PromQL 直方图 跟踪请求的延迟或响应大小 99%的请求是在多少延迟下完成的?

API Server 监控
API Server 是 Kubernetes 集群中所有组件交互的中枢。下表列出了 API Server 的主要监控指标。
| 指标 | 描述 |
|---|---|
| 请求延迟 | 资源请求响应延迟,单位为毫秒。该指标按照 HTTP 请求方法进行分类。 It’s a good idea to use percentiles to understand the latency spread: histogram_quantile(0.99, sum(rate(apiserver_request_latencies_count{job="kubernetes-apiservers"}[5m])) by (verb, le))
|
| 每秒请求次数 | kube-apiserver 每秒接受的请求数。 |

Histogram
摘要非常有用,但是平均值会隐藏一些细节,如果我们想查看时间花在什么地方了,那么我们就需要直方图了。
直方图以 bucket 桶的形式记录数据,所以我们可能有一个桶用于需要 1s 或更少的计算,另一个桶用于 5 秒或更少、10 秒或更少、20 秒或更少、60 秒或更少。该指标返回每个存储桶的计数,其中 3 个在 5 秒或更短的时间内完成,6 个在 10 秒或更短的时间内完成。
Prometheus 中的直方图是累积的,因此所有 10 次计算都属于 60 秒或更少的时间段,而在这 10 次中,有 9 次的处理时间为 20 秒或更少,这显示了数据的分布。所以可以看到我们的大部分计算都在 10 秒以下,只有一个超过 20 秒,这对于计算百分位数很有用。
在 Prometheus Server 自身返回的样本数据中,我们也能找到类型为 Histogram 的监控指标prometheus_tsdb_compaction_chunk_range_seconds_bucket:可以看到这个值是一直增加的,因为是累计增加的,因为1600是包含前面400和100的。
# HELP prometheus_tsdb_compaction_chunk_range_seconds Final time range of chunks on their first compaction
# TYPE prometheus_tsdb_compaction_chunk_range_seconds histogram
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="100"} 71
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="400"} 71
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="1600"} 71
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="6400"} 71
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="25600"} 405
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="102400"} 25690
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="409600"} 71863
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="1.6384e+06"} 115928
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="6.5536e+06"} 2.5687892e+07
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="2.62144e+07"} 2.5687896e+07
prometheus_tsdb_compaction_chunk_range_seconds_bucket{le="+Inf"} 2.5687896e+07
prometheus_tsdb_compaction_chunk_range_seconds_sum 4.7728699529576e+13
prometheus_tsdb_compaction_chunk_range_seconds_count 2.5687896e+07Histogram vs Summary
与 Summary 类型的指标相似之处在于 Histogram 类型的样本同样会反应当前指标的记录的总数(以 _count 作为后缀)以及其值的总量(以 _sum 作为后缀)。
不同在于 Histogram 指标直接反应了在不同区间内样本的个数,区间通过标签 le 进行定义。histogram有专门的函数去计算。
直方图
在这一节中,我们将学习直方图指标,了解如何根据这些指标来计算分位数。Prometheus 中的直方图指标允许一个服务记录一系列数值的分布。
直方图通常用于跟踪请求的延迟或响应大小等指标值,当然理论上它是可以跟踪任何根据某种分布而产生波动数值的大小。Prometheus 直方图是在客户端对数据进行的采样,它们使用的一些可配置的(例如延迟)bucket 桶对观察到的值进行计数,然后将这些 bucket 作为单独的时间序列暴露出来。
下图是一个非累积直方图的例子:(x轴是区间,y轴对应的是值。,统计的是每个区间里面的个数,一个区间就是一个bucket,比如0-25是一个bucket,25-50也是一个bucket。25-50这个区间值是40,这个40可能是延时时长也可能是响应大小,得看具体的值)

