Python爬虫第一次打卡学习
参加活动:Datawhale Python爬虫打卡学习小组
笔记:第一次打卡活动学习内容
开源链接
一.互联网、HTTP、网页概念
1.1 互联网vs万维网:
互联网(Internet):
网络与网络所串联成的庞大网络,这些网络以一组标准的网络协议族相连,连接全世界几十亿个设备,形成逻辑上的单一巨大国际网络。这种将计算机网络互相连接在一起的方法可称作“网络互联”,在此基础上发展出来的覆盖全世界的全球性互联网络称为“互联网”,即相互连接在一起的网络。
万维网(World Wide Web):
一个超文本相互链接而成的全球性系统,而且是互联网所能提供的服务之一。万维网由浏览器浏览连超文本页面组成,这些超文本页面是通过TCP/IP协议从网络上获取的。网页的开头部分总是http://或者https://,表明被浏览器的信息是超文本,是利用超文本传输协议来传输的。互联网包含广泛的信息资源和服务,例如相互关联的超文本文件,还有万维网的应用,支持电子邮件的基础设施、点对点网络、文件共享,以及IP电话服务。
此处可参考CSDN上一位大佬的解释,链接如下:
互联网和万维网的区别:https://blog.csdn.net/sinat_36728518/article/details/79369789
1.2 HTTP

HTTP的请求方法:
GET,HEAD,POST,PUT,DELETE,TRACE,OPTIONS,CONNECT
1.3 网页
点击跳转到菜鸟教程CSS|HTML
网页组成三要素: HTML 、 CSS 、JavaScript 。
1)HTML :搭建整个网页的骨架;
2)CSS :美化页面;
3)JavaScript: 让网页“动”起来,即网页的数据动态交互和网页上的动画(动画由 JavaScript 配合 CSS 来完成)。
网页结构:
以建立一个demo.html为例,效果图如下:

代码如下:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Demo</title>
</head>
<body>
<div id="container">
<div class="wrapper">
<h1>Hello World</h1>
<div>Hello Python.</div>
</div>
</div>
</body>
</html>
注意:文件保存为".html"格式
作出部分修改后:

<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Demo</title>
</head>
<body style="background-color:grey;">
<div #container>
<div .wrapper>
<h1 style="text-align:center;background-color:black;color:white;">Hello World</h1>
<div style="text-align:center;background-color:white;color:black;">Hello Python.</div>
</div>
</div>
</body>
</html>
二.使用开发者工具检查网页
略(因为Datawhale已经讲得图文并茂)
点击跳转笔记链接
2.1 Requests库的基本应用
2.1.1 Requests.get
爬取的网络链接:https://www.python.org/dev/peps/pep-0020/
import requests
url = 'https://www.python.org/dev/peps/pep-0020/'
res = requests.get(url)
text = res.text
text
运行结果以字符串返回了开发者工具下的Elements的内容(截取了部分图片如下):

接下来用python的内置函数find来定位“python之禅”的索引,然后从这段字符串中取出它。步骤如下:
1)通过观察网站,我们可以发现这段话在一个特殊的容器中,通过审查元素,使用快捷键Ctrl+shift+c快速定位到这段话也可以发现这段话包围在pre标签中,因此我们可以由这个特定用find函数找出具体内容。
*: < p r e >
<pre>标签可定义预格式化的文本。 被包围在" < p r e >
<pre> 标签 元素中的文本通常会保留空格和换行符。而文本也会呈现为等宽字体。
2)
## 爬取python之禅并存入txt文件
with open('zon_of_python.txt', 'w') as f:
f.write(text[text.find(')+28:text.find(' 
为什么"+28"
print(text[text.find(')+28])
print(text[text.find(')+28:text.find(')+59])

*:在chrome源代码页search的时候,可以直接用"CTRL+F",或者在工具栏寻找"search"按键查找想找的关键词。
Requests.post
爬取链接金山词霸:http://www.iciba.com/
步骤:
1)打开开发者工具下的“Network”,翻译一段话,比如刚刚我们爬到的第一句话“Beautiful is better than ugly.”

