平视图感觉有点像洛洛历险记里的能源之城)。
俯视:
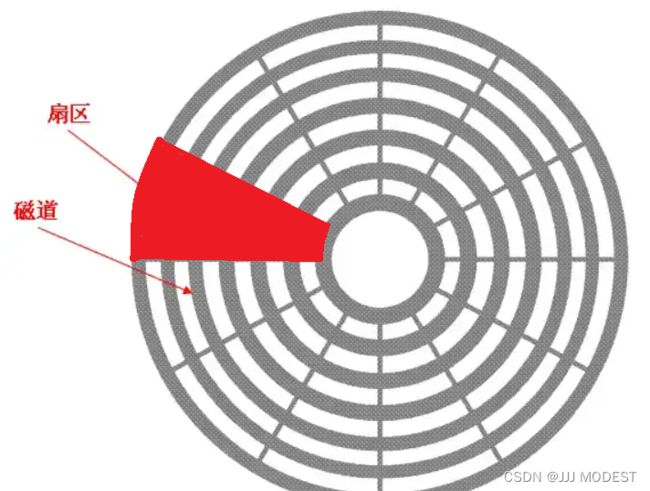
扇面(Sector):如图该磁盘被分为12个扇区数。数据以扇区进行存储,扇区也是磁盘I/O操作的最小单位。 一个扇区的大小是512字节。
磁道(Tracker):是一个个同心圆。盘面随着主轴转动,如果磁头不动,则会在磁盘画出一个圆形轨道这就是磁道。
柱面(Cylinder):硬盘通常由多个盘片构成,而且每个面都被划分为数目相等的磁道,并从外边缘开始编号 。每个盘面相同编号的磁道可以形成一个个柱面。
盘面(Head):一个磁盘分两面,这两面注意都可以读写。
分别有了这几个确定的区域,我们是不是可以精确定位到哪个盘面哪个扇面哪个磁道的确定位置,这样就可以精确存储了。
这样的精确地址叫C(Cylinder)H(Head)S(Sector)地址,有了它,我们可以精确访问磁盘的任意位置。
③抽象结构
这个磁盘好像我们小时候用的磁带啊。

小时候贪耍,经常把不用的磁带拆开,把两卷磁带都拉长。

磁带原来是缠在一起,数据都记录在上面,拉长之后,就像一个长长的细带子,记满了数据,这好像数组啊,磁盘也可以理解成这样。即将对磁盘的管理,转换为对数组的管理。
![]()
这个磁盘100Gb大小,一个扇面基本单位是512字节,也就是说这个数组有209,715,200个元素。我们可以通过下标来访问磁盘上具体的元素。这个下标就叫做LBA(逻辑块地址)。
例如:
假设整个数组大小是80000,磁盘结构有5片磁盘10面(H),有12个柱面(C),有10扇面(S)。我想知道下标为24143的元素在磁盘上什么位置存储:

得出在第3面第9个扇区第2个磁道中。
2.数组空间
①分区
我们每次只是管理512字节的数据太少了,管理太麻烦,所以操作系统将8个512字节的数据管理为一个数组元素。
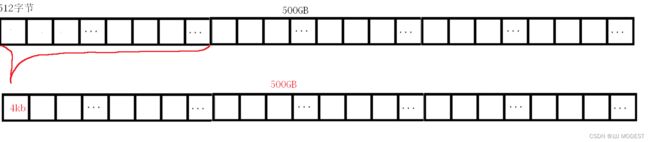
所以IO的基本单位是4kb。
这样做的目的是:减少IO次数,提高IO效率;不让操作系统或者软件和硬件之间具有更高的耦合性,解耦合。
我粗浅的理解是每个part都“各行其事”,将自己的部分做的更好,减少各各part的强相关性,不会因为一个part改变所有part,所谓高内聚低耦合。
但是500GB的数组太大了,我们还要进行分区。

