
2.找到每一个商品对应的标签
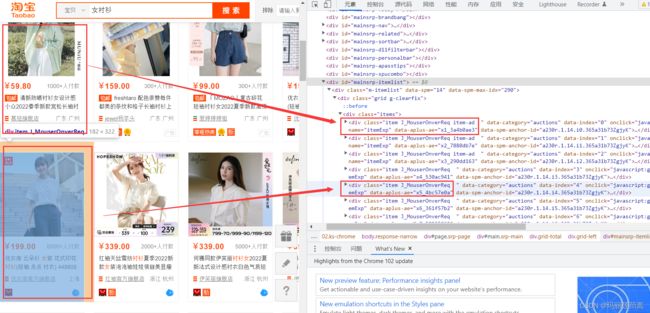
这里发现前三个商品的class和后面的都不一样,仔细一看,前三个是给淘宝上供的广告商品。那就不pa前三个了吧
3.
遇到淘宝的反pa,不想弄了
目录
一、jsoup入门
1.1 org.jsoup.Jsoup类
1.2 org.jsoup.nodes.Document类
1.2.1 DOM
1.2.2 CSS选择器
1.3 org.jsoup.nodes.Element类
二、 创建项目
三、 京东完整代码(简单版)
四、 京东多页版
五、 淘宝进阶版
要实现多样化的pa取,还得从jsoup本身学起呀!
(1)定义:JSoup是一个用于处理HTML的Java库,它提供了一个非常方便类似于使用DOM,CSS和jQuery的方法的API来提取和操作数据。
(2)主要作用:
- DOM:将HTML解析为与现代浏览器相同的DOM,和js中的document对象一样,用getElementById等方法获取元素
- CSS:利用CSS选择器选择src等属性
(3)API学习
学习jsoup就是学习这几个类的方法。
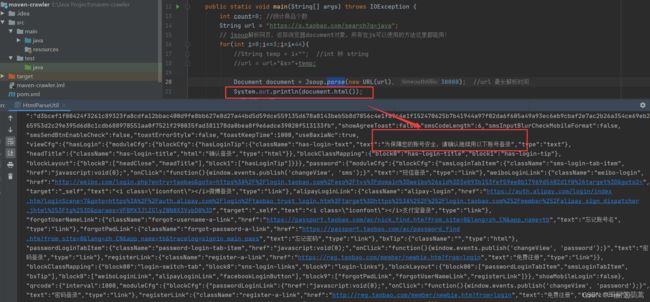
主要就是记parse这个函数就行了
Document document = Jsoup.parse(new URL(url), 30000); //url 最长解析时间document对象和JavaScript里的document是一个东西,js里能用的方法这里都能调用。
Element element = document.getElementById("J_goodsList");下面例子中从HTML提取带a[href] 、src、 link[href]属性的元素,再用这些元素的attr函数提取更精确额内容。
Document doc = Jsoup.connect(url).get();
Elements links = doc.select("a[href]");
Elements media = doc.select("[src]");
Elements imports = doc.select("link[href]");
print("\nLinks: (%d)", links.size());
for (Element link : links) {
print(" * a: <%s> (%s)", link.attr("abs:href"), trim(link.text(), 35));
}
print("\nMedia: (%d)", media.size());
for (Element src : media) {
if (src.tagName().equals("img"))
print(" * %s: <%s> %sx%s (%s)",
src.tagName(), src.attr("abs:src"), src.attr("width"), src.attr("height"),
trim(src.attr("alt"), 20));
else
print(" * %s: <%s>", src.tagName(), src.attr("abs:src"));
}
print("\nImports: (%d)", imports.size());
for (Element link : imports) {
print(" * %s <%s> (%s)", link.tagName(),link.attr("abs:href"), link.attr("rel"));
}
示例输出:
Imports: (2)
* link (stylesheet)
* link (shortcut icon)
Media: (38)
* img: 18x18 ()
* img: 10x1 ()
* img: x ()
Links: (141)
* a: ()
* a: (Hacker News)
* a: (new)
根据下面的例子理解吧
因为要用到解析网页的jsoup依赖,所以新建一个maven项目。
添加jsoup依赖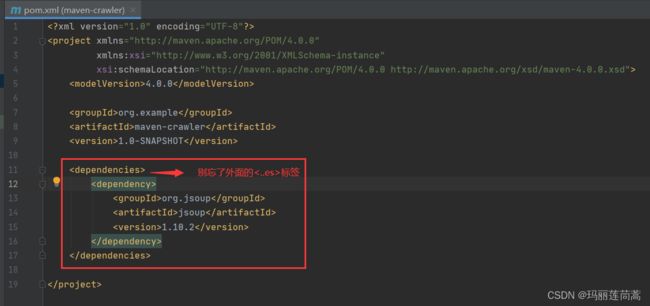
在侧边栏检查一下,发现添加成功

京东抓取一页商品的代码
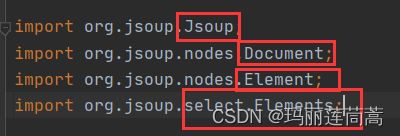
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
import java.net.MalformedURLException;
import java.net.URL;
public class HtmlParseUtil {
public static void main(String[] args) throws IOException {
//被pa取页面的url https://search.jd.com/Search?keyword=Java
String url = "https://search.jd.com/Search?keyword=女衬衫";
// jsoup解析网页,返回浏览器document对象,所有在js可以使用的方法这里都能用!