2)点击翻译后可以发现Name下多了一项请求方法是POST的数据
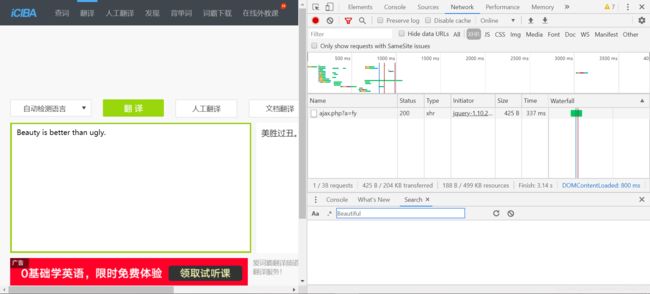
3)点击Preview可以发现数据中有我们想要的翻译结果
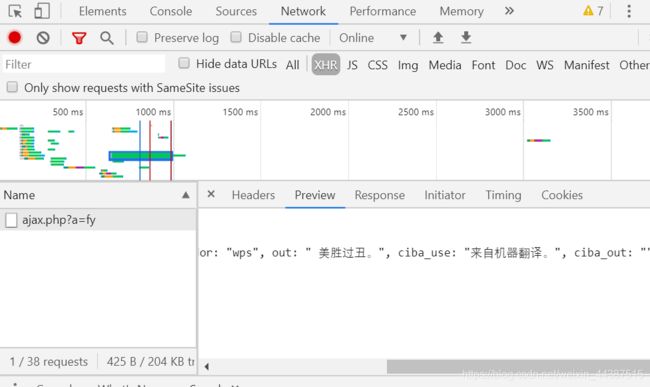
我们目前需要用到的两部分信息是Request Headers中的User-Agent,和From Data。

接下来我们利用金山词霸来翻译我们刚刚爬出来的python之禅
import requests
def translate(word):
url="http://fy.iciba.com/ajax.php?a=fy"
data={
'f': 'auto',
't': 'auto',
'w': word,
}
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36',
}#User-Agent会告诉网站服务器,访问者是通过什么工具来请求的,如果是爬虫请求,一般会拒绝,如果是用户浏览器,就会应答。
response = requests.post(url,data=data,headers=headers) #发起请求
json_data=response.json() #获取json数据
#print(json_data)
return json_data
def run(word):
result = translate(word)['content']['out']
print(result)
return result
def main():
with open('zon_of_python.txt') as f:
zh = [run(word) for word in f]
with open('zon_of_python_zh-CN.txt', 'w') as g:
for i in zh:
g.write(i + '\n')
if __name__ == '__main__':
main()
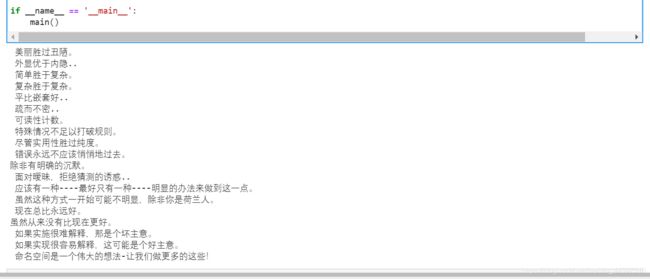
三. API的使用
3.1 定义
首先,我们明确什么是数据采集。请看百度释义:
“网络数据采集”是指利用互联网搜索引擎技术实现有针对性、行业性、精准性的数据抓取,并按照一定规则和筛选标准进行数据归类,并形成数据库文件的一个过程。
采集网络数据,并不一定必须从网页中抓取数据。API(Application Programming Iterface)的用处就在这里:API为开发者提供了方便友好的接口,不同的开发者用不同的语言都能获取相同的数据。目前API一般会以XML(Extensible Markup Language,可拓展标记语言)或者JSON(JavaScript Object Notation)格式来返回服务器响应,其中JSON数据格式越来越受到人们的欢迎。
3.2 使用示例
以百度地图为例:http://lbsyun.baidu.com/apiconsole/key
填写自己的信息:
根据指示申请完毕后,可以申请密钥。这里我们选择应用类型:“浏览器端”,启用服务:所有;Refer白名单:*,提交,即可跳入新的页面。
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<meta name="viewport" content="initial-scale=1.0, user-scalable=no" />
<style type="text/css">
body,
html,
#allmap {
width: 100%;
height: 100%;
overflow: hidden;
margin: 0;
font-family: "微软雅黑";
}
</style>
<script type="text/javascript" src="http://api.map.baidu.com/api?v=3.0&ak=输入你自己的ak密钥"></script>
<title>地图展示</title>
</head>
<body>
<div id="allmap"></div>
</body>
</html>
<script type="text/javascript">
// 百度地图API功能
var map = new BMap.Map("allmap"); // 创建Map实例
map.centerAndZoom(new BMap.Point(116.404, 39.915), 11); // 初始化地图,设置中心点坐标和地图级别
//添加地图类型控件
map.addControl(new BMap.MapTypeControl({
mapTypes: [
BMAP_NORMAL_MAP,
BMAP_HYBRID_MAP
]
}));
map.setCurrentCity("北京"); // 设置地图显示的城市 此项是必须设置的
map.enableScrollWheelZoom(true); //开启鼠标滚轮缩放
</script>