还是太大,我们在进行分组,毕竟管好一个个分部,汇聚起来整体也就管好了,分治的思想。
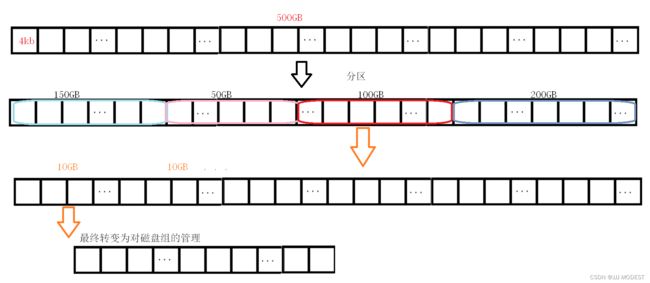
②对磁盘组的管理
磁盘组中有什么?
如图:
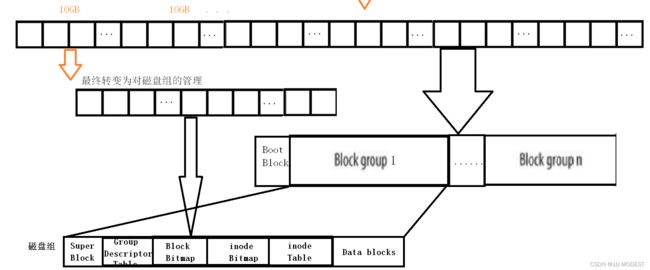
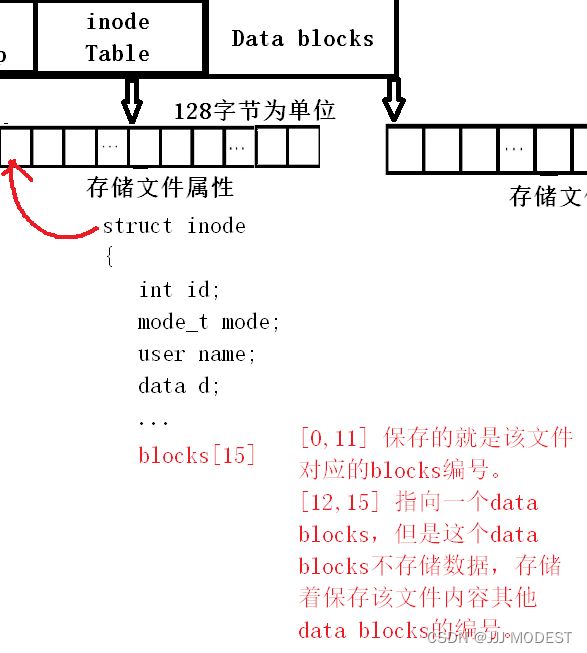
注意:文件=内容+属性,这些都是数据,在linux下采用的是内容和属性数据分开存的策略。
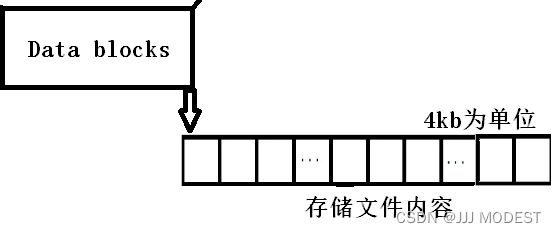
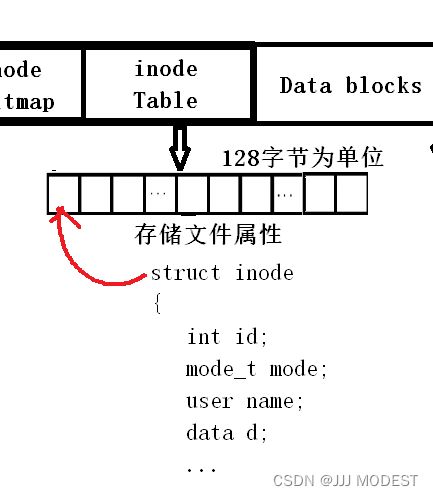
内容存在block中大小4kb,属性数据存在inode(另一块磁盘上的空间)中大小128字节。
一般block的大小会不断增加,因为文件内容会增加减少,但inode的空间一般是定长,不变, 因为文件的属性是稳定的。
Boot Block:里面存储着开机信息,包括磁盘分区情况(分区表),操作系统软件具体在什么地方,然后硬件读取这些信息,加载操作系统,就可以开机了。
Block group:
我们在xshell中看一下:
这些文件都对应为一个inode。
问题: