解决加载大量列表DOM导致浏览器性能瓶颈的虚拟滚动技术
【为什么使用虚拟滚动】提到前端性能瓶颈,大家首先会想到的现象就是页面卡顿。当然,页面很“卡”这个表现,用前端的视角来看,也有几种不同的诱因。例如 http 请求过多导致数据加载很慢、下载的静态文件非常大导致页面加载时长很高(CSS,JS,静态图片等)、js在密集型计算中本身性能拉胯等等。当然,本文所阐述的也是前端近几年一直想方设法优化的一个切入点,DOM 渲染。
【浏览器渲染原理】即使不太懂前端技术的同学,看到前端或是网页,通常会想到三个名词:HTML、CSS、JS。一个完成的网页也是由这三个元素组合而成的,这里可以拿乐高对比,HTML好比是不同长宽、大小的积木块,CSS 就是这些积木块的颜色,JS便是积木块的一些交互事件,例如有些积木块是轮胎可以滚动并带动整个上层的积木块产生位移等。而浏览器渲染自然也会去解析这三块内容并拼凑成一个完整的网页:
-
HTML/SVG/XHTML 解析提供的html文件会产生一个 DOM Tree。
-
CSS 解析CSS会生成一个CSS Rule Tree
-
在渲染阶段,浏览器会把 DOM Tree 和 CSS Rule Tree 进行一个结合,生成一个最终的 DOM Tree并赋予每个树节点样式,生成 Render Tree
-
布局 Render Tree(layout/reflow),绘制各元素尺寸、位置计算
-
绘制 Render Tree (paint),绘制页面像素信息
-
将计算好的信息发送给 GPU 并显示在屏幕上
举个例子,下方HTML文本在浏览器中的渲染过程:
Yunqu Web Title 1
Content
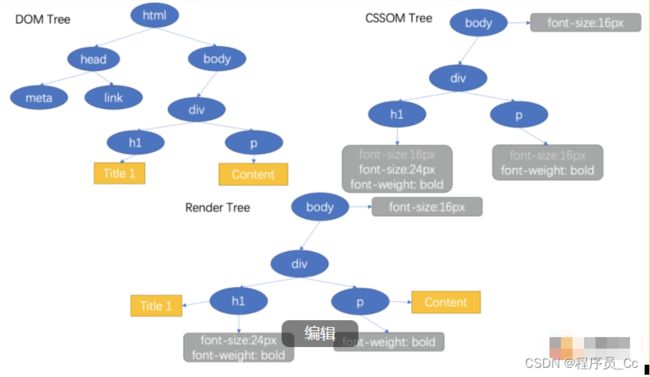
看完上面的注解大家应该大致明白浏览器渲染一次页面大概需要做什么步骤,当然,网页不是纯静态的,我们势必会在页面上进行交互,而交互过后的结果也会导致页面上部分元素产生变动,例如样式或布局上,这就成为回流和重绘。
-
重绘:当 Render tree 中的一些元素需要更新属性,而这些属性只影响到元素的外观(例如颜色)而不会影响到整体布局
-
回流:当 Render Tree 中的一部分(或全部)元素因为规模、尺寸等等其他因素而改变时则需要重新构建 DOM Tree
【性能瓶颈】从上文可以看出,回流必定发生重绘,而重绘不一定会引发回流。由此可以推断,回流所带来的成本是非常高的,如果频繁触发回流操作,那势必会造成页面的卡顿。已知下列操作都会导致回流和重绘:
-
页面第一次渲染(初始化)
-
添加或删除可见的 DOM 元素
-
元素的位置发生变化
-
元素的尺寸发生变化(包括外边距,内边距,边框大小,高度和宽度等)
-
内容发生变化,比如文本变化或图片被另一个不同尺寸的图片所替代或者字体改变
-
浏览器窗口尺寸的变化(因为回流是根据视口的大小来计算元素的位置和大小的)
-
定位或者浮动,盒模型等
当然,由于每次重排都会造成巨大的性能消耗,大多数浏览器本身会实现一个队列去记录每次重排的动作,当队列中的动作达到一定的阈值或是经过一定的时间后会批量清空队列并进行一次重排,这样就会让原本多次的重排压缩成一次处理。
但是凡事没有绝对,当出现获取布局信息的操作时(这里可以理解为用户的某些行为需要看到浏览器页面的直接反馈效果),会立即刷新该队列的刷新并触发重排:
-
offsetTop, offsetLeft, offsetWidth, offsetHeight(获取元素位置信息)
-
scrollTop, scrollLeft, scrollWidth, scrollHeight(溢出类元素的滚动条操作)
-
clientTop, clientLeft, clientWidth, clientHeight(获取滚动条偏移量)
-
getComputedStyle()
-
getBoundingClientRect()
本文会围绕列举的第二种情况,也就是 scroll event(滚动事件)的发生来讲解性能优化。这里我们需要明确,不是滚动事件本身就一定意味着性能上的消耗,而是该动作如果伴随着大量的元素参与到了重排的动作中,那么才会引起性能上的焦虑。这里需要注意,我们加粗了“大量”这个关键词,俗话说得好,量变引起质变,即使是频繁重排但是只涉及到两三个元素,那么以现在我们的硬件性能也不在话下。但问题就在于特殊的业务场景,例如需要在页面上表现一个超长的表格(可能上万行数据),就是需要所有数据一次性都展示在页面中,并且在滚动时及时显示对应偏移量的数据,那么每一次滚动都是对这几万个元素的重排,性能自然不堪入目。
【分段渲染】那么在上文的大背景下,我们可以得出浏览器的性能瓶颈在于两点:
-
无法一次性渲染太多的 DOM 元素
-
每一次滚动事件将会让对应 DOM 中的所有元素重新渲染
现在看来,这两点大条件是客观存在的,我们无法改变,所以这时候解决的方案就呼之欲出了,别让浏览器一次性渲染这么多元素,这里通常会对应三种做法来减少元素渲染。
【数据分页】这个方案是大家浏览到页面所常用的,通常在需要展示非常多行的数据时页面会采用分页的做法来分割数据,但在SQL结果集的场景下并不是通用方案,原因是虽然该方法减少了一次性所渲染的行数,但是如果查询的表列数非常多的话,还是有很大概率需要渲染非常多的元素,所以不是一个稳妥的选型。
【无限滚动】该方案的解决方法是第一次只渲染所能承受范围内的数据量,当滚动条拖动接近底部(或右部)时,再去追加下一批所需要渲染的元素,该方案也是有一个明显的缺陷在于,无限地滚动下去必然会触及浏览器的性能瓶颈,而且所需要渲染的元素会越来越多,性能迟早会被拖垮。
【什么是虚拟滚动】
其实答案已经隐藏在上面两种解决方案里面了,数据分页的方案是一次性渲染固定行数和列数的数据量,缺点是怕一次性的量就逼近上限。无限滚动的方案是想看更多数据的时候再继续渲染,不看就不渲染避免性能浪费,但缺点就在于只要一直触发“继续看”的操作,那么之前遗留的数据将会越来越多导致性能雪崩。
这时候我们可以把两个方案中和一下,既然在有限的视窗中我们只能看到一部分的数据,那么我们就通过计算可视范围内的单元格,这样就保证了每一次拖动,我们渲染的 DOM 元素始终是可控的,不会像数据分页方案怕一次性渲染过多,也不会发生无限滚动方案中的老数据堆积现象。接下来我们用一张图来表示虚拟滚动的表现形式。

根据图中我们可以看到,无论我们如何滚动,我们可视区域的大小其实是不变的,那么要做到性能最大化就需要尽量少地渲染 DOM 元素,而这个最小值也就是可视范围内需要展示的内容,也就是图中的绿色区块,在可视区域之外的元素均可以不做渲染。
那么问题就来了,如何计算可视区域内需要渲染的元素,我们通过如下几步来实现虚拟滚动:
-
每一行的高度需要相同,方便计算
-
需要得知渲染的数据量(数组长度),可基于总量和每个元素的高度计算出容器整体的所需高度,这样就可以伪造一个真实的滚动条
-
获取可视区域的高度
-
在滚动事件触发后,滚动条的距顶距离也可以理解为这个数据量中的偏移量,再根据可视区域本身的高度,算出本次偏移的截止量,这样就得到了需要渲染的具体数据
-
如果类似于渲染一个宽表,单行可横向拆分为多列,那么在X轴上同理实现一次,就可以横向的虚拟滚动
【背景说明】假设实际开发中服务端一次响应10万条列表数据,此时设备屏幕只允许容纳10条,那么用户理论上只可以看见10条数据。此时如果前端将10万条数据全部渲染成DOM元素,可能造成程序卡顿,占用较大资源,非常影响用户体验,那么虚拟滚动技术就完美的解决了这一问题。
【虚拟滚动案例网址】虚拟滚动原理(未来此地址可能失效,失效后请直接复制源码学习)
【虚拟滚动的实现】
虚拟滚动原理
20条
一百条
一千条
十万条
-
{{item}}
【实现原理】
1、获取滚动高度
2、列表单个item的高度
3、计算屏幕容纳几个item
4、计算滚动了几个item到顶部不可见区域
5、使用css3的transform属性将滚动到上方不可见区域的DOM元素偏移到可见区域,同时进行数据的更新(重绘操作节约性能)。
总结:虚拟滚动技术的实现是合理运用“回流必定发生重绘,而重绘不一定会引发回流”的理论进行实现。