在 Prometheus 内部,直方图被实现为一组时间序列(不是单个的,0-25实际上代表一个bucket桶,但是在Prometheus也是一个时间序列,25-50 50-100 100-25都是序列),每个序列代表指定桶的计数(例如25ms以下的请求数20个、50ms以下的请求数20+40个、100ms以下的请求数20+40+30等)。
在 Prometheus 中每个 bucket 桶的计数器是累加的,这意味着较大值的桶也包括所有低数值的桶的计数。(后面的时间序列包含前面时间序列值的)
在作为直方图一部分的每个时间序列上,相应的桶由特殊的 le 标签表示。le 代表的是小于或等于。
与上面相同的直方图在 Prometheus 中的累积直方图如下所示:
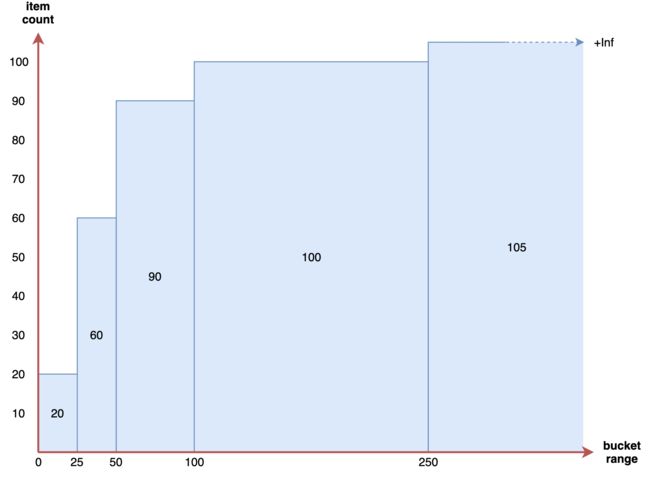
可以看到在 Prometheus 中直方图的计数是累计的,这是很奇怪的,因为通常情况下非累积的直方图更容易理解。Prometheus 为什么要这么做呢?
想象一下,如果直方图指标中加入了额外的标签,或者划分了更多的 bucket,那么样本数据的分析就会变得越来越复杂,如果直方图是累积的,在抓取指标时就可以根据需要丢弃某些 bucket,这样可以在降低 Prometheus 维护成本的同时,还可以粗略计算样本值的分位数。(有些时候区间需要划分的更加细粒度,但是真正来抓取这些指标的时候,这些细粒度的可对我们意义不是特别大,那么我们之间丢弃就行了。丢弃了之后不会影响后面去计算的一些值。如果是非累计直方图,如果将前面的丢弃了,那么小于100区间的请求就不能获取了,只知道50-100之间,0-50的被丢弃了)通过这种方法,用户不需要修改应用代码,便可以动态减少抓取到的样本数量。
另外直方图还提供了 _sum 指标和 _count 指标,所以即使你丢弃了所有的 bucket,仍然可以通过这两个指标值来计算请求的平均响应时间。通过累积直方图的方式,还可以很轻松地计算某个 bucket 的样本数占所有样本数的比例。
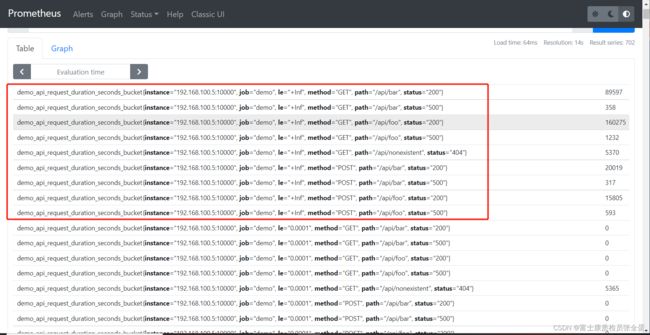
我们在演示的 demo 服务中暴露了一个直方图指标 demo_api_request_duration_seconds_bucket,用于跟踪 API 请求时长的分布,由于这个直方图为每个跟踪的维度导出了 26 个 bucket,因此这个指标有很多时间序列。我们可以先来看下来自一个服务实例的一个请求维度组合的直方图,查询语句如下所示:
demo_api_request_duration_seconds_bucket{instance="demo-service-0:10000", method="POST", path="/api/bar", status="200", job="demo"}
正常我们可以看到 26 个序列,每个序列代表一个 bucket,由 le 标签标识:(所有bucket的值加起来等于+inf的值,都包含进去了)

