学习神经网络从1x1卷积核开始(在inception中的应用)
11卷积是大小为11的滤波器做卷积操作,不同于22、33等filter,没有考虑在前一特征层局部信息之间的关系。
1、卷积核的原理
卷积核:可以看作对某个局部的加权求和,它是对应局部感知,它的原理是在观察某个物体时我们既不能观察每个像素也不能一次观察整体,而是先从局部开始认识,这就对应了卷积。卷积核的大小一般有1x1,3x3和5x5的尺寸。卷积核的个数就对应输出的通道数,这里需要说明的是对于输入的每个通道,输出每个通道上的卷积核是不一样的。比如输入是28x28x192(WxDxK,K代表通道数),然后在3x3的卷积核,卷积通道数为128,那么卷积的参数有3x3x192x128,其中前两个对应的每个卷积里面的参数,后两个对应的卷积总的个数。
原文:https://blog.csdn.net/qq_27871973/article/details/82970640
2、卷积核的具体操作
下面直接截图吴恩达老师的课件,做11卷积运算的理解。对于如下的二维矩阵,做卷积,相当于直接乘以2。
 对于三维矩阵,做卷积
对于三维矩阵,做卷积
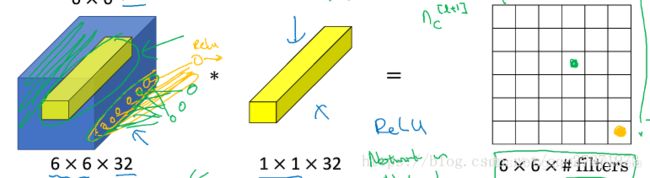
当设置多个11filter时,就可以随意增减输出的通道数,也就是降维和升维。
3、1x1卷积核在在网络中的应用
1)Network In Network论文
最早出现在 Network In Network的论文中 ,使用1*1卷积是想加深加宽网络结构
2)Inception网络
原文:https://blog.csdn.net/stdcoutzyx/article/details/51052847
读google的论文,你立马会感到一股工程的气息扑面而来。像此时的春风一样,凌厉中透着暖意。所谓凌厉,就是它能把一个idea给用到节省内存和计算量上来,太偏实现了,所谓暖意,就是真的灰常有效果。
自2012年AlexNet做出突破以来,直到GoogLeNet出来之前,大家的主流的效果突破大致是网络更深,网络更宽。但是纯粹的增大网络有两个缺点——过拟合和计算量的增加。
解决这两个问题的方法当然就是增加网络深度和宽度的同时减少参数,为了减少参数,那么自然全连接就需要变成稀疏连接,但是在实现上,全连接变成稀疏连接后实际计算量并不会有质的提升,因为大部分硬件是针对密集矩阵计算优化的,稀疏矩阵虽然数据量少,但是所耗的时间却是很难缺少。
所以需要一种方法,既能达到稀疏的减少参数的效果,又能利用硬件中密集矩阵优化的东风。Inception就是在这样的情况下应运而生。
Inception-V1
在Inception网络(论文Going Deeper with Convolutions)中图像输入进来后,通常可以选择直接使用像素信息(1x1卷积)传递到下一层,可以选择3x3卷积,可以选择5x5卷积,还可以选择max pooling的方式downsample刚被卷积后的feature maps。 但在实际的网络设计中,究竟该如何选择需要大量的实验和经验的。 Inception就不用我们来选择,而是将4个选项给神经网络,让网络自己去选择最合适的解决方案。但是这些卷积滤波器的设计也会在计算上造成很大的消耗,由于33卷积或者55卷积在几百个filter的卷积层上做卷积操作时相当耗时,所以11卷积在33卷积或者5*5卷积计算之前先降低维度。
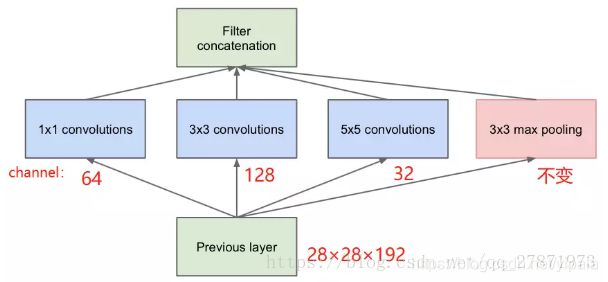
按照上面的说法,我们的这层的模型参数与输入的特征维数(28x28x192),卷积核大小以及卷积通道数(包括三种卷积核,分别是1x1x64,3x3x128,5x5x32),所以参数为:
参数:(1×1×192×64) + (3×3×192×128) + (5×5×192×32) = 153600
最终输出的feature map个数:64+128+32+192 = 416
池化层不引人参数!