Document document = Jsoup.parse(new URL(url), 30000); //url 最长解析时间
Element element = document.getElementById("J_goodsList");
// 获取J_goodsList下的所有的li元素
Elements elements = element.getElementsByTag("li");
int count=0;
for (Element el : elements) {
// 找到![]() 标签; 找到
标签; 找到标签下的第1个![]() 标签; 获取其src属性
//String img = el.getElementsByTag("img").eq(0).attr("src");
// 找到"p-price"类;找到
标签; 获取其src属性
//String img = el.getElementsByTag("img").eq(0).attr("src");
// 找到"p-price"类;找到 标签下的第1个"p-price"; 将其内容转为文字
String price = el.getElementsByClass("p-price").eq(0).text();
// 同上
String name = el.getElementsByClass("p-name").eq(0).text();
//System.out.println(img);
System.out.println(price);
System.out.println(name);
count++;
}
System.out.println(count);
}
}
只需要将url最后的“女衬衫” 改为你想搜索的商品就行了。
结果如下图:
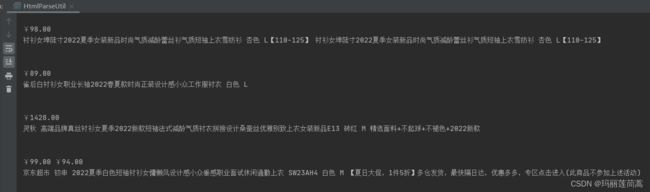
但是只能实现第一页的pa取。
借鉴:jsoup pa取分页的内容_depthwhite的博客-CSDN博客_jsoup pa取分页
网站显示内容基本上都是通过分页来显示,我们用jsoup简单pa取页面仅能获取本页的内容,对于其他页面的内容该如何pa取?其实很简单,就是通过检查下一页的链接地址,基本上下一页的超链接地址都是有规律的,基本上都是*****/1或者*****/2等等,所以我们可以按照这个规律,循环访问页面,抓取信息即可;当然,通过选择器直接将下一页的url获取出来也可以,不过我觉得直接分析还是比较简单。
因为选择器不太熟,我选择采用观察法。
当我翻到第二页的时候,发现URL后面多了一大串,似乎没有规律可循(崩溃)。
![]()
让人头大的是pvid=后面的一串是随机的。下一次搜索就变了
![]()
![]()
比如说我只输入上面的URL,就可以访问java商品的第6页
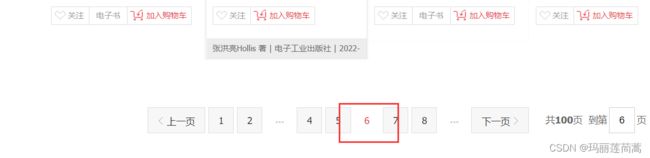
那这样的话,我们给上面的简单版代码套一个循环就可以访问多页了。
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
import java.net.MalformedURLException;
import java.net.URL;
public class HtmlParseUtil {
public static void main(String[] args) throws IOException {
int count=0; //统计商品个数
//被pa取页面的url https://search.jd.com/Search?keyword=Java
String url = "https://search.jd.com/Search?keyword=java";
// jsoup解析网页,返回浏览器document对象,所有在js可以使用的方法这里都能用!
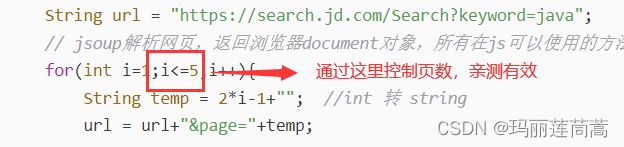
for(int i=1;i<=5;i++){
String temp = 2*i-1+""; //int 转 string
url = url+"&page="+temp;
Document document = Jsoup.parse(new URL(url), 30000); //url 最长解析时间
Element element = document.getElementById("J_goodsList");
// 获取J_goodsList下的所有的li元素
Elements elements = element.getElementsByTag("li");
for (Element el : elements) {
// 找到![]() 标签; 找到
标签; 找到标签下的第1个![]() 标签; 获取其src属性
//String img = el.getElementsByTag("img").eq(0).attr("src");
// 找到"p-price"类;找到
标签; 获取其src属性
//String img = el.getElementsByTag("img").eq(0).attr("src");
// 找到"p-price"类;找到 标签下的第1个"p-price"; 将其内容转为文字
String price = el.getElementsByClass("p-price").eq(0).text();
// 同上
String name = el.getElementsByClass("p-name").eq(0).text();
//System.out.println(img);
System.out.println(price);
System.out.println(name);
count++;
}
}
System.out.println(count);
}
}

1. 找到所有商品对应的
2.找到每一个商品对应的标签
这里发现前三个商品的class和后面的都不一样,仔细一看,前三个是给淘宝上供的广告商品。那就不pa前三个了吧
3.
遇到淘宝的反pa,不想弄了