直方图可以帮助我们了解这样的问题,比如"我有多少个请求超过了100ms的时间?" (当然需要直方图中配置了一个以 100ms 为边界的桶),又比如"我99%的请求是在多少延迟下完成的?",这类数值被称为百分位数或分位数。在 Prometheus 中这两个术语几乎是可以通用,只是百分位数指定在 0-100 范围内,而分位数表示在 0 和 1 之间,所以第 99 个百分位数相当于目标分位数 0.99。
如果你的直方图桶粒度足够小,那么我们可以使用 histogram_quantile(φ scalar, b instant-vector) 函数用于计算历史数据指标一段时间内的分位数。该函数将目标分位数 (0 ≤ φ ≤ 1) 和直方图指标作为输入,就是大家平时讲的 pxx,p50 就是中位数,参数 b 一定是包含 le 这个标签的瞬时向量,不包含就无从计算分位数了,但是计算的分位数是一个预估值,并不完全准确,因为这个函数是假定每个区间内的样本分布是线性分布来计算结果值的,预估的准确度取决于 bucket 区间划分的粒度,粒度越大,准确度越低。
回到我们的演示服务,我们可以尝试计算所有维度在所有时间内的第 90 个百分位数,也就是 90% 的请求的持续时间。
# BAD!
histogram_quantile(0.9, demo_api_request_duration_seconds_bucket{job="demo"})
但是这个查询方式是有一点问题的,当单个服务实例重新启动时,bucket 的 Counter 计数器会被重置,而且我们常常想看看现在的延迟是多少(比如在过去 5 分钟内),而不是整个时间内的指标。我们可以使用 rate() 函数应用于底层直方图计数器来实现这一点,该函数会自动处理 Counter 重置,又可以只计算每个桶在指定时间窗口内的平均增长。
我们可以这样去计算过去 5 分钟内第 90 个百分位数的 API 延迟:
# GOOD!
histogram_quantile(0.9, rate(demo_api_request_duration_seconds_bucket{job="demo"}[5m]))
这个查询就好很多了。
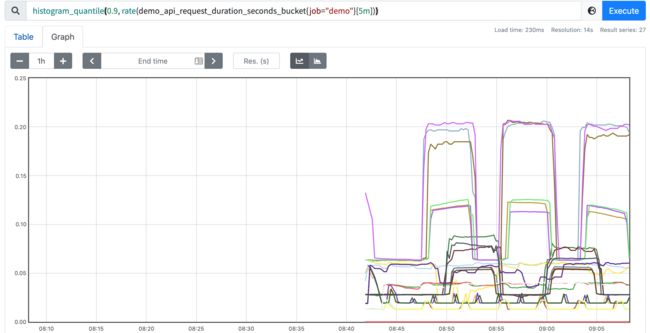
这个查询会显示每个维度(job、instance、path、method 和 status)的第 90 个百分点,但是我们可能对单独的这些维度并不感兴趣,想把他们中的一些指标聚合起来,这个时候我们可以在查询的时候使用 Prometheus 的 sum 运算符与 histogram_quantile() 函数结合起来,计算出聚合的百分位,假设在我们想要聚合的维度之间,直方图桶的配置方式相同(桶的数量相同,上限相同),我们可以将不同维度之间具有相同 le 标签值的桶加在一起,得到一个聚合直方图。然后,我们可以使用该聚合直方图作为 histogram_quantile() 函数的输入。
注意:这是假设直方图的桶在你要聚合的所有维度之间的配置是相同的,桶的配置也应该是相对静态的配置,不会一直变化,因为这会破坏你使用
histogram_quantile()查看的时间范围内的结果。
下面的查询计算了第 90 个百分位数的延迟,但只按 job,le,instance 和 path 维度进行聚合结果: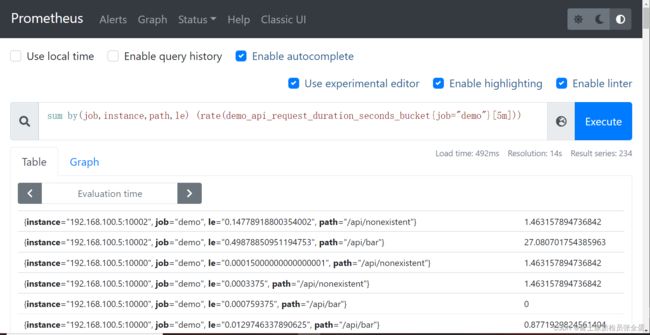

计算完分位数之后le标签就不存在了。
如果不是特别理解histogram_quantile计算出来值的话,只需要记住,前面这个是分位数,计算的是90个分位数,后面是一个瞬时的向量,而且一定要包含le这个标签的。
练习:
1.构建一个查询,计算在 0.0001 秒内完成的 demo 服务 API 请求的总百分比,与过去 5 分钟内所有请求总数的平均值。
sum(rate(demo_api_request_duration_seconds_bucket{le="0.0001"}[5m])) / sum(rate(demo_api_request_duration_seconds_bucket{le="+Inf"}[5m])) * 100或者可以使用下面的语句查询
sum(rate(demo_api_request_duration_seconds_bucket{le="0.0001"}[5m])) / sum(rate(demo_api_request_duration_seconds_count[5m])) * 1002.构建一个查询,计算 demo 服务 API 请求的第 50 个百分位延迟,按 status code 和 method 进行划分,在过去一分钟的平均值。
histogram_quantile(0.5, sum by(status, method, le) (rate(demo_api_request_duration_seconds_bucket[1m])))