feature map个数就是filter个数,一个滤波器在前一个feature map上进行一次卷积操作(特征抽取)会产生一个feature map或者叫通道、深度。
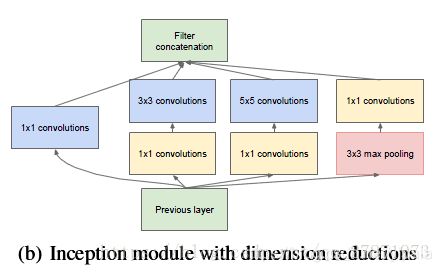
上图中在3x3,5x5 卷积层前新加入的1x1的卷积核为96和16通道的,max pooling后加入的1x1卷积为32通道。
参数:(1×1×192×64)+(1×1×192×96+3×3×96×128)+(1×1×192×16+5×5×16×32)+(1x1x32)=15904
最终输出的feature map个数: 64+128+32+32=256
所以,加入1×1的卷积后,在降低*大量运算的前提下,*降低了维度加粗样式。
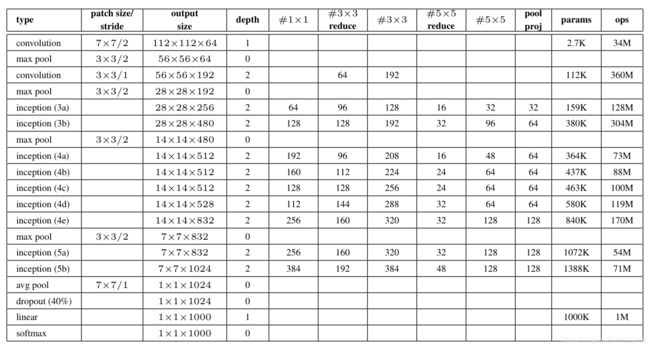
GoogLeNet的模型参数详细如下:
Inception-V2
oogle的论文还有一个特点,那就是把一个idea发挥到极致,不挖干净绝不罢手。所以第二版的更接近实现的Inception又出现了。Inception-V2这就是文献[3]的主要内容。
Rethinking这篇论文中提出了一些CNN调参的经验型规则,暂列如下:
- 避免特征表征的瓶颈。特征表征就是指图像在CNN某层的激活值,特征表征的大小在CNN中应该是缓慢的减小的。
- 高维的特征更容易处理,在高维特征上训练更快,更容易收敛
- 低维嵌入空间上进行空间汇聚,损失并不是很大。这个的解释是相邻的神经单元之间具有很强的相关性,信息具有冗余
- 平衡的网络的深度和宽度。宽度和深度适宜的话可以让网络应用到分布式上时具有比较平衡的computational budget。
Smaller convolutions
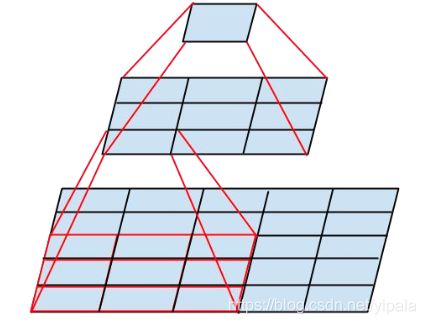
简而言之,就是将尺寸比较大的卷积,变成一系列3×3的卷积的叠加,这样既具有相同的视野,还具有更少的参数。
这样可能会有两个问题,
- 会不会降低表达能力?
- 3×3的卷积做了之后还需要再加激活函数么?(使用ReLU总是比没有要好)
实验表明,这样做不会导致性能的损失
于是Inception就可以进化了,变成了
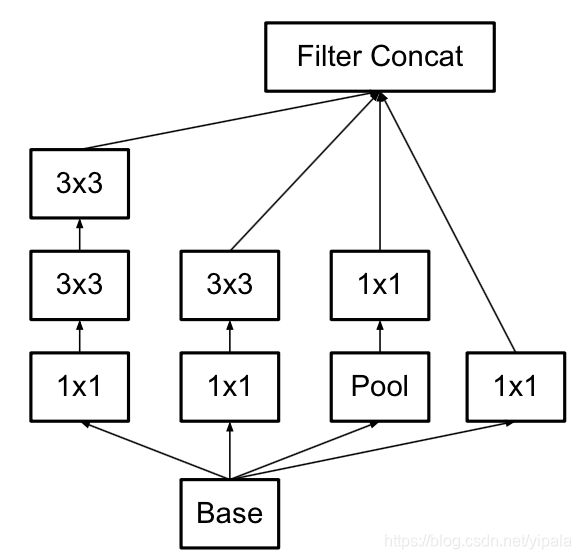
Asymmetric Convoluitons

使用2个2×2的话能节省11%的计算量,而使用这种方式则可以节省33%。
于是,Inception再次进化
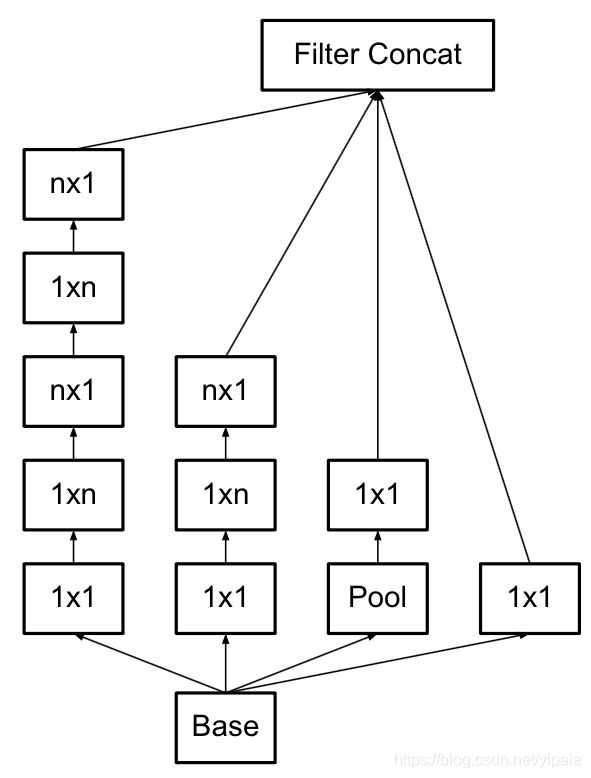
Grid Size Reduction
Grid就是图像在某一层的激活值,即feature_map,一般情况下,如果想让图像缩小,可以有如下两种方式
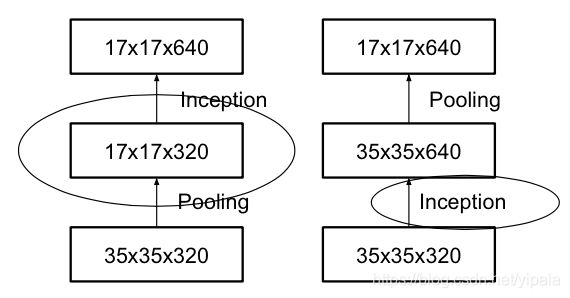