关于百度地图API的使用:http://lbsyun.baidu.com/index.php?title=jspopular3.0
3.3 实现地理编码功能
import requests
def getUrl(*address):
ak = '' ## 填入你的api key
if len(address) < 1:
return None
else:
for add in address:
url = 'http://api.map.baidu.com/geocoding/v3/?address={0}&output=json&ak={1}'.format(add,ak)
yield url
def getPosition(url):
'''返回经纬度信息'''
res = requests.get(url)
#print(res.text)
json_data = eval(res.text)
if json_data['status'] == 0:
lat = json_data['result']['location']['lat'] #纬度
lng = json_data['result']['location']['lng'] #经度
else:
print("Error output!")
return json_data['status']
return lat,lng
if __name__ == "__main__":
address = ['北京市清华大学','北京市北京大学','保定市华北电力大学','上海市复旦大学','武汉市武汉大学']
for add in address:
add_url = list(getUrl(add))[0]
print('url:', add_url)
try:
lat,lng = getPosition(add_url)
print("{0}|经度:{1}|纬度:{2}.".format(add,lng,lat))
except Error as e:
print(e)

3.4 JavaScript与AJAX技术
Requests库和BeautifulSoup采集一些大型电商网站页面,对于同一个URL、同一个页面,抓取到的内容却与浏览器中看到的内容有所不同。比如有的时候去寻找某一个
为了避免为每一份要呈现的网页内容都准备一个HTML,网站开发者们开始考虑对网页的呈现方式进行变革。在JavaScript问世之初,Google公司的Gmail邮箱网站是第一个大规模使用JavaScript加载网页数据的产品,在此之前,用户为了获取下一页的网页信息,需要访问新的地址并重新加载整个页面。但新的Gmail则做出了更加优雅的方案,用户只需要单击“下一页”按钮,网页就(实际上是浏览器)会根据用户交互来对下一页数据进行加载,而这个过程并不需要对整个页面(HTML)的刷新。换句话说,JavaScript使得网页可以灵活地加载其中一部分数据。后来,随着这种设计的流行,“AJAX”这个词语也成为一个“术语”,Gmail作为第一个大规模使用这种模式的商业化网站,也成功引领了被称之为“Web2.0”的潮流。
JavaScript语言一般被定义为一种“面向对象、动态类型的解释性语言”,是为“用户浏览器”提供的语言。
3.4.1JavaScript的特点:
1.动态类型
动态语言是指程序在运行时可以改变其结构:新的函数可以被引进,已有的函数可以被删除等在结构上的变化。
2.脚本语言
脚本语言是为了缩短传统的编写-编译-链接-运行(edit-compile-link-run)过程而创建的计算机编程语言,只在被调用时进行解释或编译,然后执行。它的命名起源于一个脚本“screenplay”,每次运行都会使对话框逐字重复。早期的脚本语言经常被称为批量处理语言或工作控制语言。
3.弱类型
弱/强类型指的是语言类型系统的类型检查的严格程度,弱类型的语言在声明变量的时候不必进行变量类型的确定,语言的运行时会隐式做数据类型转换,对于弱类型语言来说,不同类型的变量可以进行直接运算,而强类型的则不可以。
3.4.2 JavaScript实例

alert() 方法:用于显示带有一条指定消息和一个 OK 按钮的警告框。
语法:
alert(message)
<!--test1.html-->
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title></title>
</head>
<body>
<script type="text/javascript">
alert('js课程开始了')
</script>
</body>
</html>
HTML < s c r i p t >