【数学建模】常用算法-线性回归Python实现
1 前言
本文主要讲解基于线性回归的糖尿病预测的python实现,后续会进行进一步的更新
2 代码实现
2.1 数据准备
导入相关的包
import numpy as np
import pandas as pd
加载数据集
这个数据集是sklearn.datasets自带的糖尿病数据集(diabetes),关于该数据集的详情大家可以去官网自行查阅
from sklearn.datasets import load_diabetes
diabetes = load_diabetes() # 加载数据集
data = diabetes.data
target = diabetes.target
查看数据集形状以及数据和标签的前5个样本
print(data.shape)
print(target.shape)
print(data[:5])
print(target[:5])
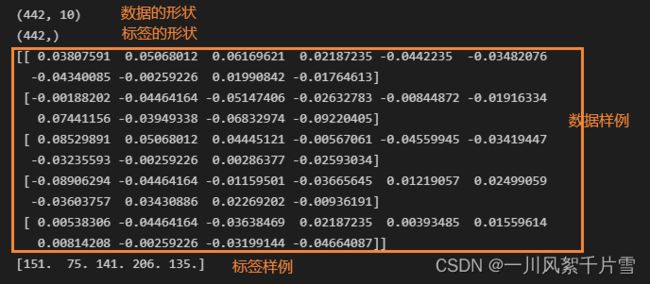
可以看到数据中包括10列特征,一列标签
2.2 模型定义
接下来讲解线性回归模型的代码实现,模型的原理大家可以自己进行查阅
初始化线性回归模型的模型参数
### 初始化模型参数
def initialize_params(dims):
'''
dims: 训练数据的维度
w: 初始化的权重
b: 初始化的偏置
'''
w = np.zeros((dims, 1))
b = 0
return w, b
定义模型主体部分
### 定义模型主体部分
### 包括线性回归公式、均方损失和参数偏导三部分
def linear_loss(X, y, w, b): # 训练集数据、y训练集标签
num_train = X.shape[0] # 有多少条训练样本
num_feature = X.shape[1] # 特征的维度
y_hat = np.dot(X, w) + b # 求线性回归模型的预测值
loss = np.sum((y_hat-y)**2)/num_train # 计算损失函数
dw = np.dot(X.T, (y_hat-y)) /num_train
db = np.sum((y_hat-y)) /num_train
return y_hat, loss, dw, db
定义线性回归模型训练的过程
### 定义线性回归模型训练过程
def linear_train(X, y, learning_rate=0.01, epochs=10000):
loss_his = [] # 记录损失函数的空列表 #每次迭代的均方损失
w, b = initialize_params(X.shape[1])
for i in range(1, epochs):
y_hat, loss, dw, db = linear_loss(X, y, w, b)
w += -learning_rate * dw
b += -learning_rate * db
loss_his.append(loss)
if i % 10000 == 0:
print('epoch %d loss %f' % (i, loss))
params = {
'w': w,
'b': b
}
grads = {
'dw': dw,
'db': db
}
return loss_his, params, grads
2.3 训练集和数据集的划分
# 导入sklearn diabetes数据接口
from sklearn.datasets import load_diabetes
# 导入sklearn打乱数据函数
from sklearn.utils import shuffle
diabetes = load_diabetes()
data, target = diabetes.data, diabetes.target # 与上边两行是等价的关系
X, y = shuffle(data, target, random_state=13) # 随机打乱数据集,随机种子设置为13
offset = int(X.shape[0] * 0.8) # 按照8:2的比例划分了训练集和测试集
X_train, y_train = X[:offset], y[:offset] # 训练数据和训练标签
X_test, y_test = X[offset:], y[offset:] # 测试数据和测试标签
y_train = y_train.reshape((-1,1))
y_test = y_test.reshape((-1,1))
print("X_train's shape: ", X_train.shape)
print("X_test's shape: ", X_test.shape)
print("y_train's shape: ", y_train.shape)
print("y_test's shape: ", y_test.shape)
2.4 模型的训练与预测
定义训练时候的模型参数
# 线性回归模型训练
loss_his, params, grads = linear_train(X_train, y_train, 0.01, 200000)
# 打印训练后得到模型参数
print(params)
定义预测函数
### 定义线性回归预测函数
def predict(X, params):
w = params['w']
b = params['b']
# b = 150.8144748910088
y_pred = np.dot(X, w) + b
return y_pred
y_pred = predict(X_test, params)
y_pred[:5]
定义评价指标,R2为回归问题的常用指标,大家可以尝试更多的指标,例如MSE、MAE等等
### 定义R2系数函数
def r2_score(y_test, y_pred):
y_avg = np.mean(y_test)
ss_tot = np.sum((y_test - y_avg)**2) # 总离差平方和
ss_res = np.sum((y_test - y_pred)**2) # 残差平方和
r2 = 1 - (ss_res/ss_tot) # R方
return r2
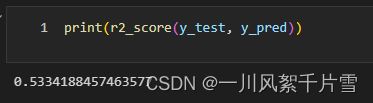
打印评价指标的值,线性回归在该数据及上的效果不是很理想,后续会使用更多模型进行讲解
print(r2_score(y_test, y_pred))