右图是正常的缩小,但计算量很大。左图先pooling会导致特征表征遇到瓶颈,违反上面所说的第一个规则,为了同时达到不违反规则且降低计算量的作用,将网络改为下图:
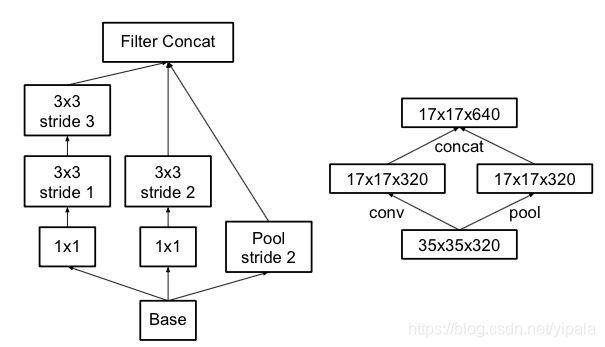
使用两个并行化的模块可以降低计算量。
经过上述各种Inception的进化,从而得到改进版的GoogLeNet,如下:
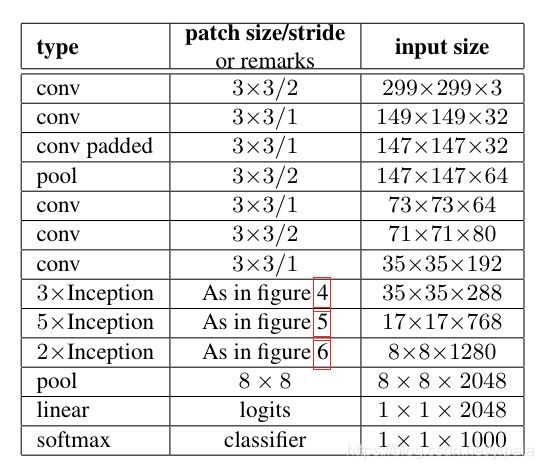
图中的Figure 4是指没有进化的Inception,Figure 5是指smaller conv版的Inception,Figure 6是指Asymmetric版的Inception
**
3、1x1卷积核作用总结**
**
总结一下,1x1的卷积核可以进行降维或者升维,也就是通过控制卷积核(通道数)实现,这个可以帮助减少模型参数,也可以对不同特征进行尺寸的归一化;同时也可以用于不同channel上特征的融合。一个trick就是在降维的时候考虑结合传统的降维方式,如PCA的特征向量实现,这样效果也可以得到保证。
- 降维。比如,一张500 * 500且厚度depth为100 的图片在20个filter上做11的卷积,那么结果的大小为500500*20
- 加入非线性。卷积层之后经过激励层,1*1的卷积在前一层的学习表示上添加了非线性激励,提升网络的表达能力
- 增加模型深度。可以减少网络模型参数,增加网络层深度,一定程度上提升模型的表征能力
参考文献
[1]. Lin M, Chen Q, Yan S. Network in network[J]. arXiv preprint arXiv:1312.4400, 2013.
[2]. Szegedy C, Liu W, Jia Y, et al. Going deeper with convolutions[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015: 1-9.
[3]. Szegedy C, Vanhoucke V, Ioffe S, et al. Rethinking the Inception Architecture for Computer Vision[J]. arXiv preprint arXiv:1512.00567, 2015.
参考资料
[1] https://blog.csdn.net/ybdesire/article/details/8031492
[2] https://blog.csdn.net/a1154761720/article/details/53411365
[3] https://www.zhihu.com/question/56024942
[4]https://mooc.study.163.com/learn/2001281004?tid=2001392030#/learn/content?type=detail&id=2001729330&cid=2001725134